基于AdaBoost的潜射防鱼雷诱饵干扰效果预测研究
2019-06-13范学满
范学满,张 会
(海军潜艇学院,山东 青岛 266199)
对于潜艇而言,其威胁主要来自于自导、线导等重型鱼雷以及空投、火箭助飞、舰艇管装等轻型鱼雷。自航式声诱饵不仅能够模拟潜艇的辐射噪声特性和声反射特性,还能模拟潜艇的运动特性,对鱼雷具有很强的欺骗性,已成为潜艇防御声自导鱼雷的主要手段之一[1]。潜艇发射自航式声诱饵后,根据本艇、鱼雷和诱饵的实时态势准确预判鱼雷能够发现本艇,对本艇下一步战术决策影响重大。
本文以离线仿真数据作为训练样本集,利用机器学习构建诱饵干扰效果的在线预测模型。考虑到单一分类器在精度和泛化能力方面的不足,本文采用典型的集成学习[2]算法——AdaBoost[3],综合利用多个基分类器提升预测性能。目前,AdaBoost在机械故障诊断[4]、发电系统孤岛检测[5]和步态识别[6]等多个领域取得成功的应用,但AdaBoost通常采用均匀分布的方式进行样本权重初始化,这并不适应于本文这类不均衡分类问题。为此,本文为AdaBoost引入数据预处理操作,专门进行样本权重初始化,从而降低类别不均衡对AdaBoost性能的影响。在基分类器选择方面,为了保证模型的可解释性,以REPTree决策树[7]作为基学习算法。基于离线仿真数据寻优确定了预测模型的参数,进行交叉校验实验验证了预测模型的有效性。
1 诱饵干扰效果预测数据集
潜艇的鱼雷防御方案可表示为四元组(αm,αy1,ty1,αy2),其中,αm、αy1、ty1、αy2分别为潜艇转向角,诱饵的第一次转向角、第一段直航时间和第二次转向角。防御过程为:潜艇鱼雷报警后立即发射诱饵,并转向αm角度规避,诱饵出水后首先转向αy1角度,然后直航ty1时间,然后再转向αy2角度,然后再直航至航程终了。
使用安全余量作为效能和方案优化指标。安全余量分为瞬时安全余量和过程安全余量两种。瞬时安全余量定义为

(1)
式中,M为潜艇位置点,C为鱼雷搜索扇面,d(M,C)为点M到扇面C的距离。过程安全余量定义为整个过程中安全余量的最小值。
潜艇规避成功当且仅当整个规避过程的安全余量大于0。进而根据潜艇、诱饵和鱼雷的运动控制逻辑,建立计算潜艇使用自航式声诱饵防御鱼雷效果的多实体有限状态机模型。利用该模型可仿真得到不同相对态势下诱饵的干扰效果。
在机器学习领域,根据本艇、诱饵和鱼雷的相对态势,预测诱饵的干扰效果即鱼雷能否发现本艇,是一个典型的二分类问题。本艇、诱饵和鱼雷的相对态势可以归纳为本艇到鱼雷的距离Dts、本艇相对诱饵的舷角φds、诱饵相对本艇的舷角φsd、鱼雷到诱饵的距离Ddt和鱼雷相对诱饵的舷角φdt这5个特征参数,构成5维特征向量x,表示一个样本。y∈{-1,1}表示样本x的真实类标签,其中,-1代表诱饵发挥了诱骗效果,鱼雷没有发现本艇;1代表诱饵未发挥诱骗效果,鱼雷发现本艇。
仿真中,Dts,φds,φsd,Ddt,φdt分别均匀地取10个值,共仿真生成105个样本,作为诱饵干扰效果预测数据集。其中,真实类标签为-1的样本19527个,真实类标签为1的样本80473个。
2 基于AdaBoost的预测模型
AdaBoost是集成学习领域处理分类问题的重要工具,可以集成多个基分类器的优势,提升整体的准确率和泛化性能。本文将AdaBoost用于预测本艇发射诱饵后,鱼雷能否发现本艇。构建AdaBoost模型通常包括数据预处理、基分类器选取和基分类器集成3个步骤。
2.1 数据预处理
X={x1,x2,…,xN}为样本集,N=105为样本总数,类标签y=-1的样本数N0=19 527,类标签y=1的样本数N1=80 473,类别比例ρ=N1/N0≈4.12。一般而言,如果类别不平衡比例超过4∶1,那么分类器性能会因数据不平衡而受到影响。因此,在构建分类器之前,需要对类别不平衡问题进行处理[8]。


(2)
式中,w0、w1分别为类别-1和类别1的样本权重;N0、N1分别为类别-1和类别1的样本数。
将N0=19 527、N1=80 473代入式(2),得w0≈2.56e-5、w1≈6.21e-6。
2.2 基分类器的选择
根据稳定性可将分类算法分为稳定和不稳定分类算法两类。其中,稳定分类算法是指当训练集发生较小变化时,训练所得分类器不会发生较大变化。不稳定分类算法是指当训练集发生较小变化时,训练所得分类器会发生明显变化。常见的分类算法中支持向量机、k最近邻法属于稳定分类算法,决策树和神经网络属于不稳定分类算法[9]。为了保证基分类器集合的多样性,AdaBoost集成学习中通常选用不稳定分类算法,另外考虑到决策树相对神经网络具有可解释性的优势,本文在后续集成分类器的构建过程中均采用Weka中的错误率降低剪枝决策树REPTree作为基分类算法[10]。
下面基于P2数据集[11]进行实验,验证REPTree的不稳定性和剪枝技术的重要性。P2问题是个二分类问题,两个类分别定义在由多项式和三角函数分割开的多个决策区域上,这些函数定义如下:
(3)
如图1(a)所示,类别1由五个区域组成,类别2由三个区域组成,两个类别对应的区域面积近似相等。生成一个包含900个样本的原始数据集,其中类别1包含452个样本,类别2包含448个样本。将原始数据集随机划分为等大的两部分,分别记为训练集和测试集。在训练集中添加15%类别噪声数据,添加噪声后的数据集如图1(b)所示。

图1 P2问题
基于添加噪声后的训练集,通过有放回采样生成4个等大小但不相同的子训练集;利用这些子训练集,训练出4个未剪枝的决策树分类器和4个REPTree分类器,并基于测试集分别评估它们的泛化分类错误率。8个决策树的决策边界以及分类错误率如图2、图3所示。可见无论是否剪枝,基于不同训练子集生成的决策树的分类边界都有明显差异,证明了决策树分类算法的不稳定性。对比图2和图3可以发现,未剪枝决策树的分类错误率都高于对应的REPTree的分类错误率,说明通过剪枝的确能提升决策树的泛化能力。另外,当训练集存在噪声时,训练所得的未剪枝决策树的决策边界会出现多个“孤岛”,相比之下REPTree的决策边界与真实边界的偏差较小,对噪声表现出更强的鲁棒性。综上所述,本文选取剪枝REPTree作为基分类器。

图2 未剪枝决策树分类边界和错误率
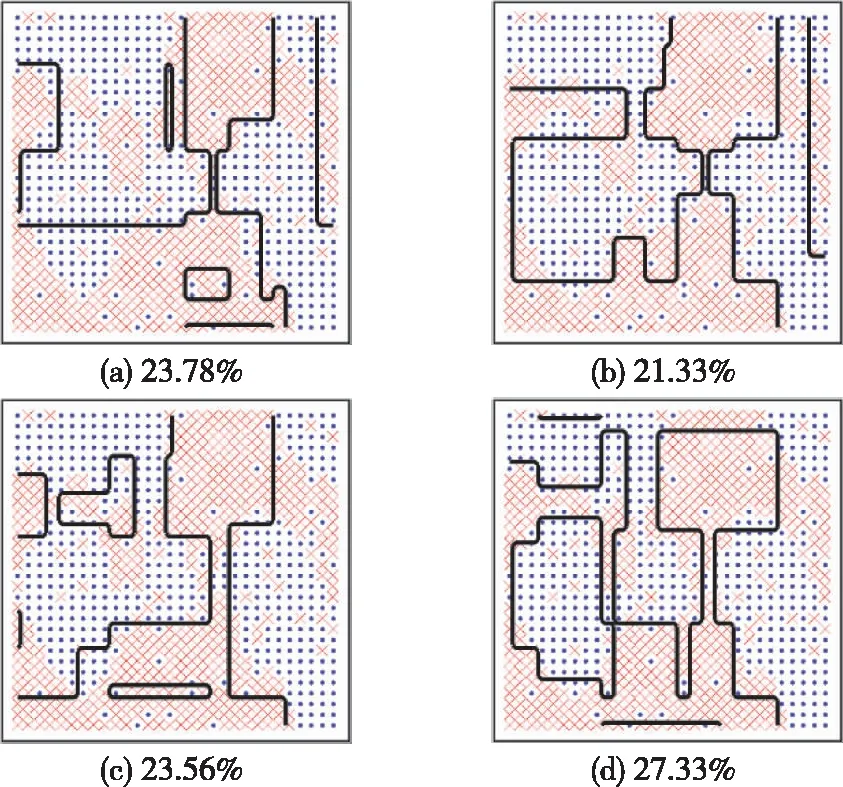
图3 REPTree的分类边界和错误率
2.3 AdaBoost集成
AdaBoost是boosting算法的改进,全称是自适应增强算法,其自适应体现在:前一个基分类器错误分类的样本权重会增大,而正确分类的样本的权重会减小,加权后的新样本继续用来训练下一个基分类器。同时,在每一轮迭代中,加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数,才通过加权集成确定最终的强分类器[12]。
总体上,AdaBoost集成主要分为3步:1)初始化样本集权重;2)自适应训练多个弱分类器;3)将多个弱分类器集成为强分类器。整个建模过程如图4所示。

图4 AdaBoost示意图
AdaBoost的算法流程如下:
1)按照上文的方法初始化训练数据的权重分布,此时
D1=(w1,1,w1,1,…,w1,N0,w1,N0+1,…,w1,N)=
(w0,w0,…,w0,w1,…,w1)
(4)
式中,wt,i为第t次迭代时第i个样本的权重;w0≈2.56e-5、w1≈6.21e-6。
2)进行迭代t=1,2,…,T
① 利用权重分布为Dt的样本集训练得弱分类器ht,并计算ht的再代入分类错误率et:
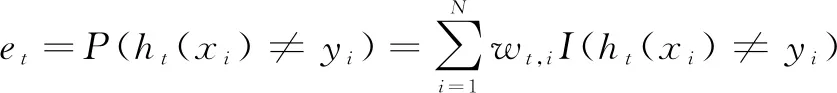
(5)
式中,ht(xi)为ht在样本xi的预测类标签;yt为样本xi的真实类标签。
② 计算ht在最终集成分类器中所占权重at:
(6)
③ 更新训练样本集的权重分布Dt+1:

(7)
式中,Zt为归一化常数。
3)将T个弱分类器按照权重at集成为一个强分类器:
(8)
式中,sign(·)为符号函数。
3 实验
基于离线仿真数据进行诱饵干扰效果实时预测有两种思路,一种是直接存储数据,通过查询确定结果;另一种是存储从数据挖掘出的数学模型,利用模型进行预测。第一种思路,受限于存储空间和泛化能力,很难得到实际应用,本文所采用的是第二种思路。本文实验主要包括三方面内容:首先,研究迭代次数AdaBoost分类性能的影响;然后,通过与常用机器学习算法对比验证AdaBoost的有效性;最后,在保证训练误差为0的前提下,使模型尽可能精简,确定AdaBoost的参数,构建最终的预测模型。实验在IntelliJ IDEA平台上利用Java调用Weka API混合编程实现。
3.1 迭代次数对AdaBoost分类性能的影响
AdaBoost集成的基分类器个数取决于迭代次数T,因此有必要研究迭代次数对AdaBoost分类性能的影响。基于离线仿真数据集进行5折交叉校验,研究训练误差和测试误差随迭代次数T的变化。具体操作是,将原始数据集随机分为等大的5份,轮流将其中4份作为训练集,剩下1份作为测试集,每轮得到一组训练误差和测试误差,取5次预测结果的均值作为模型预测效果的估值。实验中将REPTree设置为剪枝、不限层数,其余参数采用Weka默认值。实验结果如图5所示。

图5 迭代次数T对分类正确率Pc的影响
由图5可见,随着迭代次数即基分类器个数的增加,AdaBoost集成模型在训练集和测试集上的分类正确率,总体上都呈现出先迅速上升后趋于稳定的变化趋势。当基分类器个数达到10个时,集成模型在训练集上的分类正确率达到100%,随后一直保持100%不变;集成模型在测试集上的分类正确率也不再有明显变化,上下稍有波动趋于稳定。综合考虑集成模型在测试集和训练集上的分类性能,本文取AdaBoost得迭代次数为10,即AdaBoost由10个REPTree集成得到。
3.2 AdaBoost有效性验证
将AdaBoost与典型的分类算法k最近邻(kNearest Neighbor,kNN)、支持向量机(Support Vector Machine,SVM),典型集成算法Bagging以及单个REPTree进行对比实验,实验中的k取3,Bagging与AdaBoost均以10个剪枝REPTree作为基分类器,其余参数采用weka中的默认设置。进行10折交叉校验实验,利用测试正确率衡量算法的泛化能力,结果如图6所示。可见,SVM的泛化能力明显不及另外4种算法,因此重点观察另外4种算法的实验结果,如图7所示。
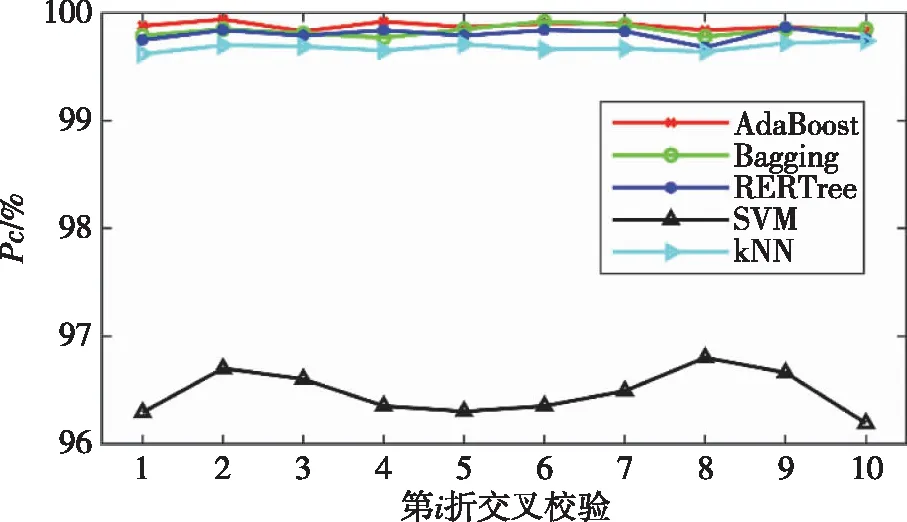
图6 5种算法的对比实验结果
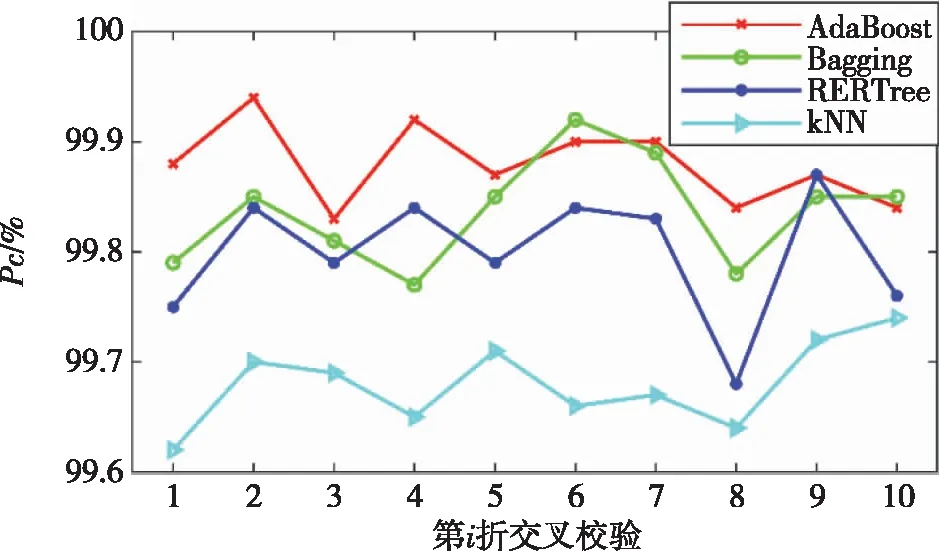
图7 4种算法的对比实验结果
由图6和图7可见,就5种算法的泛化能力而言,总体上AdaBoost>Bagging>REPTree>kNN>SVM,另外5种算法10折交叉校验的平均分类正确率99.879%(AdaBoost)>99.836%(Bagging)>99.799%(REPTree)>99.680%(kNN)>96.473%(SVM)进一步验证了AdaBoost的泛化能力最强。
3.3 预测模型最终参数确定
在上文中确定了AdaBoost的基分类器个数为10,同时要求REPTree采取剪枝策略,但对各REPTree的层数并没有限制。REPTree的层数是影响AdaBoost集成预测效率的重要因素,同时层数过多也会造成过拟合影响集成模型的泛化能力,因此在保证分类正确率的前提下应尽可能减少REPTree的层数。基于离线仿真数据集进行5折交叉校验,研究训练误差和测试误差随REPTree最大深度D的变化,实验结果如图8所示。

图8 REPTree最大深度D对分类正确率Pc的影响
由图8可见,当基分类器的最大深度达到10时,集成模型在训练集上的分类正确率趋于100%,并保持稳定;集成模型在测试集上的分类正确率也趋于稳定。因此本文取REPTree最大深度为10。
综上所述,本文AdaBoost模型的最终参数为:以最大深度为10的剪枝REPTree作为基分类器,基分类器个数为10。基于上述参数,在离线仿真数据全集上训练得到最终的AdaBoost模型,用于潜射诱饵鱼雷干扰效果的预测。
4 结束语
本文采用AdaBoost集成学习将潜射诱饵鱼雷干扰效果预测问题转化为典型的二分类问题,以本艇、诱饵和鱼雷的相对态势作为分类特征,通过离线仿真生成训练数据集,以REPTree作为基分类器,构建了集成预测模型。通过与Bagging、REPTree、Knn、SVM这4种机器学习算法对比,验证了AdaBoost算法的有效性。研究了迭代次数和决策树的最大深度对AdaBoost分类性能的影响,实验结果表明迭代次数和决策树最大深度都取10可以兼顾效率和泛化能力。本文的决策问题虽然只是潜艇作战指挥决策的冰山一角,但集成学习在该问题上的适应性可以推知机器学习等智能算法在潜艇作战智能辅助决策领域的广阔前景。
