蝙蝠算法优化极限学习机的滚动轴承故障分类
2019-05-27覃爱淞吕运容张清华孙国玺
覃爱淞,2,吕运容,张清华,胡 勤,孙国玺
(1.广东石油化工学院 广东省石化装备故障诊断重点实验室,广东 茂名 525000;2.广东省石油化工装备工程技术研究中心,广东 茂名 525000)
0 引言
在滚动轴承故障诊断研究中,通常采用时域或频域分析方法对振动监测数据进行故障诊断。由于时域信号是最基本、最原始的信号,直接通过时域信号进行故障特征提取,进行故障诊断,将有利于保持信号的基本特征。在时域分析中,广泛采用无量纲指标,如脉冲指标,峭度指标,裕度指标,波形指标和峰值指标[1],但这些指标只对某些故障种类较为敏感,而对其他一些故障种类分类效果可能不好[2]。因此文献[3-4]利用遗传编程方法对传统5种无量纲指标进行组合优化,通过构建新无量纲指标进行故障诊断,但是该方法对于混叠程度很大的样本数据时,通常也往往难以获得一个具有较好分类能力的无量纲指标。
极限学习机(Extreme Learning Machine,ELM)是一类针对前馈神经网络设计的机器学习算法[5],它学习效率高,计算复杂度低,同时它克服了梯度下降算法的一些缺点,但是隐含层个数预先分配、隐含层参数随机选择、参数在训练过程中保持不变,这些参数的设置直接影响ELM分类结果,只有设置合适的参数才能取得较好的性能。
为了解决此问题,本文采用蝙蝠算法对ELM进行参数优化,提高故障诊断准确率。蝙蝠算法(Bat algorithm,BA)是一种新兴的启发式群智能算法,是一种基于迭代的优化技术,可以实现局部搜索和全局搜索间的相互转换,因此,避免算法陷入局部最优,具有更好的收敛性[6-7]。与现有的遗传优化算法和粒子群优化算法相比,BA算法具有更好地局部搜索和全局搜索的性能,研究人员和学者已经广泛地将BA应用于各种优化问题[8-9]
目前研究中直接采用原始无量纲指标作为故障特征参量,并结合经蝙蝠算法优化后的极限学习机进行诊断的研究甚少,大多数文献在采用极限学习机或者改进的极限学习机之前,运用了各种特征提取和选择方法[10-12]。本文以原始机械振动信号作为输入,对振动信号不做任何处理,保留振动信号最真实的面貌,直接采用原始信号的5个无量纲指标作为诊断参数,结合蝙蝠极限学习机(BA-ELM)方法,将其运用到滚动轴承故障诊断中,经过美国西储大学(Case Western Reserve University,CWRU)轴承数据中心网站公开发布的轴承探伤数据集的验证,相比BP神经网络、SVM和ELM3种方法,本文所提出的方法能够获得更高的分类精度。
1 相关算法介绍
1.1 蝙蝠算法
蝙蝠算法[13]是Yang教授于2010年提出的一种模拟蝙蝠利用声呐来探测猎物、避免障碍物的启发式搜索算法,可以实现动态控制局部搜索和全局搜索间的相互转换。因此,蝙蝠算法有更好的寻优能力、更快的收敛速度。蝙蝠算法的具体实施过程详见文献[14]。
1)蝙蝠个体的速度更新和位置更新。

(1)
式(1)中:Y*为当前全局最优解,fi是蝙蝠个体i的搜索脉冲频率,按式(2)进行更新。
fi=fmin+(fmax-fmin)λ
(2)
式(2)中:λ属于[0,1]是均匀分布的随机数,fmin和fmax是最小和最大搜索脉冲频率,种群初始化时随机给定搜索脉冲频率范围[fmin,fmax]。
在局部搜索中,一旦选中一个当前的全局最优解,则该解将根据式(3)产生一个新的替代解:
Yn(i)=Y0+μAt
(3)
式(3)中:Y0是当前的全局最优解,At为当前蝙蝠种群脉冲音量的平均值,μ为-1和1之间的D维随机向量。
2)蝙蝠个体的脉冲率更新和脉冲音量更新。
蝙蝠在迭代进化过程中,随着不断靠近最优解,蝙蝠个体的脉冲率ri会越来越大,而脉冲音量Ai则会逐渐变小,进化过程按式(4)对ri和Ai进行更新:
(4)
式(4)中:α和γ通常等于0.9。
1.2 极限学习机算法
极限学习机是一种泛化的单隐藏层前馈神经网络的机器学习算法,其输入层和隐含层间的连接权值和隐含层阈值随机产生,且训练过程中无需调整,从而可以避免迭代调整神经网络参数的繁琐[5]。
假设有N个任意的样本(Xi,ti),其中,Xi=(xi1,xi2,...,xin)T∈Rn,ti=(ti1,ti2,...,tin)T∈Rm,n为输入层的维度,m为输出层的维度。对于一个具有L个隐层节点的单隐层前馈神经网络输出可以表示为:
(5)
其中:i=1,2,...,N,Wj=(wj1,wj2,...,wjn)T为输入权重,βj=(βj1,βj2,...,βjm)T为输出权重,bj是第j个隐层单元的偏置,Wj·Xi表示Wj与Xi的内积,g(x)激活函数。
单隐层前馈神经网络学习的目标是在最小的误差下逼近N个样本,可以表示为:
(6)
即存在Wj,βj,bj使得:
(7)
可简化为Hβ=T,其中,H是隐层节点输出矩阵,β为输出权重,T为期望输出。
H(W1,W2,...,WL,b1,b2,...,bL,X1,X2,...,XL)=

(8)

j=1,2,...,L
(9)
当单隐层前馈神经网络的输入权重Wi和隐含层偏置bi随机确定后,隐层的输出矩阵H就会被确定,单隐层神经网络的求解过程就会被转换成一个线性系统Hβ=T的求解问题,输出权重β可由式(10)确定。
(10)
2 基于BA-ELM的滚动轴承故障诊断
2.1 无量纲指标
采用无量纲指标直接对原始信号进行分析处理,可以有效地减少误差,获取更多的故障信息。本文选取5个常用的时域无量纲指标作为样本的特征向量,分别是峭度指标Kv、波形指标Sf、峰值指标Cf、裕度指标CLf、脉冲指标If,具体的定义分别如式9~13。BA-ELM模型的输入层节点数为5。
(11)
(12)
(13)
(14)
(15)

2.2 ELM的参数优化
为了提高ELM方法的分类精度,本文将蝙蝠算法用于ELM网络输入层和隐含层的参数优化,利用蝙蝠算法的全局寻优能力,获取最优的ELM输入层权值和隐含层阈值,输出权重可由式(10)确定,从而弥补ELM因参数选择不良造成诊断准确率不够高的缺陷。BA算法优化ELM模型参数的流程图如图1所示。

图1 BA优化ELM模型参数
假设有N个任意的样本(Xi,ti),其中,Xi=(xi1,xi2,...,xin)T∈Rn,ti=(ti1,ti2,...,tin)T∈Rm,n为输入层的维度,m为输出层的维度,g(x)为激活函数,隐含层节点数为L,BA算法优化ELM模型参数的主要过程如下:
1)初始化参数。最大迭代次数N_iter=50,初始种群数量N_pop=20,最大脉冲音量A0=1.6和最大脉冲率r0=0.000 1,搜索脉冲频率范围[fmin,fmax]=[0,2],音量的衰减系数α=0.9,搜索频率的增强系数γ=0.99;
2)随机初始化蝙蝠的位置Yi,其由ELM网络的输入层权重Wi和隐含层偏置bi组成,计算隐层节点输出矩阵H,通过式(10)确定相应的输出权重β;
3)适应度函数的设计。本文采用分类结果的均方根误差作为BA算法的适应度函数,其表达式如式(16)所示,进化过程选择适应度值最小的个体作为当前最优解;
(16)
4)调整蝙蝠的搜索脉冲频率,对速度和位置进行更新,获取下一代种群;
5)判断是否满足中止条件,如果满足,输出蝙蝠全局最优位置对应的ELM参数(输入权值Wi和隐含层偏置bi),输出权重β可由式(10)确定。否则返回步骤2),重复步骤2)~5)。
2.3 基于BA-ELM的滚动轴承故障诊断


图2 基于BA-ELM方法的滚动轴承故障诊断流程图
基于BA-ELM的滚动轴承故障诊断流程如图2所示。首先将滚动轴承不同状态下的原始信号数据进行数据分割,分别计算5种时域无量纲指标构建5维特征向量,作为极限学习机的输入向量;其次采用蝙蝠算法优化极限学习机参数,通过训练样本对ELM进行训练,获取最优的ELM诊断模型;最后将该诊断模型作为最终的分类器,对测试样本进行识别分类。
3 实验结果与分析
3.1 数据采集
为了验证上述方法的有效性,实验所用的数据是CWRU轴承数据中心网站公开发布的轴承探伤测试数据集,此数据已被国内外故障诊断领域中的学者广泛研究,成为验证机械设备状态识别新方法的标准数据集。机械故障模拟实验平台由1.5 kW电动机、扭矩传感器/译码器、功率测试计和电子控制器等组成,如图3所示,模拟产生多种轴承故障。轴承用电火花加工单点损伤,损伤直径0.021英寸,加速度传感器布置在驱动端的轴承座上用来采集故障轴承的振动加速度信号,对轴承正常状态(NS)、内圈故障(IF)、外圈故障(OF)和滚动体故障(BF)4种状态信号分别进行采样,转速为1 797 r/min,采样频率为12 kHz。

图3 机械故障模拟实验平台
3.2 数据处理
每种故障采集的数据点高达120 000以上,因此对同一故障的数据进行分割,分割后每个样本包含的数据点长度为1 024点,根据式(11~15)分别计算出5种时域无量纲指标,获得每种状态各110组样本,其中80组作为训练样本,余下30组作为测试样本。5种时域无量纲指标(Kv、Sf、Cf、CLf和If)对轴承4种工作状态的取值范围见图4,横坐标为数据样本个数,其中样本段1~110、111~220、221~330、331~440分别对应轴承正常、内圈故障、外圈故障和缺滚动体故障4种状态,纵坐标为无量纲指标值。
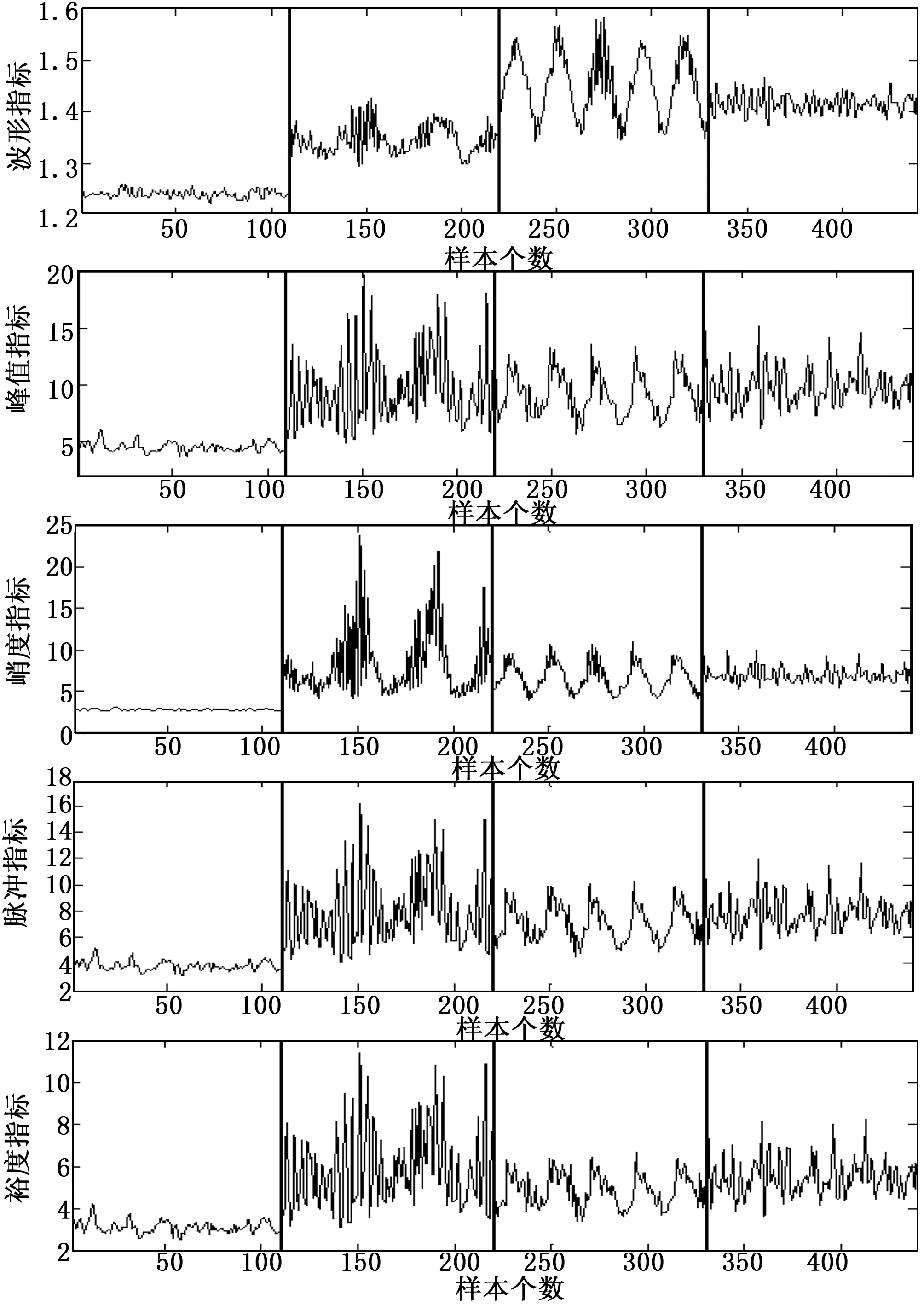
图4 无量纲指标对轴承4种工作状态分类比较图
从图4可以看出,虽然5个无量纲指标均能够将正常状态和3种轴承故障状态进行区分,但是滚动轴承3种故障状态的5种无量纲指标的取值范围存在严重交叉、混叠,并且指标值的波动很大,无法直接通过5个无量纲指标实现对故障状态的区分,为了解决这个问题,下文将采用极限学习机的方法来实现对4种轴承状态进行分类。
3.3 分类结果与分析
将训练样本作为BA-ELM模型的输入进行网络训练,输入层节点数为5,隐含层节点数L=30,激活函数选用sigmoidal函数,输入权重和隐含层偏置由BA算法优化得到,获取分类效果最佳的滚动轴承状态辨识模型,利用测试样本检验分类器的准确性。BA算法优化过程的适应度值如图5所示。

图5 BA的适应度变化曲线图
从图5可以看出,BA算法优化过程收敛非常快,从第5代开始,适应度值保持0.008 3保持不变,满足终止条件,输出最优解,获取ELM最优的输入权重和隐含层偏置。此时,BA-ELM模型对轴承故障的平均分类准确率为99.17%,测试样本的诊断结果如表1所示,从表1中可以看出,120个测试样本仅有1个样本诊断错误,说明该方法可以对滚动轴承的故障进行非常精确地诊断。

表1 测试样本的诊断结果
同时,为了进一步验证BA-ELM诊断模型对滚动轴承故障具有诊断率高的优势,利用上文的实验数据,分别采用BP神经网络、SVM和ELM算法等3种方法构建诊断模型,利用训练样本和测试样本分别进行训练和测试,3种诊断模型和BA-ELM模型的故障分类精度对比见表2。其中,BP隐含层节点个数S设为30;SVM人为选择惩罚系数C=2,核宽度系数g= 0.2。从表2中很容易看出,虽然ELM模型的具有较高的诊断准确率为97.5%,120个测试样本有3个样本诊断错误,诊断准确率明显高于BP神经网络和SVM分类器,但是利用BA算法对ELM网络优化后的BA-ELM分类模型具有最高的诊断准确率,达到99.17%,120个测试样本仅有1个样本诊断错误,对轴承正常状态、内圈故障、滚动体故障的诊断准确率均达到100%,表明了基于BA-ELM滚动轴承故障诊断方法可以对滚动轴承的故障进行非常精确地诊断。

表2 4种状态辨识模型运行时间与分类精度的对比
4 结束语
本文提出了一种基于BA算法优化ELM的滚动轴承故障诊断分类算法,直接提取滚动轴承振动信号的时域无量纲指标作为BA-ELM模型特征向量输入进行故障状态的分类,经过实验结果表明,本文直接采用无量纲指标作为诊断参数,能够最大程度地保障原始信号的特征,避免了采用信号处理方法而导致局部信息丢失的缺陷;采用BA-ELM作为诊断模型,不仅可以最大化利用BA的全局和局部搜索能力和ELM的快速学习的优点,同时也克服了ELM固有的不稳定性,使得算法收敛速度快、诊断精度高,对滚动轴承故障诊断效果明显。
