基于Hadoop的数据分析系统设计
2019-06-15贠佩晁玉蓉樊华崔超飞陈伟
贠佩 晁玉蓉 樊华 崔超飞 陈伟

摘要:Hadoop是一个分布式开源计算平台,它以分布式文件系统HDFS和MapReduce为核心,为用户提供系统底层细节透明的分布式基础架构。HDFS为分布式文件系统提供存储环境,而MapReduce为分布式数据提供运算环境。其特点是高可靠性、高扩展性、高效性、高容错性。
关键词:Hadoop;HDFS;MapReduce
中图分类号:TP311.13 文献标识码:A 文章编号:1007-9416(2019)03-0180-01
在巨量数据中,迅捷、快速地从数据中挖掘出有价值的信息并将其转化为决策的依据,将成为企业未来依据的关键因素。数据分析的重要性不言而喻,但随着数据量的突飞猛进,数据处理中遇到难题也更加突出。如何从巨大的数据中提取有价值的信息,并分析深层寓意,进而实现可行性,已经成为互联网处理的重要问题。
1 Hadoop
Hadoop是一个可靠的分布式共享存储系统,HDFS用于数据的存储,MapReduce用于数据分析和处理。HDFS运行于集群之上,以流式数据存储超大文件;MapReduce是分布式数据处理模型和运行环境。
1.1 HDFS架构
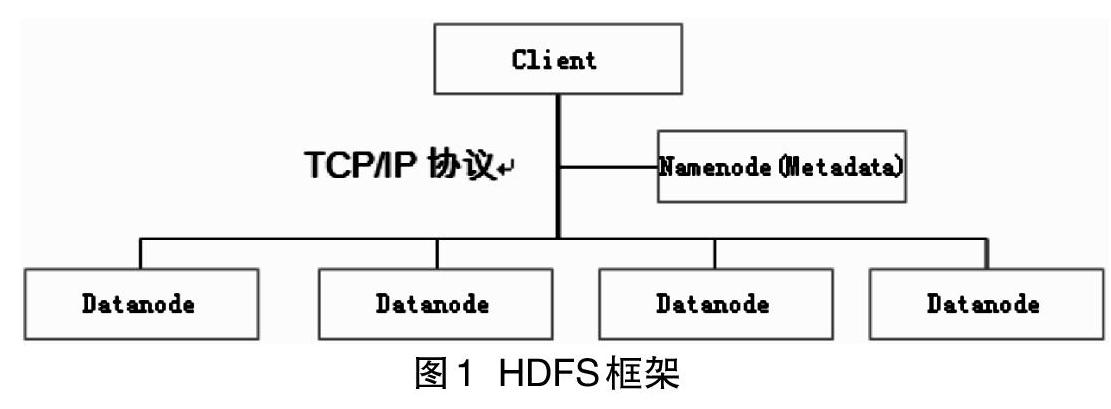
HDFS的框架采用主从架构,是由一个NameNode和多个DataNode组成。NameNode是中心节点,负责对客户端文件的访问和文件名字空间的管理。DataNode是一般节点,负责处理文件系统客户端的读写请求和管理节点上的存储,结构图如图1所示。
1.2 MapReduce架构
MapReduce包括一个主节点,多个子节点共同组成。客户程序负责输入/输出,通过抽象的接口实现map和reduce,与其他参数共同构成整体配置。应用MapReduce的程序能够运行在大型商用机集群,提供可靠容错的并行处理级别的数据,结构图如图2所示。
2 Hadoop数据分析系统的设计
采用实时Scribe收集各个Datenode节点上数据,数据采集完毕后,写入到分布式HDFS,HDFS以流式数据的访问模式存储超大文件,MapReduce计算分析数据且HDFS以MapReduce提供底层文件系统的支撑。处理步骤如下:
(1)根据输入数据的键值对,传送到Mapper类的map函数。(2)map输出键值对到缓冲内存。(3)Reduce获取Mapper记录,产生另外键值对,输出到HDFS中。
数据分析任务由集群来进行计算,将产生结果存入HBase进行可视化展示,由web服务器采用相应的接口进行调用,采用由Thrift的接口对HBase进行访问。
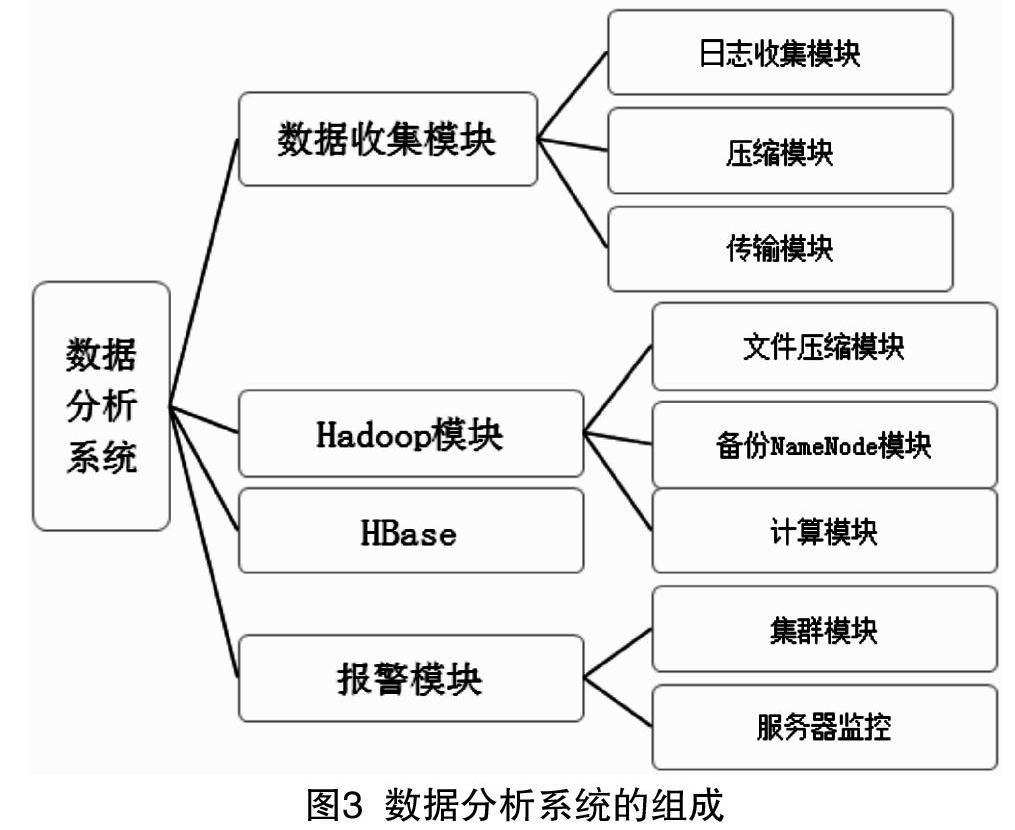
整个数据分析系统分别由数据收集模块,Hadoop模块、HBase模块和报警模块来构成,具体结构如图3所示。
3 结语
根据海量数据处理中的问题,设计了基于Hadoop数据分析系统。系统从底层数据采集、数据存储和计算、数据分析、系统监控等方面提供对Scirbe和Hadoop集群指标(IO、Load)实时监控的执行,减轻了集群人员的压力。
参考文献
[1] Tom Wbite著.Hadoop权威指南[M].清华大学出版社,2011.
[2] 朱珠.基于Hadoop的海量數据处理模型的研究和应用[D].北京:北京邮电大学图书馆,2007.
[3] 张华强.关系型数据库与NoSQL数据库[J].电脑知识与技术,2011,7(20):4802-4804.
[4] 许春玲,张广泉.分布式文件系统Hadoop HDFS与传统文件系统Linux FS的比较分析[J].苏州大学学报,2010,30(4):5-9+19.
[5] 张建勋,古志民.云计算研究进展综述[J].计算机应用研究,2010,27(2):429-433.
[6] 范波.基于MapReduce的结构化查询机制的设计与实现[D].成都:电子科技大学图书馆,2011.
Data Analysis System Based on Hadoop
YUN Pei,CHAO Yu-rong,FAN Hua,CUI Chao-fei,CHEN Wei
(Xianyang Normal University,Xianyang Shaanxi 712000)
Abstract:Hadoop is actually a concrete implementation of a distributed file system. The core design of Hadoop's architecture is HDFS and MapReduce. HDFS provides storage for massive data, while MapReduce provides computation for massive data. HDFS features high fault tolerance, high throughput, large data sets and low hardware cost.
Key words:Hadoop; HDFS;MapReduce
