实验数据的随机化检验及R语言实现
2019-05-24吕小康付英涛
吕小康 付英涛

摘 要 随机化检验是基于实验中对实验处理的随机化分配,通过计算所有可能分配方法的结果得出某一统计量的随机化分布,并据此进行实验效应是否存在的统计推断。相较基于从某一总体中进行重复随机抽样而得到抽样分布推论模式,随机化检验不需要正态总体假定,尤其适合样本数据存在明显离群值或小样本情形,更适合作为随机化实验的推论框架。借助免费开源的R软件及相关软件包已能快速实现双处理组和多处理组均值差比较及其他统计量比较的随机化检验,但在心理统计教育与应用中还需进一步推广。
关键词 随机化分布; 随机化检验; 显著性检验; 置换检验; 心理统计
分类号 B841.2
DOI: 10.16842/j.cnki.issn2095-5588.2019.05.001
1 统计推论中的总体模型与随机化模型
目前心理统计教材中介绍的统计推论方法大多基于抽样分布(sampling distribution)的框架,即将样本数据视为从特定总体中随机抽样得到的一次观测结果,并考虑对该总体进行同样本容量的重复抽样,以得到所关注的样本统计量的假想分布,进而计算相关p值来判断实验效应是否存在。心理统计的相关教材、包括其他领域的诸多入门统计教材一般都只是将随机化实验得到的数据默认为随机样本处理,对数据的正态性进行检验后,直接应用抽样分布进行统计推论。但从严格意义上说,这些随机化实验的数据并不是在总体中抽样得到的随机样本,并未直接满足应用抽样分布进行统计推论的条件。同时,随机化实验的目的通常也不是像基于随机抽样的研究那样要求将样本结论推论至总体、即追求外在效度,而是验证实验的处理效应是否真实存在、即追求内在效度。
事实上,统计学中进行统计推论有两种模型(Ludbrook, 2005):总体模型(population model)和随机化模型(randomization model)。将随机化实验的数据视为随机样本属于总体模型的思想,此模型假定实验数据是相应总体的随机样本,统计推论用到的抽样分布常为正态分布或由正态分布推导出的其他理论分布,对正态性假定的依赖性较强。而随机化模型不需要总体和样本的假定,其思想基于实验中的随机化操作,其统计推论无需依赖正态性前提、而是一种精确分布——随机化分布(randomization distribution),基于此种分布进行的显著性检验可称为随机化检验(randomization test)。
基于随机化分布进行显著性检验的思想,从其起源上讲并不晚于基于抽样分布的显著性检验,但囿于计算便利性上的欠缺而一直没有得到足够重视。随着计算机软件的发展,随机化分布的计算或模拟已不是问题,因此其思想又重新得到重视与实践。随机化检验早期常用来检验t检验或F检验的正确性,Fisher(1936)曾指出与随机化方法不一致的结论(t检验和F检验)是不合理的,因为其他方法通常涉及理论上的近似,而数据的真实形态可能并不能够满足使用这些近似公式所需要的前提条件。而在当代,随机化检验甚至被一些统计学家认为是“随机化实验情形下的金标准”(Edgington & Onghega, 2007),基于随机化分布的检验模式及相关探讨日渐增多(Basu, 2011; Dugard, 2014; Lu, Ding, & Dasgupta, 2015; Mielke, Berry, & Johnston, 2011),相关教材也不断面世(Berry, Johnston, & Mielke, 2014; Berry, Mielke, & Johnston, 2016; Dugard, File, & Todman, 2011)。但此種推论方式目前在国内外心理统计教材中仍介绍不多、在实践研究中的应用也较少,因此有必要加以说明与推广。本文将介绍随机化分布的理论假定及其实现方法,用免费开源软件R模拟随机化实验数据及其随机化分布,对比随机化分布和抽样分布的异同,并提出相应的教学与应用建议。鉴于国内心理学界的教学与研究目前多数仍使用商业化的SPSS或SAS等软件,对R软件的认识与应用尚未普及,正文中有少数R语言命令的示范,所有图片也使用R软件绘制,以增进国内对该软件的了解。
2 随机化检验的基本思想
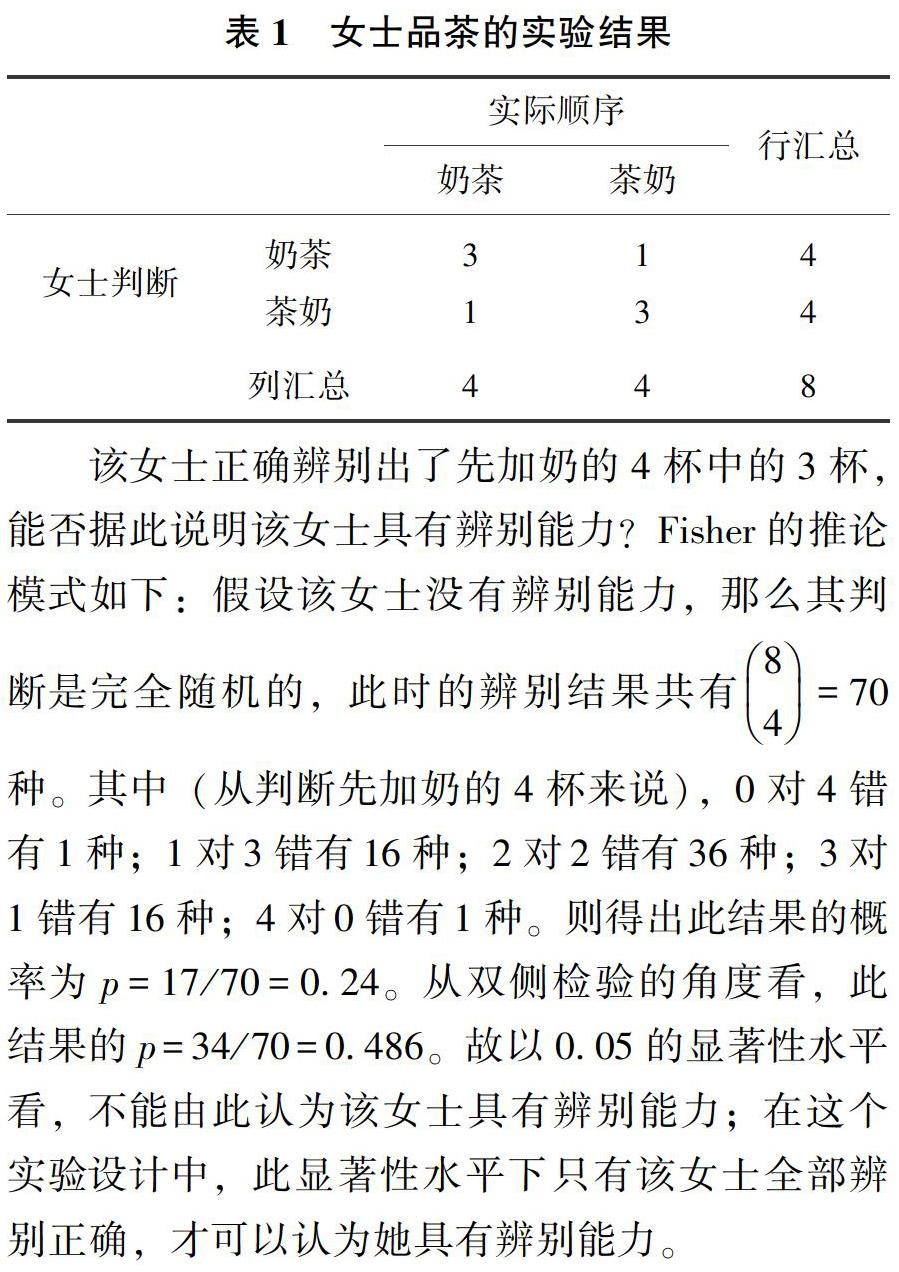
随机化检验的思想其实在20世纪初期就已经出现。较早的一个例子可见于统计学家Fisher(1935)的“女士品茶”名例。其情境大致如下。一名女士声称自己可以辨别奶茶里面先放的奶还是先放的茶,Fisher想通过实验验证这一点。故选取8杯奶茶,随机选取其中4杯先放奶,另外4杯先放茶,其他条件保持一致。以随机顺序让女士品尝后辨别出哪4杯先放了奶,哪4杯先放了茶。结果如表1。
该女士正确辨别出了先加奶的4杯中的3杯,能否据此说明该女士具有辨别能力?Fisher的推论模式如下:假设该女士没有辨别能力,那么其判断是完全随机的,此时的辨别结果共有84=70种。其中(从判断先加奶的4杯来说),0对4错有1种;1对3错有16种;2对2错有36种;3对1错有16种;4对0错有1种。则得出此结果的概率为p=17/70=0.24。从双侧检验的角度看,此结果的p=34/70=0.486。故以0.05的显著性水平看,不能由此认为该女士具有辨别能力;在这个实验设计中,此显著性水平下只有该女士全部辨别正确,才可以认为她具有辨别能力。
此例中随机化检验的思想已有所体现,即在原假设成立的条件下,根据所有可能的实验结果判断出现实际结果的可能性。但严格来说,Fisher的这种检验思想应称为置换检验(permutation test,其中permutation即排列的意思)而不是随机化检验,因为这一实验中并未涉及随机化分组。随机化检验实际上利用了置换检验的计算方式进行p值计算,但置换检验本身不一定仅适用于随机化实验的情形,也可适用于随机抽样的情形,是含义更为宽泛的一种检验。换言之,随机化检验可视为置换检验的一个子集(Edgington & Patrick, 2007)。不过,由于两者的区分主要在应用情境的区别而非计算方法的区分,在实际使用中两种方法也常被视为是同一种方法。
此外,Fisher(1935)在另一个配对比较问题中应用了随机化检验的思想。问题是比较有15个观测值的配对样本,两个样本的差异值是314。在此配对设计中给被试随机分配实验处理共有215种方式,在零假设条件下,所有可能的结果中有1726种情况大于等于314,即p=0.05267。而根据抽样分布得出的t值算出的p=0.0497,两者相差较小。
在Fisher(1925)、Geary(1927)、Eden和Yates(1933)、Pitman(1937a, 1937b, 1938)等人置换检验思想的基础上,Kempthorne(1955)等人开始着手发展更具一般性的随机化分布及检验的理论框架。实验设计中比较重要的一步是给被试分配实验处理,随机化要求这一过程在实验的约束条件下(比如区组内)是完全随机的,即在有限的所有可能的分配方式中随机选取一种,每种方式被选中的概率相等。选定一个统计量,计算零假设条件下所有可能的分配方式下该统计量的值,即得到该统计量的随机化分布。根据实验结果得出的统计量在随机化分布中的相对位置和设定的显著性水平,即可得出相应p值并判断是否拒绝零假设。
Kempthorne(1955)提出,随机化分布的应用依赖于被试—处理可加性假定(unit-treatment additivity)。其基本思想如下:每名被试的观测值可以视为被试本身的基本量和所接受处理效应的加和。用i表示参加实验的被试,i=1,2 …,N;t表示实验处理,t=1,2,…,T。随机分配每名被试接受一种实验处理,如果被试i接受了实验处理t,得到的观测值可以表示为:
在假设实验处理效应相同的条件下,只需要对实验结果进行随机化排列即可得到所有可能的结果,进而选择某个适合的统计量并计算它在每种分配方式下的取值,就可以得到该统计量对应的随机化分布。再通过计算该分布中如此次样本观测值这么极端、更为极端值(所谓“极端”即指偏离原假设的设定)占整个分布中所有可能取值的比例,即可得到相应p值。这就是利用随机化分布进行显著性检验的基本模式。
随机化分布的思想框架较为直观,并不需要假想存在实验处理组之外的一个“(正态)总体”,这对于实际研究者理解统计推论的思维框架是较为便利的。问题在于其计算过程比较麻烦。随着样本量和处理组数的增加,实验结果的可能性会大大增加;对于复杂问题的可能结果排列需要花费相当长的时间,往往超过手动计算或公式推导的可能。因此随机化检验在计算机软件兴起之前并未得到太多重视。但随着計算机的发展,随机化结果的计算不再是问题,并且可以通过软件对随机化分布实现可视化,理论假定更少、结果更加精确的随机化检验又逐渐开始受到重视(Ludbrook & Dudley, 1998; Rubin, 1991)。
3 基于随机化分布的统计推论示例:基于R的应用
随机化检验通常用于检验不同实验组之间的处理效应是否真实存在,故通常不能应用于单样本数据的情形。这里仅就最一般意义上的双处理组和多处理组情形做出示例。
3.1 双处理组情形:与传统t检验的比较
不妨先考虑随机分配被试到两种实验处理的情况,此时的随机化过程发生在被试之间,实验结果为独立的双样本数据。用R模拟服从特定正态分布的随机数,样本量为7。
此时=20.29,s2x=18.90,=15.57,s2y=21.95。能否根据上面的数据得出结论:实验处理X的效果大于处理Y的效果?
这显然是一个单侧检验问题。基于传统抽样分布的统计推断模式如下:将两种实验处理下的结果看作是来自两个独立同方差的正态分布总体的简单随机样本。结果可算得t=1.95,p=0.037,在0.05显著性水平下可认为实验处理X的效应大于Y。由于这一检验公式较为常见,故这里不再具体叙述相关过程。R中的命令如下:
t.test(X, Y, var.equal=TRUE, alternative="greater") # 执行同方差前提下的双样本单侧t检验
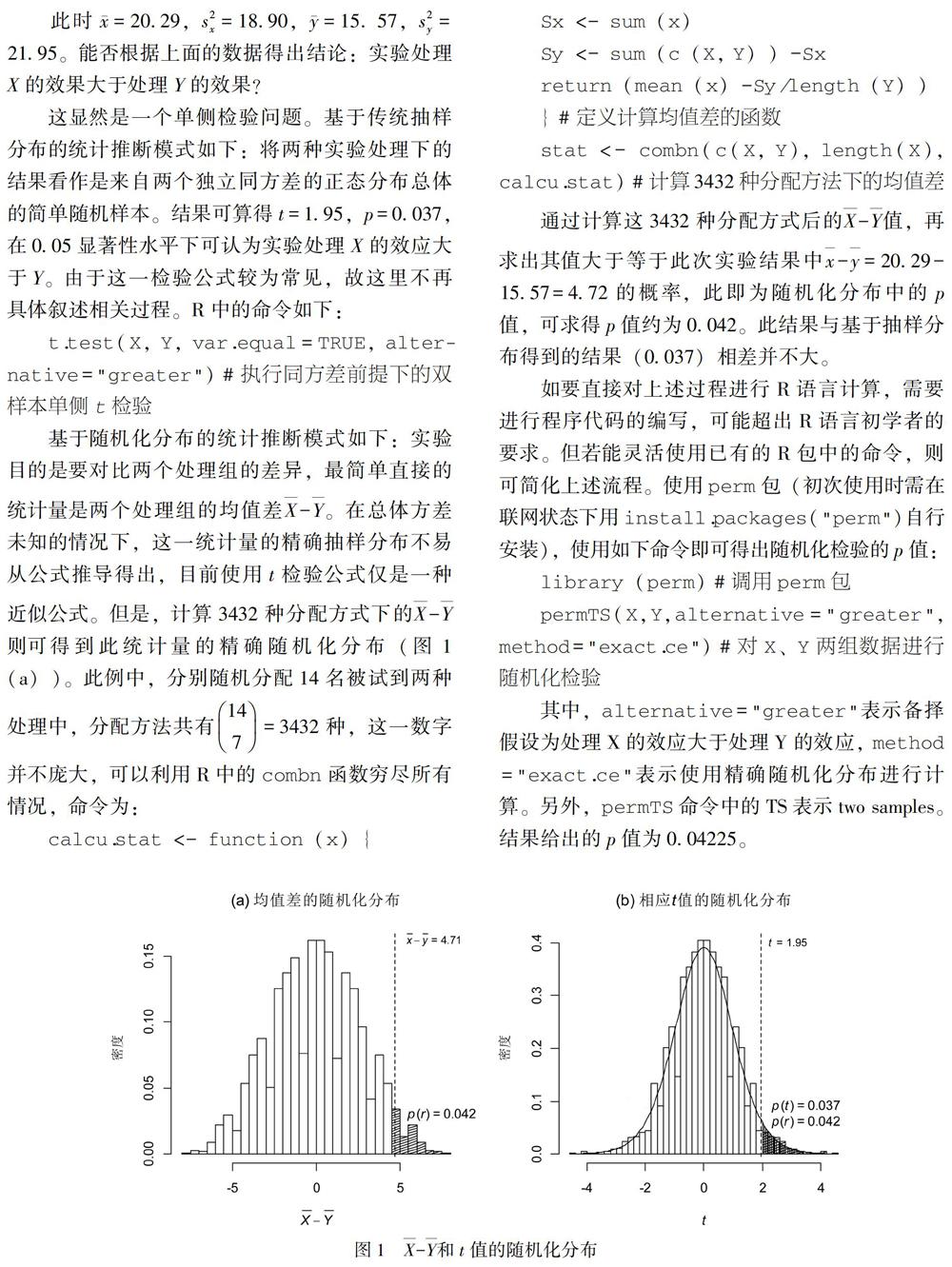
基于随机化分布的统计推断模式如下:实验目的是要对比两个处理组的差异,最简单直接的统计量是两个处理组的均值差X-Y。在总体方差未知的情况下,这一统计量的精确抽样分布不易从公式推导得出,目前使用t检验公式仅是一种近似公式。但是,计算3432种分配方式下的X-Y则可得到此统计量的精确随机化分布(图1(a))。此例中,分别随机分配14名被试到两种处理中,分配方法共有147=3432种,这一数字并不庞大,可以利用R中的combn函数穷尽所有情况,命令为:
calcu.stat<-function(x){
Sx<-sum(x)
Sy<-sum(c(X, Y))-Sx
return(mean(x)-Sy/length(Y))
} # 定义计算均值差的函数
stat<-combn(c(X, Y), length(X), calcu.stat) # 计算3432种分配方法下的均值差
通过计算这3432种分配方式后的X-Y值,再求出其值大于等于此次实验结果中x-y=20.29-15.57=4.72的概率,此即为随机化分布中的p值,可求得p值约为0.042。此结果与基于抽样分布得到的结果(0.037)相差并不大。
如要直接对上述过程进行R语言计算,需要进行程序代码的编写,可能超出R语言初学者的要求。但若能灵活使用已有的R包中的命令,则可简化上述流程。使用perm包(初次使用时需在联网状态下用install.packages("perm")自行安装),使用如下命令即可得出随机化检验的p值:
library(perm) # 调用perm包
permTS(X,Y,alternative="greater", method="exact.ce") # 对X、Y两组数据进行随机化检验
其中,alternative="greater"表示备择假设为处理X的效应大于处理Y的效应, method="exact.ce"表示使用精确随机化分布进行计算。另外,permTS命令中的TS表示two samples。结果给出的p值为0.04225。
除此之外,还可以另一种思路进行随机化检验,即计算每种排列情形下的传统双样本t检验观测值,从而求出此t值的随机化分布。再基于分布计算此次实验中的t观测值在多大程度上偏离原假设(t=0),从而得到相应p值。图1(b)是覆盖了t分布曲线的随机化分布,p(r)表示随机化(randomization)情形下的p值,p(t)表示传统抽样分布t检验下的p值。此次实验得出的结果为t=1.95,在此随机化分布中p(t≥1.95)=0.042。显然,以X-Y作为统计量计算出的p值和以t值作为统计量得出的p值相同,这是因为根据每种分配方式的结果计算出的t值和X-Y是一一对应的。
对于上述实验处理数和样本量比较少的情况,可以计算所选统计量的精确随机化分布,这里所谓“精确”(exact),其实只是“完整”的意思,即穷尽了所有可能的随机分配情况。但在实际研究中经常会遇到实验处理和样本量比较多的情况,即使有计算机的帮助,计算所有的分配方式也往往不现实,但可以在R中运用sample函数进行一定次数的模拟,即在所有可能的分配方式中进行重复抽样,得出近似随机化分布。用R对此例进行10000次抽样得出的近似随机化分布,p值为0.039,与精确随机化分布稍有差异,这是因为随机取样所产生的抽样误差所致。
现考虑上文中的随机数为配对样本的情形。传统t检验模式下,可算得p值为0.08248,在0.05的显著性水平下没有充分理由认为 X的实验处理效应显著高于 Y 的实验处理效应。R语言命令如下:
t.test(X, Y, paired=TRUE, alternative="greater")
如果采用随机化检验,此例中由于随机化发生在每个被试内部,每个被试共有2种处理分配顺序,故共有27=124种分配方式。通过计算每种分配方式下的配对均值差,即可得到其精确随机化分布。再计算此分布中大于等于此次实验结果中的配对差值所占的比例,即可得到相应p值。这里使用exactRankTests包中的函数来做示范。
library(exactRankTests)
perm.test(X, Y, alternative="greater", paired=TRUE)
结果给出的p值为0.09375,与配对样本t检验的结果也很接近。
3.2 多处理组情形:与传统方差分析的比较
如果把上例中实验处理数扩大为四组,其结果如表3。其中A、B、C和D的数据分别取自正态分布总体N1(20, 52),N2(17, 52),N3(15, 52),N4(13, 52)。其命令如下:
检验多个实验组的均值是否具有显著差异的常用方法是方差分析。此例中所有样本数据来自同方差的正态总体,故适宜使用传统方差分析进行显著性检验,结果为F=3.74,p=0.0246,在0.05显著性水平下可认为各实验处理的效应并不完全相同。对应的R语言命令如下(这里先对数据格式进行变动,以变成软件处理所需要的长格式数据):
dataABCD<-data.frame(A, B, C, D)
library(tidyr) # 调用tidyr包,以进行数据操纵
ABCD<-gather(dataABCD, group, value, factor_key=TRUE) # 将数据变成长格式数据,各分组信息存为一列,命令为group,各取值信息存为另一列,命令为value,factor_key=TRUE 用于确保group为因子变量、即类型变量
fit1<-aov(value~group, data=ABCD) # 进行方差分析
summary(fit1) # 给出方差分析结果
基于随机化分布的统计推断模式如下。此例中随机分配28名被试到4种处理中的方式共有
287×217×147×77=4.73×1014
种。此时要穷尽所有的分配方式得出精确的随机化分布是不现实的,但可以通过对所有分配方式的随机抽样得到近似的随机化分布。先选取F值作为统计量,分别计算每种分配方式下的F统计量即得其近似随机化分布,再根据此分布、此次观察结果得到的F值,即可算出相应p值。F值得随机化分布如图2,由此得到的p值为0.0226,这与传统F检验的结果非常接近。
c=10000 # 设定模拟次数
F.stat<-numeric(c) # 构建F统计量变量
F.stat[1]<-summary(aov(value~group, data=ABCD))[[1]][4][[1]][1] # 设此次观察为第一个值
set.seed(1234) # 设定循环种子数
for(i in 2:c){
F.stat[i]<-summary(aov(sample(value)~group, data=ABCD)) [[1]] [4][[1]][1]
} # 随机抽取其他分配方法的F值
p=mean(F.stat>=F.stat[1]) # 計算p值
对上述过程进行编程计算稍显麻烦,使用用coin包中的函数可简介上述过程:
library(coin)
oneway_test(value~group, data=ABCD, distribution=approximate(B=10000))
其中B=10000即表示进行10000次模拟。计算结果可得p值为0.02433。这与传统F检验的p值非常接近。实际上,当方差分析的假定未被明显违背时,随机化检验的优势并不明显。但当数据明显呈现偏态、尤其是各组方差相差较大时,使用传统检验方法会存在统计上二类错误的增大问题,此时使用随机化检验来做判定则可使统计决策更为稳健。值得注意的是oneway_test函数使用的随机化检验方法为Pitman-Fisher法,其检验统计量的选取与前面的模拟有所不同,具体可参见Boik(1987)。
下面考虑随机区组设计的情形。将表2问题的表述稍作变动,假设表中的数据是7个区组接受4种实验处理的情况,每个区组有4名被试,每名被试随机接受一种实验处理。此时就变成了一个随机区组问题,从数据处理方法上讲则是双因素方差分析的过程。传统方差分析结果为F=3.46,p=0.0382。R中的命令如下:
library(dplyr)
block<-as.factor(c(1:7)) # 生成区组标签
blockABCD<-data.frame(A, B, C, D, block)
newABCD<-gather(blockABCD, group, value,-block, factor_key=TRUE)
fit2<-aov(value~block+group, data=newABCD)
summary(fit2)
随机化检验的模式如下。在4种处理没有差异的原假设下,由于對随机化在区组内进行,此时随机化分配方式共有(4×3×2×1)7=4586471424种。虽然用软件可以一一计算各分配下的F值,但耗时较长,故仍可考虑使用随机抽样的方式进行模拟。这里只用coin包中的oneway_test函数进行示范。
library(coin)
oneway_test(value~group | block, data=newABCD, distribution=approximate(B=100000)) # | block表示指定区组名称
结果得到的p值为0.03259,与传统检验的结果也很接近。
4 随机化分布和抽样分布的比较:样本量与离群值的影响
对于正态性拟合良好的数据,抽样分布是随机化分布的良好近似。在图1(a)和图2中,将t分布和F分布曲线覆盖在相应随机化分布上,两者均拟合良好。这是因为用R模拟的数据均是来自正态分布总体,数据的正态性可以得到保证。下面以两个处理组的情况为例,考虑两个影响数据正态性的因素——样本量和离群值(outliers)。
此处考虑服从偏态分布和正态分布的两种数据。对数正态分布是一种右偏态分布,对服从对数正态分布的数据取对数可以得到正态分布数据。图3(a),(c),(e)的样本是从对数正态分布中抽样得到的右偏态数据,样本量分别为5,10和20。图3(b),(d),(f)的样本是对相应样本量的右偏态数据取对数得到的正态数据。
取样本量为5的偏态样本程序如下:
set.seed(123)
x<-rlnorm(5, 1)
set.seed(321)
y<-rlnorm(5, 0.5)
其他样本量的情形可依此得出。图3中可以直观地看到不同分布形态和不同样本量的数据对随机化分布和t分布拟合状况的影响。可以发现:(1)偏态数据和正态数据相比而言,正态数据的随机化分布和t分布拟合得较好,这一点在样本量较小的情况下体现得尤其明显;(2)当样本量较小的时候,即便对于正态性数据而言,抽样分布与随机化分布的拟合状况也是比较差的;(3)而样本量较大时,即使数据呈现偏态,抽样分布与随机化分布也拟合得较好,这正是传统t检验在双处理组数据中得到普遍应用的原因之一。
另外,比较由随机化分布和t分布得出的p值可以作为衡量拟合状况的一个指标。图4是对于偏态数据而言,样本量从5~50变化时,由随机化分布和t分布得出的p值变化。图4(a)随机化分布p值和t分布p值随样本量的变化情况,(b)是两个p值差随样本量的变化情况。
从图4可以看出,总体而言随机化分布和t分布得出的p值是比较一致的。对于偏态数据而言,样本量的增加可以有效地使p值减小,尤其是在样本量增加到30之后。这一方面增大了统计检验力,另一方面也使随机化分布和t分布得出的p值差异逐渐减小。
下面考虑离群值的影响。以表2中的数据为例,图5中(a),(b),(c),(d)是假设表2中X组最大值分别为28,38,48,58时的随机化分布。可以发现,离群值距离均值越远,随机化分布和t分布的拟合状况越差,根据两者得出的p值相差越大。Ernst(2009)通过设置样本最小值的方法探讨了离群值对随机化分布和t分布拟合状况的影响,与此结论一致。由于t检验假定其数据是取自正态分布总体的随机样本,因此当不能保证样本的随机性和正态性时,t检验的结果理论上不能保证其准确性。而基于随机化分布的检验不需要正态性假定,也无需随机样本。若其分布呈现偏态、样本量较少或存在离群值时,基于随机化分布的检验结果更令人信服。不过,当样本量较大时,t检验的结果对数据的正态性要求不高,与随机化分布的结果差异不大。
5 总结与建议
随机化检验依赖于实验处理的随机化分配和处理效应的可加性假定,不适合观测数据,但较适合具有两个或多个处理组的随机化实验结果的显著性检验。在推理框架上,随机化检验并不需要假想总体的存在,这更有利于初学者理解随机化实验的实际情境,更适宜作为随机化实验的统计推论框架。同时,随机化检验并不需要假定总体的分布形态,因此比基于抽样分布的假设更具灵活性,可以适用于传统显著性检验不能胜任的情形。虽然目前随机化实验的显著性检验常常通过抽样分布理论给出,这是因为很多情况下抽样分布理论对数据正态性的要求并不十分严格。随着实验处理数和被试数的增多,基于抽样分布的显著性检验与基于随机化分布的显著性检验越来越接近。在许多情况下,两者在实验处理数和被试数较少时仍有良好的近似性。因此,运用抽样分布对随机化实验的结果进行推论多数情况下是比较可靠的。
但在以下几种情况中,建议基于随机化分布进行推论而非抽样分布,或者至少将随机化分布的结果作为必要参考。(1)样本数据量过少。样本数据量过少带来的问题是无法保证数据的正态性,即使是從正态总体中抽取的小样本,抽样分布和随机化分布的拟合状况也很差。(2)样本中存在较严重的离群值。此时或者找出产生离群值的原因,将离群值进行剔除使数据符合抽样分布条件,或者没有合理的理由剔除离群值,此时需考虑随机化分布方法。(3)需选取的统计量难以从公式推导得出。随机化分布的统计量选取更加自由,许多统计量的抽样分布难以计算,但是研究者可以根据需要选择合适的统计量计算其随机化分布。例如离群值对于抽样分布的统计量往往影响较大,但对中位数、四分位数之类的统计量影响就较小,它们的理论分布通常难以求得。除此之外,对于计数数据和等级数据而言,常常利用一些近似估计和检验,可能会造成近似误差,此时随机化分布的应用更应当得到重视(Eudey, Kerr, & Trumbo, 2010)。
最后需要说明的是,对于心理统计的教育与应用而言,随机化检验的思想并不复杂,但计算比较繁琐,教学过程中可以借助R之类的软件进行辅助教学或计算。这需要对软件的应用有一定了解。鉴于目前R、Python等开源统计软件尚未成为国内心理统计主流软件,加强对此类软件的宣传和应用仍是必要的。实际上,这些软件已经具备不亚于SPSS或SAS的统计分析功能,在某些方面甚至更胜一筹。促进软件应用的开源化、免费化,对于国内的心理学教学和研究单位节省统计软件方面的支出或避免软件使用上的版权问题,也是具有积极意义的。其中,除了文中提到的perm、exactRankTests、coin等R包外,还有ez、AUtests、flip、jmuOutlier、jmuOutlier、treeperm等软件包提供了丰富的随机化检验函数与算法,可供研究者进一步探索利用。当然,相较于发展更为成熟的总体模型推论,一些复杂实验设计的随机化检验模式仍还有待开发,基于这一模式的统计功效与效应值探讨也还有待深入。
参考文献
Basu, D.(2011). Randomization analysis of experimental data: The fisher randomization test. Journal of the American Statistical Association, 75(371), 305-325.
Berry, K. J., Johnston, J. E., & Mielke, Jr, P. W.(2014). A chronicle of permutation statistical methods: 1920-2000 and beyond. Cham, Switzerland: Springer.
Berry, K. J., Mielke, Jr, P. W. & Johnston, J. E.(2016). Permutation statistical methods: an integrated approach. Cham, Switzerland: Springer.
Boik, R. J.(1987). The fisher-pitman permutation test: A non-robust alternative to the normal theoryFtest when variances are heterogeneous. British Journal of Mathematical & Statistical Psychology, 40(1), 26-42.
Box, G. E. P., & Anderson, S. L.(1955). Permutation theory in the derivation of robust criteria and the study of departures from assumption. Journal of the Royal Statistical Society, 17(1), 1-34.
Dugard, P.(2014). Randomization tests: A new gold standard?Journal of Contextual Behavioral Science, 3(1), 65-68.
Dugard, P., File, P., & Todman, J.(2011). Single-case and small-n experimental designs: A practical guide to randomization tests. London: Routledge.
Eden, T., & Yates, F.(1933). On the validity of Fishersztest when applied to an actual example of non-normal data. Journal of Agricultural Science, 23(1), 6-17.
Edgington, E. S., & Onghena, P.(2007). Randomization tests. Boca Raton, FL: CRC Press.
Ernst, M. D.(2009). Teaching inference for randomized experiments. Journal of Statistics Education, 7(1).
Eudey, T. L., Kerr, J. D., & Trumbo, B. E.(2010). Using R to simulate permutation distributions for some elementary experimental designs. Journal of Statistics Education, 18(1).
Fisher, R. A.(1925). Statistical Methods for Research Workers. Edinburgh: Oliver and Boyd.
Fisher, R. A.(1935). The Design of Experiments. Edinburgh: Oliver and Boyd.
Fisher, R. A.(1936). The coefficient of racial likeness and the future of craniometry. The Journal of the Royal Anthropological Institute of Great Britain and Ireland, 66, 57-63.
Geary, R. C.(1927). Some properties of correlation and regression in a limited universe. Metron Rivista Internazionale de Statistica, 7, 83-119.
Kempthorne, O.(1955). The Randomization Theory of Experimental Inference. Journal of the American Statistical Association. 50(271), 946-967.
Lu, J., Ding, P., & Dasgupta, T.(2015). Construction of alternative hypotheses for evaluation of randomization tests with ordinal outcomes. Statistics & Probability Letters, 107(12), 348-355.
Ludbrook, J. & Dudley, H. A. F.(1998). Why permutation tests are superior tot- andF-tests in biomedical research. The American Statistician, 52(2), 127-132.
Ludbrook, J.(2005). Randomization based tests. Encyclopedia of statistics in behavioral science. Hoboken, NJ: John Wiley & Sons, Inc.
Mielke, P. W., Berry, K. J., & Johnston, J. E.(2011). Robustness without rank order statistics. Journal of Applied Statistics, 38(1), 207-214.
Pitman, E. J. G.(1937a). Significance tests which may be applied to samples from any populations. Supplement to the Journal of the Royal Statistical Society, 4(1), 119-130.
Pitman, E. J. G.(1937b). Significance tests which may be applied to samples from any populations II: The correlation coefficient test. Supplement to the Journal of the Royal Statistical Society, 4(2), 225-232.
Pitman, E. J. G.(1938). Significance tests which may be applied to samples from any populations III: The analysis of variance test. Biometrika, 29(201), 322-335.
Rubin, D. B.(1991). Practical applications of modes of statistical inference for causal effects and the critical role of the assignment mechanism. Biometrics, 47(4), 1213-1234.
