MD-RBM神经网络模型及其在材料微结构中聚类研究
2019-06-17储节磊张永盛杜金树马普欢吕俊营钱泳霖
储节磊 张永盛 杜金树 马普欢 吕俊营 钱泳霖
1(西南交通大学信息科学与技术学院 四川 成都 611756)2(西南交通大学力学与工程学院 四川 成都 611756)
0 引 言
材料的内部结构称之为微结构,材料微结构的特征隐藏着材料的所有物理和化学性质,通常情况下是通过专家人工分类识别材料微结构,这样会增加主观上的不确定性,因此,用机器学习的方法研究材料微结构识别具有很高的理论价值和实际意义。Azimi等[1]提出了一种全新的全卷积神经网络(FCNN),利用深度学习的方法解决了高级钢微结构的分类问题;Gola等[2]利用支持向量机(SVM)研究了高级钢微结构的分类识别,这些机器学习方法在微结构识别中都达到了比较高的识别精度。
受限玻尔兹曼机(RBM)神经网络及其变体结构具有强大的特性学习能力,在Hinton提出了RBM快速算[3]法以后,基于标准RBM模型的研究在理论和实际应用中出现了丰富的成果,例如:自然语言理解[4]、实时关键点识别[5]、特征学习[6]、计算机视觉[7]、人脸识别[8]、分类[9-11]、时间数列预测[12-13]、语音转换[14]、降维[15]等。但是传统的RBM在编码的过程中缺乏一定的监督信息指导,编码过程缺少方向性。
为此本文作者前期的研究中针对图像聚类问题,提出了一种pcGRBM神经网络模型[16],该模型在编码过程中引入了成对约束信息[17](Must-link和Cannot-link)监督编码过程,但是采用的是欧式距离,计算距离的时候缺乏稳定性。因此,本文提出了一种全新的MD-RBM变体模型用于超高碳钢材料微结构的聚类研究,在其编码的过程中同样采用了少量成对约束信息引导编码过程,使得在Must-link(ML)集合中成对数据的隐藏层编码更加聚集到一起,同时使得在Cannot-link(CL)集合中成对数据的隐藏层编码距离变得更远;在计算成对约束数据之间的距离时,本文采用了乘积距离(MD)[18],有效缓解高维数据距离的不稳定性问题,使得MD-RBM学习到的隐藏层特征更加适合于后续的聚类任务;本文在MD-RBM模型的基础上,设计了两个基于该模型的半监督聚类方法(AP+MD-RBM,SC+MD-RBM)用于评价MD-RBM模型特征学习的有效性。
1 传统RBM模型
RBM(Restricted Boltzmann Machine )神经网络模型是一个两层网络结构,第一层是由二进制可视单元构成,第二层由二进制隐藏层单元构成,两层之间通过连接权矩阵连接,同层单元之间没有任何连接,其结构图如图1所示。
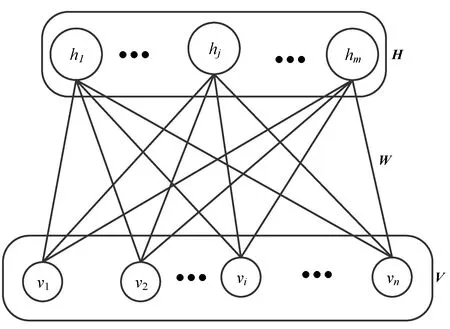
图1 传统RBM模型
RBM模型参数为θ=(W,a,b),其中Wn×m是连接权矩阵,可视层单元为V=(v1,v2,…,vn),隐藏层单元为H=(h1,h2,…,hm),可视层的偏差参数为a=(a1,a2,…,an),隐藏层的偏差参数为b=(b1,b2,…,bm)。
传统RBM模型的能量函数为:
(1)
对于随机给定的可视层数据v,隐藏层二进制单元等于1的概率为:
(2)
式中:σ是S型函数。
在hinton提出快速算法之前,RBM神经网络模型的训练效率比较低,难以实际应用。2005年,hinton提出了CD(contrastive divergence)快速算法,大大提高了RBM神经网络的训练效率,基于CD1算法的模型W、a、b的更新规则如下:
(3)
(4)
(5)
有了上面的快速算法,使得RBM在很多实际应用中取得了成功。
2 MD距离
在高维数据空间中,常用的欧式距离会变得不稳定,在这样的背景下由Jafar Mansouri提出了乘积距离(MD)[18],用于缓解高维数据的距离不稳定性。
定义1假设X=(x1,x2,…,xm),Q=(q1,q2,…,qm)是两个随机向量(k=1,2,…,m),令zk=1+|xk-qk|,则两个向量X和Q之间的MD距离定义为如下形式:
(6)

3 MD-RBM模型
3.1 模型参数更新规则
对于可视层输入数据集V,隐藏层特征数据集H,假设在MD-RBM隐藏层H特征集合中存在任意一对向量(Hs,Ht)∈ML,其中Hs=(hs1,hs2,…,hsm),Ht=(ht1,ht2,…,htm)。另外存在任意一对向量(Hp,Hq)∈CL,其中Hp=(hp1,hp2,…,hpm),Hq=(hq1,hq2,…,hqm),那么向量Hs和Ht之间的MD距离表达式为如下形式:
(7)
同理可以得到向量Hp和Hq之间的MD距离表达式为:
(8)
令JM=MD(Hs,Ht)+1,JC=MD(Hp,Hq)+1,则有:
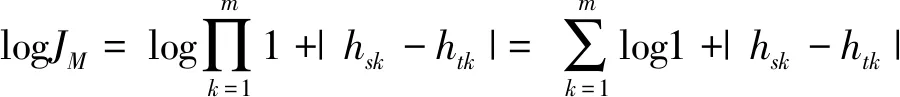
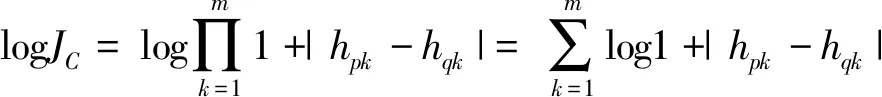
那么MD-RBM的目标函数F(θ)定义为如下形式:

(11)
式中:λ∈(0,1)是约束调节参数,负责调节约束信息在整个模型中权重,N和M分别是ML和CL集合中的大小值。下面采用随机梯度下降法求解模型参数,其中logp(v,θ)优化采用hinton提出的CD1快速算法,那么接下来的主要难点在于求解logJM和logJC的梯度,下面将分别求解这两部分关于MD-RBM模型参数θ=(W,a,b)的偏导数,首先对连接矩阵W求解有:
(12)
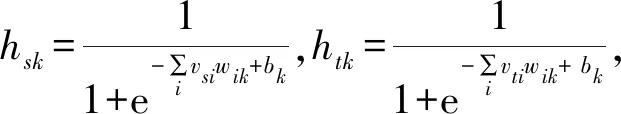
显然只有当k=j时,hsk和htk才和wij相关,所以有:
(13)
由于:
(14)
同理可以得到:
(15)
所以:
(16)
采用同样的求解方法,同样也可以得到:
(17)
接下来求解参数b,同样只有当k=j时,hsk和htk才和bj相关,所以有:
(18)
(19)
对于模型参数a,logJM和logJC都与之无关,所以有:
(20)
综上求解结果,可以得到MD-RBM模型参数θ=(W,a,b)的更新规则如下:
wijτ+1=wijτ+λε(

(21)
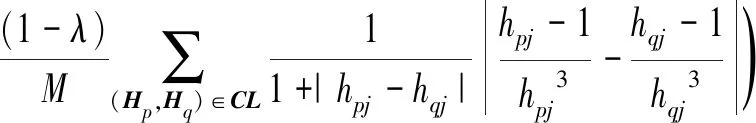
(22)
(23)
3.2 MD-RBM学习算法
根据以上求解得到的MD-RBM模型的参数更新规则,MD-RBM模型学习算法如下:
第一步:初始化模型参数W、a、b;
第二步:对可视层数据集,获得隐藏层特征采样;
第三步:对所有隐藏层特征,计算第一次重构数据采样;
第四步:按照式(16)-式(19)

第五步:分别按照式(21)-式(23)获得模型参数的更新规则;
第六步:如果迭代没有结束,返回第二步继续迭代,否则结束迭代过程;
第七步:返回模型参数。
3.3 基于MD-RBM模型的聚类算法
本文把MD-RBM模型提取到的特征分别作为AP,SC算法的输入,就可以得到基于MD-RBM模型的两种对比聚类算法: AP+MD-RBM和SC+MD-RBM,如图2所示。
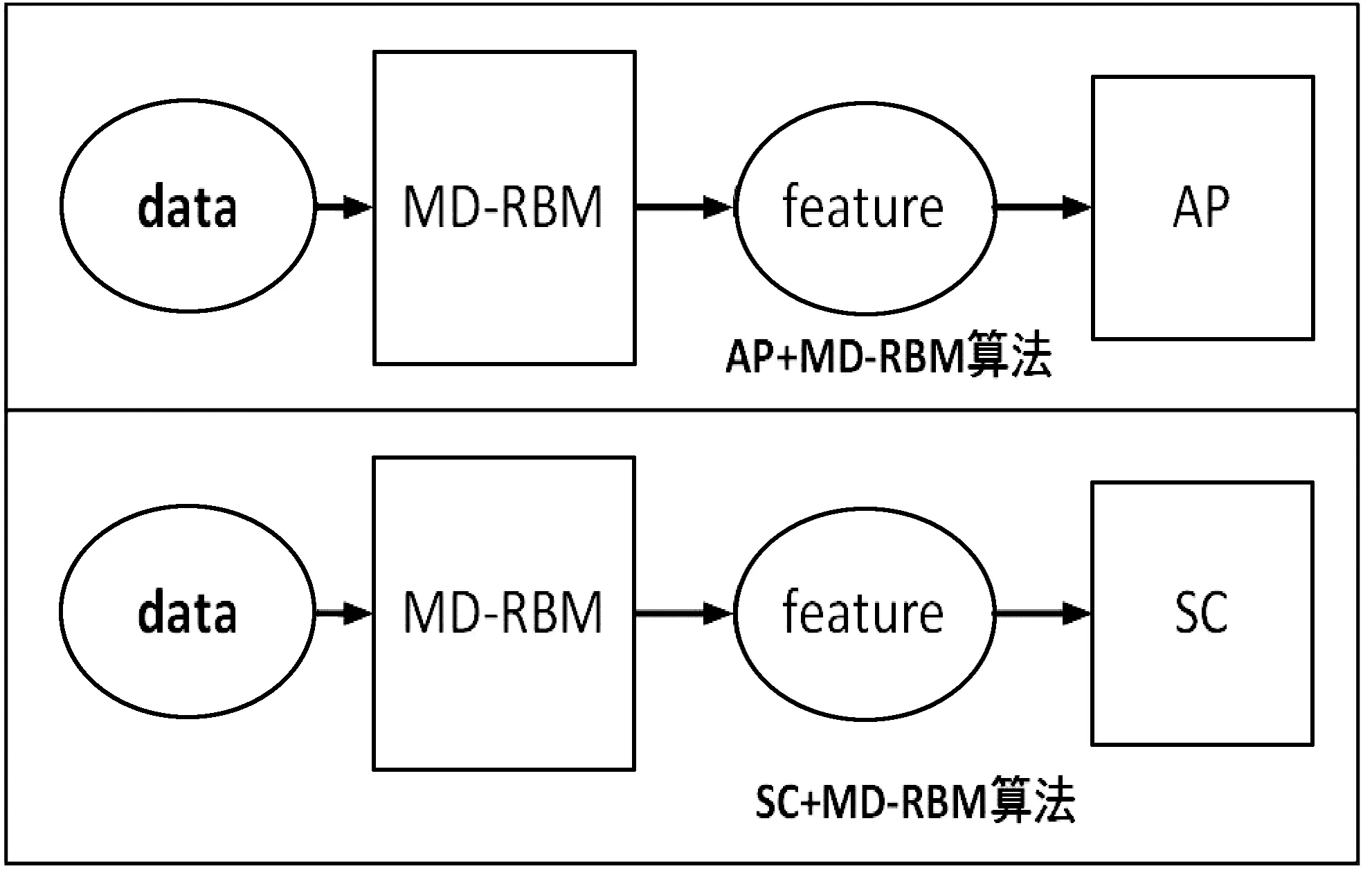
图2 AP+MD-RBM和SC+MD-RBM 算法流程
4 实 验
4.1 数据集
本文实验选择的数据集来源于美国国家标准和技术研究所(https://materialsdata.nist.gov)提供的超高碳钢微结构数据集。该数据集由超高碳钢(UHCS)显微照片组成,实验前对1 732张图片进行了标注,分为六类微结构,第一类是珠光体,第二类是先共析渗碳体网状微观结构,第三类是球状渗碳体,第四类是包含球状渗碳体的珠光体,第五类是魏氏渗碳体,第六类是马氏体或贝氏体。调整后的图片维度为685⊆484维度,原始图片实例如图3所示。


图3 六类超高碳钢微结构
4.2 对比实验及参数
为了验证本文提出的MD-RBM神经网络模型的特征学习能力及其在材料微结构识别性能,把MD-RBM模型的隐藏层特征分别作为AP[19]和SC[20]两种聚类算法的输入,设计两种新的算法,分别命名为AP+MD-RBM和SC+MD-RBM。为了测试算法的性能,实验中选择了三类对比实验,具体如下:
第一类对比实验: AP+MD-RBM和SC+MD-RBM算法分别与传统算法AP和SC之间的对比;
第二类对比实验: AP+MD-RBM和SC+MD-RBM算法分别与传统半监督算法Semi-AP[21]和Semi-SC[22]之间的对比;
第三类对比实验:传统的RBM模型同样具有很强的特征学习能力,为了对比本文提出的MD-RBM模型和传统的RBM模型的特征学习能力,让RBM模型的隐藏层特征分别作为AP和SC两种聚类算法的输入,设计了两种算法,分别命名为: AP+RBM和SC+RBM,然后分别与AP+MD-RBM和SC+MD-RBM算法进行对比实验。
对比实验中选择了三类聚类外部指标作为算法性能评判标准,第一类指标是正确率[23](Accuracy);第二类指标是Purity[24];第三类指标是Rand Index指数[25]。
正确率(Accuracy)指标定义如下:
(24)
式中:n是实例个数,如果x=y,那么δ(x,y)=1,其他情况下δ(x,y)=0,map(ri)是标签映射函数。
purity指标定义如下:
(25)

给定一个集合U={u1,u2,…,un},O={o1,o2,…,or}是U的r个子集划分,p={p1,p2,…,ps}是U的s个子集划分,那么Rand Index指标定义如下:
(26)
式中:Nss表示元素同时在O和P的相同子集中的个数,Nsd表示元素在O中同一子集和在P的不同子集中的个数,Nds表示元素在O中不同子集和在P的同一子集中的个数,Ndd表示元素在O和P中都不同子集中的个数。
实验中使用的软件平台是Windows 7,MATLAB 2013R,服务器主要硬件配置为:48核CPU,128 GB内存,2 TB硬盘。
MD-RBM模型中约束权重调节参数λ=0.2,迭代次数设置为6次。实验中重复了十次实验,后续的实验结果采用取平均值得方法得到最终的评价指标。
4.3 实验结果
从表1中可以看出,两个传统算法AP和SC的正确率分别是:39.16%和35.53%;purity指标分别是: 0.622 7和0.618 9;RandIndex指标分别是:0.513 4和0.508 8。但是表2、表3中基于MD-RBM模型的聚类算法AP+MD-RBM和SC+MD-RBM的平均正确率分别提高到了:85.461 0%和82.096 0%,大幅度提升了聚类性能;表4显示平均purity分别提高到了0.854 4和0.844 0;而表5显示出它们的平均Rand Index指标分别提高到了0.822 5和0.802 7。综合上述三个平均指标的实验结果可以看到MD-RBM模型具有很强的特征学习能力,而且提取到的特征用于聚类识别分别比传统的聚类算法更好。
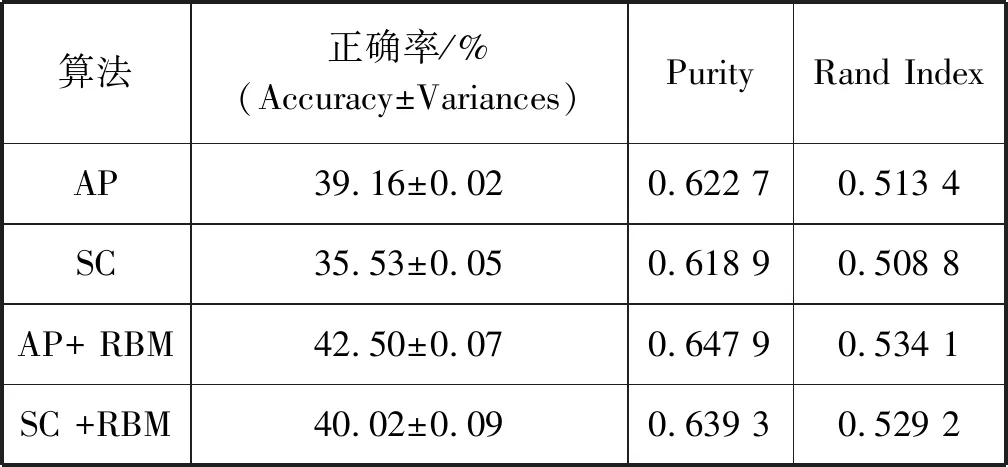
表1 传统AP,SC与基于RBM模型的AP+RBM和SC+RBM算法性能对比(正确率、Purity和Rand Index)
从表2、表3中可以看出,两个半监督聚类算法Semi-AP和Semi-SC的平均正确率分别为63.818 0%,和62.172 0%,基于MD-RBM模型的算法平均正确率分别提高到了85.461 0%和82.096 0%。从表4中可以得到两个半监督聚类算法Semi-AP和Semi-SC的评均purity指标分别为0.777 1和0.767 2,低于基于MD-RBM模型的对比算法。从表5中同样可以得到两个半监督聚类算法Semi-AP和Semi-SC的平均RandIndex指标分别为0.673 5和0.664 0,低于基于MD-RBM模型的对比算法。

表2 Semi-AP半监督算法与AP+MD-RBM算法正确率指标性能比较(约束数量从15逐步增加到60) %
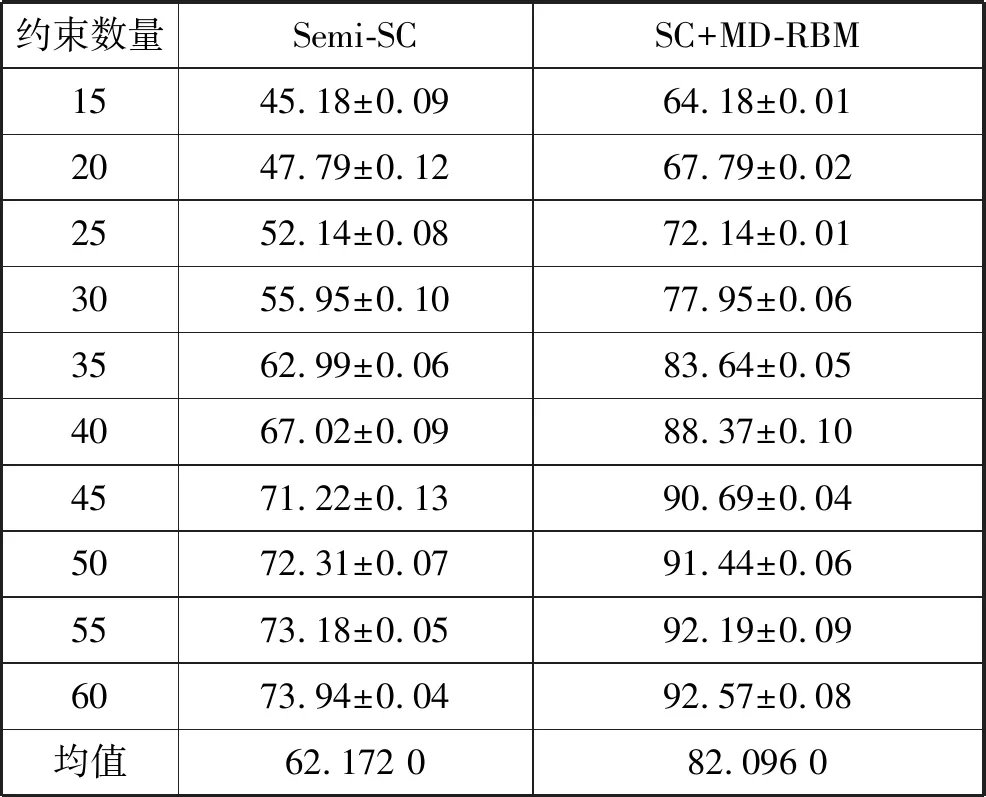
表3 Semi-SC半监督算法与SC+MD-RBM算法正确率指标性能比较(约束数量从15逐步增加到60) %
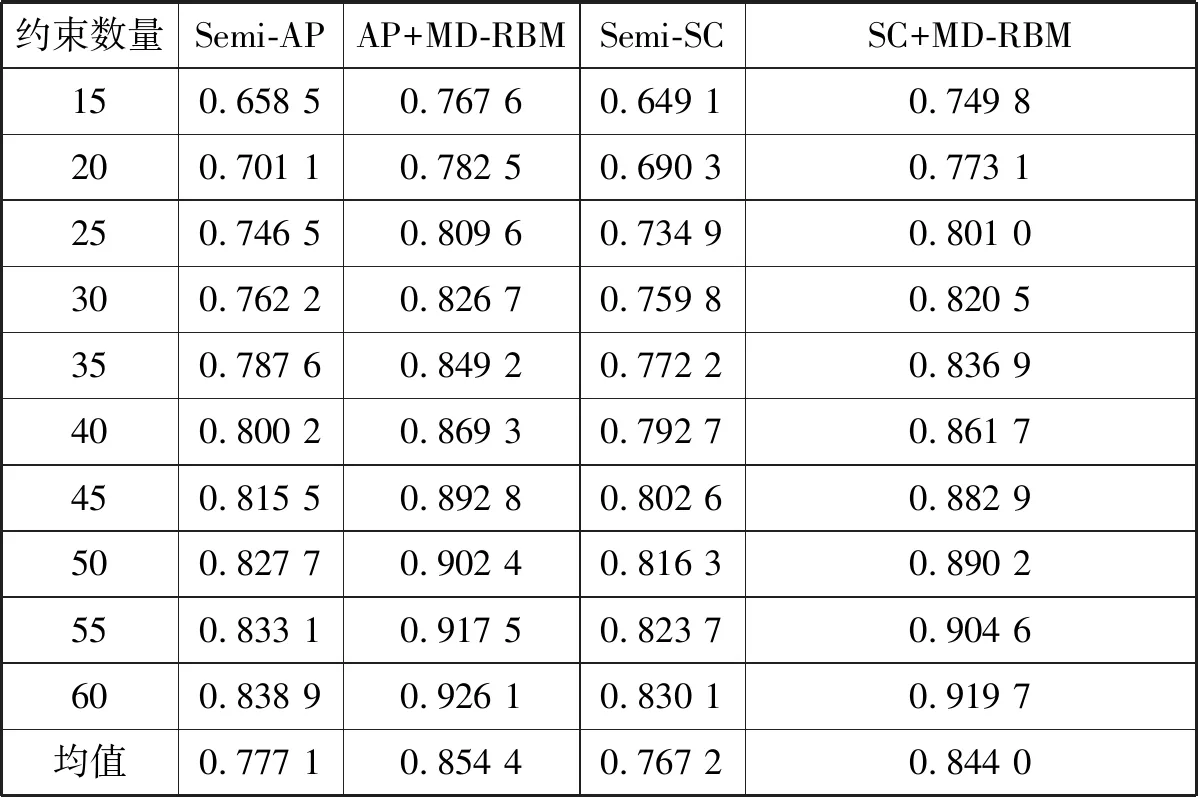
表4 Semi-AP、 Semi-SC半监督算法与AP+MD-RBM、SC+MD-RBM算法Purity指标性能比较(约束数量从15逐步增加到60)
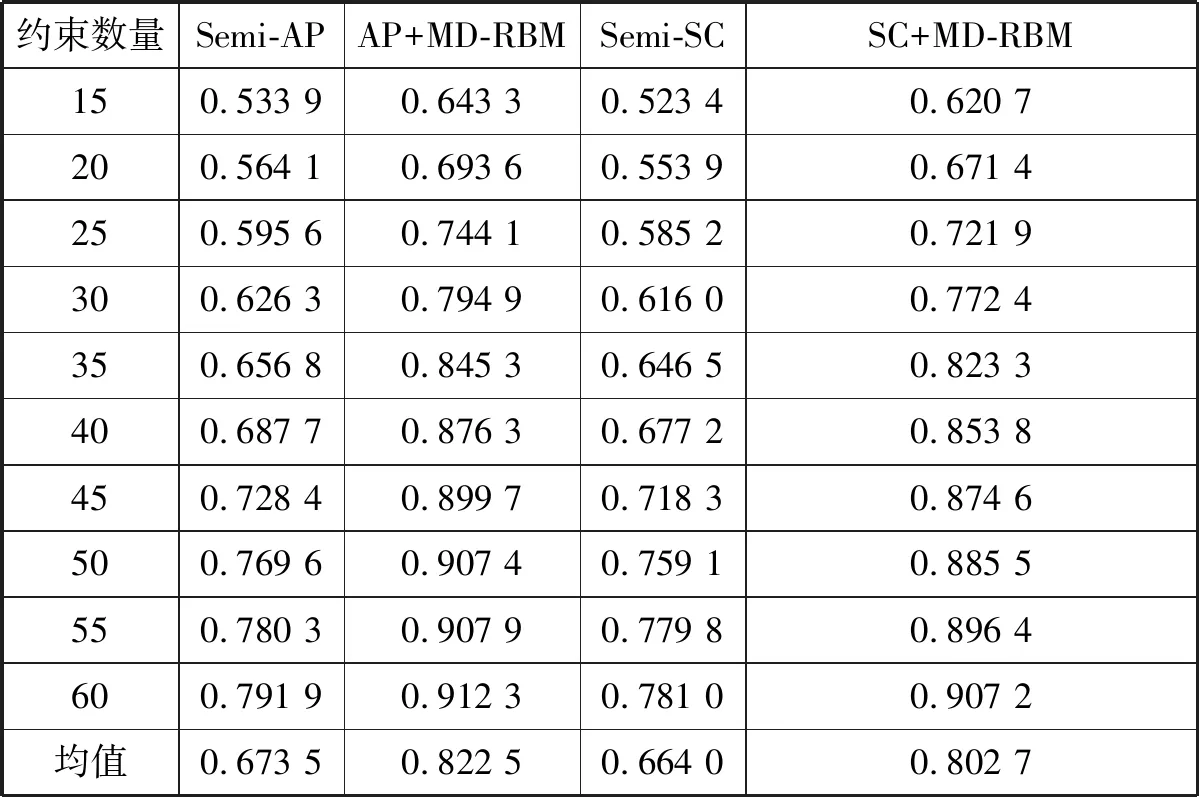
表5 Semi-AP、 Semi-SC半监督算法与AP+MD-RBM、SC+MD-RBM算法Rand Index指标性能比较(约束数量从15逐步增加到60)
为了更加直观地对比实验结果,图4-图6分别描绘出了基于MD-RBM算法与传统半监督算法正确率、purity和Rand Index三个评价指标的对比结果。很显然,三个评价指标都随着成对约束数量(从15到60)增加而不断提升。
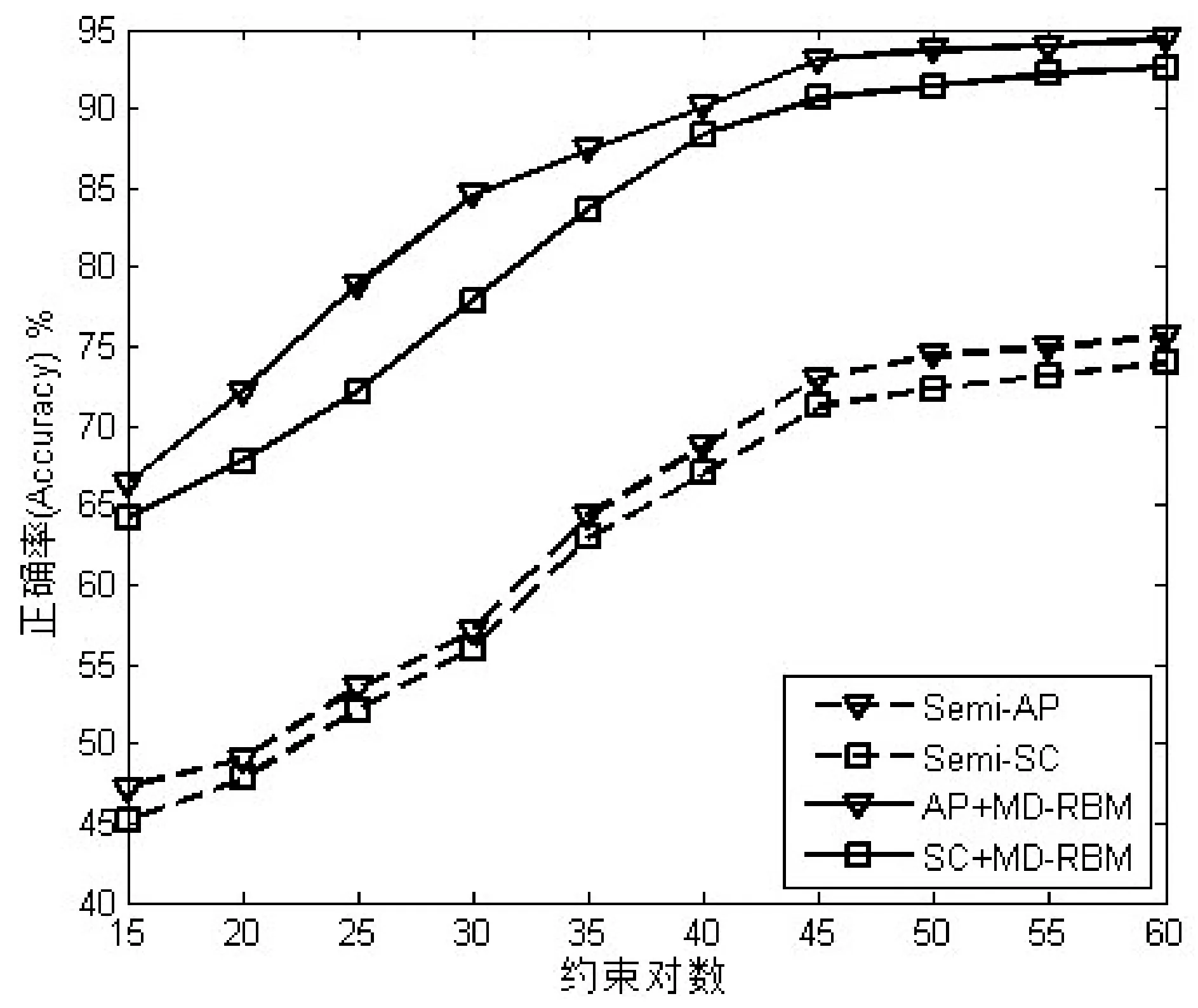
图4 基于MD-RBM算法与传统半监督算法正确率对比
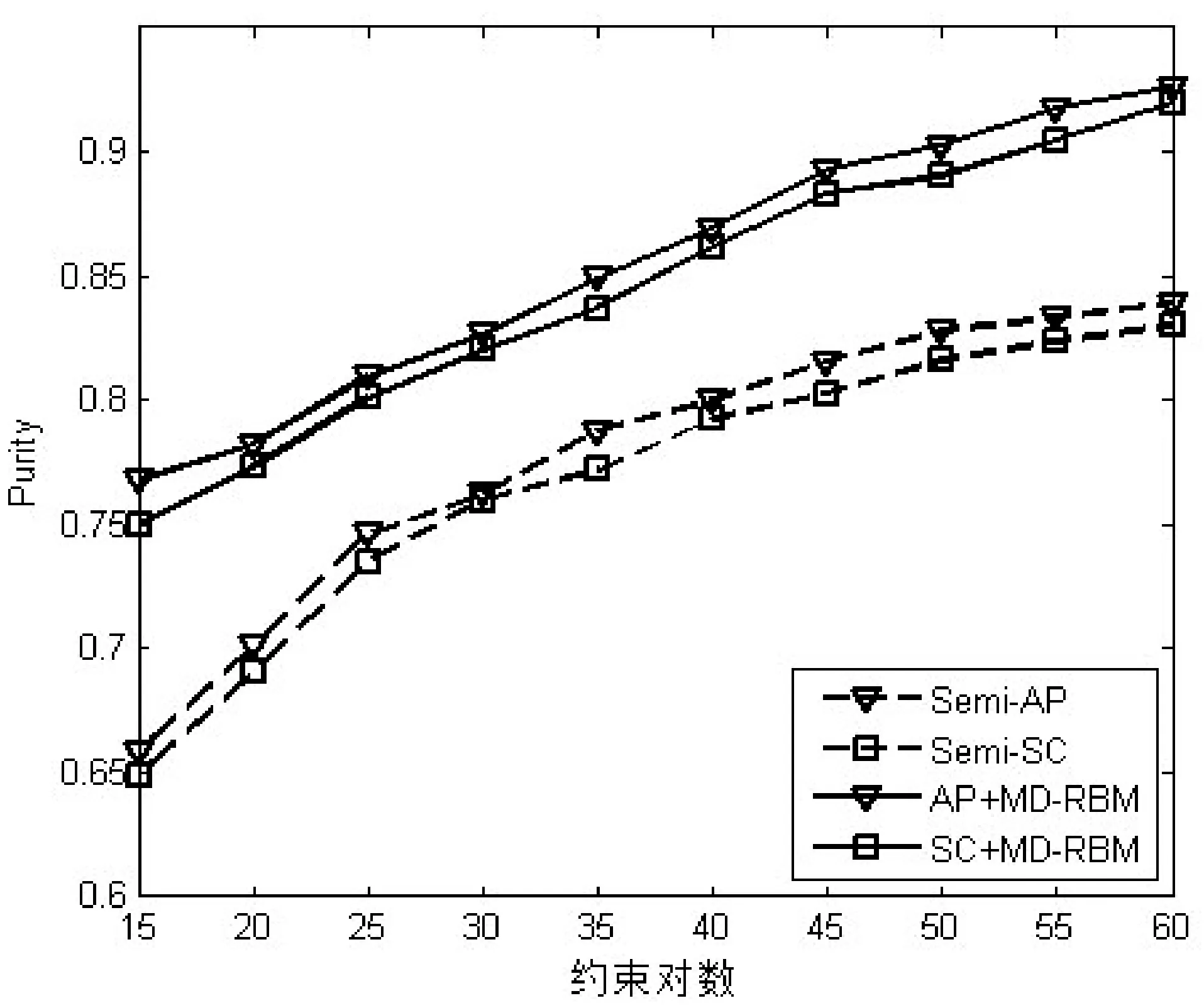
图5 基于MD-RBM算法与传统半监督算法Purity对比
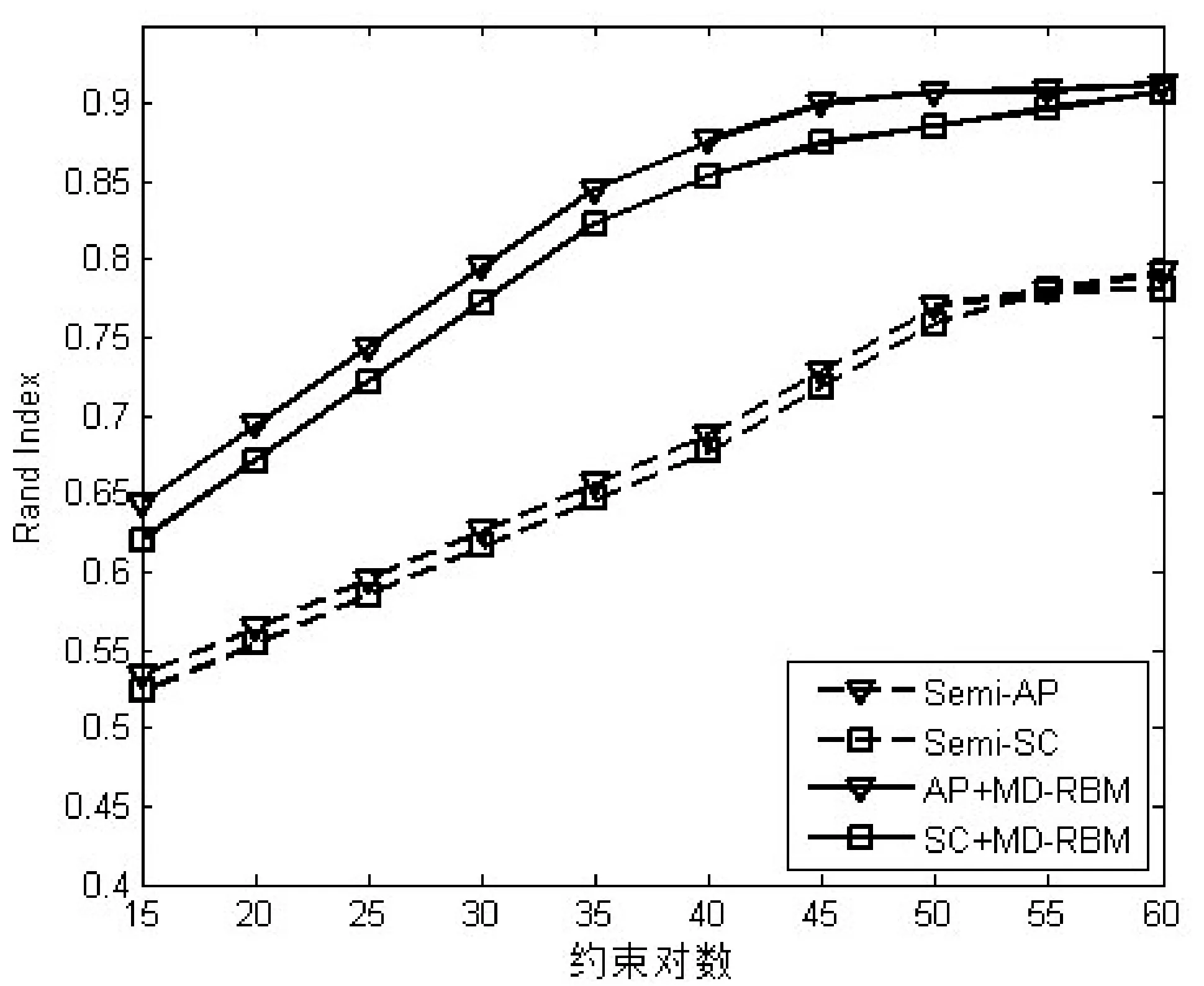
图6 基于MD-RBM算法与传统半监督算法Rand Index对比
传统的RBM神经网络模型和本文提出的MD-RBM模型都具有很强的特征学习能力,因此,有必要通过实验来对比两种模型特性学习能力的性能。从表1-表5可以看出,对于三种评价指标(正确率,purity和Rand Index),基于MD-RBM模型的两个算法都优于基于传统的RBM模型的算法,正确率分别提升了42.96%和42.08%;purity分别增加了0.206 5和0.204 7;Rand Index指数分别增加了0.288 4和0.273 5。
另外,为了使得对比结果更加直观,图7-图9包含了MD-RBM模型和传统RBM模型性能对比。结果显示,本文提出的MD-RBM模型在超高碳钢微结构高维图像的聚类识别任务中比传统的RBM模型表现的更加优异。

图7 基于MD-RBM模型算法与传统无监督算法、半监督算法以及基于RBM模型算法平均正确率(Accuracy)对比
5 结 语
本文在传统的RBM神经网络模型基础上提出了一个新的MD-RBM模型,在编码过程中采用成对约束信息引导,使得一部分微结构图像数据隐藏层编码聚集到一起,一部分微结构图像数据隐藏层编码更加分散,在计算数据对之间的距离时采用了乘积距离(MD)代替欧式距离,使得高维数据的距离更加稳定。在超高碳钢微结构(UHCS)数据集上的实验表明,本文的MD-RBM模型学习到的特征用于聚类识别效果优于传统的AP和SC算法,同时也优于传统的半监督聚类算法Semi-AP和Semi-SC。因此,在超高碳钢微结构(UHCS)聚类识别任务上,MD-RBM模型比传统的RBM模型表现出更好的性能。
DOI:10.1109/TCYB.2018.286360.
