基于中文微博语言特征的自杀意念检测
2019-06-11许立鹏宋文爱
许立鹏,宋文爱
(中北大学 软件学院,山西 太原 030051)
0 引 言
自杀已经成为当今世界导致人类死亡的第三大因素. 认识自杀、了解自杀、研究自杀、识别自杀甚至于干预自杀已经刻不容缓. 美国精神卫生专家认为自杀行为可分为自杀意念、自杀未遂和自杀死亡,这三类情况可逐渐发展和重叠[1]. 据世界卫生组织报告,在全球每40 s就有1人死于自杀,而1个人的自杀,可能会影响其6个亲友至少20年. 经报告数据显示,在半个世纪里全球产生自杀行为的人群年龄正逐渐趋于年轻化: 由50年前的30岁左右人群居多到今天的16岁左右. 互联网的飞速发展,催生出了一系列聊天交友平台,如QQ、微信、贴吧、微博、知乎等等. 而患有精神疾病的人们往往羞于在他人面前吐露心声,往往面对他人时伪装自己,在无人的角落里展现最真实的自己. 于是,互联网的发展,为这些患者提供了一个虚拟的“无人角落”,在这里他们发泄自己的情绪,吐露自己的心声,表达自己的意念,研究也表明,那些有自伤史,或自杀风险高的人,他们经常使用互联网来表达自己的自杀行为[2],而且社交媒体数据经常反映用户的情绪状态[3],自然语言处理技术与机器学习的发展,也使得人们可以通过机器实现很多人类完成较为困难的任务,使得通过社交媒体探究自杀意念成为可能.
一部分学者研究了导致自杀的因素,如Karambelas T 在他的文章中说,抑郁是自杀的最大风险因素,自杀意念是抑郁的一种症状,同时文章还提到,抑郁症产生的这些自我伤害行为,像切割(身体)或者燃烧,大多数时候是自杀的前兆[4]; 还有一部分学者研究了这些自杀因素在社交媒体中的表现形式,如Qijin Cheng等通过对中国社交媒体上的用户数据进行研究发现,有自杀行为的用户高频率地使用人称代词、表达计划的词以及多功能词,但是却很少使用动词,研究还发现严重抑郁症患者和有较大压力的人在产生自杀行为时较多地使用第二人称代词[5]; 有一部分学者也会研究如何识别那些有自杀意念的帖子,如Xiaolei Huang等以n-gram特征与心理词典为特征、以支持向量机算法为核心构建机器学习分类模型以识别具有自杀意念的帖子[6].
在最初的自杀意念检测研究中,大多数学者采用n-gram特征工程 + 传统机器学习算法(如支持向量机等)的方式来实现样本的二分类任务,进而实现自杀意念的检测. 但是由于n-gram特征的局限性,模型的准确率比较低,因此为了提升模型的识别准确率,学者们构建了自杀词典,采用n-gram特征 + 自杀词典 + 传统机器学习算法的方式实现自杀意念的检测. 然而由于字典构建的方式的缺陷使得这种提升很有限,如Xiaolei Huang等人构建心理词典,仅仅是以积极词汇和消极词汇为元素构建该词典[6],这就导致该词典元素在表示自杀意念时缺少很多必要的信息,从而不能完全表现出自杀者与正常人在语言上的不同,导致其模型性能的提升并不明显.
因此,本文提出了基于各自杀诱因在社交媒体上的语言表达来构建自杀词典. 该词典适用于各种自杀研究场景,迁移性强,由于其涵盖了大部分的自杀诱因内容,使得模型有较强的泛化性能. 同时,本文还提出了“新”特征 - 词性特征,如第二人称代词等,加入该特征的原因在于有大量的研究表明: 有自杀倾向的人在社交媒体上表达自杀意念时常常使用更多地特定词性,如抑郁症患者在表达自杀意念时通常更多地使用第二人称代词,却很少使用第一人称,因此通过句子中人称代词的使用情况可以更好地区分有自杀意念的样本与无自杀意念的样本.
1 自杀诱因分析及其语言特征
1.1 自杀诱因
在社交媒体中反映其语言特征的自杀诱因如表 1 所示.

表 1 各自杀诱因与自杀意念之间的关系
根据表 1 中的文献可以确定相应的自杀诱因在自杀意念检测中是重要的,且在微博等社交媒体中可以被反映出来.
1.2 自杀诱因的语言特征
下面介绍自杀诱因在社交媒体中的语言特征[32],本文涉及到的语言特征主要包括词汇特征与词性特征,见表 2 和表 3.

表 2 各自杀诱因的部分词性特征

表 3 各自杀诱因的部分词汇表达
续表3:

自杀诱因语言特征(词汇特征)情绪愤怒, 罪恶, 烦恼, 对抗, 不满人格很好, 很开心, 吃惊的, 最好的, 激动的, 派对, 悬挂, 晚餐, 或许, 也许, 焦虑, 不确定, 失控, 愤怒, 绝望, 自我干扰, 行为失控, 情感失控(失调), 脆弱, 怀疑, 疑问, 对立, 恐惧, 抑制, 社会, 害羞, 悲观, 侵略, 敌意, 冲动失业失业, 丢失工作, 工厂, 访问, 薪水烟烟草, 吸烟, 吸烟者, 烟雾, 尼古丁, 香烟, 戒烟, 停止, 放弃, 安非他酮, 伐尼克兰酒精醉酒, 嗡嗡声, 浪费, 虚度, 被摧毁, 醉意, 呕吐, 醉人, 辣味, 影响, 醉汉经历死亡, 逃生, 睡着, 唤醒, 结束, 生活, 杀死, 消失, 尝试, 再次, 冲动, 打架, 欺凌, 欺负, 父母, 父亲, 姐姐, 兄弟, 朋友, 我们, 我自己, 爸爸, 祖父母严重疾病癌症, 癫痫, 哮喘, 肝脏疾病, 糖尿病, 高血压, 中风, 艾滋病, 艾滋病, 获得性免疫缺陷综合征, 慢性风湿性疾病
2 语言特征的选取与量化
2.1 特征
语言特征是语言所特有的,它包含了词汇、语法、语义、语音、词性等多种内容. 词汇又包括了消极词汇、积极词汇、同义词、反义词、近义词等内容; 词性包括了动词、名词、代词、形容词、冠词、量词等内容. 在通过大量的文献查阅后,收集了一些关于自杀诱因在社交媒体上的词汇、词性等语言特征. 对于各自杀诱因中的高频词汇,本文做了同义词与反义词的扩展,一起存储在高频词汇表中,所使用的工具是WordNet.
对于搜集到的语言特征作如下处理,结果见表 2,表 3:
1) 剔除无法在文本中反映的语言特征,如音调、音色等;
2) 对词汇特征中的“综合”词,如焦虑,扩展其内容,即把可以形容“综合”词的词语,加入自杀词典中;
3) 消除重复特征;
4) 对在语音等社交媒体中获得的特征与在文本下的特征做相对应的转化,如人称代词等;
5) 对收集到的语言特征做统一化的表达.
n-gram特征: n-gram模型语言模型基于马尔可夫假设进行了限制,即第n个词出现的概率仅与它前面出现的n-1个词有关.
于是,n-gram数学表达为
P(s)=P(w1)…P(wT│w1w2…).
(1)
本文使用Uni-gram, Bi-gram以及Tri-gram从数据中提取特征,其数学表示为:
Uni-gram:
P(s)=P(w1)…P(wT│wT-1).
(2)
Bi-gram:
P(s)=P(w1)…P(wT│wT-1wT-2).
(3)
Tri-gram:
P(s)=P(w1)…P(wT│wT-1wT-2wT-3),
(4)
式中:wi表示词i;T表示总词数;s代表句子.
其运行过程如图1 所示:
1) 首先对句子信息进行粗切分,得到语段序列;
2) 对语段序列进行gram切分,得到gram频度列表;
3) 选择频度大于设定阈值的gram片段作为新的特征向量;
4) 每个gram片段就是一个向量维度,形成特征向量表.

图1 n-gram特征提取过程Fig.1 n-gram feature extraction process
2.2 特征量化
对本文中使用TF-IDF模型来量化n-gram特征与词汇特征. TF-IDF是一种统计方法,用以评估一个字词对于一个文档或一个语料库中的其中一份文档的重要程度,是一种常用的加权技术. 字词的重要性随着它在文件中出现的次数呈正比增加,但也会随着它在语料库中出现的频率呈反比下降.
词频(Term Frequency,TF): 是指该词在文章中出现的频率,本文中是指在本语句中该词出现的频率,其数学计算公式表示为
(5)
式中:ni,j表示在句子j中词i出现的次数.
IDF(Inverse Document Frequency)是一个词语普遍性的度量. 本文中,某一词语的IDF可由数据总量数除以包含该词语的语句的数目,再将结果取以10为底的对数得到,其数学计算公式为
(6)
式中: |D|表示数据集中数据的总量; |{j∶ti∈dj}|表示在数据集|D|中包含词i的句子j的数量,而分母加1是为了避免当词语不在语料库中时,出现分母为0的情况. 于是,有
tf-idf=tfi,j*idfi.
(7)
直观地,某一特定语句内的高词语频率,以及该词语在整个数据集中的低文档频率,可以产生高权重的TF-IDF,因此,TF-IDF倾向于过滤掉那些常见的词语,保留重要的词语.
最后根据均值归一化公式对其归一化为0~1区间,数学公式表示为
(8)
式中:μ表示所有数据的均值; max表示所有数据中的最大值; min表示所有数据中的最小值.
对于词性特征,使用SC-LIWC——简体中文版的Linguistic Inquiry and Word Count,来统计句子中的词性特征. 本文使用由中国科学院心理研究所开发的文心中文心理分析系统(Text Mind)来实现SC-LIWC的功能: 当输入一条数据后,“文心”会分析句子中的所有成分,给出包含人称代词、动词、介词等102个特征的占比. 因此,本文从中提取包含表1元素在内的词性特征并提取其他相关特征如句子词计数等.
3 实验与结果分析
3.1 假设
由于n-gram特征的局限性,在加入由词汇表达的自杀诱因的完备词典后,模型的精准率提高应是题中之意,于是有假设1:
假设 1 基于n-gram特征与完备的词典特征的模型在精准率上应优于基于n-gram特征的模型;
同样地,在加入分类性较强的词性特征后,对假设1中的模型的精准率的提高也是预期的效果,于是有假设2:
假设 2 基于n-gram特征、完备的词典特征与词性特征的模型在精准率上应优于基于n-gram特征模型与基于n-gram特征和完备的词典特征的模型.
3.2 数据来源及预处理
3.2.1 数据来源
本文的数据主要来自于微博中的“自杀树洞”. “自杀树洞”是微博名为“走饭”的微博下的留言评论. 这里是很多有心理疾病以及有自杀意念甚至实施自杀行为的人宣泄、表达他们情感的地方.
3.2.2 数据预处理
为了获得标准化的数据,使用Python脚本完成:
1) 对评论内容、评论人id的获取;
2) 同时对爬取时间进行转换标准化;
3) 删除包含乱码的数据;
4) 对评论内容中的标点符号统一化为逗号.
3.2.3 数据标注
由于本文所完成的实验为有监督的学习,因此,需要对数据进行标签的标注. 在本实验中,数据标注是雇佣5名心理学专业人士人为进行的,要求如下:
1) 若本人认为该数据有自杀倾向,则标记为“有自杀倾向”;
2) 若认为该数据无自杀倾向,则标记为“无自杀倾向”;
3) 若本人认为该数据无法确定是否有自杀倾向,则标记为“无法确定”.
对反馈回来的数据按如下规则进行总和,对相同数据:
1) 若标记为“有自杀倾向”的标记数大于3,则判定该数据的标记为“有自杀倾向”,记为“1”;
2) 若标记为“无自杀倾向”的标记数大于3,则判断该数据的标记为“无自杀倾向”,记为“0”;
3) 若标记为“无法确定”的标记数等于3,则要求所有专家讨论该数据,仍按上述规则1,2确定最终标记.
通过数据预处理,数据标注等工作,最终获得可使用数据7 000例,其中正样例3 500例,负样例3 500例.
3.3 实验方法
设置对照组实验与实验组实验,通过控制变量的方法来论证假设1的正确性. 表 4 给出了实验组与对照组的设置.

表 4 实验组与对照组设置
为了探索在SVM和Random Forest算法下组间模型的差异,现设置如下实验,表 5 给出了相应的实验设置.

表 5 组间模型差异实验设置
3.4 自杀意念检测与模型评估
评估模型性能好坏的度量有很多,如准确率、错误率、精准率、召回率、F1度量等等. 但是每一种性能度量方式所关注的信息又各不相同,例如错误率衡量的是在所有数据中有多少数据被分类错误,而精准率衡量的是在所有预测出来的数据中有多少是数据真正含有自杀倾向的.
本论文采用精准率(precision)、召回率(recall)、F1度量以及t检验来衡量模型的性能,其在本论文中代表的含义为: 精准率,评估的是模型所预测的所有数据中有多大的比例是真正含有自杀倾向的数据; 召回率,评估的是模型在所有真正含有自杀倾向的数据中有多大比例的数据被预测正确;F1度量,平衡精准率与召回率. 表 6 为分类结果的混淆矩阵.

表 6 分类结果的混淆矩阵
精准率的数学公式定义为:
(9)
召回率的数学公式定义为
(10)
F1度量的数学公式定义为
(11)
学习器A与B在k-折交叉验证下的t检验计算公式为
(12)
式中:μ为均值;σ为方差.
3.5 实验结果分析
本节对不同算法下对照组、实验组-1以及实验组-2所得模型进行性能评估,结果见表 7,同时,表 8 给出了组间的模型差异评估,表 9 为p值及其参考意义.
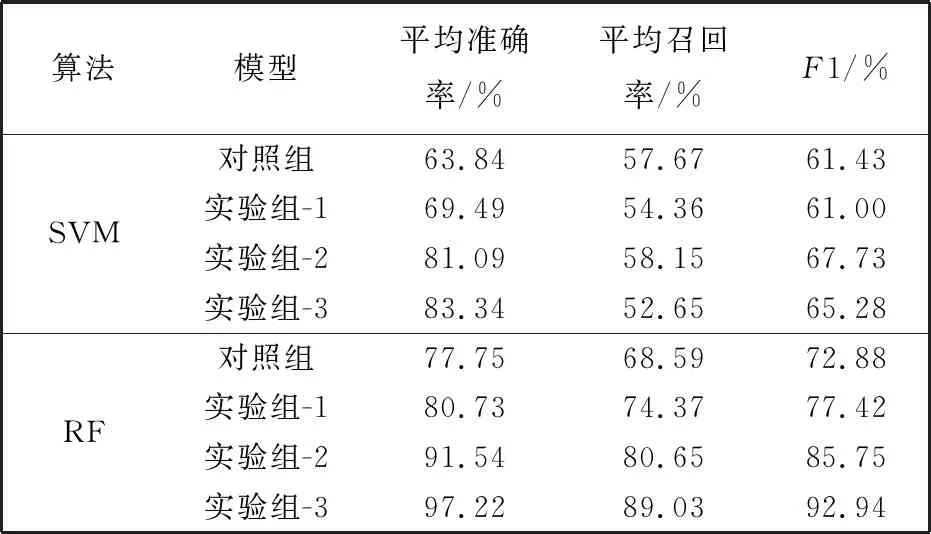
表 7 各分类算法下各组模型评估结果

表 8 各算法下组间模型的差异评估结果

表 9 p值对应的假设的统计学意义
由表 7,表 8,图2~图3 可得:
1) 由表 7,图2~图3中各算法下的对照组与实验组-1在精准率度量上可以看出,完备的字典对于基于n-gram特征的模型在精准率性能上有所提高,这也符合假设1的预期期望;
2) 由表7,图2~图3中各算法下的对照组、实验组-1与实验组-2在精准率度量上可以看出,词性特征对于基于n-gram特征与完备词典特征的模型在精准率性能上也有所提高,这同样符合假设2的预期期望;
3) 由表 7 中,图2~图3中实验组-2与实验组-3在精准率度量上可以看出,不添加n-gram特征会使得模型在精准率上有所提升,这种提升在2%左右,但是在召回率上有所下降,这种下降在6%左右;
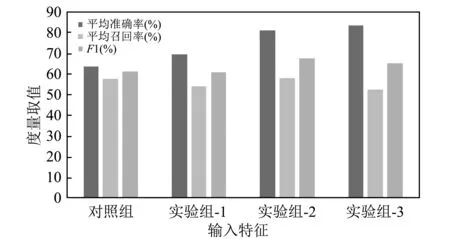
图2 支持向量机算法下各类特征所得模型的度量Fig.2 Measurement of models obtained from various features under support vector machine algorithm

图3 随机森林算法下各类特征所得模型的度量Fig.3 Measurement of models obtained from various features under random forest algorithm
4) 由表 7 中,图3中实验组-2与实验组-3在精准率度量上可以看出,不添加n-gram特征会使得模型在精准率上有所提升,这种提升在6%左右,在召回率上也有所提升,这种提升在9%左右;
5) 由表 7,图2~图3中各算法下模型的F1度量来看,基于n-gram特征与语言特征的模型优于基于n-gram特征的模型;
6) 由表 7,图2中各部分数据可以看出,随机森林算法在语言特征下表现最优,提升最大: 精准率提升约20%,召回率提升约21%,F1值提升约20%,即模型整体性能提升约20%;
7) 由表8与表9可以得出,无论哪种分类算法,基于n-gram特征的模型与基于n-gram特征和语言特征的模型都有极其显著的差异性,且后者优于前者;
8) 由表8和表9可以得出,支持向量机算法,n-gram特征使得两个模型产生显著性差异: 添加n-gram特征的模型优于不添加n-gram特征的模型;
9) 由表8和表9还可以得出,随机森林算法,n-gram特征使得两个模型产生极其显著性差异: 不添加n-gram特征的模型优于添加n-gram特征的模型.
4 结 论
关于自杀的话题,尤其是青少年的自杀,一直以来都备受关注. 过去由于技术的限制以及数据的稀少,无法完成对庞大社交媒体的自杀监控. 而近年来随着人工智能的快速发展,使得对社交媒体的自杀监控变为了可能. 近10年,机器学习应用领域中关于如何提高自杀意念检测的准确率成为了心理学研究中的一大热点课题.
本文的主要贡献在于:
1) 提供了一个较为完备的、可迁移行强的自杀词典;
2) 提出了语言特征,并证明了该特征对基于n-gram特征与基于n-gram特征和词典模型的模型的性能有所提高;
3) 试验了不同分类算法在n-gram特征、词典特征、语言特征下的模型性能,为特征与算法的选择提供了一定的依据.
后续可以在以下方面继续展开研究:
1) 在确定自杀意念拥有者后,对其近期内的微博进行分析,在原有特征中加入时间特征进行横向扩展,进一步确定其自杀意念;
2) 在现有特征中加入与用户相关的其他特征,继续提升模型的分类性能;
3) 对自杀诱因进行细化,实现可以确定用户是因何产生自杀意念的系统;
4) 通过BERT模型完成语言的特征的粗粒度提取,以语言特征为细粒度特征,通过CNN模型实现自杀意念检测.
