基于文献整合的中国不同下垫面植被覆盖度遥感估算模型数据集
2019-06-24刘二华周广胜周莉
刘二华,周广胜,2*,周莉
1. 中国气象科学研究院,北京 100081
2. 南京信息工程大学气象灾害预警协同创新中心,南京 210044
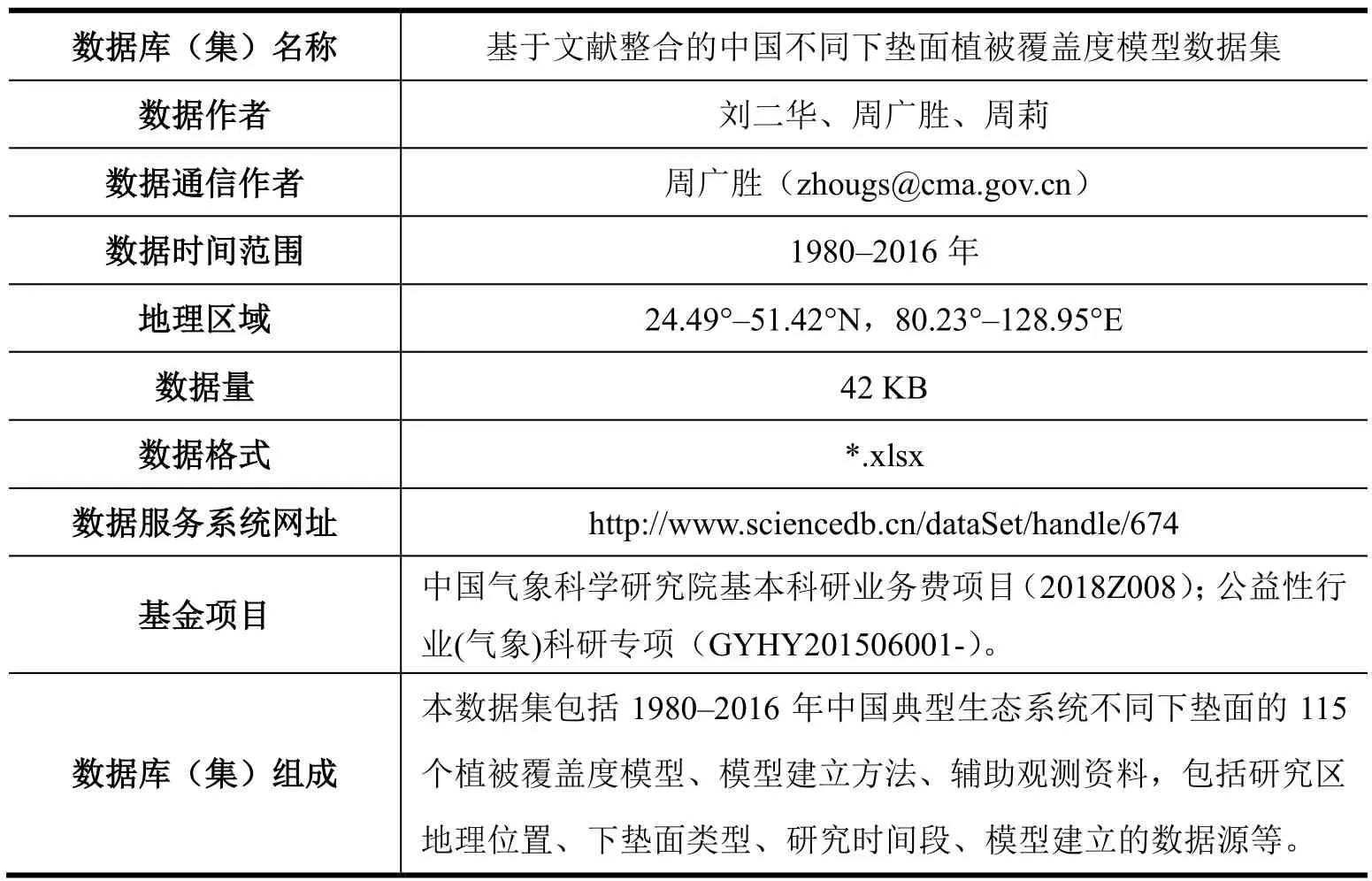
数据库(集)基本信息简介表
引 言
植被是土地覆盖的主要类型之一[1],植被变化对全球物质和能量循环具有重要的影响[2-3]。植被的变化受到气候因素的综合影响,同时,植被也可以调节局地气候[4],即植被是连接土壤、大气和水分的自然纽带[5],也是评估生态环境的重要参数之一。描述植被覆盖状况的重要指标植被覆盖度(Fractional Vegetation Coverage,FVC)是指植被(包含茎、叶、枝)的垂直投影面积占统计面积的百分比,它能够反映植被的生长状态和生长趋势,是衡量植物群落覆盖地表状况的一个综合性量化指标,也是研究生态环境、水土保持和气候变化等方面的重要基础数据[6]。科学定量地反演植被覆盖度对实现生态环境检测和治理以及生态建设服务具有重要的研究价值。贾坤等[7]表示深入研究植被覆盖度对提高地球系统模式和全球变化研究水平具有重要的科学价值。陈洪萍等[8]研究认为气候模式中模拟的气象要素的变化与植被参数的变化密切相关,特别是对FVC、叶面积指数(Leaf Area Index,LAI)等参量极为敏感。根据文献调研,已有的中国生态系统植被覆盖度模型呈现多样化趋势,主要原因 :(1)中国是一个地理分布复杂的国家,地理位置、气候环境和人为活动的复杂性导致气候特征空间异质性。(2)基础数据来源多样化,植被覆盖度的获取方式从目测估算到仪器估算再到遥感解译[9],尤其是随遥感技术的发展,其大范围、准确、及时地监测植被覆盖度[10],同时遥感数据能够反映不同空间尺度的植被覆盖信息以及其变化趋势的优势[7],进一步拓展了数据的获取方式,基于遥感资料估算植被覆盖度已经成为当前科学研究的重要手段[11]。(3)植被覆盖度估算方法的多样化。当前,广泛应用的方法主要有两类,一类是经验模型法(回归模型法、植被指数法)、混合像元分解法(像元二分模型法)、物理模型法(光谱梯度差法和模型反演法)和FCD模型制图法[1];另一类是基于空间数据挖掘技术即机器学习法,该类方法主要有神经网络算法、支持向量机和决策树算法[12]。其中应用最多的方法是经验模型法和像元二分模型法。(4)下垫面植被类型不同导致模型的多样化。
下垫面类型对植被覆盖度的影响很大。不同下垫面类型对应的植被覆盖度具有较大的差异。因此,分不同地理区域、分不同下垫面类型整理植被覆盖度模型数据集对于科研业务研究具有重要的实际意义。下垫面的复杂性与异质性在各区域难以形成统一且广泛应用的植被覆盖度模型。同时,各个生态区脆弱性和环境承载力均不一致,如何在不同省、市、流域或矢量边界选择合理的植被覆盖度模型并准确评估生态系统的安全性是科研研究和业务应用的关键。然而,多样而宝贵的植被覆盖度模型仍没有得到系统的整理,尚未形成一套系统的可以评估生态系统效益的综合模型数据集。基于以上限制,本研究通过对公开发表的文献资料收集整理,构建了典型生态系统不同下垫面植被覆盖度模型数据库,并公开应用于生态环境评估中。为各区域生态、水保、土壤、水利、植物等领域的定量研究提供模型数据基础,促进自然环境研究不断深入发展,以期为全国省、市和区、流域等地区的生态安全建设提供植被覆盖度模型数据库支撑。
1 数据采集和处理方法
1.1 数据来源
本研究收集了1980–2016年中国典型生态区域植被覆盖度遥感估算模型文献资料。主要来自于中国知网数据库(http://www.cnki.net/)等。以“植被覆盖度”“草地植被覆盖度”“回归模型法”和“像元二分模型”等作为关键词检索文献。获取的文献有以下要求:(1)地面采样点数据能与遥感影像获取数据准确定位,地面采样点的空间尺度尽量与遥感资料空间尺度一致。(2)地面采样点应体现植被和土壤的均质性且采样点植被覆盖度应具有一定的变化范围。(3)文献中明确指出植被覆盖度模型对应的下垫面类型。本研究将符合以上3点要求的文献资料进行整理,最终获取了包括林地、灌丛、草地、湿地、沙漠化草地、农田、城镇和石漠化区的植被覆盖度模型数据集。
1.2 数据处理步骤
整理收集的文献资料,查询每篇文献中植被覆盖度模型、植被类型信息以及地理信息等。对于提供的资料是区域研究的,将经纬度分别取平均值,将该经纬度作为研究区代表点;对于提供同一站点多年植被覆盖度模型的资料,逐一提取每年特定时间的植被覆盖度模型;对同一站点提供多种植被类型植被覆盖度模型的研究,逐一统计各类模型。缺失站点地理位置和生态系统类型信息的站点,再基于观测站点名称进一步查阅资料进行补充。具体处理步骤如图1所示。
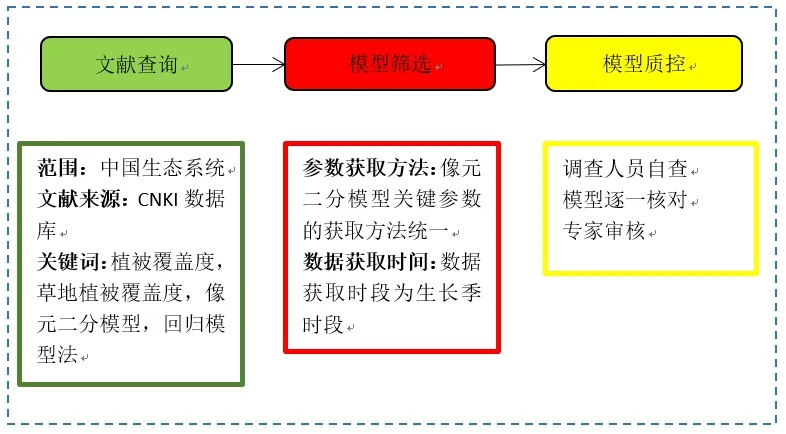
图1 模型数据处理流程
2 数据样本描述
本数据集共包含中国区域1980–2016年基于像元二分模型和回归模型法建立的115个植被覆盖度模型,涉及的下垫面类型包括林地、灌丛、草地、湿地、沙漠化草地、农田、城镇和石漠化区,模型中以林地、草地、沙漠化草地和农田为主。
本数据集由一个EXCEL格式的文件组成,包括两个WORKSHEET,分别是植被覆盖度模型以及相关信息和文献出处。观测数据表的列表依次是序号、下垫面类型、下垫面类型分区、分布区域、纬度、经度、适用时段、植被覆盖度模型、植被指数类型、时间分辨率、空间分辨率、遥感资料来源、模型构建方法、验证资料来源、R2、模型精度、文献(表1)。不同下垫面类型建立的植被覆盖度模型存在差异。表1中下垫面为林地,植被覆盖度与林地植被指数构建了像元二分模型,0.42表示该研究区植被指数最小值,0.83表示该研究区植被指数最大值。同时,数据集中包含的石漠化地区的植被覆盖度模型可以看出最大植被指数和最小植被指数均比林地小。以上两个差异较大的下垫面类型,其对应的最大最小值差异较大,这正是不同地区,不同下垫面构建了不同植被覆盖度模型的区别所在。另一方面,不同地区研究对象均是林地,模拟得到的植被覆盖度也存在差异,是合理的,因为同样是林地,研究区域以及林地类型不同等均是导致植被覆盖度存在差异的原因。

表1 不同下垫面植被覆盖度模型数据库列表项及说明
3 数据质量控制与评估
本数据集来源于公开发表的文献。对于收集的文献数据,从数据库选择、检索关键词、文献筛选标准、数据提取到整理,整个过程都对数据质量进行了控制。
模型质量控制:基于中国知网等权威的文献数据库进行检索,保证了文献来源的质量。锁定“像元二分模型”和“回归模型法”,集中统计基于这两个方法的文献研究。同时,保证像元二分模型中关键输入参数 VIsoil和 VIveg的获取方法统一,因为这两个参数获取的准确性直接影响到植被覆盖度的估算结果[13-14]。

式(1)中FVC表示植被覆盖度,VI表示植被指数。VI可以是NDVI,也可以是其他任何一种植被指数。VIsoil表示完全裸露土壤所在区域的VI值,VIveg表示植被完全覆盖区域的VI值。对于多数裸地表面,VIsoil理论值应该是 0,但是受大气效应和地表水分等因素影响,其值一般在−0.1~0.2之间。VIveg也受植被类型的影响而变化。不同研究参数获取方法存在较大差异[15]。目前参数获取方法有4种:(1)目视解译或者端元提取法;(2)结合样地调查,通过对实测数据和对应像元植被指数的关系获得参数;(3)结合土地利用类型数据和土地分类图,根据累计概率值分别获得纯植被像元和纯土壤像元的植被指数值;(4)在植被指数灰度分布的置信区间内获取植被指数最大值和最小值。当前,由于缺乏大面积地表实测数据做参考,广泛应用的确定VIsoil和VIveg的方法是通过土地利用图、土壤图和地形图对VI数据进行统计分析来获取[16]。以下为像元二分模型构建步骤(图2)。
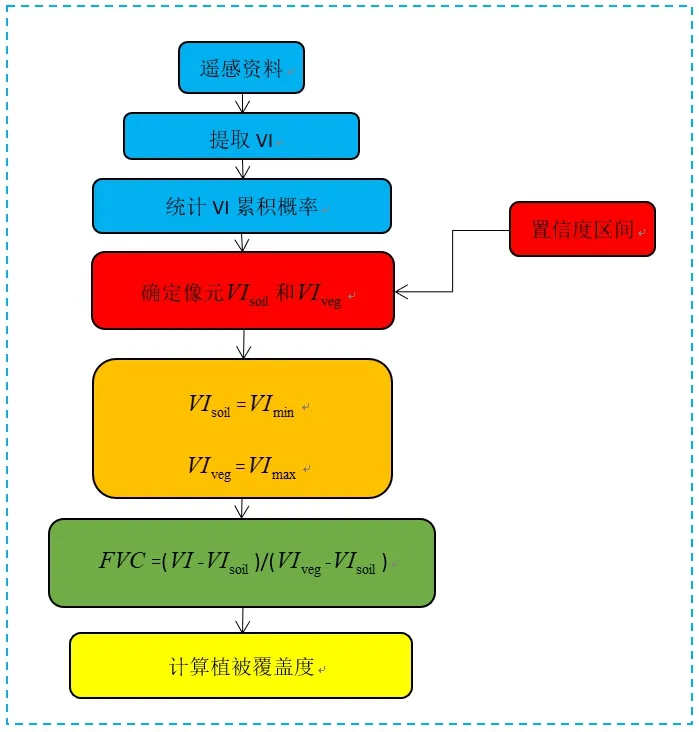
图2 植被覆盖度构建流程
首先获取VI遥感影像图,利用遥感处理软件统计每个像元对应VI的分布表。其次将该表做统计处理,获取影像像元总个数,并统计每一景影像VI的像元个数,累计概率分布为每一景影像中VI累计像元个数除以总像元个数。最后,根据置信度确定最大最小累积概率置信区间的值,分别为VIveg和VIsoil。其中置信区间的选取目的在于排除异常值[17],置信区间的取值主要由图像大小、图像清晰度等情况来决定[18],因此数据来源、空间分辨率等导致置信区间选取的不一致性。研究表明像元二分模型估算植被覆盖度具有一定的准确性,其理论简单,制约条件少,在区域尺度监测上有较好的适用性[19]。另外,像元二分模型可以削弱大气、土壤背景和植被类型的影响[20]。
模型审核:对整理完毕的植被覆盖度模型数据库,先由整理者逐一对应每篇文献出处复查原始模型,再由多名模型整理者随机交叉抽取文献进行检验,最后交付给专家进行最终的审核和修订,确保模型数据库的正确、可靠。
模型质量评估:植被覆盖度遥感估算模型的数据源、植被类型、研究区域等的不一致性导致植被覆盖度估算过程存在诸多不确定性。本研究收集的植被覆盖度模型主要分析了以下几点不确定性:
(1)本研究整合的数据集中的植被覆盖度遥感估算模型主要是基于像元二分模型以及少数的线性或非线性模型收集整理,这些方法在实际应用中较为简单,计算效率较高,但是基于不同的遥感数据源、不同的植被覆盖度以及不同的研究区建立的经验或半经验遥感估算模型,仅适用于特定区域的特征植被[8]。
(2)基于像元二分模型法估算的植被覆盖度则存在理论不确定性和物理不确定性两方面。理论不确定性主要是由于模型输入原始数据的不确定性,即地面采样点选取的主观性等造成的人为误差;遥感信息测定过程中,由于受传感器倾角、大气稳定性等影响使结果存在一定的系统误差;像元二分模型反演的不完善性,反演过程中误差传递造成的不确定性;物理不确定性如植被覆盖度参量本身具有一定的方向性,植被覆盖度随角度的变化而变化,从而造成的不确定性。
(3)使用数据集中相关植被覆盖度遥感估算模型时,应多关注模型数据来源。利用相关植被覆盖度模型时进一步地利用现有数据验证模型的准确性。比如数据集中存在遥感资料来源不一致但研究区、下垫面等一致的情况下,植被覆盖度模型存在一定的差异性,这说明模型的定量化形式与遥感资料的来源密切相关,关于这一点需要使用者特别关注。
(4)数据统计分析误差。由于生态系统、植被类型以及遥感数据源不同,每个站点采用不同的数据源,数据剔除、校正和插补方法等的差异,使分析结果引入了一定的系统误差。本研究中,收集的观测站点在分析方法上的差异主要体现在模型构建方法、数据源和数据时空分辨率上。因此本研究在考虑模型准确应用方面,将下垫面类型进行了分区,以便于使用者准确筛选数据模型。本模型数据集中不同研究区不同植被类型中,得到的像元二分模型法中的纯土壤和纯植被像元的植被指数值有差异。收集的模型库中模型适用的时间尺度主要有年尺度、月尺度和日尺度。
4 数据使用方法和建议
植被覆盖度为生态建设和可持续发展提供科学依据。本研究整合了中国区域现有公开发表的典型生态区植被覆盖度模型。根据下垫面土地利用状况,绘制出典型生态区植被覆盖度模型的空间分布状况,为全国或区域生态格局、生态功能以及生态质量检测提供数据库支撑。建立的中国典型陆地生态系统植被覆盖度模型数据库,是国内首个基于文献整合的生态系统尺度的植被覆盖度模型数据库。本数据集涵盖了我国115个植被覆盖度模型,这一数据集可为我国区域生态系统植被效益评估、生态环境承载力评价、全球变化研究以及生物地球化学循环模型的优化提供重要的数据支持。本数据集在使用中需要注意以下3个方面的问题:
(1)对于植被覆盖度模型处理技术与方法,目前还没有全球统一的技术规范,各研究通过对比分析采用了最适合当地植被覆盖度模型估算方法进行分析处理。因此,每个模型构建方法、极值设定等方面存在差异。建议研究特定地区植被覆盖度时,应选取本数据集中对应地区、对应植被类型的植被覆盖度模型。数据处理方法也应与现有模型相统一。
(2)植被覆盖度具有明显的时空分异的特点[21]。本研究综合了同一观测点的多年植被覆盖度模型,反映的是同一台站不同数据源和不同下垫面类型模型,因此各个模型有一定的差异性。同一个地区具有多个植被覆盖度模拟模型时,建议尽量保证遥感数据来源一致,下垫面植被类型保持一致。
(3)不同时间和空间尺度的观测数据遥感反演产品不具有可比性,同时不同尺度的遥感反演模型也不能混用[9],应根据研究需要的时间分辨率和空间分辨率采纳合适的植被覆盖度模型。建议利用该数据集时,注意保证本数据集中模型时空尺度与使用者研究的保持一致。
致 谢
感谢本文数据收集、整理、分析者做出的贡献!
