基于数据半衰期的数据仓库分级存储研究
2019-06-10曾广移卢勇李德华李俊超
曾广移 卢勇 李德华 李俊超


摘 要:在大数据时代,数据高速增长,对数据仓库管理方法和技术提出了全新挑战,为实现仓储资源优化配置,提高资源使用效率,首次把数据半衰期运用于数据仓库分级存储。传统固定阈值转存策略存在存储资源配置不合理的问题,利用半衰期分级存储策略,对每个数据对象进行计算分析后转存,采用MPP数据仓库和Hadoop构建混合数据仓库存储架构,解决了大数据背景下的数据存储与分析,实现了数据仓库管理方法和数据存储架构的创新。实际验证发现,数据半衰期转存策略优于固定阈值转存策略,证明数据半衰期在数据仓库的管理中有显著应用价值。
关键词:数据半衰期;分级存储;Hadoop;数据仓库
DOI:10. 11907/rjdk. 181572
中图分类号:TP319文献标识码:A文章编号:1672-7800(2019)002-0123-05
Abstract:In the era of big data, the rapid growth of data has brought new challenges to data warehouse management methods and technologies. This paper applies data half-life to hierarchical storage of data warehouses for the first time. The purpose is to optimize the configuration of storage resources and improve the efficiency of resource use. The traditional fixed-threshold save strategy has the shortcoming of unreasonable allocation of storage resources. A half-life storage strategy is used to calculate, analyze and transfer each data object. In terms of technology, MPP data warehouse and Hadoop are used to build hybrid data warehouse storage. The method solves the problem of data storage and facilitates analysis under the background of big data, and realizes the data warehouse management and data storage architecture innovation. The method of verifying the half-life of data by empirical method is better than that of the fixed threshold, which proves that the data half-life has significant application value in the data warehouse management.
Key Words:data half life;hierarchical storage;Hadoop;data warehouse
0 引言
全球知名咨询公司麦肯锡全球研究院发布了一份题为《大数据:创新、竞争和生产力的下一个新领域》的报告,报告指出2011年后大数据将保持每年50%以上的增长速度。2011年全球数据增量就达到了1.8ZB(1.8万亿GB),相当于全世界每个人产生200GB以上数据。从宏观角度看,全球数据实现爆炸式增长;从微观角度看,企业管理数据也在高速增长,商业数据更是呈指数级增长。大数据指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产,同时对技术和工具提出了更高要求。随着数据的快速增长,商业数据仓库已不能适应新业务和新应用场景的要求,数据仓库不能支撑大数据分析与预测。
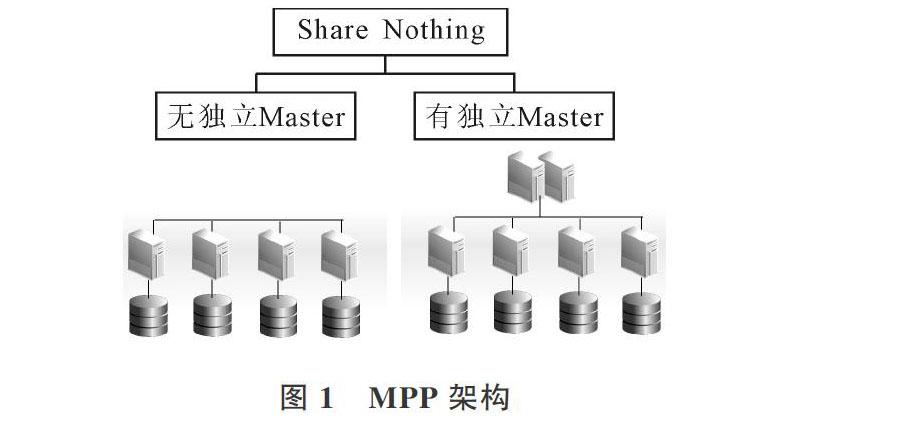
传统商业数据仓库采用MPP架构。数据仓库MPP[2](massively parallel processing)是将任务并行地分散到多个服务器和节点上,在每个节点上计算完成后,將各自部分的结果汇总在一起得到最终结果。在 MPP 系统中,每个节点内的CPU不能直接访问另一个节点的内存,节点之间信息交互通过节点互联网络实现。因为MPP系统不共享资源(Share-Nothing),资源水平扩展比较容易实现。常见的MPP数据库架构如图1所示。
MPP架构特点包括:①通过Scale-Out的方式扩展计算能力,存储也同步线性扩展;②适用于结构化数据,支持TB级数据分析预测;③存储空间扩容价格昂贵,多采用软硬件绑定的模式销售。
由于MPP数据仓库技术成熟、稳定性好,支持在线阶段分析与计算,因此运用MMP数据仓库的产品在商业中被大量采用,如Teradata、DB2等。在数据增长缓慢的时代,数据仓库可以发挥MPP架构的优点,通过挂载服务器和存储设备,实现资源的水平扩展,但是在大数据时代,数据增长迅速,通过增加服务器已经不能很好解决数据仓库存储问题,具体包括两个方面: ①服务器及存储设备的大量增加,会大幅降低数据分析能力,运行效率快速下降,无法实现数据快速响应的要求;②MPP架构的服务器和存储设备必须由厂商提供,价格非常昂贵。为了保证数据及时和快速响应,在早期数据仓库建设中,并未考虑数据分级存储。大数据时代,MPP架构的数据仓库暴露了诸多缺点,结合大数据时代的新技术,本文依据数据生命周期原理,提出对数据仓库进行分级存储的解决方案。许多学者在数据分级存储领域进行了分析与归纳,其中杨文晖对海量空间数据的特点和日常数据应用规律,提出了基于访问热度和聚类关联的海量空间数据分级存储模型,该模型主要包括热点数据分级、关联数据分级、数据迁移3部分[3]。吴洪桥等[4]针对数据中心在线、近线和离线的多级存储体系架构,提出了开展多源、异构影像数据分级存储与数据迁移规则的研究,依据影像数据产品链与生命周期,提出了分级存储原则、价值评估要素、分级存储策略与方法。史敏鸽[5]则从数据分级如何在图书馆领域应用进行了研究。
