基于词嵌入的微博谣言主题分类研究
2019-06-09关菁华刘鑫刁建华
关菁华 刘鑫 刁建华


摘 要:近年来,随着智能移动设备的普及,人们可以随时随地通过网络社交媒体获取与分享信息。然而,便捷的上网方式以及自由的网络空间,也为网络谣言的产生与传播提供了条件,广泛传播的谣言可能具有极大的破坏性。因此,及时识别谣言对于保障社会稳定具有重要意义。使用词嵌入对微博短文本进行向量化处理,然后使用朴素贝叶斯、K最近邻和支持向量机对文本向量进行主题分类,以期及时发现具有周期性出现特点的谣言。将该模型在中文谣言真实数据集上进行有效性验证,使用5 487条数据作为训练集,2 703条数据作为测试集进行分类实验。实验结果表明,K最近邻模型相比于朴素贝叶斯模型及支持向量机模型,在谣言主题分类任务中表现最佳,其F1值和分类准确率都达到0.93,表明基于词嵌入的谣言主题分类方法可及时发现周期性谣言。
关键词:微博谣言;词嵌入;主题分类;文本向量
DOI:10. 11907/rjdk. 191169
中图分类号:TP301文献标识码:A文章编号:1672-7800(2019)004-0001-03
0 引言
谣言是一种自发性、扩张性的社会心理现象,至今尚没有一个公认的定义[1]。本文采用我国《现代汉语词典》对谣言的定义,谣言即没有事实根据的消息。
根据中国互联网络信息中心(CNNIC)2018年8月发布的《中国互联网络发展状况统计报告》显示,截至2018年6月,中国网民规模达8.02亿,互联网普及率达到57.7%。网民中使用手机上网人群占比达到98.3%,且网民上网设备进一步向移动端集中。迅速增长的网民规模、方便快捷的上网方式,为网络谣言的产生与传播提供了条件。广泛传播的谣言可能具有极大的破坏性,如:2011年郭美美事件爆发后,谣言四起,在网络上不断发酵,自事件发生后,社会捐款数额以及慈善组织捐赠数额均出现锐减。根据民政部统计数据显示,全国2011年7月社会捐款数额为5亿元,与6月相比降幅超过50%。慈善组织6~8月接收的捐赠数额降幅更是达到86.6%;2015年,有关“娃哈哈爽歪歪、AD钙奶等饮料中含有肉毒杆菌”的谣言在微博、微信中热传。娃哈哈方面表示,相关谣言使娃哈哈部分产品当年第一季度损失高达20亿元。以上案例都说明了网络谣言的巨大危害。由此可见,研究如何从每天产生的大量社交媒体数据中,及时发现并识别谣言,从而将谣言传播扼杀在初期,降低谣言对社会的危害具有重大意义。微博作为目前最大的广播式社交媒体,是最常用的谣言传播平台。如何从微博文本中提取有效语义特征并进行谣言主题分类成为目前短文本分类研究中的热点之一。因此,进行基于内容的谣言主题分类研究,从而自动识别谣言主题,及时发现一些具有周期性特点的谣言,具有重要的研究意义。
目前,国内谣言研究主要集中在谣言传播模型构建与仿真实验上。如任宁等[2]在经典SIR谣言传播模型基础上,引入反对者角色,运用概率生成函数方法解决了谣言传播过程中任意时刻的传播规模等问题;王飞雪等[3]基于经典SIR传播模型,引入謠言在不同节点之间的传播概率,并分析了不同节点对传播概率的影响,建立社交网络中考虑网络节点自身影响的谣言传播模型;王雨嘉等[4]也基于经典SIR谣言传播模型,引入观望者与辟谣者角色,并将移出者分为中立者、相信谣言者与得知真相者3类,构建一个改进的WT-SIR*谣言传播模型;刘雅辉等[5]指出谣言内容、发布用户及其传播过程是识别谣言与非谣言的关键要素;张仰森等[6]利用SVM构建一个基于评论异常度的谣言识别模型。以上文献多从经典SIR谣言传播模型出发进行模型改进与仿真实验,而从网络谣言自动主题分类角度进行的研究较少,但谣言的自动主题分类对周期性谣言的自动识别具有重要意义。
谣言主题分类问题可看作文本的多分类问题加以解决。基于机器学习的文本主题分类方法包括朴素贝叶斯(NB)、K最近邻(KNN)、决策树、支持向量机(SVM)等。丁晟春等[7]借助本体将领域知识及领域文本特征融入分类过程,使用加权朴素贝叶斯模型对网络信息进行主题分类;贾隆嘉等[8]提出将特征由基于词的表示转换为基于类别的表示,然后采用支持向量机进行高校新浪微博主题分类;程元堃[9]提出基于词向量的网页分类模型与基于URL+关键词的网页分类模型,并使用朴素贝叶斯算法模型解决对未知网页的分类问题;黎巎等[10]使用LDA(Latent Dirichlet Allocation)主题发现模型对游客评论进行主题分析与情感倾向分析;胡朝举等[11]利用LDA模型得到文档主题分布,然后使用主题词对原始文本进行特征扩充,最后利用SVM分类模型进行分类;宗乾进等[12]通过隐含狄利克雷分布对生成与举报的谣言内容进行主题分类;姜赢等[13]采用文本句式特征分析方法进行谣言识别。近年来,随着深度学习技术的不断发展,已成功应用于图像识别[14]、语音识别[15]等领域,目前越来越多研究者开始尝试利用深度学习技术解决自然语言处理领域的各类问题,也取得了一定效果。如卷积神经网络、循环神经网络与长短时记忆网络等深度模型即被应用于句子分类[16]、情感分类[17]与文本分类[18]等问题中。
以上方法中,基于机器学习的文本分类方法需要研究人员根据经验,事先筛选好用于分类的特征,即分类效果与特征选择紧密相关,但该方法前期需要大量人工参与,不适用于目前多变、海量的数据。基于深度学习技术构建的模型具有不可解释性,且在模型训练过程中对运行系统硬件要求较高,训练时间也很长,在自然语言处理领域,分类效果与传统方法相近。
因此,本文从微博内容本身特点出发,综合考虑方法的时效性,使用具有语义信息的词嵌入表示微博文本向量,且选择经典的NB、KNN和SVM作为分类模型,进行微博谣言主题分类研究,并提出一种基于词嵌入的谣言主题分类模型。实验结果表明,该方法能有效地对微博谣言进行主题分类,且准确率和 F1 值较高,都达到了0.93。
1 主题分类模型
1.1 基于词嵌入的微博文本表示
传统文本表示方法是对一段文本信息先进行分词,使用一个与词典维度相当的向量表示一条文本信息,用1表示在文档中有该词出现,0表示不出现。但该表示方法丢失了词语间的语义关系,且文本的向量表示很稀疏,增加了训练难度。本文使用压缩的词嵌入存储方式,每一个词语、段落或篇章都可以使用一个比较低维、具有语义信息的向量进行表示,从而有利于机器对人类语言的语义表达与理解,且有利于算法实现。
文本常见的向量化表示方法包括对一段文本包含的所有词向量求平均值、对词向量聚类以及doc2vec模型[19]。本文从微博属于短文本的特点出发,选择简单求和、求平均的方法,采用公式(1)进行文本向量计算。
1.2 基于词嵌入的微博谣言主题分类模型
本文以中文Wiki百科作为背景语料库,首先使用MIKOLOV等[20]提出的word2vec工具進行中文词向量学习,为微博短文本向量生成作准备;然后对微博谣言文本进行分词、去停用词等预处理操作;接着使用公式(1)构建每条微博的文本向量;最后分别使用NB、KNN和SVM作为分类模型,进行谣言的主题分类研究,具体模型如图1所示。
2 实验结果
2.1 数据
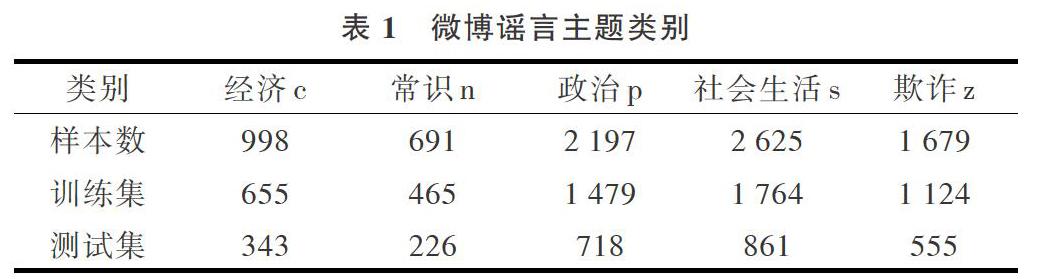
实验数据为刘知远等[1]给出的微博谣言数据,其将谣言主题分为5个类别:政治、经济、欺诈、社会生活与常识类,总共8 190条微博,数据详细信息如表1所示。为便于进行分类模型的实验比较,本文随机抽取原始数据中的 2/3作为训练集,构建分类模型,其余1/3数据作为测试集,测试模型的分类性能。
2.2 数据预处理
由于微博中存在繁体文字,因此首先使用OpenCC工具将微博中的中文繁体转为中文简体,然后采用中科院分词工具NLPIR对微博进行分词,并结合哈工大停用词表和百度停用词表,将部分词从中移除,以提高主题分类性能。
2.3 微博文本向量计算
由于微博属于短文本,大部分微博长度都不会超过140词限制,且本文使用的数据均属于短文本范畴,因此采用文本词向量加权平均方法计算微博文本向量。词向量维度根据经验选择200维,经过计算后微博文本向量维度也是200维。词向量使用Wiki中国作为语料库,计算结果作为词向量。
2.4 实验结果
使用NB、KNN与SVM进行分类建模,比较3种模型在微博文本向量作为特征的情况下,微博谣言主题分类的准确率,如表2所示。从表中可见,KNN模型在该谣言数据集上获得了最好的分类准确率0.93,远高于NB模型的0.79,比SVM也高了3个百分点,因此KNN与SVM模型在该谣言数据集主题分类方面是比较有效的。
不同主题下各分类模型的F1分数如图2所示,在经济与欺诈类主题下,KNN和SVM都取得了相同的F1-score,在常识、政治与社会生活类主题下,3种分类模型的F1-score都低于经济与欺诈类主题下的F1-score,即常识、政治与社会生活类主题比较容易混淆。
KNN模型混淆矩阵如表3所示,从表中可以发现,该模型将社会生活类谣言错分成政治类的有43个,占实际社会生活类谣言总数的4.99%,将政治类错分为社会生活类的有33个,占实际政治类谣言总数的4.60%。以上两种类别不太容易区分,以后可考虑进一步提取特征,以提高模型在该类别上的分类准确率,进而提高模型的整体主题分类性能。
4 结语
本文以新浪微博谣言数据作为分析对象,使用词嵌入方式表示微博文本特征,进行微博谣言数据的主题分类。谣言主题可分为经济类、常识类、政治类、社会生活类与欺诈类。本文选择NB模型、KNN模型及SVM模型作为分类模型,对微博谣言数据集进行主题分类。由实验结果可以发现,KNN模型在谣言主题分类中表现出最好的分类性能,其F1值和分类准确率都达到0.93。通过对KNN模型的混淆矩阵进行分析,发现社会生活类与政治类谣言最不易区分,因此未来工作需要进一步寻找特征,以提高模型在以上两个主题类别上的分类准确率,进而提高模型整体的主题分类性能。
参考文献:
[1] 刘知远,张乐,涂存超,等. 中文社交媒体谣言统计语义分析[J].中国科学: 信息科学,2015, 45(12):1536-1546.
[2] 任宁,李金仙. 带有反对机制的谣言传播模型[J]. 云南民族大学学报:自然科学版,2019(1):67-71.
[3] 王飞雪,李芳. 社交网络中考虑不同传播概率上的谣言传播模型[J]. 计算机应用研究,2019(11):1-4.
[4] 王雨嘉,侯合银. 小世界网络中基于一种改进模型的谣言传播研究[J/OL]. 情报杂志:1-11[2019-02-26]. http://kns.cnki.net/kcms/detail/61.1167.g3.20190222.1319.012.html.
[5] 刘雅辉,靳小龙,沈华伟,等. 社交媒体中的谣言识别研究综述[J]. 计算机学报,2018,41(7):1536-1558.
[6] 张仰森,彭媛媛,段宇翔,等. 基于评论异常度的新浪微博谣言识别方法[J/OL]. 自动化学报:1-14[2019-02-26]. https://doi.org/10.16383/j.aas.c180444.
[7] 丁晟春,王小英,刘梦露. 基于本体和加权朴素贝叶斯的网络舆情主题分类[J]. 现代情报,2018,38(8):12-17.
[8] 贾隆嘉,张邦佐. 高校网络舆情安全中主题分类方法研究——以新浪微博数据为例[J]. 数据分析与知识发现,2018(7):55-62.
[9] 程元堃. 基于URL+文本的网页主题分类模型研究[D]. 武汉:武汉邮电科学研究院,2018.
[10] 黎巎,谢宗彦,张公鹏,等. 基于LDA的游客网络评论主题分类:以故宫为例[J]. 情报工程,2017,3(3):55-63.
[11] 胡朝举,徐永峰. 基于LDA特征扩展的短文本分类方法研究[J]. 软件导刊,2018,17(3):63-66.
[12] 宗乾进,黄子风,沈洪洲. 基于性别视角的社交媒体用户造谣传谣和举报谣言行为研究[J]. 现代情报,2017,37(7):25-29,34.
[13] 姜赢,张婧,朱玲萱,等. 网络谣言文本句式特征分析与监测系统[J]. 电子设计工程,2017,25(23):7-10,15.
[14] HINTON G E, SRIVASTAVA N, KRIZHEVSKY A, et al. Improving neural networks by preventing co-adaptation of feature detectors[J]. Comput Science, 2012,3: 212-223.
[15] GRAVES A, MOHAMED A, HINTON G. Speech recognition with deep recurrent neural networks[C]. Proceedings of the International Conference on Acoustics, Speech and Signal Processing, Vancouver, 2013:6645-6649.
[16] KIM Y. Convolutional neural networks for sentence classification[C]. Proceedings of the Conference on Empirical Methods in Natural Language Processing, Doha, 2014:1746-1751.
[17] CHEN H M, SUN M S, TU C C, et al. Neural sentiment classification with user and product attention[C]. In: Proceedings of Conference on Empirical Methods in Natural Language Processing, Austin, 2016:1650-1659.
[18] 高成亮,徐華,高凯. 结合词性信息的基于注意力机制的双向LSTM的中文文本分类[J]. 河北科技大学学报,2018,39(5):447-454.
[19] LE Q V, MIKOLOV T. Distributed representations of sentences and documents[C]. In Proceedings of the 31st International Conference on International Conference on Machine Learning,2014.
[20] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space[J]. Computer Science,2013.
(责任编辑:黄 健)
