改进PSO-SVM工业防火墙白名单自学习方法研究*
2019-06-11任翔宇潘林伟
潘 峰,薛 萍,任翔宇,潘林伟
(1.茅台学院,贵州 遵义 564507;2.太原科技大学 电子信息工程学院,山西 太原 030024;3.上海交通大学 电子信息与电气工程学院,上海 200240)
0 引言
随着工业化与信息化融合加速,尤其是工业互联网获得空前关注,工业控制系统逐渐进入信息化和智能化发展阶段,更多的工业控制系统和工控设备直接或间接接入互联网,导致工控系统的信息安全问题与日俱增[1]。
工业防火墙作为维护工控系统安全的主要设备,对流通在工控网络中的所有数据进行全方位解析、判断和控制,有效地保障客户正常数据的传输,基本杜绝非法数据在工控网络中的分散和传播,最大程度上保证了客户生产的长期稳定运行[2]。但是由于不同工控网络的过滤规则不同,人为配置受到操作员知识水平的限制,将影响规则自学习的准确率和工业防火墙的性能,所以研究如何提高工业防火墙白名单规则自学习的方法非常必要。
文献[3]中SAHS J等运用机器学习算法(如SVM、贝叶斯分类法)对工控系统进行可行性分析,并利用工控数据流对机器算法进行了评估。文献[4]中利用PSO算法对SVM算法中的c,g参数进行优化,虽然PSO的收敛速度较快,局部搜索能力强,但它也存在着精度较低、全局搜索能力较弱等缺点。文献[5]利用网格搜索法对SVM算法中的c,g参数进行寻优时,如果步长较长时,其搜索速度慢,不容易获得全局最优解。针对PSO算法和网格搜索法所存在的不足,本文提出一种基于改进的粒子群优化算法和SVM相结合的白名单规则自学习算法,提高工业防火墙白名单规则自学习的准确率。
1 工业防火墙
1.1 工业防火墙系统结构
工业防火墙与普通防火墙最大的区别是加装了工业协议深度过滤模块,通过对工业控制协议的深度解析,提取特征集,结合白名单技术和智能学习方法建立工控网络安全通信模型,阻断非法数据访问,只允许可信的流量在网络上传输[6]。其系统结构如图1所示。
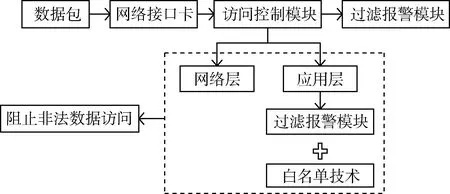
图1 工业防火墙系统结构图
工业防火墙的功能模块主要由三部分组成,每个功能块描述如下[7]:
(1)数据包采集和控制模块:通过网络接口卡(NIC)收集传入该模块的数据包,并将它们送到访问控制模块,可以根据访问控制模块的结果对数据包进行传递或阻挡。
(2)访问控制模块:通过对工控数据流进行分析,阻止非法数据访问。该模块主要包括两个部分,一是网络层访问控制块,它在网络层中执行网络级访问控制;二是应用层控制模块,它在应用层中执行应用级访问控制。
(3)过滤和报警模块:管理访问控制模块对数据包的处理结果,还可以与外部用户界面相连接。
1.2 白名单规则自学习
白名单技术主要针对工控系统安全的可用性和完整性这两个方面。
(1)白名单机制只允许正常的工控数据流通过,不会对数据的可用性造成破坏,并保证了进入系统的数据是正常的,从而保证了工控系统安全。
(2)白名单技术是通过智能算法将正确的数据加入规则库,对于变化的数据,白名单技术往往能准确定时刷新,保证了系统安全运行的实时性。
所谓工业防火墙过滤规则是在过滤时利用白名单技术将数据包信息与规则表内的规则进行匹配,至少与其中的某一条吻合,才被认为是合法数据允许通过。如使用Modbus TCP协议通信的工控网络,可加入白名单规则表中的数据特征,包括IP地址、MAC地址、协议标识符、端口号、功能代码、线圈或寄存器地址范围等。
2 工业防火墙算法
2.1 SVM基本原理
支持向量机(SVM)是指在统计学理论中运用结构风险最小化原理,根据统计出来的有限个样本信息,以寻求对特定训练样本的学习准确性(即模型复杂性)和识别无错误样本的能力(即学习能力)的最佳解,以期获得最好的推广能力[8]。它是使用线性超平面来创建具有最大余量的分类器,该算法旨在通过在高维特征空间内使用核函数来找到支持向量和其相应的系数,以便建立最优分类面(即使得两类样本的分离间隔最大)。其支持向量示意图如图2所示。在图2中,虚线代表使用神经网络算法找到的分类界面,只保证现有样本位于分类界面两侧,而SVM算法可找到全局最优。
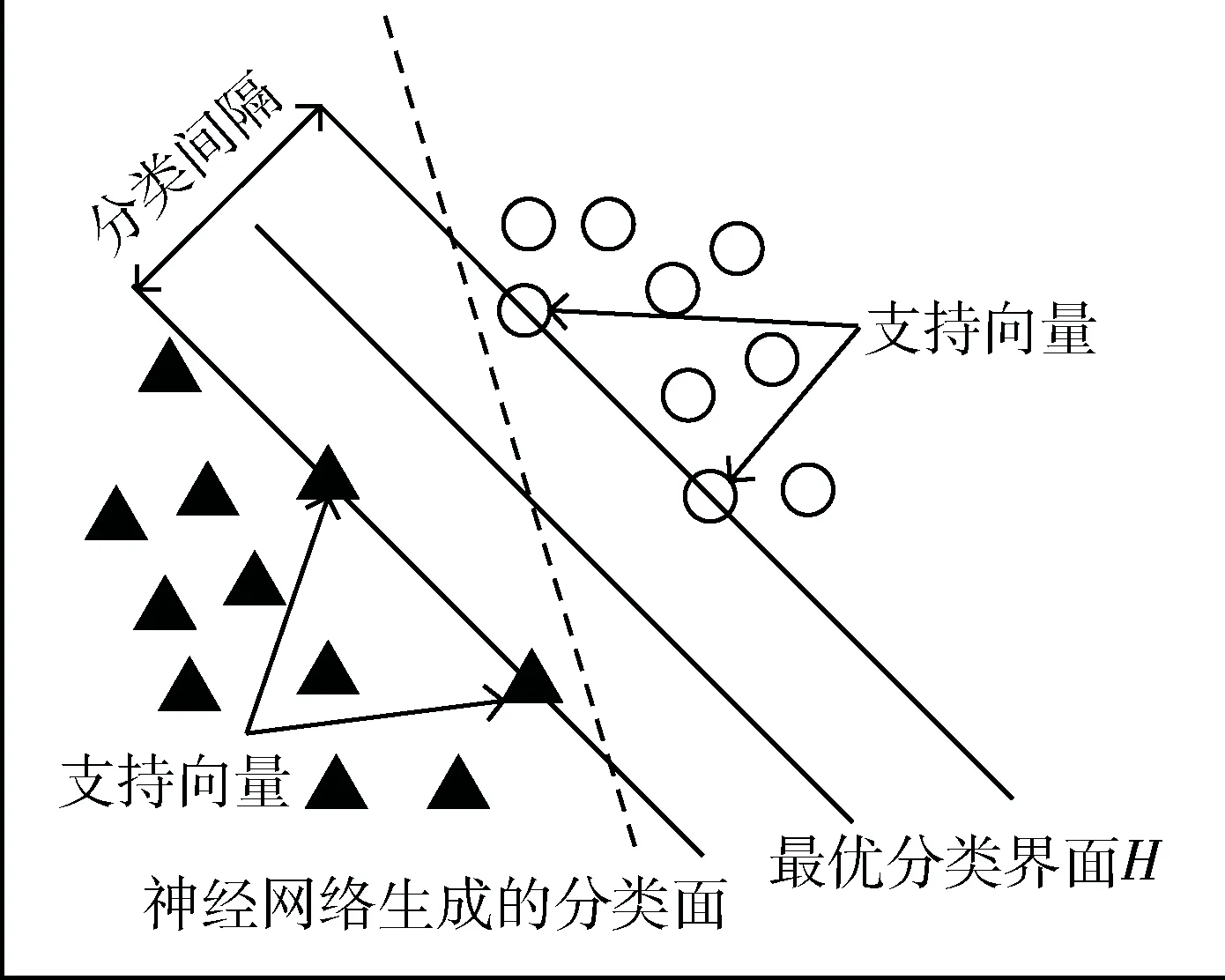
图2 支持向量机示意图
在运用SVM分析工控数据流时,用D表示工控数据的训练样本,则
(1)
其中训练样本集的组合集为(xi,yi)=(x1,y1),(x2,y2),…,(xd,yd),yi为与训练样本对应的标签,如果是相关的,则取值为+1;若不关联,则取-1。本文采用高斯函数(Gaussian)作为SVM的核函数:
(2)
则由偏差和权向量两者定义的广义最优分类面函数表示为:
(3)
其中w为判别函数的权向量;ξi是为分离不可分离的数据而引入的松弛变量,表示对训练样本的错分度;参数C为惩罚常数,表示控制对错分样本的宽容度。
此函数的约束条件为:
(4)
通过构造拉格朗日函数,则高维特征空间内原始函数的判别函数为:
(5)

2.2 粒子群算法
粒子群优化算法是模拟鸟群起飞的信息交互过程,是一种典型的全局优化算法。该方法是利用移动的粒子搜索n维空间中n个可变量函数优化问题的解。所有的粒子都具有适应度值,并且根据适应度函数来评估和优化所有例子的适应度值,并使粒子的速度发生变化。群体中的每个粒子均可受益于同一群体中所有其他个体的先前经历。在n维解空间中的迭代搜索期间,每个粒子将根据其自身的飞行经验以及群体中其他伴随粒子的飞行经验来调整其飞行的随度和位置[9]。为了寻求最优解,每个粒子将根据自身认知和社会部分改变其速度和位置:
vid(k+1)=wvid(k)+c1randid(·)[pid(k)-xid(k)]+c2randid(·)[pgd(k)-xid(k)]
(6)
xid(k+1)=xid(k)+vid(k),d=1,2,…,n
(7)
式中:w为惯性权重,c1、c2为加速系数,rand(·)∈[0,1]。
3 改进PSO-SVM规则自学习算法
3.1 算法改进
在实际应用中,SVM的性能主要取决于c和g参数的选择,设计者往往通过个人经验给定c和g的值,效果不佳。c值如果过大,则对于训练样本来说,其分类准确率非常高,但会导致其测试样本分类准确率非常低。如果c太小,则分类准确率不能令人满意,使得模型不能使用。参数g对分类结果的影响要远大于c值,其值会影响特征空间中数据的区分结果。参数g过大,会导致过度拟合,而值越小,会导致拟合缺陷[10]。
由于粒子群算法是一种随机搜索算法,算法中的一些参数(如惯性权重、加速系数等)通常根据有限的经验来确定,效率低且收敛速度不快。为了解决上述存在的问题,本文将加速系数c1、c2和线性权重参数w按以下方法进行改进:
(8)
式中,wmin为最小惯性权重值,wmax为最大惯性权重值,itermax为最大迭代次数,iteri为当前迭代次数,ctmax为迭代终值。
3.2 改进PSO-SVM算法
基于改进PSO-SVM算法流程图如图3所示。

图3 改进PSO-SVM算法流程图
该寻优算法的基本步骤如下:
(1)样本数据通过交叉验证法将其分为训练数据集和测试数据集。
(2)设置最大迭代次数itermax=200,当前的初始迭代值iter=1。
(3)利用PSO随机生成初始种群,常用的参数设置为Ctmax=3.9,C0=1。
(4)本文选用5折交叉验证意义下的准确率作为适应度函数,以此计算群体中每个粒子的适应度值。
(5)更新个体极值和群体极值。
(6)判断是否满足iteri≥itermax。若满足,则停止该算法,输出值即为SVM的最优参数。若不满足,返回第(2)步继续操作,直到满足条件。
4 实验测试与结果分析
4.1 实验模型搭建
由于国内外的工控数据尚未公开,为了对算法进行验证,本文模拟工厂搭建了一个简单的工控实验平台,拓扑图如图4所示。
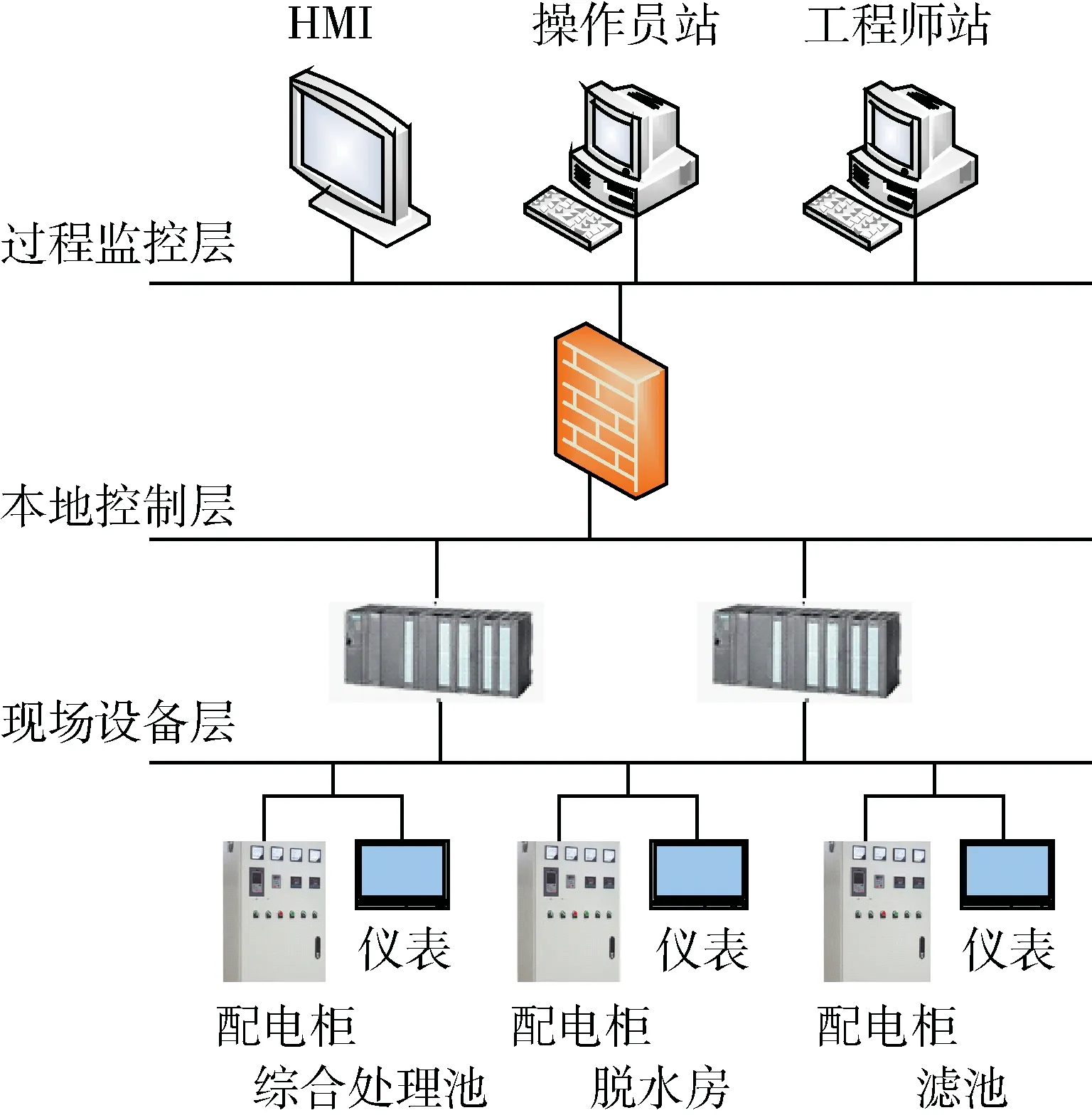
图4 工控实验平台
在该工控实验平台中,过程监控层中操作员站采用WINCC软件对其进行监控,工程师站采用STEP7对PLC进行编程。现场控制层选择两台西门子PLC300,CPU为315-2PN/DP。BCNet-s7通信模块用于过程监控层和现场控制层之间,将S7协议转换成MODBUS TCP协议,以此实现WINCC与PLC之间的MODBUS TCP通信。工业防火墙中的白名单规则自学习模块主要由协议解析工具以及Wire-shark抓包工具组成,该模块用于对数据的抓控和解析,位于过程监控层和现场控制层之间。该环境模拟了小型污水处理系统中水泵中水位的控制,并对电动阀门的开闭进行了逻辑上的模拟。
4.2 实验仿真
4.2.1 数据来源
实验数据主要考虑Modbus TCP中的功能码和线圈或寄存器地址两个,并按顺序组合两个数据。将本次试验中PLC已使用的功能码和寄存器的地址组合成正常数据;异常数据样本集由未使用的功能码、地址与已使用的功能码、地址两种数据组成。生成的异常类样本集有三类:(1)功能码和地址列表均非法;(2)功能码合法,地址列表非法;(3)功 能码非法,地址列表合法。
4.2.2 仿真平台
仿真实验平台选用CPU 3.30 GHz,4.0 GB,Windows 7系统。采用MATLAB 2014b、Libsvm-mat-2.89-3工具箱进行实验,先把SVM工具箱下载到MTALAB中,通过编写SVM程序并利用改进的粒子群算法对其参数进行寻优,并带入SVM编写的程序中得到最优准确率。
4.2.3 仿真实验对比
本文训练数据共分为7组,分别利用网格搜索法、PSO和改进的PSO对这7组数据进行训练,生成白名单规则表,然后用三种算法对测试数据进行准确率测试。PSO算法得到SVM的最佳c,g参数如表1所示。
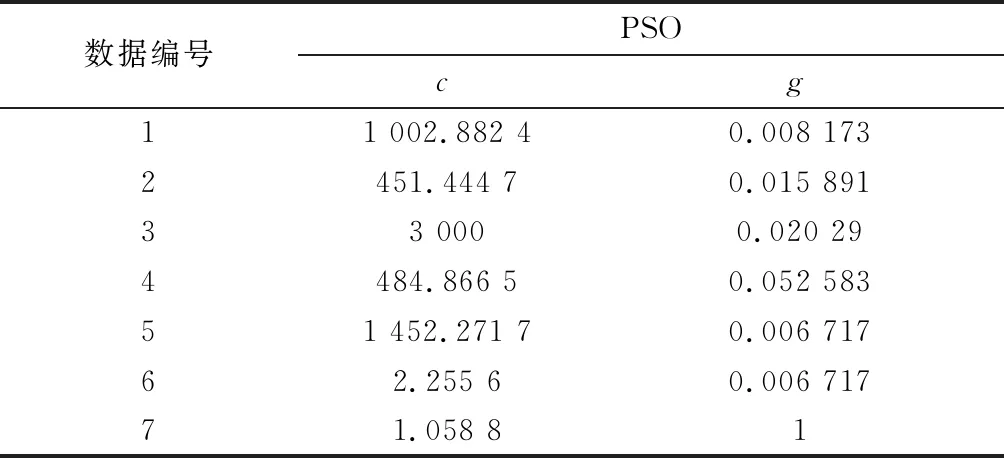
表1 PSO算法得到SVM的参数
网格搜索法得到SVM的最佳c,g参数如表2所示。
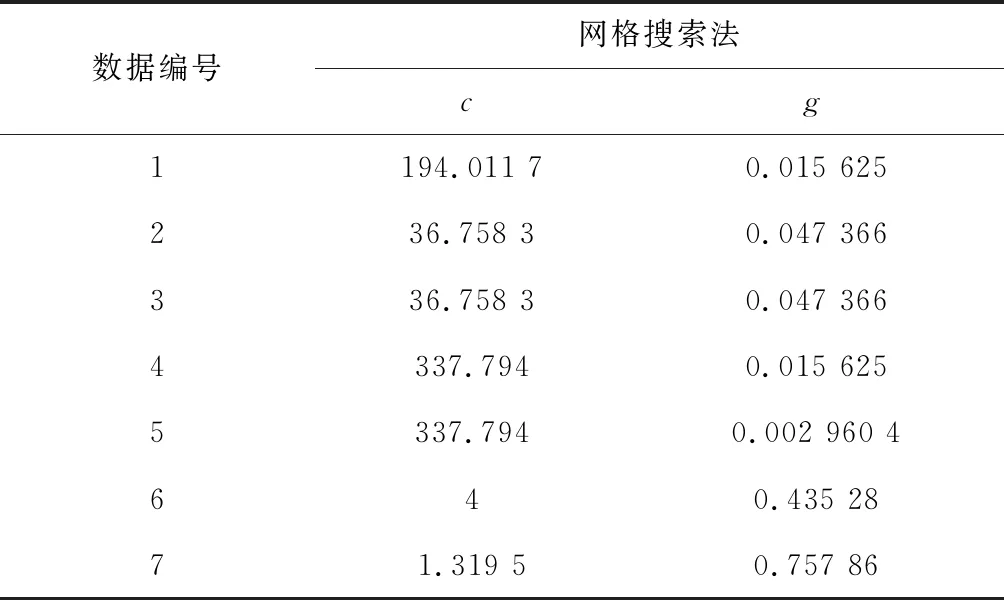
表2 网格搜索法得到SVM的参数
改进PSO算法得到SVM的最佳c,g参数如表3所示。
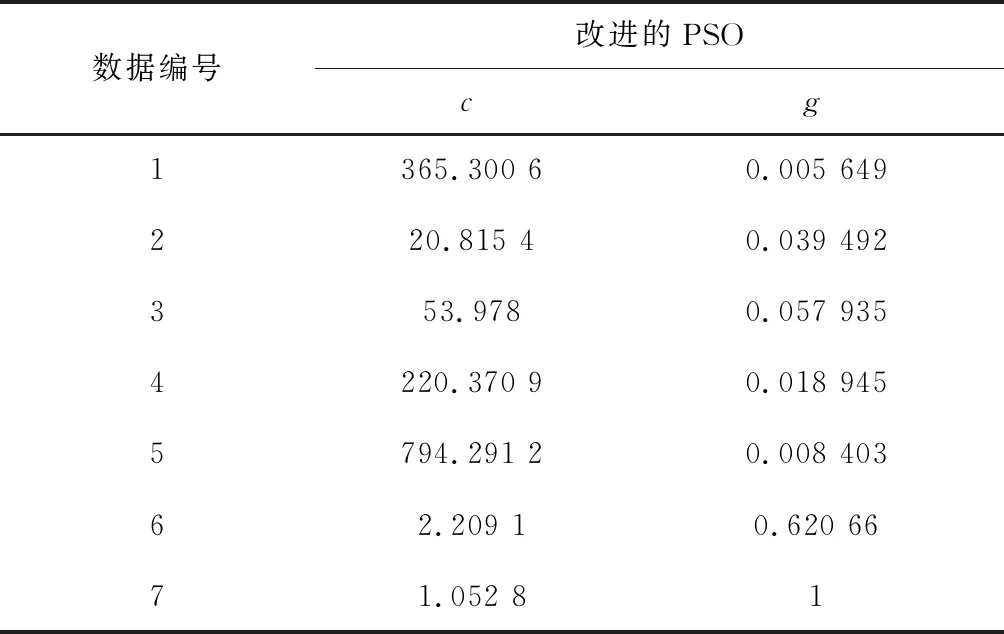
表3 改进PSO算法得到SVM的参数
将三种算法所得到SVM中c,g的参数值带入SVM的程序中,由此得到测试数据的准确率。
PSO算法测得正常数据和异常数据的准确率如图5所示。

图5 PSO算法测得的准确率
网格搜索法测得正常数据和异常数据的准确率如图6所示。
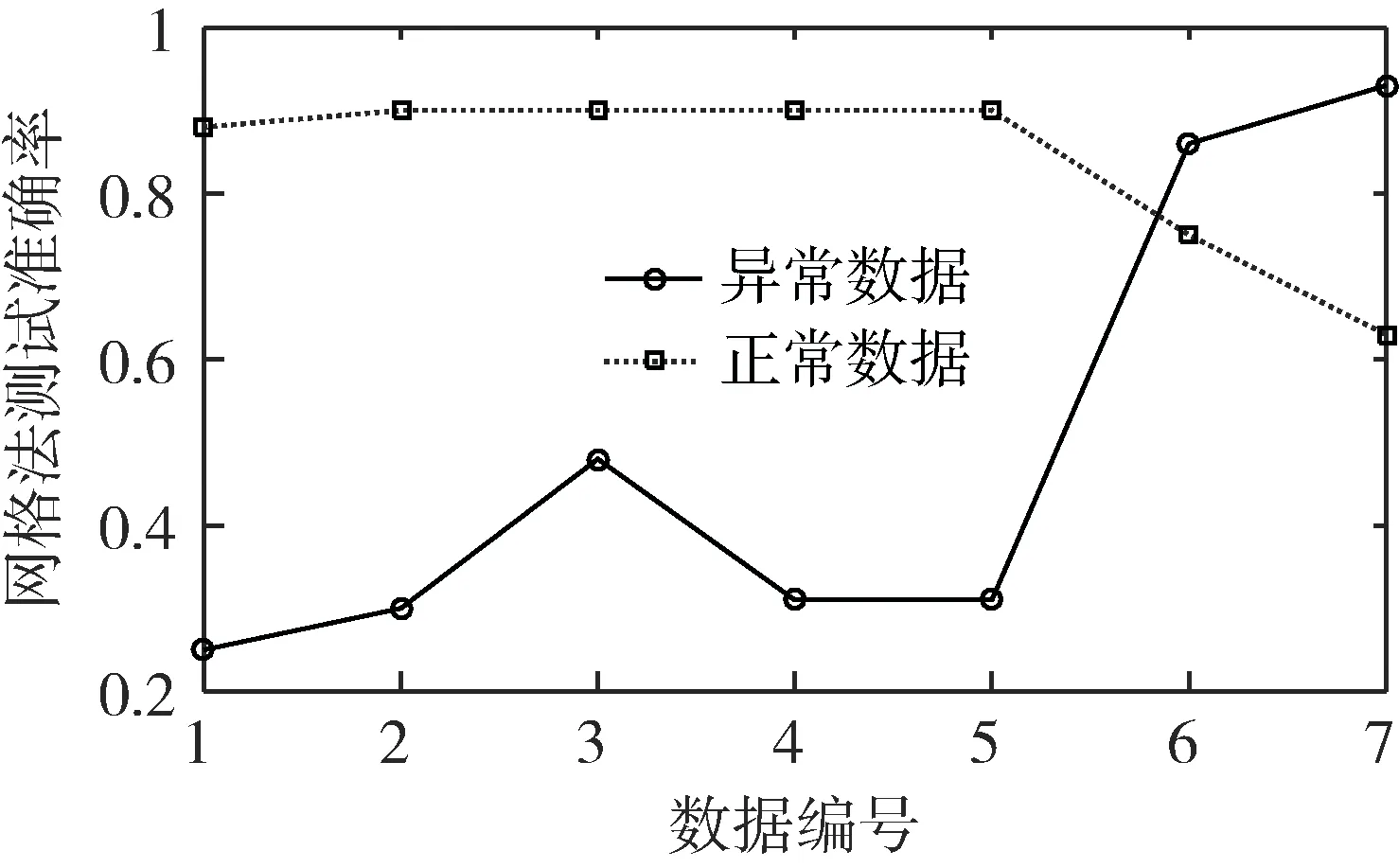
图6 网格搜索法测得的准确率
改进的PSO算法中,最大迭代次数设为200次,种群为50。利用改进的PSO算法依次将7组数据所优化的c,g参数导入SVM中,得到改进PSO算法的测试数据的准确率,如图7所示。

图7 改进PSO算法测得的准确率
与网格搜索法、PSO相比,改进的PSO算法对异常类数据的检测率提高了,对正常类数据的样本虽有所降低,但是其准确率高于另外两种算法。对比结果如图8和图9所示。
图8表示三种算法对异常数据的检测率,从图中可以看出,异常数据的准确率在不断上升。在第3组数据中,改进的PSO算法准确率相比PSO提高了22%;较网格搜索法提高了2%。

图8 异常数据的准确率
图9表示三种算法对正常数据的检测率,从图中可以看出,改进PSO算法测得正常数据的准确率均高于PSO和网格搜索法。
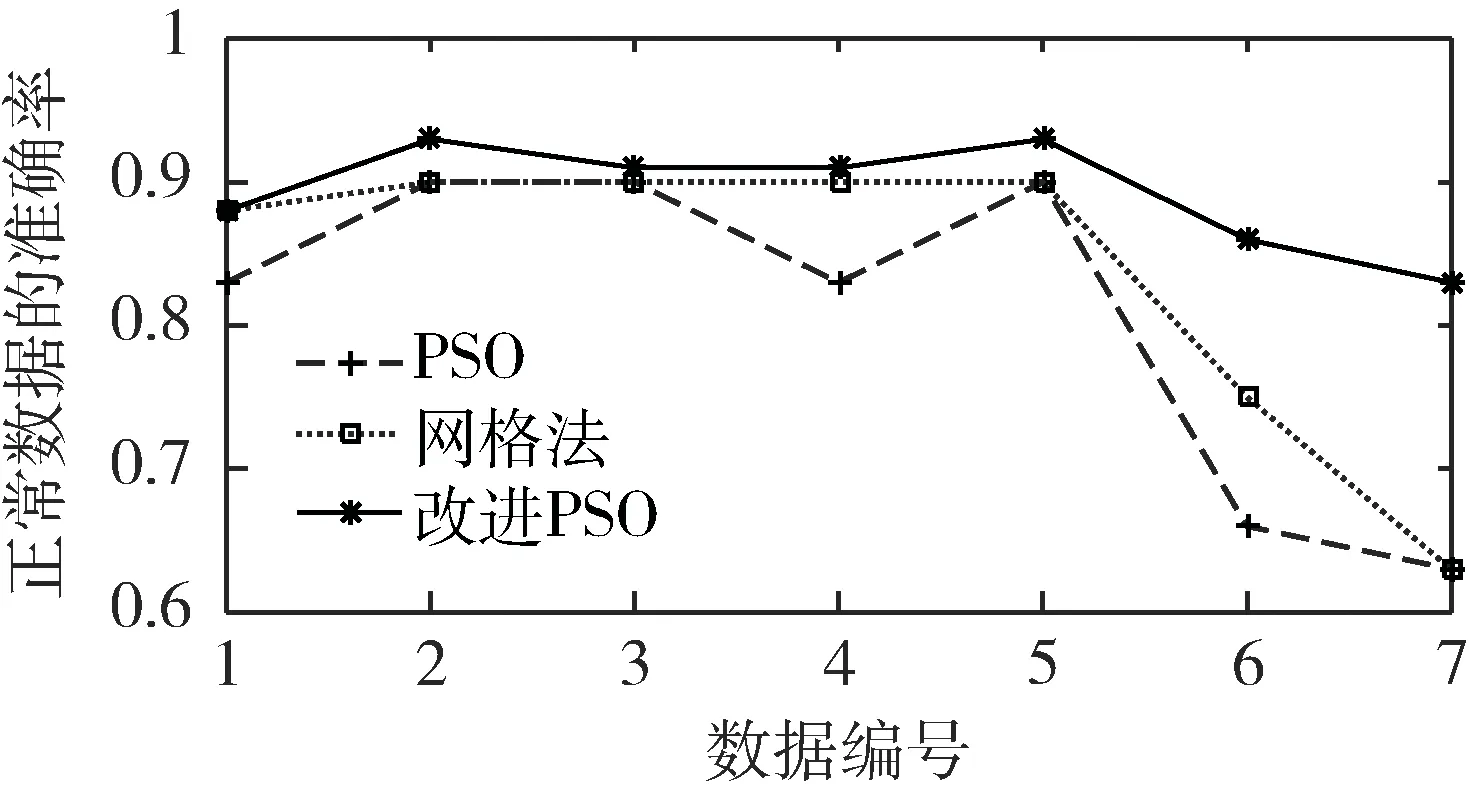
图9 正常数据的准确率
实验结果表明,相比网格搜索法和PSO算法,改进的粒子群算法具有优化时间短、计算方便、可以提高异常类和正常类数据的准确率的优点。通过该算法可以提高工业防火墙的性能,提高规则自学习的准确率。
5 结论
针对网格搜索法和粒子群优化算法存在的缺点,导致白名单规则自学习方法的准确率低,影响工业防火墙的性能,本文提出利用基于改进的粒子群优化算法和支持向量机相结合的白名单规则自学习算法对SVM算法中的参数进行优化,提高了异常数据和正常数据的准确率,从而提高了工业防火墙的性能。
