基于深度卷积网络的遥感影像建筑物分割方法
2019-06-14龙慧云
余 威,龙慧云
(贵州大学 计算机科学与技术学院,贵州 贵阳 550025)
1 概 述
遥感影像目标识别作为当前遥感影像应用领域中的主要研究内容,具有重要的理论研究意义和广泛的应用价值[1]。以城市区域的高分辨率遥感影像为例,大部分识别目标是建筑物、道路和桥梁等人工地物,这些目标的有效识别和精确定位一直以来都是急需解决的问题。而这其中的遥感影像建筑物识别在民用领域和军事领域都有较为重要的意义,为灾害应急和生产生活提供便利。
近年来,传统计算机视觉技术进行高分辨率遥感影像地面建筑物识别提取主要是利用建筑物的多边形形状信息、颜色和纹理特征[2],随后使用传统机器学习分类算法(例如AdaBoost、支持向量机、随机森林等)对这些特征进行分类,并完成建筑物的提取[3-5]。但是真实环境下,城市建筑物有着复杂多变的纹理和颜色,以及会受到阴影的遮挡,这些因素使上述算法在复杂的建筑物提取场景下处理能力不足[6]。
从遥感影像中进行建筑物识别,在计算机视觉领域中被认为是语义分割问题,语义分割是通过一定的方法,将整幅图像分割成具有一定语义含义的区域块,并识别出每个语义块的类别,实现从底层到高层语义的推断过程[7]。最终得到一幅逐像素语义标注的分割图像。建筑物分割是一种二分类的语义分割,分割后得到建筑物区域和非建筑物区域。
卷积神经网络(CNN)作为计算机视觉任务上成功的监督分类方法,将其应用在图像语义分割上有以下两个问题:一是输出结果相对输入分辨率降低,影响最终的分类精度;二是忽略了上下文信息。图像中物体之间存在局部上下文关系以及物体与图像之间存在全局上下文关系,CNN模型会将这些信息忽略。为了解决这些问题,Jonathan Long等提出了Fully Convolutional Networks (FCN)[8];Zheng等[9]将卷积神经网络的输出作为全连接条件随机场(full connected CRF)的输入,提高了语义分割准确率。此外,还有一些跳越连接(skip-connections)网络结构[8,10-11],膨胀卷积(dilated convolutions)网络结构[12]能在一定程度上提高整体分割准确率。虽然这些方法在处理自然图像时性能较好,但是它们并不太适合处理遥感影像。因为高分辨率遥感影像每张影像包含成百上千的建筑物目标,并且在影像中建筑物结构精细,这些都与自然图像不同。但是可以借鉴自然图像语义分割思路,结合不同网络模型优点,研究一种对复杂场景具有较强鲁棒性的遥感影像建筑物分割方法。
因此,文中构建了两种端对端的全卷积神经网络结构,并将其应用在遥感影像建筑物分割上。此外,重新设计结合交叉熵损失函数和Jaccard index的联合损失函数,用以提高遥感影像建筑物分割精度。受ImageNet竞赛集成方法[13-14]的启发,文中提出融合两种模型的遥感影像建筑物分割方法来提高整体分割精度。
2 端对端全卷积网络模型
在高分辨率的遥感影像中,一张图往往包含成千上万个像元,这使得图像占用很大的存储空间。由于计算机硬件的限制,只能对一整张图像进行分块预测,再对预测图进行拼接恢复。直接的预测拼接会有很明显的拼接痕迹,影响建筑物的分割精度。解决这一问题的方式是在重叠的图像块上进行预测。文中提出在模型中加入剪裁层的方式来解决这个问题,两种端对端的模型均是基于此思想。即:
p(N(M(i,j),wm)|N(S(i,j),ws))
(1)
其中,N(I(i,j),w)表示在图像I上以(i,j)为中心,大小为w*w的图像块。将给定大小为ws*ws的遥感影像输入模型,经模型预测得到大小为wm*wm的预测(wm 典型FCN模型通过转置卷积一次性将底层特征图恢复成原图大小,致使模型分割精度不高。与FCN不同的是,编解码网络逐级通过卷积和上采样恢复图像分辨率,这样模型能保留更多细节特征。整个网络模型的结构[10]如图 1所示。 图1 编解码分割网络结构 大小为128×128像素的图像作为网络输入。在网络编码部分,使用VGG16结构进行特征提取,五个卷积结构部分分别由64个、128个、256个、512个和512个3×3的卷积核进行特征提取,紧随其后的是2×2的最大池化层。在解码部分,分别由五个2×2的上采样层通过双线性插值进行分辨率还原。根据式1,加入剪裁层,将128×128的特征图剪裁至80×80大小。在最后一层使用卷积核大小为1×1的卷积层。由于目标输出是建筑物和非建筑物两类,采用Sigmoid函数得到最终的二类输出,最终的输出是输入数据在两种语义类别上出现的概率。最后设置一个最佳阈值,形成分割掩码图像。这里,将两个池化层或者两个上采样层之间的结构称为一个卷积结构。 U-Net网络[11]与编解码网络模型结构不同的是,它将包含上下文信息的低层级的特征图和包含图像细节的高层级的特征图结合起来,实现了分割的精确定位。具体结构图和各特征图维度如图2所示。 输入网络中的是3维的RBG遥感影像,大小为112×112像素,通过滑动窗口选取像素块。在对图像进行卷积(卷积核大小为3×3)后进行批量正则化(batch normalization)操作,让图像像素值的均值为0并且方差为1,加速网络收敛速度。紧接着采用ELU非线性激活函数。下采样操作采用max-pooling来降低特征图分辨率。在上采样阶段,使用Concat连接层将包含上下文信息的低层级的特征图和包含图像细节的高层级的特征图结合起来。最后将剪裁得到的特征输入到Sigmoid层,通过反向传播进行训练。 图2 U-Net分割网络结构 上述两个模型的损失函数采用与Sigmoid函数对应的Binary Cross Entropy函数,并通过负对数,将输出的概率值从最大化概率变成最小化信息熵。其表达式如下: ③对汉江堤防、航运等方面造成一定的负面影响。调水后枯水期延长,流量变化造成河势多变,使得堤防的重点位置发生转移。河堤基脚长期显露,防守将更加被动,同时清水下泄严重危及堤防安全。此外,调水后汉江中下游航道水深下降,航道宽度和弯曲半径发生变化,河漫滩增大,致使内河航运能力大大下降。 (2) 此外,为了使建筑物分割任务有更高的精度,在二进制交叉熵损失函数中加入IOU公式,形成联合损失函数。最终两个模型的损失函数如下: L=H-logJm (3) (4) 受模型融合方法的启发,将两种模型的预测结果通过加权的方式融合,即保留编解码分割网络对大建筑物的分割提取,也保留了U-Net分割网络在小型建筑物上的精确分割。结合式1,模型预测融合的公式如下: P=α*pe+β*pu,α+β=1 (5) 其中,pe为编解码网络的预测结果;pu为U-Net网络的预测结果。 模型融合流程如图3所示。在输入的影像中以给定点为中心,分别提取尺度大小为1122px和1282px的影像块,分别送入两个模型中进行预测,经过模型运算后得到大小为802px的预测结果,最后对预测结果按照上述公式进行加权叠加得到最终的分割掩码图像。实验表明,当α=0.45,β=0.55时,融合模型能取得最好结果。 图3 模型融合流程 本次实验的数据集[15]来自法国国家信息与自动化研究所(Inria),该数据集包含来自美国和澳大利亚不同城市居民区上空的遥感影像,它们被标注为建筑物和非建筑物两类。与一般数据集不同的是,该数据集的训练样本和测试样本按影像所属地区划分,而不是将同一地区的不同区域分别划分为训练样本和测试样本。也就是说,用来自Chicago的训练数据得到的分类器可以用来预测San Francisco的数据,旨在提高模型的泛化能力。该数据集的航空正射校正影像的空间分辨率是0.3 m,具体信息如图4所示。 图4 数据集样本统计(每张图大小为5 0002px) (6) (7) 对于所提出的两种模型,使用Inria数据集中的180幅高分辨率影像及其对应的语义标注图进行学习。首先,从180幅影像中随机切割出144块大小为128×128像素的图像块,并随机进行图像的水平、竖直或者镜像翻转,组成维度为144×128×128的图像斑块作为编解码分割网络的输入。在一次迭代的过程中,使用5 000批上述维度图像斑块进行网络参数的批量梯度下降学习,共进行25轮迭代。对于U-Net分割网络模型,在25轮迭代过程中,使用维度为64×128×128的图像斑块作为模型输入,每轮迭代使用8 000批图像斑块进行训练。在两个模型中,使用Nadam优化器以初始学习率0.001进行网络参数学习。完成学习后,使用test time augmentation对测试集中180幅影像进行预测,每张影像分别进行水平旋转预测、竖直翻转预测、镜像翻转预测和直接预测,将预测得到的四幅图像复原后,取各图像像素值的平均值,并以0.5的预测阈值得到最终的二分类分割图像。最后,将得到预测的语义分割图与对应Ground Truth进行比对,分别得到每个地区的建筑物分割精度和IOU。 本次实验是基于Keras深度神经网络框架,使用单张12 GB GTX TitanX显卡完成模型的训练。模型训练结束后,给出模型在测试集上三个不同区域上的样例结果。两个模型预测结果和模型融合的预测结果如图5所示。图中从上到下分别是RGB遥感影像、Ground Truth、编解码网络、U-Net网络和模型融合的结果。可以看出,编解码网络能更好地识别和提取大型建筑物的轮廓,而U-Net网络由于结合了高低层级特征图,能更好地提取建筑物的边缘细节和小型建筑物轮廓。模型融合很好地结合了二者优点。同时在结果上出现了小面积的false positive(将非建筑物识别为建筑物)和false negative(无法识别建筑物区域)。 (a)RGB输入图 (b)Ground Truth (c)ED-Net结果 (d)U-Net结果 (e)融合结果 表1给出了三个模型在测试集上的定量化结果,按照区域显示预测精度和IOU,并求取区域预测的结果的平均值作为最后的预测结果。从表中可以看出,模型融合在测试集上的整体结果相对U-Net有了近似2%的提升,达到了70.08%,也就是说预测区域的面积覆盖了真实区域面积的70%。对于特定地区,例如Bloomington,IOU指数有3.46%的提升。 表1 模型在测试集上的定量评估结果 文中设计和实现了两种基于高分辨率遥感影像的建筑物语义分割模型,进行了模型融合,并通过实验对模型进行了验证和分析。实验结果表明,由于输入编解码分割网络的图像斑块尺度较大,包含更多的上下文细节,使得编解码网络能更好地提取大型建筑物的轮廓。而U-Net网络,结合了高层级的图像细节特征,对于小型建筑的特征更加敏感。模型融合结合了二者优点,在建筑物分割测试集上可以获得更加令人满意的语义分割结果。2.1 编解码分割网络模型(ED-Net)

2.2 U-Net分割网络模型

2.3 损失函数及模型融合




3 实 验
3.1 实验数据



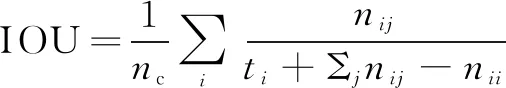
3.2 实验设计
3.3 实验结果






4 结束语
