基于深度学习的白内障自动诊断方法研究*
2019-06-27刘振宇宋建聪
刘振宇,宋建聪,2
(1.沈阳工业大学信息科学与工程学院,沈阳110870;2.辽宁何氏医学院生物医学工程系,沈阳110163)
1 引 言
白内障是全球首要的致盲原因,白内障患者在低视力人群中占比达到47.8%[1]。传统的白内障筛查方法需要患者在大型医院由专业的眼科医生通过裂隙灯设备采集眼部晶体图像进行检查,但在一些贫穷国家及地区,眼科医生及检查设备资源匮乏,加上当地眼病患者的医疗意识较弱,经常出现由于发现或治疗不及时延误最佳治疗时机最终导致失明的情况,因此,亟需一种方便快捷的白内障自动诊断方法,为临床的综合治疗提供依据和参考。
多年以来,国内外专家学者提出过许多方法。美国威斯康星白内障分级系统[2]利用了4 张标准的晶体裂隙灯图像,并将图像按照从1 到4 四个递增的数字来表示白内障的严重程度,其中,数字越大,表示白内障病情越严重,在临床诊断过程中,医生将患者的晶体裂隙灯图像与已分级的标准图像作比较,从而识别出白内障严重程度的等级;许言午等人[3]采用ACHIKO-NC 数据库,以威斯康星白内障分级系统为依据,利用群稀疏回归算法将核性白内障图像自动划分等级;文献[4]将白内障分级问题看作一个排序问题来处理,通过离散排序效果衡量标准连续化和最优化方法达到了学习排序函数的目的。美国约翰霍普金斯大学的Fan S 等人[5]将核性白内障的分级任务视为一个分类问题,他们分析视轴上的强度分布并提取了两个特征:核平均灰度、晶状体后部曲线斜率,并通过最小二乘拟合方法得出疾病程度预测值。中山大学附属医院[6-7]的学者们于2017年提出了一个用于检查先天性白内障的人工智能平台CC-Cruiser,该平台利用了476 个健康人的晶体图像和410 个患者的晶体图像,通过对晶体不透明区域的面积、密度及位置三个方面进行测试,准确率均可达到90%以上,但该系统数据库样本数量少,且只针对先天性白内障这种稀有病进行有效筛查,不能解决大部分白内障的诊疗问题。
根据以上研究,目前对于白内障的自动筛查方法虽然已有很大进展,但仍存在一些问题。一方面基于传统方法的白内障分类研究主要使用人工提取预先定义的特征集,但这些预定义特征可能存在定义特征不够完整且主观性强的问题;另一方面,当前已公开且标注的白内障数据集所对应的白内障类型还不够全面,仅供研究部分类型的白内障,如核性白内障或先天性白内障,导致训练的模型不能达到全面筛查的效果。
为了解决上述问题,构建一组白内障数据集并设计了一个基于卷积神经网络的白内障特征自动学习模型,具体流程如图1所示。首先,为了解决当前白内障数据集缺乏的问题,收集了临床中由裂隙灯采集的眼部晶体图像,并由眼科医生将其分为正常、早期白内障及白内障三类,构建MSLPP 数据集;然后对图像进行预处理,主要操作为光照增强和数据量的扩增;最后,为了解决自动提取深度特征的问题,利用ImageNet 预训练过的Inception-V3模型及参数,并采用迁移学习的思想进行训练,从而得到分类模型。该系统完成后可实现通过手机APP 即能实时进行白内障筛查。

图1 白内障特征自动学习模型流程图
2 数据集与图像预处理
2.1 MSLPP数据集
数据库是实现深度学习系统的重要组成部分,高质量的数据库可以增强系统筛查的准确性。但由于目前缺乏大型公开已标记的裂隙灯眼部晶体图像数据集,因此需要构建用于白内障分类的数据集。实验中采用的数据集为与沈阳艾洛博智能科技有限公司和沈阳何氏眼科集团合作开发,并将其命名为MSLPP(Marked Slit Lamp Picture Project)数据集。
MSLPP 数据集共包含16239 张图片,其中白内障患者眼部样本图像5302 张,早期白内障患者眼部样本图像5400 张,正常人的眼部样本图像5537 张,图像采集于2015年到2018年,来自于2864 个健康人和5532 个白内障患者。
该数据集中所收集的图像均为裂隙灯拍摄的眼部样本图像,所使用的裂隙灯主要为台式裂隙灯和手机裂隙灯,该数据库部分样本图像如图2所示。由图可以看出,将裂隙光聚焦到瞳孔区,内部呈透明或浅黄底色即是正常的晶体,如图2(a)所示;内部呈透明见黄底,光斑略暗即为早期白内障,如图2(b)所示;若内部有明显浑浊,病灶位置可见即为白内障,如图2(c)所示。
2.2 光照增强
亮度是图像处理过程中重点关注的部分。该数据集在采集时,由于实际筛查环境复杂多样,所拍摄样本图像亮度差异大,会影响深度学习准确率,因此,需要对样本图像进行光照调节,突出样本特征,减小由图像亮度差异带来的影响,具体做法如下:
输入图像被压缩为299×299 像素,任意一点A(x,y)的三通道像素则图像的平均像素值a¯可表示为:
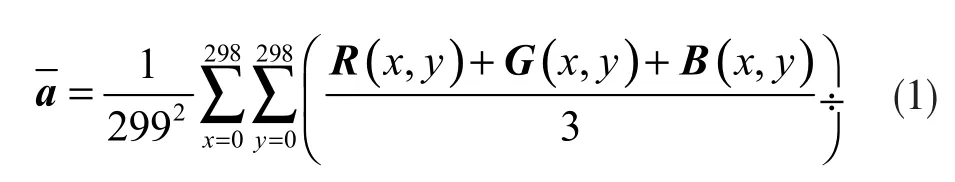
2.3 数据扩增
为了避免模型训练时发生过拟合情况,在进行图像预处理时,需要对样本进行数量扩增处理,有利于改善模型的性能,提高图像分类准确率。实验所采用的数据扩增方式有以下三种:
1) 平移:将图像分别向上下左右平移12 个像素点;
2) 旋转:将图像分别沿顺/逆时针方向旋转15°;
3) 镜像:将图像上下/左右方向各做镜像一次。

图2 MSLPP 数据集部分样本图像
3 模型与方法
3.1 卷积神经网络
在实验中,所采用的方法是卷积神经网络(Convolutional Neural Networks,CNNs)。卷积神经网络是一种带有卷积结构的深度神经网络[8],其结构如图3所示,主要包含卷积层、池化层和全连接层三个部分[9]。
在整个网络中,利用卷积层和池化层提取图像中的有效特征,在网络中引入非线性激活函数,减少有效特征所占维度,输出能够表示输入图像的高级特征,最后,由全连接层将这些特征用于对所要筛查的输入图像的分类。除了上述所提到的基本网络结构,在最后的全连接层中还增加了Dropout 策略,能够有效避免过拟合,提高网络泛化能力,加快网络的训练过程。
3.2 Inception-V3模型
通过比较 AlexNet[10]、VGG16[11]、GoogLeNet[12]等深度卷积模型,最终选用的卷积神经网络结构是谷歌基于GoogLeNet 提出的Inception-V3 模型。该模型共有42 层网络结构,在GoogLeNet 的基础上,对模型的结构进行进一步的分解,将7×7、3×3 结构分解成两个一维的卷积以加速计算,而节省下来的算力可用来加深网络,将卷积层由原来的一个拆分为二,可以更进一步地加深网络,进而提高网络的非线性。
3.3 迁移学习
在医学图像领域,缺乏大量公开已标注的数据集是将深度学习应用于医疗图像处理中的难题之一。在样本不足的情况下,易导致模型训练过程中出现不收敛或者所训练出来的模型泛化能力差等一系列问题。因此,实验采用迁移学习的方法来解决以上问题。
基于卷积神经网络模型迁移学习的白内障分类方法流程图如图3所示。
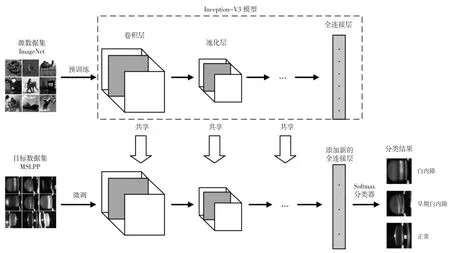
图3 迁移学习策略训练示意图
首先,对基于ImageNet 图像标注的数据集,在Inception-V3 模型上进行预训练,提取一个2048 维的特征向量。这一阶段充分利用知识迁移,使用预训练权重进行特征提取,不对Inception-V3 的权重参数进行训练,与传统方法相比,提取特征更加高效。然后,将特征向量输入一个单层的全连接神经网络。因为训练好的Inception-V3 模型已经将原始的图像抽象成更加容易分类的特征向量,因此使用一个包含Softmax 分类器的单层全连接神经网络,再经过已分类的白内障晶体图像训练后即得到最终分类结果。这一阶段,输入的特征向量主要承担对分类器的训练任务,使得分类器能够更好地基于已提取的特征完成场景分类。
4 实验结果与分析
4.1 实验数据
MSLPP 数据集共包含5302 张白内障晶体图像、5400 张早期白内障晶体图像和5537 张正常晶体图像。实验将该数据集划分为训练集、验证集和测试集,在三个类别中分别随机取出500 张作为测试集,其余样本按6:1 的比例随机分为训练集和验证集。其中,训练集共12630 张,包含白内障4083张、早期白内障4241 张、正常4306 张;验证集共2109 张,包含白内障 719 张、早期白内障 659 张、正常731 张。各类别下图片具体数量如表1所示。
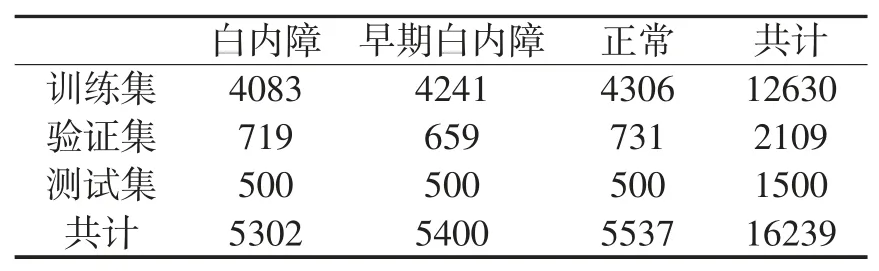
表1 各分类下图片数量对比
将训练集和验证集数据进行扩增,测试集保持不变。扩增后,训练集和验证集的总数量由原来的14739 张增加到了132651 张,其中白内障患者晶体裂隙灯图像变为43218 张,早期白内障患者晶体裂隙灯图像变为44100 张,正常人的晶体裂隙灯图像变为45333 张。
4.2 评价方法
采用四种常用的指标来评估系统的性能:准确率(Accuracy)、召回率(Recall)、精确率(Precision)和F1 指标(F1_meature)。准确率是分类性能的总体度量,它是分类正确的样本数与总样本数之比;召回率是所有正例样本中被分对的比例;精确率是被分为正例的样本中实际为正例的比例;F1 指标是精确率和召回率的调和均值。它们的计算方法如下:其中,TP、TN、FP、FN 分别代表真阳性(True Positive)、
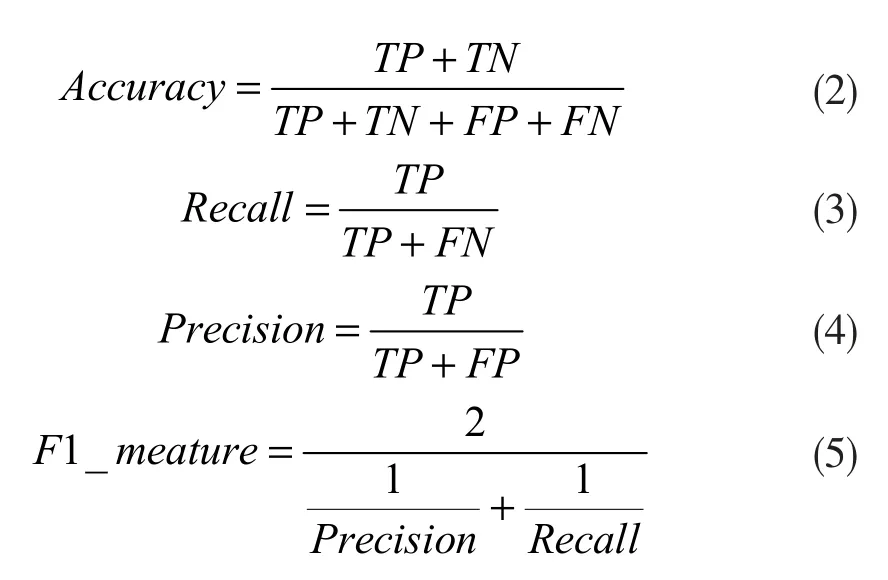
真阴性(True Negative),假阳性(False Positive)和假阴性(False Negative)的数量。以白内障样本为例,“真阳性”意味着白内障样本被正确分类为白内障。如果白内障样本被错误地归为其他分类,我们将其称为“假阴性”。“真阴性”和“假阳性”的含义类似,“真阴性”意味着其他分类样本未被错误地归为白内障,而“假阳性”意味着其他分类样本被错误地归为白内障。
4.3 实验过程与结果分析
4.3.1 训练过程
实验中的所有代码都是以Keras 为前端、以TensorFlow 为后端完成的,该框架基于Ubuntu16.04(64 位)+CUDA9.1+CUDNN9.0 系统。采用的编程语言为Python。训练过程如下:
1、加载去掉全连接层的Inception-V3 模型以及用ImageNet 数据集预训练得出的权重参数;
2、在初始化后的Inception-V3 网络上添加全连接层结构,并在全连接层中加入Dropout 策略,比率设置为0.75;
3、将除了全连接层以外的所有特征提取层冻结,然后将学习率设为0.001,利用预处理后的训练集训练1 个epoch,迭代550 次;
4、将所有层解冻,利用微调(fine-tune)迁移学习,继续用MSLPP 数据集进行训练,采用随机梯度下降的方法,初始学习率设为0.01,训练100 个epoch,每个 epoch 迭代 550 次,每结束一个 epoch,利用验证集测试模型准确率,若准确率较上次提高,保存此次训练参数,若准确率降低,则利用之前保存的参数继续训练。批样本数batch_size 设置为32,动量momentum 设置为0.9。
4.3.2 实验结果分析
模型训练完成后,利用验证集对模型进行验证,其中白内障的召回率为88.24%,早期白内障的召回率为86.63%,正常的召回率为97.51%。随后,又用训练时模型未接触过的测试集进行测试,测试集包含图像共1500 张,其中医生判定为白内障的有500 张,早期白内障500 张,正常500 张,经系统分类后的样本分布情况如表2所示。
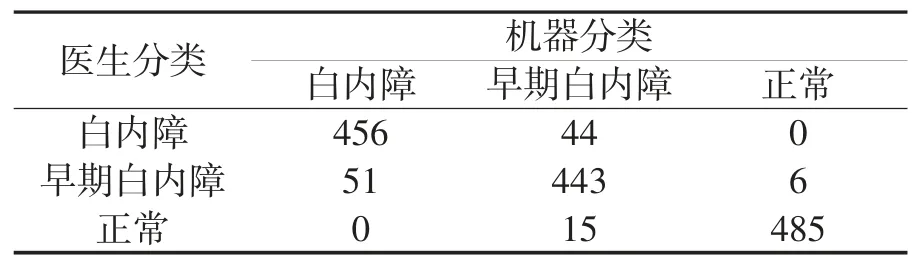
表2 测试集样本分布情况
按照4.2 节的评价方法,系统的性能如表3。
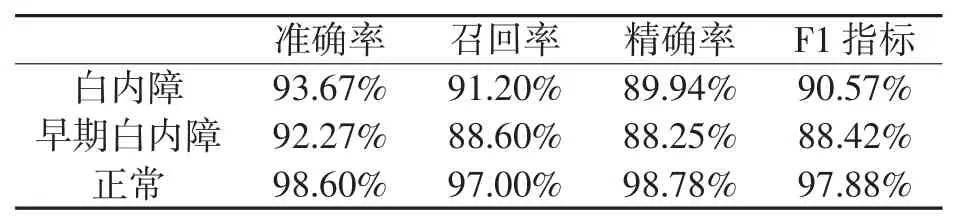
表3 模型可靠性判定
由表中可知,识别正常晶体时的准确率最高,这是因为正常晶体通透性强,特征更明显,而早期白内障的特征则较为多变,且在有些情况下与白内障和正常晶体两个类别的区分界限不够明确,更不容易进行区分,从而影响模型筛查的准确性。由于测试集中三个分类的图像数量均为500 张,因此模型准确率为各类别准确率的平均值,由此可计算出,该模型的准确率为94.85%,召回率为92.27%,根据临床使用标准,该系统具有实用性。同时,根据表3 还可以看出,白内障图像错分为正常图像或正常图像错分为白内障图像的概率为0,以最高的准确度保证了系统的实用性。
5 结束语
提出了基于卷积神经网络的白内障筛查方法,利用特征迁移学习和微调迁移学习,训练后的模型可将被检测晶体图像分为正常、早期白内障及白内障三类。所采用的MSLPP 数据集包含核性白内障、皮质性白内障以及后囊性白内障,并涉及多种不同光照情况,样本具有多样性。实验测试表明,该模型准确率达94.84%,优于其他现有的白内障筛查方法,实用性强,为临床诊断起到了更好的辅助作用。
