基于分类算法的汽动给水泵组故障预测
2019-05-22徐红伟刘振宇李崇晟
徐红伟,刘振宇,李崇晟
基于分类算法的汽动给水泵组故障预测
徐红伟,刘振宇,李崇晟
(西安热工研究院有限公司,陕西 西安 710054)
汽动给水泵组是火电厂热力系统的重要辅助设备,对汽动给水泵组有效的故障预测有助于其状态检修。本文通过基于统计特征的特征提取方法及Relief特征选择算法,实现厂级监控信息系统历史数据到分类模型输入参数的合理转化,并采用5种分类算法分别针对2个电厂汽动给水泵组的小机叶片断裂和给水泵动、静平衡盘碰磨实际故障案例,建立了正常与故障状态的分类模型。实际数据验证表明:BP神经网络、支持向量机和组合分类算法分类效果更优,可提前4~10周识别设备故障的潜在风险,该结果为其他设备故障预测提供了新的思路。
汽动给水泵组;故障预测;BP神经网络;支持向量机;组合分类;状态检修
火电厂设备检修模式主要分为定期检修、事故检修和状态检修。定期检修是按预定时间周期进行的计划检修;事故检修是设备发生故障后被动进行的非计划检修;状态检修则根据设备状态变化合理安排检修时间和内容,是检修模式的发展方向。有效的故障预测可为状态检修提供技术支撑。
故障预测一般有2类方法:1)通过机理分析综合考虑机械、材料等特性确定设备劣化趋势,但由于制造、运行等过程的不确定性,增加了研究的复杂度和误差率;2)挖掘设备历史数据中的隐藏信息,根据数据特征变化分析设备状态变化趋势。
汽动给水泵组是火电厂热力系统的重要辅助设备,它将给水从凝结水压力提高到锅炉给水压力,并向过热器及再热器提供减温水。汽动给水泵组的安全运行与整个机组的安全密切相关,将数据挖掘技术应用于汽动给水泵组的故障预测,可为汽动给水泵组状态检修的发展探索新的方向。
数据挖掘技术在设备故障预测领域的应用已有较多研究:Golriz Amooee等[1]使用贝叶斯网络、支持向量机(SVM)、神经网络等预测了设备的缺陷,并比较了不同算法的性能;雷金波[2]运用逻辑回归模型实现了设备状态退化评估,并采用SVM预测了设备状态发展趋势;Elyas Rakhshani等[3]将锅炉燃烧系统的有效参数数据进行聚类,并采用神经网络分别实现了故障监测和预测;Andrew Kusiak等[4]使用随机森林算法实现了风机状态预测,从而识别风机故障;童超等[5-6]采用改进Apriori关联规则算法分析了风电机组桨距角不对称故障前后的报警信息,从中提炼了有效报警量,并采用分类算法辨别风机处于正常或故障状态;Zhao Gang等[7]将故障类型与振动频谱和过程特征相关联,采用决策树实现了故障分类;李莎等[8]将相关分析法结合最大最小聚类对数据进行了约简,并采用SVM实现了汽轮机故障诊断;张国坤[9]利用k-均值聚类方法对汽轮发电机组构建了基于多征兆信息融合的故障识别体系;张子泓[10]使用改进Apriori算法对给水泵进行了关联规则挖掘,实现了给水泵故障预测及检修计划编制;Yang Haowei等[11]将关联规则挖掘应用于给水泵故障预测,得到了特定测点组合超标与故障的警示关系。
本文依托火电厂厂级监控信息系统(supervisory information system in plant level,SIS),采用多维时间序列分类方法实现了汽动给水泵组的典型故障预测,并结合实际案例对模型的有效性进行了验证。
1 研究对象
本文分别选取电厂A和电厂B的1台汽动给水泵组作为研究对象进行故障预测,分别取性能测点、轴承及油温测点、振动测点3类数据。其中,性能测点主要包括功率、转速、进出口压力、温度、流量等参数;轴承及油温测点主要包括轴承温度和润滑油温度等参数;振动测点主要包括轴向位移、和向振动等参数。A电厂共选取39个测点,B电厂共选取22个测点。
设备的故障往往不是瞬间导致,而有萌芽、发展、恶化直至发生事故的过程(图1)。尽管无法完全正确地衡量故障萌芽、发展、恶化的时间点,但可通过模糊处理,将设备离故障发生点还很久时的状态看作健康状态,将设备故障前夕的状态看作故障状态。

图1 故障发展过程
A电厂于2016年9月28日发生了小汽轮机末 级叶片断裂事故(3片断裂、1片损伤),选取其 2016年1月至2016年9月的SIS数据。B电厂于 2016年9月至2017年6月因给水泵动、静平衡盘碰磨而产生了一系列问题,选取其2015年11月至2017年6月的SIS数据。
2 数据预处理
2.1 数据特性分析
测点数据是时间序列数据,时间序列数据根据其采样方式有所不同,一般是根据固定时间间隔(如1 s)采样,这样容易组合为向量或矩阵,易于采用矩阵理论处理。而SIS对数据的存储依据数值的变化和时间差2个因素来设定,当实时值与前存储值的差超过设定的百分比,或当实时值与前存储值的时间差超过一定时间时,才存储当前实时值及其时刻。SIS中获取的某功率测点数据见表1。
表1 SIS中获取的某功率测点数据

Tab.1 The data of a power measurement point from SIS
由表1可以看出,该数据在时间维度上缺乏规律性。对于多维数据来说,由于不同测点的变化规则各有差异,不规律性更加突出,SIS中多维数据存储示例如图2所示。图2中,①、②、③分别代表不同测点,横向间隔表示存储值的时间差。可以看出,在任意固定时间区间内,各测点的存储值个数均有差别,各值的存储时间也并无联系。

图2 SIS中多维数据存储示例
2.2 样本划分
根据以上分析,首先对数据划分样本。由于某些测点数据波动较大,如果单纯考虑瞬时数据时,可能丢失时序信息,所以在此将一段固定时间间隔内的多维数据集及其存储时刻集作为一个样本。此固定时间间隔取为1 800 s,即每隔30 min,取其间各测点的存储数据及存储时刻作为一个样本。然后对存储时刻规范化,根据各值存储时刻与样本初始时刻的时差,将其转换为1~1 800中的一个数。
根据第1节中对设备故障与正常状态的假设说明,对A电厂,将2016年1月的样本标定为正常类,将2016年9月的样本标定为故障类;对B电厂,将2015年11—12月以及2016年1月的样本标定为正常类,将2016年8—10月的样本标定为故障类。其余样本均作为验证数据。
然后对所有数据进行清理,即剔除原始数据中的坏值,对缺失值进行光滑,并实现数据的一致性。
2.3 特征提取
分类问题需要先将对象描述成特征向量形式。对于本文中多维数据且各维数据长度不同的情况,需要先通过合适方式提取数据特征,并构造特征向量。时间序列特征提取方法主要分4类:基于频谱分析的方法(离散傅里叶变换[12]和离散小波变换[13]等)、基于统计特征的方法[14]、基于形状的方法[15]、基于模型的方法[16]。此外,还有分段线性表示[17]、奇异值分解[18]、符号聚集近似[19]等。
对于本文中的数据,不仅同一测点各值的存储间隔差异很大,不同测点间也完全不一致。甚至有些测点参数在一个样本的1 800 s内只有2~3个数据,显然这样的数据不适于采用基于频谱分析、基于形状和基于模型等对数据密度要求较高且存储值时间间隔必须一致的方法来处理。基于统计特征的方法不需顾及数据的存储密度,也不考虑数据的存储间隔,对于数值型数据,总能找到合适的统计特征量来描述。
本文对各维数据均提取6个统计特征量,分别为加权平均值1、加权标准差2、变化次数3、最大变化率4、平均变化率5、极差6。其中,加权平均值反映数据的集中趋势,加权标准差和极差反映数据的离散程度,变化次数、最大变化率和平均变化率反映设备在状态恶化时数据可能出现的频繁或大幅的波动。具体计算公式为:





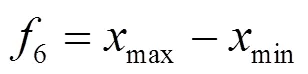
式中:为样本中要提取特征的维度值数量;x为样本中要提取特征的维度的第个数据;t为数据对应的规范化时标,1=1,t1=1 801;max为样本中要提取特征维度的最大值;min为样本中要提取特征维度的最小值。
特征提取中部分变量取值如图3所示。图3表示单个样本中的一维数据,在此样本范围内,此一维数据包含5个数据点。当下一个数据点出现前,默认数据值约等于前一个数据值。

图3 特征提取中部分变量取值
A电厂共39个测点,每个维度产生6个特征量,将各维的特征量依次排序组成特征向量,其维度为39×6=234维。B电厂共22个测点,得到的特征向量维度为22×6=132维。
将数据在[0,1]区间归一化,归一化处理后,所有数据值都处于[0,1]区间。
2.4 特征选择
按照特征子集形成方式,特征选择方法分为穷举式、启发式和随机式。穷举式方法是在原始特征集中考虑特征的完全组合,根据评价最优标准,选取最佳特征子集;启发式方法在穷举式的基础上增加了一些主观调节倾向,提高了最优子集的搜索效率;随机式方法先采用随机抽取方式选择特征子集,然后评估各子集的有效程度并择取最优[20]。
穷举式方法一定能得到最优解,但计算复杂度太大,应用价值较低;随机式方法的有效性与参数设置的合理性密切相关;启发式方法简单快速,也能获得近似最优解。在此采用一种常用于二分类问题的启发式特征选择算法——Relief算法,该算法根据原始特征集中各特征与各类别的相关性程度赋予特征不同的权重[21]。其思路如下:
1)建立特征的权重向量并初始化为0;
2)在训练数据集中随机选取一个样本A;
3)从与A同类的样本集中找出与其距离最近的样本S,从与A不同类的样本集中找出与其距离最近的样本D;
4)对每个特征=1~(原特征向量维度),通过式(7)更新其权重,


式中,为抽样次数,[]为A样本在特征上的值,max()为特征上的最大值,min()为特征上的最小值;
5)返回步骤2)继续进行下一次抽样,直到完成次抽样;
6)按权重由大到小对特征进行排序,取排名靠前的部分特征的组合作为最终的特征向量;
7)对A电厂选取权重排序前43维特征,对B电厂选取前33维特征,分别作为各自的特征向量。
3 模型建立
常用分类算法有BP神经网络、SVM、朴素贝叶斯算法、决策树以及组合分类等。
BP神经网络是神经网络中最常用的网络类型,其层与层间神经元全连接,同一层各神经元互不连接。信号传播方式分数据信号正向传播和误差信号反向传播。前者指输入数据信号由输入层到输出层逐层通过各神经元的连接权值计算网络输出,而后者指实际输出与期望输出的误差信号由输出层到输入层逐层反向传播并调整相应连接权值[22]。
SVM在统计学习理论和结构风险最小化原则基础上发展而来,易解决非线性、小样本和高维分类问题。对线性问题,SVM通过搜索最大边缘超平面实现最优分类。对非线性问题,SVM通过非线性映射,将原样本空间的非线性问题转化为高维空间的线性问题,从而在高维空间寻找最优超平面实现分类[23]。
朴素贝叶斯算法基于贝叶斯定理和类条件独立假设,其原理是将给定样本分类到具有最高后验概率的类。类条件独立假设假定各属性在各类别上互不干扰,以对计算加以简化。朴素贝叶斯算法分类效率稳定,但由于类条件独立假设在实际中往往很难满足,当数据各属性对同一类别的影响具有相关性时,可能导致分类效果不太理想[24]。
决策树是一种树结构分类算法,每个内部结点(非树叶结点)代表数据在一个属性上的分类过程,每个分枝代表分类的一个输出,最终一直分到树叶结点,每个树叶结点都代表一个类标号。决策树算法不需专业领域知识支撑,且形式直观,容易理解,但其忽视了各属性间可能存在的关联性[25]。
组合分类是将多个分类器组合形成的复合方法。组合策略有装袋、提升等。装袋方法对各子分类器分别建模,预测时再以相同权重进行综合。提升方法在训练中不断更新样本权重,增大误分类样本权重,使其后学习的分类器更关注误分类样本,最终各子分类器投票权重与其分类准确率有关。
本文分别采用以上5种算法来建立模型,比较选取最适合汽动给水泵组的故障预测方法。其中,决策树采用C4.5算法,组合分类使用装袋策略。
A电厂正常数据和故障数据分别有1 390和 1 307个样本,共2 697个。从中随机选择1 800个样本作为训练数据,剩余897个样本作为测试数据。B电厂正常数据和故障数据分别4 295和2 022个样本,共6 317个。同样,从中随机选择4 200个样本作为训练数据,剩余2 117个作为测试数据。
根据特征选择结果,在建模时,A电厂分类模型输入参数为43维向量,B电厂分类模型输入参数为33维向量,输出用{[1]、[–1]}简单区分。据此可以对各分类算法设置模型参数。
对BP神经网络模型,选择单隐含层网络结构。隐含层节点数通常采用经验公式[22]给出。A电厂BP神经网络模型的隐含层节点数取11,B电厂 取12。训练函数均取trainlm,性能函数均取mse。
SVM的惩罚参数和核函数参数通常凭经验给定,但往往难以取得最优值。此处采用交叉验证法对其寻优。首先选定和的筛选区间和步长,使和取遍区间的所有组合。同时,将总体样本分为组,每组数据分别作一次验证集,其余数据作训练集,对和的每个组合都计算个模型的平均分类准确率,作为性能指标。最终取性能指标最优的和组合作为最优参数。当多组和性能相差较小时,取最小的组合以避免过学习。A电厂和B电厂的和选择结果分别如图4和图5所示。图4和图5中“*”对应最优和。

图4 A电厂c和g参数选择结果

图5 B电厂c和g参数选择结果
4 模型评估
BP神经网络、朴素贝叶斯、SVM、决策树、组合分类这5种方法对A电厂和B电厂的数据分类结果分别见表2和表3。由表2、表3可见,BP神经网络、朴素贝叶斯、SVM和决策树都对A电厂和B电厂的训练和测试样本有极高识别率,最高甚至达到100%,最低也在93%以上,说明前述方法选取的特征向量对正常和故障数据有良好区分能力。但决策树算法的训练及测试时间远大于其他3种,而组合分类的投票需要奇数个分类器,考虑到决策树算法会大大增加组合分类时间,故组合分类的子分类器选取BP神经网络、朴素贝叶斯、SVM。
表2 A电厂数据分类结果

Tab.2 The classification results of data from plant A
表3 B电厂数据分类结果

Tab.3 The classification results of data from plant B
总体而言,BP神经网络、SVM和组合分类 3种算法的分类性能指标最优,决策树算法耗时较长,朴素贝叶斯算法性能指标略低,故针对此问题,BP神经网络、SVM和组合分类算法最适合。
5 模型应用
将上述3种较优分类方法模型应用于其余样本数据中,并将分类结果与实际运行和检修记录进行比较,实现模型的验证。3种分类方法对A电厂和B电厂验证数据的分类结果分别如图6和图7所示。由图6可见:对A电厂,2016年9月28日发生了一次给水泵汽轮机叶片断裂事故,在以2016年9月数据为故障样本、2016年1月数据为正常样本建立分类模型情况下,模型不仅可以很好地识别2类,而且可以在8月就给出故障指示,提前4~5周达到预测效果。
对B电厂,情况略微复杂。经专家鉴定,B电厂汽动给水泵组在2016年9月至2017年6月因给水泵动、静平衡盘碰磨故障而产生了一系列问题。由图7可见:在以2015年11月至2016年1月数据为正常样本、以2016年8—10月数据为故障样本建立分类模型情况下,模型也可以将2类很好地识别,而且可以在2016年6月就给出故障指示,提前9~10周达到预测效果。2016年11月至2017年6月共 8个月里,除2016年12月(检修)、2017年1月(停机)、2017年2月(检修)外,其余月份的预测结果都明显偏向故障类,而电厂专业人员证实,在此期间,设备确实一直处于带故障运行状态,且此给水泵在每次完成检修投入运行后,状态又会逐渐恶化,其故障未能得到根本解决。2016年12月及2017年2月的预测结果偏向正常类,与当月对设备进行了检修这一事实正好吻合,且2017年2月后预测结果的逐渐上升趋势与给水泵完成检修投入运行后设备状态的逐渐恶化也基本匹配。

图6 分类方法对A电厂数据验证结果

图7 分类方法对B电厂数据验证结果
根据以上分析,数据分类的结果与设备的实际运行和检修记录基本吻合,说明此分类方法对汽动给水泵组的典型故障预测有明显效果。
6 结 语
本文依托火电厂SIS,通过统计特征提取和Relief特征选择算法,实现了SIS数据到分类模型输入参数的合理转化,避免了冗余特征对分类结果的干扰。同时,采用5种分类算法分别对2个电厂汽动给水泵组的故障案例建立了正常与故障状态分类模型,经现场实际数据验证,BP神经网络、SVM和组合分类算法分类效果更优,可提前4~10周识别故障的潜在风险,避免恶性事故的发生,并为其他设备的故障预测提供了新的思路。
[1] AMOOEE G, MINAEIBIDGOLI B, BAGHERID EHNAVI M. A comparison between data mining prediction algorithms for fault detection[J]. International Journal of Computer Science Issues, 2011, 8(6): 425-431.
[2] 雷金波. 基于逻辑回归和支持向量机的设备状态退化评估与趋势预测研究[D]. 上海: 上海交通大学, 2008: 31-38. LEI Jinbo. Research on degeneration assessment & trend prediction about machine based on logistic regression and SVM[D]. Shanghai: Shanghai Jiao Tong University, 2008: 31-38.
[3] RAKHSHANI E, SARIRI I, ROUZBEHI K. Application of data mining on fault detection and prediction in boiler of power plant using artificial neural network[J]. International Conference on Power Engineering, 2009, 5852(2014): 473-478.
[4] KUSIAK A, VERMA A. A data-mining approach to monitoring wind turbines[J]. IEEE Transactions on Sustainable Energy, 2011, 3(1): 150-157.
[5] 童超. 基于数据挖掘方法的风电机组状态监测研 究[D]. 北京: 华北电力大学, 2014: 14-18. TONG Chao. Research on wind turbine condition monitoring based on data mining[D]. Beijing: North China Electric Power University, 2014: 14-18.
[6] 童超, 郭鹏. 基于特征选择和BP神经网络的风电机组故障分类监测研究[J]. 动力工程学报, 2014, 34(4): 313-317.TONG Chao, GUO Peng. Wind turbine fault classification based on BP neural network and feature selection algorithm[J]. Journal of Chinese Society of Power Engineering, 2014, 34(4): 313-317.
[7] ZHAO G, JIANG D X, LI K, et al. Data mining for fault diagnosis and machine learning for rotating machinery[J]. Key Engineering Materials, 2005, 293/294: 175-182.
[8] 李莎, 陶红, 高尚. 基于属性约简与参数优化的SVM故障诊断研究[J]. 计算机技术与发展, 2012, 22(4): 175-178. LI Sha, TAO Hong, GAO Shang. SVM fault diagnosis research based on attribute reduction and parameters optimization[J]. Computer Technology and Development, 2012, 22(4): 175-178.
[9] 张国坤. 基于聚类分析的汽轮发电机组早期故障识别系统研究[D]. 北京: 华北电力大学, 2013: 52-56. ZHANG Guokun. Research on early fault identification system for turbo-generation unit based on cluster analysis[D]. Beijing: North China Electric Power University, 2013: 52-56.
[10] 张子泓. 基于数据挖掘的火电厂设备检修管理的研究[D]. 大连: 大连海事大学, 2014: 38-48.ZHANG Zihong. The research on equipment maintenance management in power plant based on data mining[D]. Dalian: Dalian Maritime University, 2014: 38-48.
[11] WEI Y H, XUE D S. The research of equipment maintenance management in power plant based on data mining[C]. IEEE International Conference on Computational Intelligence & Communication Technology. 2015: 543-547.
[12] AGRAWAL R, FALOUTSOS C, SWAMI A. Efficient similarity search in sequence databases[J]. International Conference on Foundations of Data Organization & Algorithms, 1993, 730: 69-84.
[13] CHAN K, FU W. Efficient time series matching by wavelets[C]. International Conference on Data Engi- neering. 1999: 126-133.
[14] NANOPOULOS A, ALCOCK R, MANOLOPOULOS Y. Feature-based classification of time-series data[J]. Nova Science Publishers lnc., 2001, 10: 49-61.
[15] GRABOCKA J, WISTUBA M, SCHMIDT-THIEME L. Fast classification of univariate and multivariate time series through shapelets discovery[J]. Knowledge & Information Systems, 2015, 49(2): 1-26.
[16] ZHONG S, GHOSH J. HMM and coupled HMMs for multi-channel EEG classification[J]. International Joint Conference on Neural Networks, 2002, 2: 1154-1159.
[17] CHANG P C, FAN C Y, LIU C H. Integrating a piecewise linear representation method and a neural network model for stock trading points prediction[J]. IEEE Transactions on Systems Man & Cybernetics Part C, 2008, 39(1): 80-92.
[18] WENG X Q, SHEN J Y. Classification of multivariate time series using two-demensional singular value decomposition[J]. Knowledge-Based Systems, 2008, 21(7): 535-539.
[19] SUN Y Q, LI J Y, LIU J X, et al. An improvement of symbolic aggregate approximation distance measure for time series[J]. Neurocomputing, 2014, 138(11): 189-198.
[20] 毛勇, 周晓波, 夏铮, 等. 特征选择算法研究综述[J]. 模式识别与人工智能, 2007, 20(2): 211-218. MAO Yong, ZHOU Xiaobo, XIA Zheng, et al. A survey for study of feature selection algorithms[J]. Pattern Recognition and Artificial Intelligence, 2007, 20(2): 211-218.
[21] 谭海龙. 多维时间序列的分类技术研究[D]. 杭州: 浙江大学, 2015: 33-34. TAN Hailong. Multivariate time series classification technology research[D]. Hangzhou: Zhejiang University, 2015: 33-34.
[22] 葛哲学, 孙志强. 神经网络理论与MATLAB R2007实现[M]. 北京: 电子工业出版社, 2007: 108-111. GE Zhexue, SUN Zhiqiang. Theory of neural network and its implementation with MATLAB R2007[M]. Beijing: Electronics Industry Press, 2007: 108-111.
[23] 丁世飞, 齐丙娟, 谭红艳. 支持向量机理论与算法研究综述[J]. 电子科技大学学报, 2011, 40(1): 2-10. DING Shifei, QI Bingjuan, TAN Hongyan. An overview on theory and algorithm of support vector machines[J]. Journal of University of Electronic Science and Tech- nology of China, 2011, 40(1): 2-10.
[24] 谢斌. 朴素贝叶斯分类在数据挖掘中的应用[J]. 甘肃联合大学学报(自然科学版), 2007, 21(4): 79-82. XIE Bin. The application of naïve Bayesian classification in data mining[J]. Journal of Gansu Lianhe University (Natural Sciences Edition), 2007, 21(4): 79-82.
[25] 李如平. 数据挖掘中决策树分类算法的研究[J]. 东华理工大学学报(自然科学版), 2010, 33(2): 192-196. LI Ruping. Research of decision tree classification algorithm in data mining[J]. Journal of East China Institute of Technology (Natural Sciences Edition), 2010, 33(2): 192-196.
Fault prediction for turbine driven boiler feed water pump set based on classification algorithm
XU Hongwei, LIU Zhenyu, LI Chongsheng
(Xi’an Thermal Power Research Institute Co., Ltd., Xi’an 710054, China)
The turbine driven boiler feed water pump set is an important auxiliary part of the thermodynamic cycle system in thermal power plants. Effective fault prediction for the turbine driven boiler feed water pump set is helpful to its condition-based maintenance. In this paper, by a feature extraction method based on statistics and a feature selection algorithm named Relief, the history data in plant-level supervision information system (SIS) is converted to the input parameters of classification models rationally. Moreover, combing with the actual fault cases in two power plants, the blades fracture of small turbine in turbine driven feedwater pump set and dynamic/static balance disk rubbing in feedwater pump, five classification algorithms are applied to establish the classification models for distinguishing normal state and fault state. The actual data verification shows that, the BP neural network, support vector machine (SVM) and combined classification algorithm have better performance than other methods, which can identify the potential risks of faults 4~10 weeks in advance. The result provides new idea for other equipment failure prediction.
turbine driven boiler feed water pump set, fault prediction, BP neural network, support vector machine, combined classification, candition-based maintenance
National Key Research and Development Program (2017YFF0210500)
TH163+.3; TM621.7
A
10.19666/j.rlfd.201807139
徐红伟, 刘振宇, 李崇晟. 基于分类算法的汽动给水泵组故障预测[J]. 热力发电, 2019, 48(4): 128-134. XU Hongwei, LIU Zhenyu, LI Chongsheng. Fault prediction for turbine driven boiler feed water pump set based on classification algorithm[J]. Thermal Power Generation, 2019, 48(4): 128-134.
2018-07-26
国家重点研发计划项目(2017YFF0210500)
徐红伟(1990—),男,硕士,助理工程师,主要研究方向为火电厂设备状态监测及状态检修,xuhongwei@tpri.com.cn。
(责任编辑 杜亚勤)
