基于深度学习的车辆检测
2019-05-20时文忠王忠荣
□文/时文忠 王忠荣
随着社会的发展和人民生活水平的提升,汽车保有量在不断的快速增长,从一些大城市的车辆限号和限行可以看出来,交通监管面临巨大的压力。各种交通卡口和红绿灯路口都安装了智能监控,随着人工智能的发展,这些繁重的工作可以借助计算机视觉来辅助处理。让计算机自动处理这些图像数据,最重要的就是需要定位图像中车辆的位置,即车辆检测。本文将深入研究目前的一些目标检测算法并提出本文的检测算法。
相关工作
随着目标检测精度和速度要求越来越高,传统方法已经不能满足需求了。近年来,深度学习技术得到了广泛的应用,产生了一系列目标检测算法,例如两阶段目标检测算法,Girshick等在2014年提出的R-CNN算法一举夺得当年Pascal VOC比赛的冠军。SPP-Net提出空间金字塔池化,Fast R-CNN[3]在R-CNN中加入RoIPooling层调整特征图的尺寸,Faster R-CNN提出RPN取代以前的选择性搜索方法来更快的生成更准确的候选框,所有步骤由卷积神经网络完成,Faster R-CNN是第一个端到端的两阶段目标检测方法。另外一大类是单阶段检测算法,以SSD(Single Shot MultiBox Detector)系列、YOLO(You Only Look Once)系列、RetinaNet等为典型代表,基于全局回归和分类的框架,从图像像素直接映射到目标边界框和类别概率,可以极大较少开销提升效率,目前大多数单阶段行人检测器都可以做到实时检测。
本文方法
在深度学习领域,一个深度学习模型由三大部分组成,网络、损失函数和数据,网络用于提取特征,数据用于模型拟合,损失函数决定如何训练。同理,对一个模型的改进也可以从这三个方面入手:首先网络方面,改进车辆检测算法的网络,在三个方面影响检测性能:网络深度、下采样率和感受野大小;其次数据方面,本文使用在图像分类领域表现很好的mixup数据增广方法;最后损失函数方面,本文使用焦点损失和困难样本挖掘提升效果。
数据集
目前的公开数据集不多,本文通过采集大量交通卡口的视频和图像数据,然后使用一些目标检测工具进行人工标注。本文使用自建和公开数据集共计25000张图像,按照9:1的比例划分为检测模型的训练集和验证集。
在数据预处理方面,本文使用了常见的数据增广方法,比如随机裁剪,随机翻转,随机旋转(-30-+30度),另外还使用了一种在图像分类领域表现较好的mixup数据增广方法。
网络结构
在目标检测网络的骨干网络部分,在Darknet基础上进行改进,得到扩张卷积暗网络,由48层1*1卷积或者3*3卷积网络构成的全卷积网络,在网络最后一个模块使用Dilated Convolution(扩张卷积),扩张卷积的最大优点在于不做池化或者下采样的操作,可以增大感受野,让每个卷积输出都包含较大范围的信息,同时尽可能保留较大的特征图和图像的空间信息,这对于小目标检测非常关键。对于目标检测问题,使用扩张卷积可以极大的保留空间信息。使用扩张卷积时,由于特征图不减小,这会极大增加计算量,与一般的网络结构不同,DDN网络在最后一个模块里,所有卷积的通道数都设置为256。实验证明,该卷积层通道数是256(记为DDN-256网络)和通道数是1024(记为DDN-1024网络)相比,精度几乎没有下降或下降极少(由实际数据集决定),却极大减少了计算量。另外,在最后一个模块中只有4个残差模块,在这里使用Bottleneck结构(瓶颈结构),通过在每个模块的首尾分别添加1*1的卷积可以进一步减少计算量,加快预测速度,同时可以增加网络的深度和增加非线性,提升网络精度。
整个DPDN网络以DDN网络作为骨干网络,检测部分借鉴FPN思想,使用特征融合的手段进行多层检测,整体思路可以概括为,使用浅层的大的特征图检测小目标,使用深层的含更多语义信息的特征图检测大目标。在FPN中,通过融合深层的含有较多语义信息的特征和浅层的语义信息较少的特征,可以更好地定位各种尺度的目标。
损失函数
在网络的损失函数的分类部分加入了Focal loss(焦点损失)和OHEM(Online hard example mining,在线困难样本挖掘)方法,检测部分使用YOLO方法里面的L2损失函数。在线困难样本挖掘方法是在计算损失的时候重点关注比较难的样本,即损失比较大的那些样本,通过加权的方式来处理不同大小的损失。焦点损失可以让网络更加关注难识别的样本,设计加权损失函数,减少简单样本损失在总的损失中的比例,进行难例挖掘,可以进一步提升精度。式1为焦点损失公式。
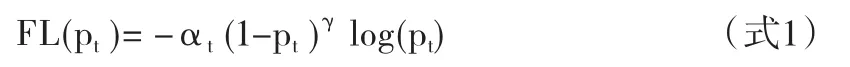
上式中pt表示目标检测结果中类别的识别概率,取值0~1之间,log自然对数,γ表示焦点参数,是一个0~1之间的数,αt是一个调制系数,是一个0~1之间的数,用来控制正负样本在总的损失中的比重。
训练和实验结果
使用预训练模型,先把DDN单独在ImageNet上训练分类模型,用来初始化骨干网络,后面检测部分的一些层使用随机初始化方法。本方法是单阶段训练方法,依赖预先设置的锚框(anchors),根据实际数据集调整anchors 的尺寸分布,该分布由K-means算法得到,使用(1-IoU)作为距离度量,其中IoU表示先验候选框与标记框之间面积的交并比。对数据进行左右翻转、随机裁剪、色彩抖动等数据增强操作,不断调整学习率、批量大小(batch_size)、优化方法等超参数来训练DPDN网络。
实验结果如表1所示,对比方法有Faster R-CNN和YOLO方法,在检测速度和精度两个重要维度进行对比,可以看到本方法全面优于上述两种算法。
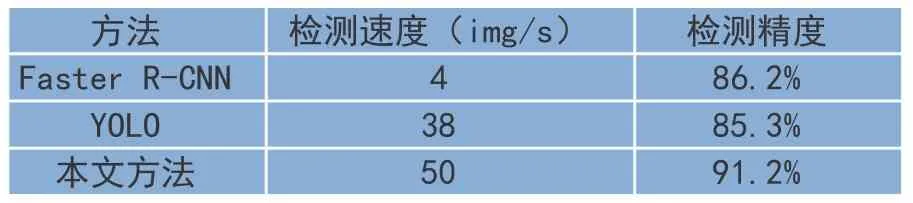
表1 实验结果对比表
本文方法的车辆检测结果展示如图1所示。

▲图1 本文方法检测结果
结论
本文在YOLO基础上设计新的目标检测网络DPDN。本方法的骨干网络是DDN,在末端卷积模块使用残差网络的瓶颈结构,引入扩张卷积,在不减小特征图的同时增大感受野,同时减少卷积通道数,在损失函数方面引入焦点损失函数,可以让模型更关注困难样本。改进检测网络和设计更合适的候选框。在检测部分,设计了一个新的检测网络,因为骨干网络使用了扩张卷积,最后两个模块的特征图的尺寸相同,可以不用做上采样。最终本文方法取得了较好的检测结果。
