一种三维脉动阵列结构的CNN推理加速器设计
2019-06-11邱超冯肖雄
文/邱超 冯肖雄
深度学习CNN神经网络因其巨大的计算量,巨大的通信带宽要求,对传统的冯诺依曼体系结构的CPU提出了挑战,传统CPU产品无法应对,因此衍生出了GPU图形处理器、ASIC专用集成电路、FPGA等几条技术路线。我们从架构灵活性、峰值算力、延迟以及功耗、研发成本对比五个维度,对四条平台技术路线进行了对比。
从以上五个维度来说,FPGA使用处于上游位置,因此使用FPGA作为深度学习定制化加速电路,具备了天然优势,本文提到的新型三维脉动阵列结构主要是基于FPGA电路动态可变基础上实现。
1 CNN卷积计算工作原理
我们知道卷积层作为计算量要求最高的网络层,是CNN推理加速器中最需要加速的网络层,接下来以简单实例为主,介绍卷积层的计算方法。
本文设定的卷积计算场景是,输入数据图像5x5大小,输入通道数ci=3,卷积核大小是3x3,卷积步长stride=2,卷积外部填充pad=1,输出图像的通道数co=2为例,介绍卷积计算过程,对于其他参数的场景,计算方法类似。
首先取卷积核参数中co相同的一组,找到对应的ci通道,覆盖到对应的Feature Input上,经过点乘求和,可得到3个结果,接下来再对3个结果进行累加,即可得到一个输出点的数据。对于其他点的输出数据,采用的计算方法一样。
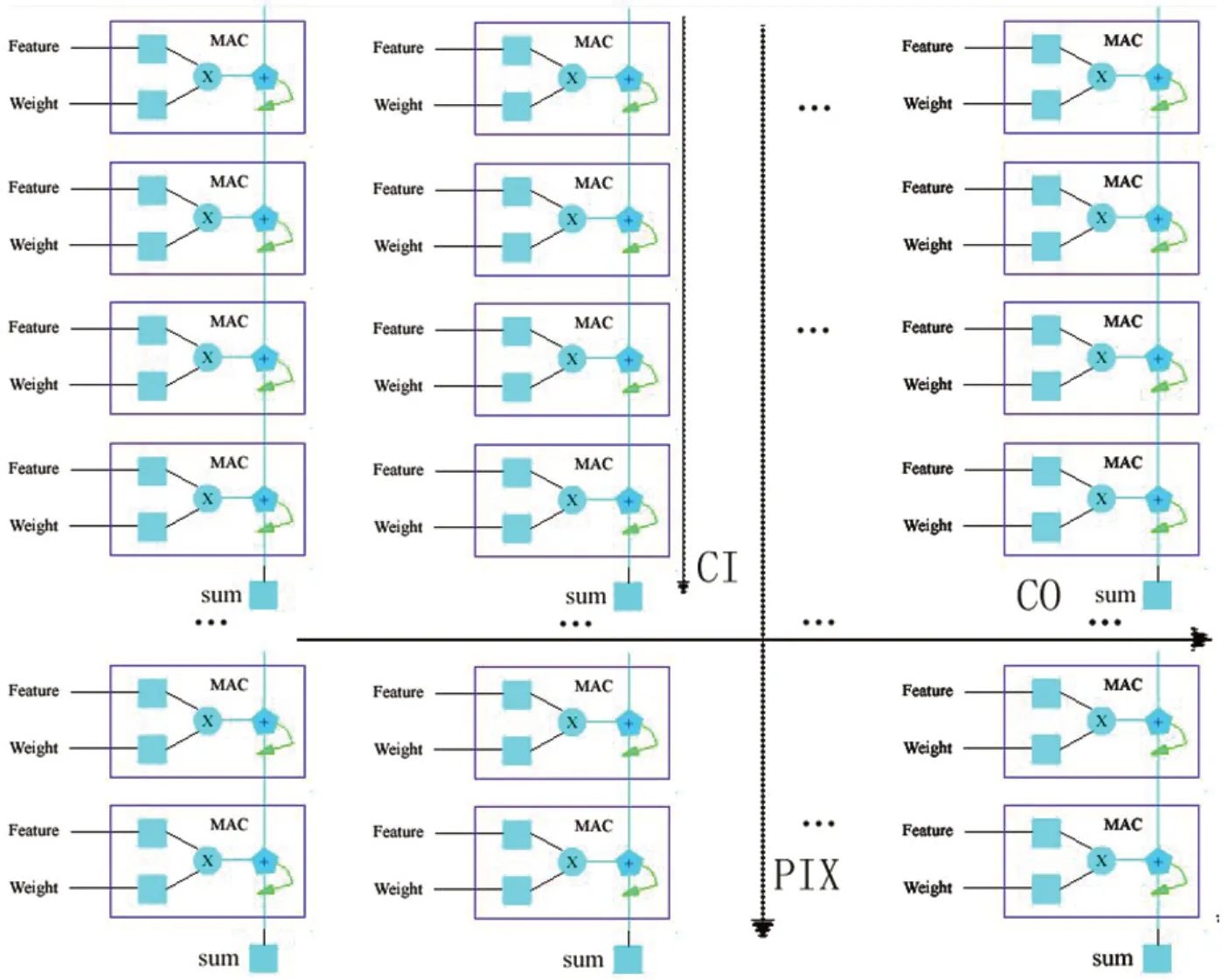
图1:三维阵列结构
2 实现结构
2.1 三维阵列结构
一种三维脉动阵列乘加器实现结构如图1所示,从卷积计算中提取3个重要维度,分别是ci(channel inputs),co(channel outputs)以及pix像素信息。
(1)Feature Map的ci信息与权重数据的ci一一对应。
(2)相同Feature Map的ci信息,可以有不同的co通道,并且co方向不需要累加和。
(3)对于不同的Pix通道信息,ci,co通道信息共用。这种三维阵列结构的乘加阵列器,极大程度满足了算力要求,并且做到累加和的关键路径最短。
前文介绍,卷积核阵列还有一个维度参数是kernel,在这个乘加阵列中没有体现出来,这里考虑的因素是由于不同神经网络下,卷积核尺寸是任意的,这个维度上做分割并行相乘不可取,因此三维阵列结构上不需要体现出来。
三维阵列结构只给出了乘加阵列计算模块工作方法,这里面有个疑问,对于Feature Map来说,数据分配器如何产生的,在下一节中有介绍。
2.2 三维脉动阵列的Feature Map分配器
Feature Maps数据分配器中包括原始输入图像IntPix和输出滑窗后的图像OutPix。我们以卷积核填充为0,核大小为5,步长为2,同时输出7点数据为例,介绍输入分配器如何同时输出多点Pix模块。
首先IntPix模块中存放的是输入图像数据,注意是单通道的。OutPix中存放输出的数据信息。其次从IntPix中每取到一个像素点pix,都会按照滑窗的对应关系,放到相应位置的opix中即可,这种操作方式是按照行扫描的方式进行,当所有行都扫描结束后,便得到了多个像素点按照滑窗展开后的像素信息。
3 结论
本文提出了一种新型三维脉动阵列结构的乘加器,并给出了Feature Map数据分配模块的实现过程,该结构具有定制灵活,关键路径长度较短,以及计算标准密集的特点,非常适合在各种型号的FPGA上进行定制化CNN推理加速应用。
