基于卷积神经网络与篇章结构的足球新闻自动生成方法
2019-05-24刘茂福齐乔松胡慧君
刘茂福,齐乔松,胡慧君
(1. 武汉科技大学 计算机科学与技术学院,湖北 武汉 430065;2. 智能信息处理与实时工业系统湖北省重点实验室,湖北 武汉 430065)
0 引言
足球赛事直播正处于蓬勃发展阶段。因受限于生活与工作的快节奏,使得足球爱好者无法拥有充足的时间观看所有足球赛事直播或重播,取而代之的是通过阅读一篇简短的足球新闻,获取比赛中发生的事情。然而,时至今日,足球新闻依然由专家或记者手工撰写,既耗时又费力。因而,采用相关信息抽取、自然语言处理等技术,从体育赛事直播脚本自动生成足球新闻,显得尤为重要。本文选择足球领域的网络直播脚本作为语料,试图提出一个基于卷积神经网络与篇章结构的足球新闻自动生成方法,尝试取代手工撰写新闻的方式。
本文提出的足球新闻生成方法是从一组网络直播脚本中抽取并生成句子。经典的单文本摘要方法往往认为,文档里句子或者词语的重要性与其出现的频率呈正相关,但是记载着体育赛事流水账的文字通常与之有所差异。在足球比赛中,人们所理解重要时刻与多种条件相互依存,描述同样事件的文字会因为时间、位置、主语、比分等多种条件的影响而呈现截然不同的重要性。承载于文字的重要时刻有多种类型,比如禁区中的对抗动作、双方球队概述、关键先生、进球。因此足球比赛新闻生成方法需要能够从文本中抽取包含重要信息的句子。由于足球新闻的上述特性,本文即利用这种特性作为评价时的辅助指标,以期取得更好的摘要效果。
文档摘要生成技术在专业领域发展迅速。Wang等[1]使用基于统计模型的单文档摘要方法生成中文新闻;林莉媛等[2]使用基于评论的多文档摘要方法生成情感类文本;李培等[3]基于斯坦纳树的最小权重支配集在微博数据集上生成故事线;Wan等[4]使用抽取多个候选句,并对候选句排序的方法来生成跨语种的文本摘要;Cao等[5]使用基于神经网络的抽象摘要方法来取代抽取式摘要,得到了忠实原文的摘要结果;Cao等[6]使用文本分类的方法来解决多文档摘要中数据匮乏的问题。
本文使用基于文本分类模型的句子抽取方法抽取出重要句子。目前,文本分类任务的相关研究已经日趋完善,段旭磊等[7]使用基于句向量的相似度计算方法来查找相似微博文本;在短文本分类任务研究上,吕超镇等[8]采用基于文档主题生成模型与特征扩展的方法来提升分类的准确率;陈宇等[9]使用基于差分演化优化的方法尝试解决在林业信息领域的文本分类难题;Sabour等[10]提出了胶囊网络,并证明了胶囊网络在图片分类任务上的优越性。
如今,企业也相继在特定领域研发并投入使用了自动写作机器人。特定领域的文章通常因为其领域特殊性而需要关注不同的侧重点,例如,财经领域的文章主题要求具有较强的数学逻辑,以此为代表的是美联社半自动化写作机器人WordSmith[注]https://automatedinsights.com/case-studies/associated-press。洛杉矶时报的Quakebot主要用来实时发布地震消息[注]http://knowledge.wharton.upenn.edu/article/will-robot-journalists-replace-humanl-ones/,Quakebot曾经在洛杉矶地震的数分钟内发布相关新闻。Quakebot属于应对突发情况的领域,需要保证极高的实时性与准确性,生成的新闻需要简明扼要、突出重点。国内同样有优秀的自动生成文章产品。如阿里巴巴的DT稿王[注]http://writingmaster.cn/、腾讯的Dreamwriter[注]http://tech.qq.com/dreamwriter.htm、今日头条的Xiaomingbot[注]http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=zgcmkhj201609002等。这些写作机器人在特定领域中表现出明显的差异化,这种差异化也使得领域相关的文章自动生成技术呈现出百花齐放的局面。
针对足球新闻,本文提出了一个基于卷积神经网络与篇章结构的足球新闻自动生成方法。首先,人工对直播文本中的句子进行抽取性标注,基于统计结果抽取文本中含有的人工特征,根据标注结果与人工特征的性质对特征进行处理。使用了词向量、人工特征与标注结果训练卷积神经网络分类模型,使用分类模型预测句子是否应该被抽取;另一方面使用训练集中的数据统计文件来生成关于队伍和球员表现总结的句子。最终这些句子将会被按照训练集结果中篇章结构来重新组合,生成一篇足球新闻。
1 总体框架
本文中提出的足球新闻自动生成方法主要包含数据预处理、特征与分类、规则与统计文件、篇章结构四个模块,如图1所示。
在数据预处理部分,该方法的主要工作是中文分词以及去停用词。本文选择了中科院的中文分词工具[注]中科院分词工具: http://ictclas.nlpir.org/downloads和哈尔滨工业大学的停用词表[注]哈工大停用词表: https://github.com/uk9921/StopWords。
在特征与分类模块中,本文从测试集中抽取时间、标点与比分三类句子特征。时间特征是指一个句子出现的时间点;标点特征反映了一个句子中包含的标点情况;比分特征是指一个句子是否包含进球信息。在词向量特征模块中,本文使用一系列的词向量来表示一个句子。随后,该方法使用卷积神经网络CNN(Convolutional Neural Networks)模型,对输入的人工特征与词向量特征加以预测。CNN的预测结果为Softmax二分类,两个结果分别表示输入句子应该被抽取(label=1)和不应该被抽取(label=0)的概率,当Plabel=1>Plabel=0时,表示抽取当前句子。

图1 方法框架图
在规则与统计文件模块中,该方法通过处理技术统计文件和主客队球员统计文件,得到了双方球队和球员有关进攻与防守的数据。同时在句子生成模块中,本文使用了这些数据中的进球次数和控球率来衡量一个球队的进攻和控球能力,并且使用模板为球队生成一个简短的比赛评价;同时,该方法也为有进球的球员和扑救次数较多的守门员生成评价。
在篇章结构模块中,该方法将会遵照训练集的结果文件格式,先把生成的句子置于文章的开头部分,再把抽取后筛选出的句子按照时间顺序来排序,置于文章开头部分之后的位置。本文将得到的句子按照篇章结构重新组合后,最终得到一篇足球新闻。
2 足球新闻自动生成
2.1 篇章结构
根据训练集结果文件中的足球新闻,本文把一篇足球新闻的篇章结构划分成如下四个部分[11]。
(1) 时间、比赛和队伍
足球新闻的第一部分一般会说明比赛时间、地点、场次以及球队双方历史对阵情况等,如例1所示。
例1北京时间2月3日凌晨3:45,英超第24轮一场焦点战,阿森纳主场出战南普顿。
在直播脚本文件中,比赛时间与场次可以在其开头部分被找到,球队数据在其结尾位置。本文足球新闻第一部分内容使用这些数据生成。
(2) 球员与比赛的概述
足球新闻的第二个部分,会着重展示表现杰出的球员与比赛的概述,第二部分内容如例2所示。
例2在本场比赛,双方在球权上争夺激烈。迪乌夫为斯托克城奉献了1粒进球。切尔西队门将库尔图瓦表现神勇,全场没收了2次射门。联赛交锋中,切尔西在客场0∶1不敌对手。
例2中,对比赛的评价总结来自比赛的技术统计文件,对球员的总结则生成自记录了主客队球员的统计文件。表1和表2说明了这两种文件的数据格式和内容。

表1 技术统计文件示例

表2 主客队球员统计文件示例
(3) 直播精彩时刻
足球新闻中的第三个部分是比赛中的主体部分,这个部分记录了直播中发生的所有重要时刻,表3 给出了直播脚本的数据格式。

表3 直播脚本的部分内容
(4) 对阵出场名单
对阵出场名单中包含有双方球员编号、出场球员、球员出场时间等信息。如例3所示。
例3阿森纳首发(4-2-3-1): 33-切赫;24-贝莱林;20-弗拉米尼(85’,科奎林)……
2.2 特征工程
本文在特征的不同垂直领域上,考虑到特征直观上的合理性,使用了时间、标点与比分三类特征,并且通过数据统计对这些特征进行了合理性验证。其中,本文统计了训练集中足球新闻的句子与时间分布,不同时间占比如图2所示。

图2 足球新闻中句子占比与时间分布
由图2可知,时间与句子重要性呈现出明显的相关性,例如,上下半场快结束的时候,句子的重要性会持续增高。基于CNN的分类没有直接使用到时序信息,引入时间特征可以一定程度上弥补时序信息的不足。在训练数据中,时间是连续的单位,而在同一纬度上,时间之间的四则运算是没有含义的(如第10分钟与第15分钟是并列时间点,而非“15-10=5”的关系),因此,本文将时间特征离散化,并表示为编码形式[12],如表4所示。
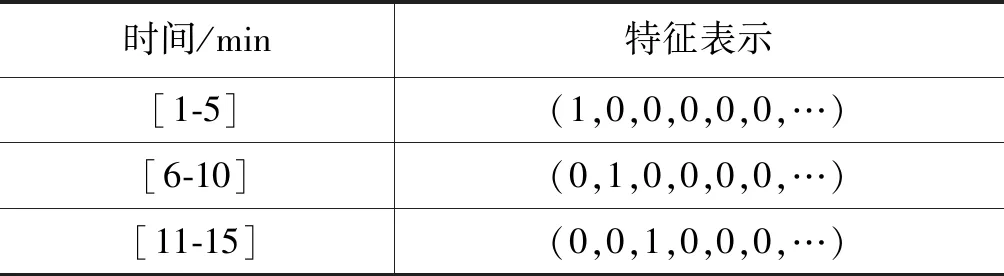
表4 部分时间特征表
本文统计了在直播文本中标注结果为“抽取”的句子中标点符号的分布,计算其TF-IDF值,如式(1)~式(3)所示。


表5 标点符号的TF-IDF值
TF-IDF值在一定程度上衡量了句子中标点符号的重要性。标点的TF-IDF值反映了标点与句子抽取的相关程度,相关程度越高,其TF-IDF值也越高。结果表明,逗号、句号与句子抽取没有明显的相关性,而感叹号与句子抽取的相关性较为明显。在常识中,射失、扑救、进球等行为引起的激烈情绪常常用感叹号表示,情绪激烈的程度与感叹号的数量也呈现相关性。本文将句子中感叹号的数量抽象为一维特征,并将特征离散化,如表6所示。

表6 符号特征表示
在足球领域,进球往往是一场比赛中最重要的时刻。因此,本文使用与上一句相比本句比分是否发生变化来表示比分特征,对其进行编码表示。如表7所示。

表7 比分特征表
2.3 基于卷积神经网络的句子抽取与生成
为了增强句子的可读性和连贯性,本文使用了一系列的句子模板,表8在细节上描述了本文中的模板匹配策略。
本文使用模板来生成篇章结构的第一、第二和第四部分;篇章结构的第三部分则使用基于CNN的句子抽取方法,使用CNN主要具有三方面的优势。

表8 模板匹配的一些例子
(1) CNN可以很好地把以句子为单位的特征与句子在同一个层次结合;
(2) 训练集规模较小的情况下,CNN可以支撑端到端的文本深度生成模型;
(3) 基于排序的句子抽取方法需要指定合理的抽取阈值,而CNN可以将其转换为基于二分类的句子抽取。
在卷积神经网络模型中,本文的卷积核窗口宽度为2、3、4,每类卷积核的数量为64个。本文中的句子是通过词向量维度×句子长度的矩阵表示的。本文中句子长度被固定为20,长度少于20句的末尾使用空格符号词向量填充,长度超出20句的句子被截断。在本文中,卷积层词向量维度与卷积核纬度都取值300。300×n的卷积矩阵与句子矩阵相乘,结果纬度为(20-n)。本文将标点、得分与时间这三维特征与池化层结果拼接,使特征在维度与层次上保持一致。经过全连接层与Softmax输出分类结果的概率值。本文的CNN结构与特征输入如图3所示。
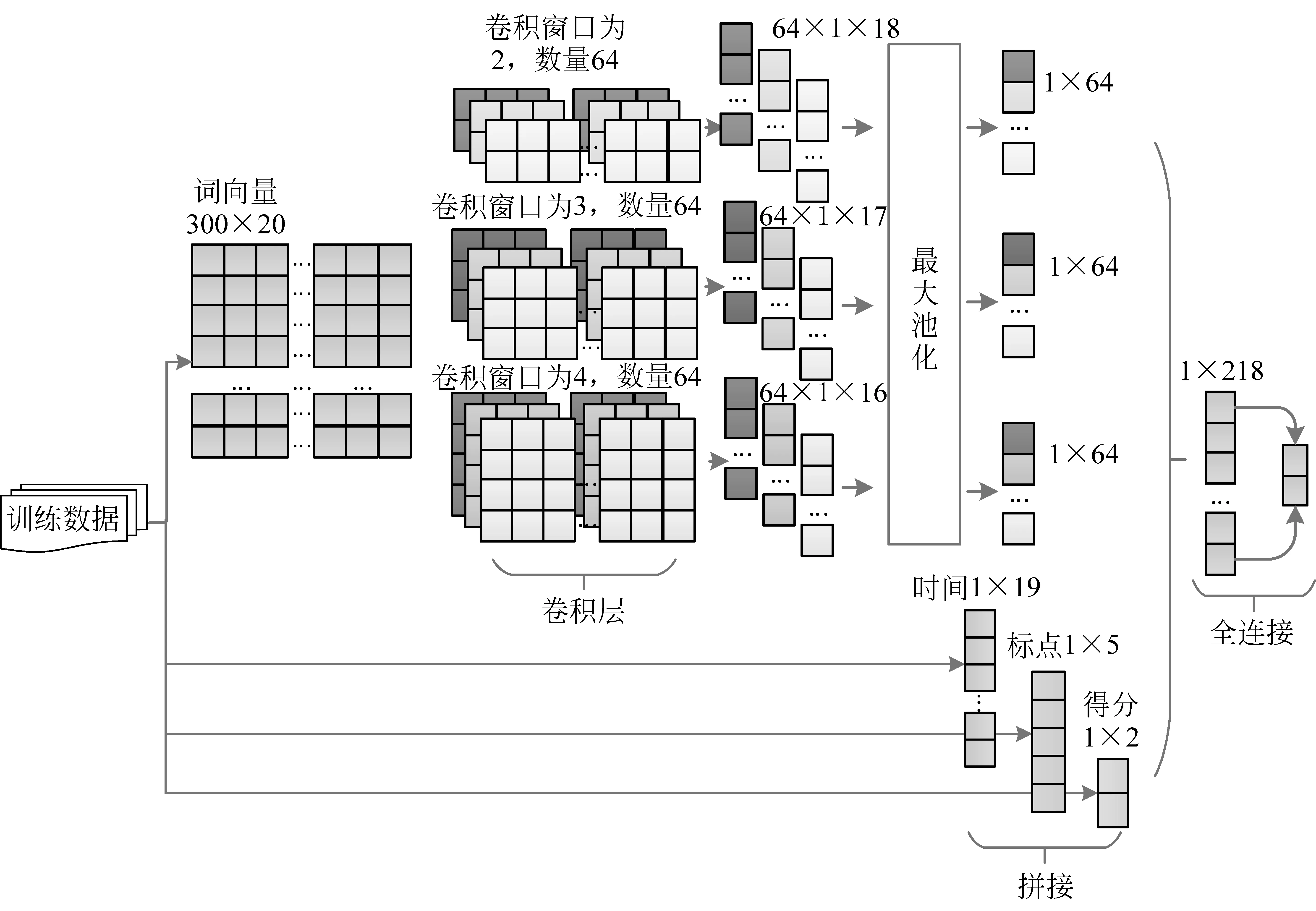
图3 CNN结构与特征输入
在模型超参数的选择上,本文尝试使用多种经验范围内的超参数组合,最终使用的学习率为0.001。本文使用RELU激活函数,优化器选择Adam Optimizer,优化目标方程使用L2正则项,正则项系数为0.005,本文在全连接层设置dropout设置为0.4。本文将batch-size设置为128,训练时对全数据集循环10次,训练的终止条件为连续多轮损失函数不再下降或者达到全数据集循环10次。
本文的基于CNN分类抽取句子的算法如下所示。

算法1 基于CNN分类抽取句子的算法输入: 足球文字直播的句子序列输出: 抽取的足球文字直播句子序列1.句子序列处理,对序列中的句子分词、去停用词。根据序列中句子长度的分布情况,确定句子需要截取的长度为N;2.截取/填充句子的字符串,控制句子长度为N;3.将一个句子表示为词向量维度×句子长度的矩阵,将矩阵与窗口大小为2、3、4的卷积核进行卷积运算;4.使用句子时间、得分和标点当作句子的人工特征,离散化并使用one-hot编码表示时间、得分和标点特征;5.将人工特征向量和卷积向量的最大池化结果拼接;6.使用Softmax层对拼接结果进行计算,输出为二维向量,代表分类为“抽取”与“不抽取”的概率值;7.若句子预测为“抽取”的概率值大于“不抽取”,则标记输出当前句子;8.重复2到7步骤,直至句子序列处理完毕或者句子序列长度达到限制。
3 实验结果
3.1 实验设置
足球直播文本通常与足球比赛同步滚动播放,与之同期更新的还有比赛技术统计数据。比赛结束之后,足球比赛门户网站会撰写并发布一篇相关新闻对赛况进行更新与总结。通常来说,使用爬虫技术从足球比赛门户网站获取实验数据是可行的,但门户网站之间,关于比赛新闻产品定义的差异化导致这些网站给出的数据,不论在长度还是文风上都有较大的差异。因此通过网络爬虫获取干净整齐的高质多量数据非常困难。本文的实验语料训练集共有50组,实验的测试集共有30组。这些数据是由专业的足球新闻报道者撰写,可以认为是高质量的数据。其中,每组数据中包含250左右个句子,训练集共包含了大约12 500个句子,测试集共包含了大约7 500个句子。本文对这些句子的二分类进行了人工标注。标注后,正负样本比例大约为1∶5,为了平衡正负样本比例,本文对正样本采用了上采样,采样后的比例大约为3∶5,采样后的训练数据大约有16 600条句子。
在对比实验方面,本文使用了基于规则的方法[13]作为对比实验,同时,得到“基于规则”、“基于规则与篇章结构”、“基于CNN”与“基于CNN与篇章结构”四种实验系统结果。 “基于规则”匹配句子中表示“禁区”的关键词;如果匹配成功,则进一步匹配句子中的其他敏感词,例如,“手球”、“越位”等;如果句子满足两次匹配,或者当前句子所在的时间内比分发生变化,则抽取该句子。“基于规则与篇章结构”的方法综合了“基于规则”的抽取结果与模板匹配生成的句子。“基于CNN分类与篇章结构”综合了“基于CNN分类”与模版匹配生成的句子。
本文使用ROUGE作为自动评估方法,使用ROUGE-N、F1作为评价指标。其基本思想是将模型生成的摘要与参考摘要的n元组贡献统计量作为评判依据,主要考察文本生成结果的充分性与忠实性。
3.2 实验结果分析
在自动评估方面,使用ROUGE工具包,用ROUGE-N的F1作为评价指标。表9是本文方法在30组测试集上的评测结果。

表9 评测结果
由表中的ROUGE结果可知,本文方法得到的结果精准率略大于召回率,说明本文中的方法在精度上略优于覆盖度。这是因为本文标注的训练数据正负样本比例不均衡。通常一场足球比赛中,直播脚本中的句子会有上百条,而足球新闻中需要的句子只有十多条。因此,在标注直播脚本中句子时,负样本(不抽取)的比例要大于正样本(抽取),这会更倾向与预测出负样本类别,从而导致覆盖率降低,精准率升高。
本文对比基于卷积神经网络与规则的抽取模型,在同样ROUGE环境下的评测结果如图4所示。

图4 评测结果对比
由图4可知,本文方法在各项结果上均优于基于规则的生成方法。这是因为本文合理地使用了文本特征,将时间、标点与比分三类特征加入到模型的训练过程,并且CNN具有较好拟合能力;而本文中使用的规则方法是从有限的数据中加上先验知识总结出来的,仅仅匹配了进球、关键词与敏感词,难以拟合复杂的文本句式。所以,本文中使用CNN分类代替规则的抽取方法是有效的。本文中“基于规则”、“基于规则与篇章结构”、“基于CNN”、“基于CNN与篇章结构”的对比结果如表10所示。

表10 有无篇章结构的评测结果对比
由表10可知,采用篇章结构的实验结果略高于不使用篇章结构的结果。本文在生成方法中使用篇章结构可以让足球新闻层次鲜明,可阅读性强。其对评测结果的提升主要体现在篇章结构上的重复部分,如“时间”和“出场阵容”等部分。本文中使用卷积神经网络与篇章结构方法的生成结果如例4所示。
例4北京时间2月6日英超联赛第25轮中最重要的一场比赛曼城主场对阵莱斯特。
本场比赛中,曼城进攻意识强烈,同时在本场比赛中展现出了惊人的控球能力。胡特、马赫雷斯为莱斯特奉献了3粒进球……
第2分钟,鹅卵石左路的传中,乔哈特飞身双龙出海将球击出禁区。马赫雷斯右路得球,假动作后搓球再加速突向底线被德尔夫绊倒。
第3分钟,莱斯特获得一个右肋部的任意球机会。瓦尔迪一晃,马赫雷斯低平球送球门前,抢点的胡特近距离将球打进球门!。
第10分钟,福布斯传中,费尔南迪奥倒地将球破坏出禁区。瓦尔迪禁区里一打三,德尔夫将球解围。胡特后场得球,被斯特林逼抢下带球出了边线。
……
双方出场名单: 曼城(4231): 1-哈特;5-萨巴莱塔……
从例4中可以看出,本文中的方法成功地抽取出足球新闻第三部分的射门、进球以及禁区内的攻防等信息。在第2分钟时,抽取出禁区内的防守和进攻队员被绊倒的信息;在第3分钟,抽取出胡特进球得分的信息;第9分钟,抽取出乔哈特禁区内封球的信息;第10分钟,抽取出瓦尔迪禁区里一打三,德尔夫将球解围的信息。
生成结果包含了比赛的基本信息、比赛中的精彩片段和双方的阵容。基于篇章结构的方法可以使得足球新闻结构更加明显,重点更为突出,增强了可读性。
4 结论与展望
本文提出了一种基于卷积神经网络与篇章结构的足球新闻自动生成方法。该方法基于卷积神经网络抽取句子,基于模板生成句子,将获得的句子按照篇章结构要求来排列,从而得到最终结果。实验结果表明,本文的足球新闻生成方法具有良好的效果,可以从直播脚本中较精准地抽取并生成符合大众常识的关键句子。
本文中的方法依然有提升的空间,一方面,可以通过拓宽训练集数据,加入规则为不同类型的体育比赛制定不同的足球新闻生成方法;另一方面,随着网络直播脚本规范化的发展,可以给每一条直播语句增加标签,从而使得语句所描述事件的特性更加明确。另外,还可以使用迁移学习在中小型数据量上完成文本生成任务。
