基于注意力和双向LSTM的评价对象类别判定
2019-07-03周陈超陈群李战怀赵波胥勇军秦阳
周陈超, 陈群, 李战怀, 赵波, 胥勇军, 秦阳
(1.西北工业大学 计算机学院, 陕西 西安 710072;2.西北工业大学 大数据存储与管理工业和信息化部重点实验室, 陕西 西安 710072; 3.中国人民解放军95806部队, 北京 100076)
最近几年,随着移动互联网的日益普及,在线评论在用户的消费决策中起着日益重要的作用[1]。用户去电影院之前,一般会先查看豆瓣网用户关于当下热门电影的评论和分析,然后选择想看的电影。去陌生的餐馆吃饭前,一般会在大众点评等评分网站查看其他人关于该餐馆的评论和打分。这些评论不仅对用户有用,同时也对商家大有裨益。好的评价会提升商家的吸引力,商家也可以在评论中发现问题,从而进行改善提高[2]。
但是,网上的评论太多,譬如大众点评关于“海底捞”某个门店的评论就有5 000多条,涉及到餐厅的食物、价格、环境以及服务等各个方面,有好评也有差评,用户自己很难充分利用这些信息。因此需要有自动化的工具对这些评论进行分类和总结[3],为用户提供凝练的关键信息。其中,很重要的一个任务就是对这些评论进行类别判定,分类后的评论能为精细化的情感分析提供细粒度的类别信息[4],有助于分析基于类别的情感 。
这些类别可以是预先设定好的,就像SemEval-2014[5]的restaurant 数据集,将restaurant的用户评论分为{“service”,“food”,“price”,“ambience”,“anecdote/miscellaneous”}5类。在评论“The pizza is the best if you like thin crusted pizza.”中,类别为“food”。
SemEval评测产生了一些类别判定的方法。Kiritchenko等[6]为每一个类别构造一个二元SVM分类器,SVM使用N-gram特征以及从yelp数据集中学到的词聚类和基于点互信息构建的词典等。从yelp学习的词典信息显著提高类别判定的F1值,达到88.6%。为了提高算法的通用性,本文仅涉及训练集中的语料,不使用额外的语料或者知识库。基于公平比较的原则,Kiritchenko等[6]没有使用外部语料和知识库的F1值为82.2%。Brychcin等[7]基于词袋(BOW)和Tf-Idf特征为每个类别构建二元最大熵分类器。在仅使用训练语料情况下,他们算法的F1值是81%。Hercig等[8]在2016年的评测中使用类似方法取得aspect category detection(相机数据集)的第一名,F1值为36.34%。
Schouten等[10]提出无监督和有监督2种方法,无监督方法F1值为67%,判定效果不佳。有监督的方法基于共现分析,包括同在一个句子中的直接共现和通过第三方词关联起来的间接共现,间接共现扩展了算法的识别范围。共现的内涵则包括简单的词-词共现,以及基于依存句法的词-词之间依存共现。训练中通过标签学习词与类别的关联概率,并优化对应的阈值。词之间的共现关系扩展了词和类别之间的关联关系,通过计算句子中词与类别的关联概率是否达到阈值来判定是否属于该类别。Schouten等[10]在有限制训练集上取得的F1值是83.8%。该方法使用外部工具Stanford CoreNLP来识别依存关系,当句子的语法不规范时,Stanford CoreNLP可能无法正确识别依存关系,进而导致类别判定的错误。
注意力机制(attention mechanism)能很好解决同一句子中不同目标的情感极性判别问题。注意力机制最早用在图像处理领域,目的是为了让神经网络在处理数据时重点关注某些信息。Mnih等[11]在2014年提出将注意力机制用在图像分类任务中验证了注意力机制在图像处理领域的有效性,同时也使结合注意力机制的神经网络成为研究热点。Wang等[12]结合LSTM和注意力机制对评论进行基于类别的情感分析,取得了不错的成果。但是注意力机制在评论对象类别判定方面的研究还很少。
我们发现,一个类别对应多个实体。就像“food”,在数据集中有“pizza、chicken、noodles、meal、dishes”等无数对应实体。此外,很多句子没有明显表示类别的词语出现。譬如“It is very overpriced and not very tasty.”包含“price”和“food”2个类别。“price”还好确认,“food”类别则是隐式表达,需要理解“tasty”的语义才能识别出来。评论中这样的隐式表达非常多。还有很重要的一点,名词和形容词在表达句子的类别信息方面起着更关键的作用。评论“pizza here is delicious.”中,只要抓住名词“pizza”就能判断出是“food”类别,形容词“delicious”能强化这种判断。评论中的形容词大多形容与类别相关的名词,不同的类别有明显的差异。譬如“prices are too high.”中“high”一般是形容“price”,而上个例子中的“delicious”一般是形容“food”。因此,形容词在区分类别方面也起到更重要的作用。
评论“the dishes are remarkably tasty and such a cozy and intimate place!”涉及food和ambience 2个类别。进行food类别判定时,只要抓住“dishs”和“tasty”这2个关键词,就能准确判断出类别,而像“the”、“are”等词起不到什么作用。假如把重点放在“cozy”和“place”等词时,还会对类别判定起负作用,这是进行“ambience”类别判定需要关注的重点。因为很多情况下一个句子可能涉及多个方面,所以进行类别判定时需要抓住与类别相关的关键信息,才能准确的判定类别。
基于上述发现,首先,我们使用word2vec训练词向量,将评论转换成词向量的形式。词向量能够表达词之间的相关性,看起来并不相关的词,可以通过词向量关联起来,从而为解决类别包含内容的多样性问题以及隐式表达问题提供了可能。BLSTM将句子的整体语义信息整合,注意力机制则将关注的重点聚焦到与类别相关的关键信息。基于词性权重的注意力机制借助人的先验知识,为注意力的聚焦提供指导。本文为每个类别构造一个二元分类器,包含类别信息的特征用于最终的分类,能有效地提高算法的准确率。
1 评论对象类别判定问题描述

2 基于注意力机制和BLSTM的类别判定算法(WA-BLSTM)
类别判定有2个关键问题需要解决,一个是识别评论中与类别相关的关键词;另一个则是学习词和类别之间的关联关系。关联关系方面的研究很多,但是如何识别评论中的关键词目前研究不多。Kiritchenko等[6]和Brychcin等[7]的方法对于评论中的词同等对待,不分主次,算法的针对性不够强。Schouten等[10]使用依存关系来识别关键词,但是依存关系依靠现有的句法分析工具,算法本身无法保证准确率。本文使用注意力机制来提取评论中与类别相关的重要信息, WA-BLSTM的框架如图1所示。

图1 模型框架图
2.1 输入词向量
本文使用Mikolov的CBOW方法[13]训练词向量,E∈Rd×|V|,其中d是词向量的维度,即把每个词映射为d维向量,|V|表示词向量的大小,即包含多少词的词向量。根据词向量将评论中的句子sj转化成词向量列表{e1,…,et,…,eLj},其中ei∈Rd。
2.2 BLSTM提取语义信息
深层神经网络利用语义合成性原理通过不同深度模型将低层词向量合成高层文本情感语义特征向量,从而得到文本的高层次情感语义表达[14]。深层神经网络同样适用于类别判定,BLSTM能有效利用词语的上下文信息,将词向量转化成高层次类别语义表达。
BLSTM同时考虑文本的上下文语境,将时序相反的2个LSTM网络连接到同一个输出, 前向LSTM可以获取输入序列的上文信息, 后向LSTM可以获取输入序列的下文信息。
前向LSTM在t步时的cell计算过程如下所示:
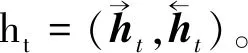
2.3 基于词性权重的注意力机制
要准确判断评论对象的类别,关键是要提取与类别相关的信息。本文使用注意力机制,在计算过程中加入类别特征,据此提取与类别相关的信息用于分类,本文为每个类别构造一个分类器。Wang等[12]在注意力计算的时候,对于LSTM的每步输出是同等对待的。但事实上在判断类别时,名词和形容词起着更为重要的作用。因此,在进行注意力计算前,根据原始评论中的词性为对应的BLSTM输出赋予不同的权重。本文在实验中,形容词权重取1.5,名词取1.2,其他词取1。
H∈R2dh×N包含BLSTM的所有输出向量[h1,h2,…,hN],N为句子S的长度,vc表示类别信息的词向量。本文将词性分为名词、形容词以及其他3类,分别赋予不同权重Q∈RN。类别词向量的加入为注意力的聚焦提供锚点,权重的分配则能为注意力的聚焦提供指导,提升算法的精确度。
(8)
Yq=Q⊙Y
(9)
M=tanh(WmYq)
(10)

(11)
β=HαT
(12)
式中,eN∈RN是值全为1的N维向量,vc⊗eN=[vc;vc;…;vc],Y∈R(2dh+d)×N为BLSTM的每步输出向量附加类别词向量,为注意力的聚焦提供锚点,Yq∈R(2dh+d)×N则是为Y基于词性赋予权重,指导注意力更好地关注与类别相关的重要特征。M∈R(2dh+d)×N,Wm∈R(2dh+d)×(2dh+d),Wα∈R(2dh+d)为模型的参数。α∈RN是ht∈H的注意力分配,β∈R2dh是句子S关于类别vc的权重表达。
句子的最终表达如下所示
h*=tanh(Whβ)
(13)
式中,Wh∈R2dh×2dh为tanh的参数,h*∈R2dh。注意力机制能够捕捉句子中与类别相关的重要特征,因此,当句子中加入不同的类别信息时,分别提取不同的权重特征用于类别判定,为每个类别构造一个分类器。
h*是句子S关于类别vc的特征表达,本文使用softmax将特征向量转换为关于类别的条件概率分布。
y=softmax(WLh*+bL)
(14)
WL∈R2dh×2,bL∈R2为softmax的参数。
2.4 模型的训练
本文使用反向传播算法来训练模型,通过最小化交叉熵和正则项来优化模型,类别ci的损失函数如下
(15)

3 实验与分析
3.1 实验数据和参数
本文使用英文的SemEval-2014 restaurant 数据集和中文的SemEval-2016 相机数据集。实验中,词向量采用Mikolov等[13]提出的word2vec方法,为公平对比,仅使用训练集训练词向量。由于restaurant数据集小,词向量为200维,BLSTM的输出向量为150维;而相机数据集稍多,词向量和BLSTM的输出向量皆为300维。对于未登录词,采用U(-0.01,0.01)来随机初始化词向量。其他超参数如表1所示:

表1 实验超参数
restaurant 数据集包含训练集3 041句和测试集300句。如图2所示,每个句子包含一个或多个类别。其中将近20%的句子包含2个及以上类别。这也是注意力机制的用武之地,能根据不同的类别提取对应的关键信息,提升类别判定的准确率。

图2 每个句子包含的类别数目分布
图3显示数据集中各个类别在评论中所占的比例,其中最大的“food”以及“anecdote/misc”类别占60%以上。占比高的类别不仅数据量大,同时词汇量也大,训练出来的词向量表达的语义丰满,类别判定的准确率高。

图3 不同类别在语料中所占的比例分布
相机数据集包含训练集5 778句和测试集2 256句。为BATTERY,CAMERA,DISPLAY以及CPU等15个类别,每个类别又细化为GENERAL,PRICES,DESIGN & FEATURES,QUALITY等9种属性(有些类别可能只包含几种属性),需要判断每句评论属于哪个“类别#属性”对。相机数据集中无“类别#属性”的句子多,数据分布不均衡,具体分布如图4所示。之所以选择该数据集是因为类别判定问题公开数据集较少,只有SemEval评测有所提供。相机数据集和restaurant数据集有所不同,需要判断评论属于类别的哪个属性,最后阶段的softmax后输出的分类数为属性数加1。
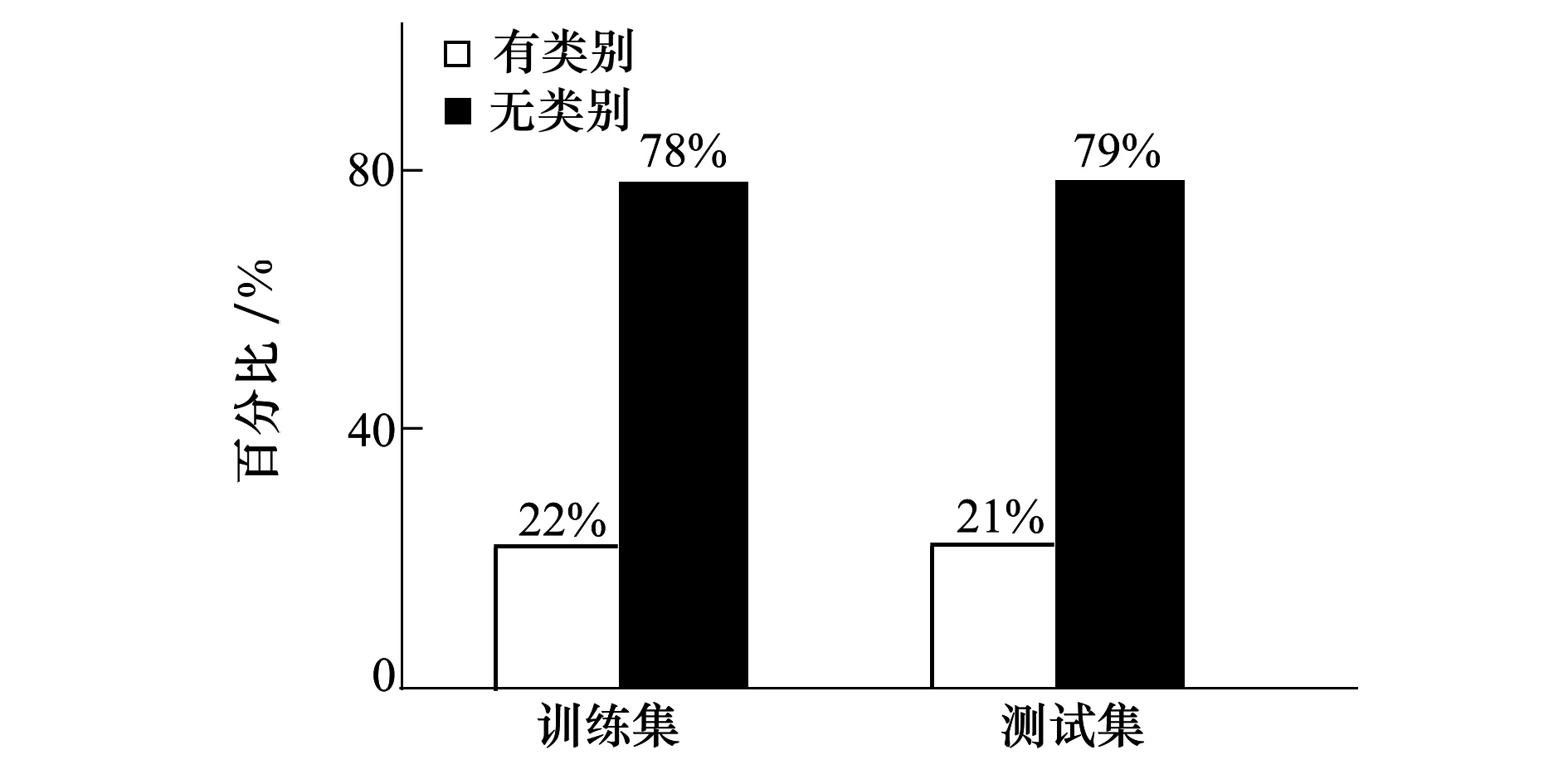
图4 相机数据集类别分布情况
参考SemEval评价方法,本文使用F1值作为评判算法的标准。
(16)
其中正确率(P)和召回率(R)定义如下
(17)
S是算法对于测试集中所有句子给出的类别标签,G是测试集中所有句子的正确类别标签。
3.2 对比实验和结果分析
本文提出的方法与以下4种方法进行比较。
PSM:文献[10]提出的有监督的方法,通过分析共现关系以判定类别。这是关于评论对象类别判定的最新研究。
SVM:文献[6]提出的基于N-gram的SVM方法,为每个类别构造一个SVM分类器。
Max-Entropy:文献[7-8]提出的基于BOW和Tf-idf等特征的最大化信息熵方法。
CNN:文献[9]提出的基于循环神经网络(CNN)的方法。
A-BLSTM:本文提出的方法,如图1所示,在注意力计算时不加入词性权重w,用以对比词性权重在类别判定的作用。
WA-BLSTM:本文提出的方法,如图1所示,在注意力计算时加入词性权重w。
实验结果如表2所示。从表2中可以看出,本文提出的方法在2个领域的数据集上都取得不错的分类效果。其中,不加词性权重的A-BLSTM与之前的最好效果持平,而加入词性权重后的WA-BLSTM分类效果有所提升。其中,restaurant数据集提升了3.21%,相机数据集提升了1.01%。实验结果表明,基于词性权重的注意力BLSTM在类别判定中优于其他方法,词性权重能提升类别判定的效果。

表2 不同方法(限制语料)的F1值
相机和restaurant数据集的分类结果差异巨大,主要因为相机数据集的“类别#属性”对多,但是包含“类别#属性”的句子少。如图4所示,其中78%的句子不包含任何类别和属性,而Restaurant数据集每个句子至少包含一个类别。
表3是restaurant数据集WA-BLSTM与PSM的分类对比,PSM是目前已知的关于类别判定的最新研究。通过表3的对比可以看出不管哪个类别本文的方法都比PSM的效果好。

表3 restaurant数据集WA-BLSTM与PSM的分类F1值
从表3可以看出“food”、“service”和“price”这3个类别的判定效果不错,但是“ambience”和“anecdote/misc”的效果不佳。“anecdote/misc”是除去4个类别剩下的所有其他类别,包含的内容比较杂,提取与类别相关的特征时,没有代表性强并且明确与类别相关的信息可以加入,因此效果不佳。
类别“ambience”的效果最差,一个方面是因为词向量训练语料太少。如图3所示,训练集中,类别“ambience”所占的比例比类别“price”高,但是单词“ambience”才出现20多次,而单词“price”却出现150多次。对比下来单词“ambience”训练语料太小,训练出来的词向量不能充分的表达“ambience”类别的特征,因此就不能很好地提取与类别相关的特征用于类别判定,效果不佳。
上述2个类别的效果差,是由于注意力计算时加入的类别词信息不够全面、准确所致,更深入的原因是训练的词向量受语料限制,表达的信息不充足。因此,加入语义信息丰富的词向量可以提高模型的判定效果。
3.3 示例学习
本文从测试集中选取包含2个类别的评论作为例子,可视化注意力分配结果,如图5所示。其中注意力权重α由公式(11)计算所得,黑色深度代表权重大小,颜色越黑注意力分配得越多。
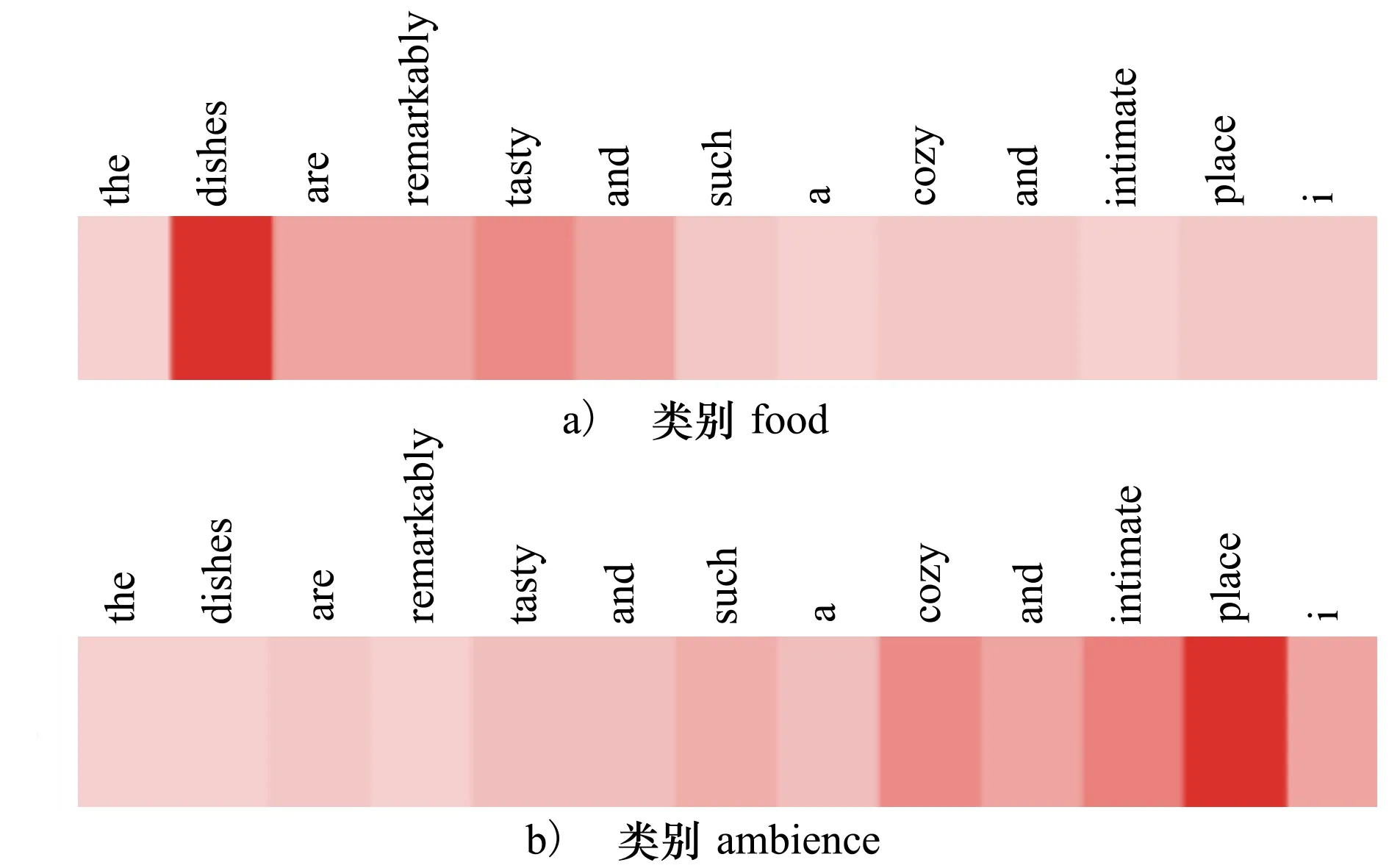
图5 注意力可视化
图5中的评论是“The dishes are remarkably tasty and such a cozy and intimate place!”,涉及“food”和“ambience”2个类别。其中,图5a)是“food”类别的注意力可视化,和food相关的“dishes”和“tasty”被识别出来,名词“dishes”最重要,形容词“tasty”次之。关于类别“ambience”则识别出了对应关键词:名词“place”和形容词“cozy”、“intimate”。
4 结 论
在评论对象的类别判定研究中,本文首先提出基于注意力机制的BLSTM模型来判定评论对象类别。此外,之前的研究主要是结合词向量的注意力机制,本文在此基础上提出了基于词性权重的注意力机制,词性权重能充分利用人的先验知识,对比实验验证了词性权重的有效性,能提高评论类别判定的正确率。实验结果表明,本文提出的方法类别判定效果优于其他方法。
本文的方法不需要外部语料,这是个优点,通用性强;也有不足,仅使用训练集训练的词向量语义表达能力有限。Kiritchenko等[6]的方法在使用外部语料后,效果有很大的提升。本文接下来将研究如何借助外部语料以及更多的先验知识,提升类别判定的效果。
