基于数据库进行乏燃料鉴别的多元统计分析研究
2019-05-17苏佳杭伍钧胡思得
苏佳杭 伍钧 胡思得
1) (中国工程物理研究院研究生院,北京 100088)
2) (中国工程物理研究院战略研究中心,北京 100088)
3) (中国工程物理研究院,北京 100088)
近年来,随着国际核军控形势的变化,包含防扩散、防核恐及核安保的多边国际军控合作越来越受到重视.核取证技术作为防扩散、防核恐及核安保的一项核心技术,在对涉核非法活动的威慑、阻止以及响应方面具有重要作用,值得深入研究.目前针对核取证技术的研究较多,主要集中于材料的表征和数据的解读.其中解读作为核取证研究技术中最重要的一环,所面对的对象是多种多样的,包括铀矿石、黄饼、核燃料、乏燃料等,而其中乏燃料由于其潜在的威胁越来越受到重视.本文聚焦于在核取证场景中利用多元统计分析方法进行乏燃料鉴别的研究,主要是利用因子分析、判别分析和回归分析方法对乏燃料组分进行分析,研究各方法的适用范围,并为未来可能的利用数据库进行乏燃料鉴别的工作提供理论依据与可行方案,为相关核取证溯源工作的顺利开展提供支撑.
1 引 言
核取证学是对截获的非法贩卖的核材料或放射性物质以及其任何相关材料进行的分析,为核归属分析提供证据[1].核取证学是在核扩散日益严峻的背景下发展起来的,通过核取证学与行政法律手段的结合,可以帮助国际社会在源头及路径上控制核扩散与核恐怖活动.冷战结束以后,核走私事件增多,核取证学开始受到初步重视;近些年,随着国际恐怖主义威胁增加,核取证学开始应用于可能的核恐怖爆炸的样品的取证分析,以此获得核材料的识别特征,以及它们的工业加工过程,为溯源提供重要依据.因此,核取证学更加受到重视,越来越多的国家开始进行核取证学的研究与合作[2].
目前针对核取证技术的研究较多,主要集中于材料的表征和数据的解读.“表征”是为了确定放射性证据及相关证据的性质.基本表征给出放射性物质(包括主要成分、次要成分和微量成分)的全部元素分析结果.而“解读”则是将材料表征与生产历史进行关联的过程,目标是确定生产的方法和时间,是核取证学实验室的最终产品[1].相比较而言,表征多是应用实验室测量技术,而解读则涉及更为广泛的方法,也是目前核取证研究的热门方向.解读将经表征过程后有用的数据(通常称之为“识别标志”)进行处理,以还原与材料来源相关的信息.识别标志通常可分为两类,预测型和比较型[3].预测型识别标志是基于物理、化学以及工程等相关专业知识发现的材料特征,而比较型识别标志是基于对有问题的样品和已知样品的材料特征的比较而发展的.之前的许多研究中,一直试图通过寻找合适的核素或核素对特征(预测型)来表征未知核材料的来源信息,但很多情况下结果并不尽如人意,原因是理论上求出的差别很难在现实测量中给出高置信的结论.
而随着国际原子能机构(International Atomic Energy Agency)推动核取证数据库的建立[4],基于数据库的利用多元统计方法表征未知核材料(铀矿石、黄饼、UF6、铀燃料块以及乏燃料等)来源信息的研究日趋活跃.而作为核恐怖活动的潜在使用对象,乏燃料溯源研究也日趋增多.核恐怖活动涉及的装置包括放射性扩散装置、简易核爆炸装置和核爆炸装置,其中放射性扩散装置的风险最大[5].放射性扩散装置可使用的放射性材料包括医用放射源、工业用放射源、走私的核材料以及乏燃料等.其中乏燃料由于其强放射性一直受到高度关注,是制作放射性扩散装置的一个重要选择.与此同时,乏燃料的处置问题一直也是个热点问题,且目前尚无合理的解决方案,无论是后处理还是放置贮存,都是有争议的.目前乏燃料均处于放置贮存状态,但随着乏燃料数量的日趋增多,现有的贮存设施越来越难以满足需求,这也就增大了乏燃料的扩散风险.虽然目前尚未出现乏燃料走私的案例(当然也有可能是发生了尚未被发现),但针对可能发生的场景进行相应的研究是非常必要的.而一旦截获了乏燃料,通过α谱、β谱、γ谱以及各种质谱方法进行测量可以得到相应的核素信息,也即核取证技术中“表征”的主要工作,目前已经较为成熟.而对此进行的分析则属于“解读”工作的范畴,方法比较多元化,其中之一就是多元统计分析.多元统计分析在核取证溯源中的应用研究由于受到缺乏足够实际测量数据的限制,因此在近些年才逐渐开展起来.此项研究的基本思路是:首先对各种堆型的乏燃料组分进行模拟,构建相应的数据库;然后选取合适的核素用多元统计分析方法进行处理;最后对所得结果进行分析与评价.模拟的软件通常包括ORIGENS,FISPIN等燃耗计算软件[6],核素选取主要包括铀钚同位素、稳定裂变产物或根据需求选取的裂变产物组等[7-14],数据处理方法包括因子分析、主成分分析、偏最小二乘法、线性判别分析等[15-27],但目前主要研究还是聚焦于方法的可行性分析.
本文主要聚焦于在核取证场景中的乏燃料鉴别方法研究,重点研究利用多元统计分析方法(包括因子分析、判别分析和回归分析)进行乏燃料鉴别,以论证鉴别的可行性并对方法的适用性进行分析,为可能的乏燃料鉴别工作提供理论支撑.
2 理论与方法
多元统计分析是运用数理统计的方法来研究多变量问题的理论和方法,它可以对多个随机变量间的统计规律进行研究,应用范围较广.多元统计分析具有包括简化数据结构、分类与判别、变量间的相互关系以及多元数据的统计推断等功能.在本文的研究中,希望利用因子分析、判别分析和回归分析来实现数据的降维与可视化、未知乏燃料反应堆类型和初始装料以及燃耗的判断等功能.由于目前并没有非常合适的公开的乏燃料数据库,因此需要通过模拟计算来构建一个可供进一步研究的数据库.在构建好数据库后,分别利用因子分析、判别分析和回归分析的方法对乏燃料的初始信息进行反演,并将结果相互比较,论证各方法的适用范围,并以此形成较为合理的乏燃料鉴别方案.
2.1 因子分析
因子分析是多元统计分析方法中用于降维的一种方法.因子分析根据研究对象的不同可以分为R型和Q型因子分析.R型因子分析研究变量(指标)间的相互关系,通过对变量的相关阵或协方差阵内部结构的研究,找出控制所有变量的几个公共因子(或称主因子、潜因子),用以对变量或样品进行分类;Q型因子分析研究样品之间的相关关系,通过对样品的相似矩阵内部结构的研究找出控制所有样品的几个重要因素(或称主因子)[28].这里基于研究场景采用Q型因子分析.基本想法是,选定n个核素,通过数值模拟得到不同初始条件(堆型、初始装料、燃耗)下乏燃料样品中的这些核素的计算数据,并以此构建数据库,这样在数据库中每个样品的数据均为n维向量.然后寻找若干互不相关的n维向量,称之为公共因子,并用这些公共因子的线性组合来表征初始的向量.这里举个简单的例子来进行具体的说明.例如选取9个铀钚同位素(U-234,U-235,U-236,U-238,Pu-238,Pu-239,Pu-240,Pu-241,Pu-242)在乏燃料中的组分做研究,这样每一个样品提取出来的都是个9维向量.选择4个样品(A,B,C,D)进行分析,并利用三个公共因子(I,II,III)的线性组合来重新表征这4个样品,即

这里,AI,···,DIII等均为常数;Δ则是对于不同样品的特殊因子,在满足分析精度的要求时是可以省略掉的.这样,之前的9维向量就可以投影到由I/II/III构成的新的三维空间的一个点上了,也就实现了将数据从9维降到3维的功能.
2.2 判别分析
判别分析是用于判断样品所属类型的一种统计分析方法.判别分析问题通常可以这样描述:设有k个m维总体G1,G2,···,Gk,其分布特征已知(如已知分布函数分别为F1(x),F2(x),···,Fk(x),或知道来自各个总体的训练样本),对给定的一个新样品X,要判断它来自哪个总体.根据判别函数的形式不同,判别分析可分为线性判别分析和非线性判别分析.对于本文研究情景而言,由于各组样品的相互对立性较好,因此选取线性判别分析来进行研究.研究的基本思路是对已知的乏燃料数据按照堆型分组并计算各组的线性判别函数,然后将未知乏燃料数据代入进行分类判别.
2.3 回归分析
回归分析方法是多元统计分析的各种方法中应用最为广泛的一种.它是处理多个变量之间相互依赖关系的一种数理统计方法.建立回归分析的模型,就是将关心的问题具体化,考虑这些问题与哪些因素相关,然后用数据来估计因变量与自变量之间的关系.具体而言,就是将我们所关心的问题y表示成各个因素x的函数,即
y=f(x1,x2,···,xn).
如果将f(x) 具体化成线性形式,即这里u为误差项,就得到了线性回归模型.在本文的研究中,y可以是初始装料或者是燃耗,而x则是乏燃料中我们所关心的核素的组分.
y=f(x1,x2,···,xn)=β0+β1x1+···+βnxn+u,
3 数据准备
本文的研究是基于乏燃料中的同位素组分,通过多元统计方法对乏燃料的来源信息(包括反应堆堆型、初始装料以及燃耗等)进行鉴别.由于目前并没有非常合适的公开的乏燃料数据库,因此选择利用程序MCORGS对不同的反应堆进行模拟[29,30],并选取各乏燃料样品中的9种铀钚同位素(U-234,U-235,U-236,U-238,Pu-238,Pu-239,Pu-240,Pu-241,Pu-242)组分构建数据库.
根据反应堆堆型、初始装料及燃耗的不同共选择了148种不同的样品,其中包括了初始装料为UO2或者钚铀氧化物混合(MOX)燃料的压水堆(pressurized water weactor,PWR),初始装料为天然铀或者UO2的加拿大重水铀反应堆(Canada deuterium uranium reactor,CANDU),初始装料为MOX燃料的液态金属快速增值反应堆(liquidmetal fast-breeder reactor,LMFBR),初始装料为天然铀的镁诺克斯气冷堆(MAGNOX),初始装料为UO2的气冷堆(gas-cooled reactor,GCR),以及初始装料为高浓铀的高温气冷堆(high temperature gas-cooled reactor,HTGR),具体参数见表1.这样基于计算结果就可以构建相应的数据库了.

表1 反应堆模拟的输入参数Table 1.Input parameters for reactor simulation.
此外,用同样的方法选取了另外三个乏燃料样品作为未知样品(Uk1,Uk2,Uk3),其输入参数如表2所列.

表2 未知乏燃料的输入参数Table 2.Input parameters for unknown spent nuclear fuel.
4 结果分析
4.1 因子分析
4.1.1 降维与可视化
利用因子分析方法可以实现数据的降维与可视化.将数据库中的每一个样品都投影到三维空间上,即将每个样品从9维降到3维,可以达到可视化的目的(见图1)[31].

图1 数据库在3维空间的可视化处理Fig.1.Visualization of database in three-dimensional space.
图1中的三个坐标轴就是前面提到的公共因子,在此例中均为9维向量.而不同颜色的点代表着来自不同反应堆的样品(这里将反应堆类型及初始装料类型都相同的视为同一来源),明显地,不同来源的样品在三维空间上形成了不同的组,并占据了不同的空间,也就是说因子分析方法可以用于区分反应堆类型.但这种区分能力是定性的,也就是说,在增加未知乏燃料样品的数据后再进行因子分析,未知样品在三维空间中落在哪个样品堆里,就定性地判断它们为同一堆型的.
4.1.2 初始装料与燃耗的鉴别
通常来讲,因子分析的作用在于降维与可视化处理以及分类工作,并没有直接进行定量化鉴别的功能.也就是说,并不能直接通过因子分析方法鉴别出未知样品的燃耗与初始装料.但可以在因子分析结果的基础上通过其他的方法近似预测一下未知样品的燃耗与初始装料,虽然这样的精度并不一定非常好.
这里将三个未知样品的乏燃料数据插入之前的数据库中,然后通过已知样品来预测未知样品的燃耗与初始装料.具体的方法是针对不同未知样品选取合适的二维投影,并利用其周围的四个点,通过海伦公式定量计算未知样品的初始装料与燃耗(如图2所示).
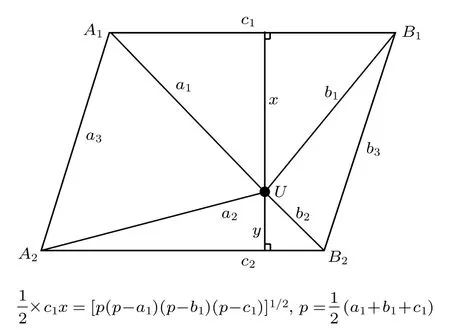
图2 海伦公式示意图(U点为未知样品点,A1,A2,B1,B2为已知样品点)Fig.2.Diagram for Heron’s formula (Ustands for unknown sample,A1,A2,B1,B2stand for known samples).
这里存在两个假设,首先要假设平面上的数据变化是单调、线性的,此外还要近似认为未知样品所落区域是平行四边形.同时还要适当选取投影平面,不同的样品需要的投影平面是不一样的,因此通常误差也是比较难以控制的,具体结果见表3.
不难看出,这种方法进行的定量鉴别还存在一定的误差.值得注意的是,这是在三个投影平面的鉴别结果中的最优解,而在实际情况中,由于并不知道未知样品的初始参数,因此并不一定会选取到最优解,这也就可能会进一步增加相对误差.
4.2 判别分析
4.2.1 反应堆类型判断结果
从因子分析的结果中不难发现,不同类型反应堆的乏燃料数据之间的差别还是很可观的.因此将数据库中的数据按照反应堆类型进行分类,其中PWR UO2和PWR MOX由于初始装料本身存在很大的差异,因此看作两种不同的反应堆.而后对数据库中的数据进行线性判别分析,并将三个未知乏燃料的数值代入进行反应堆类型的判断,结果如表4所列.

表3 因子分析鉴别结果Table 3.Result of identification by using factor analysis.

表4 反应堆类型判断结果Table 4.Result for the determination of reactor type.
不难看出,利用线性判别分析对三个未知样品反应堆类型的判断所得到的结果都是正确的.其中未知样品2和3的反应堆类型判断是非常准确的,而未知样品1的反应堆类型判断稍有误判概率.这是因为在本文的模拟中,PWR和CANDU堆所选取的反应堆模型是一样的,再加上初始装料类型相同,只有装料量和燃耗上的区别,因此在进行反应堆类型的判断时,会产生一些误差,但并不影响判断结果.而将线性判别分析的结果与因子分析的结果进行比较可以发现,因子分析对反应堆类型的判断是定性的,也就是说是通过未知样品落在降维后的空间中的位置来判断其应该属于哪一类型;而线性判别分析则可以更直观地、定量地给出未知样品属于某一反应堆的概率,并选取最高概率确定其反应堆类型.因此相较于因子分析而言,线性判别分析更适合用于反应堆类型的判断.
4.2.2 乏燃料初始装料与燃耗的相关鉴别
根据前面对判别分析的描述不难看出,和因子分析一样,判别分析并不适于进行定量化的鉴别,即当需要定量化地描述未知样品的某一自变量,而这个自变量又并不完全和已知样品的自变量相吻合的时候,判别分析是不适用的.
这里,基于线性判别分析,可以用以下的方法来近似计算初始装料和燃耗.基本思路为:计算未知样品对各个总体的线性判别函数值,对燃耗/初始装料和各线性判别函数值进行多项式拟合,寻求极值点,并求出极值点对应的未知样品的燃耗/初始装料.这里应用到了距离判别的思想.利用马氏距离来进行计算,其定义为[12]

其中,G为考察的总体;X为未知样品;μ为均值向量;∑为协方差阵.而线性判别函数值是与未知样品和各总体的马氏距离相关的,即

这里Gi是各数据组,为各数据组的均值,S为合并样品协方差阵.也就是说,线性判别函数值越大,证明其马氏距离越小,当线性判别函数取极大值时,马氏距离为0,此时对应的燃耗/初始装料值即为未知样品的预测值.以未知样品Uk1为例,将数据库中的PWR UO2组的数据按照初始装料继续分组,然后通过线性判别分析来计算各组的线性判别函数,再将Uk1的数据代入到各线性判别函数中,拟合初始装料-线性判别函数值(如图3所示),寻求极大值点的初始装料值,即认为是Uk1的初始装料.
这里横坐标为初始装料值,纵坐标为线性判别函数值,拟合的结果为二次多项式,只要求极值处的横坐标值即可.这样按照该方法可以对三个未知样品的初始装料与燃耗进行鉴别.值得注意的是,对于不同的情形拟合出的多项式的阶次是不一样的,要根据拟合度进行判断选择.这样得到线性判别分析结果与因子分析结果的比较,如表5所列.
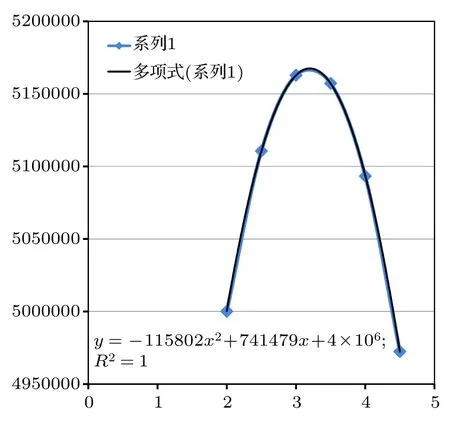
图3 对未知样品1的各线性函数值的多项式拟合Fig.3.The Polynomial fitting of the linear function values of unknown sample 1.
不难看出,线性分析的鉴别结果要普遍好于因子分析的鉴别结果.这里有几点需要说明:首先,对于堆型的判断,因子分析是定性的,而线性判别分析是定量的,因此虽然判断的结果相同,但是还是线性判别分析要好一些;其次,对于初始装料和燃耗的判断,因子分析有很多假设和不确定性,线性判别分析则少很多.因子分析是3个投影平面选取最好的,这在现实应用中是不可能的,而线性判别分析则没有这方面的要求.但仍需要注意到,对判别函数值拟合求极值的方法仍然会引入一些误差.
4.3 线性回归分析
通过之前的分析已经可以较好地分辨未知乏燃料的反应堆类型了,但是初始装料和燃耗的相关反演还不尽如人意,因此这里采用线性回归分析再次进行鉴别分析.对于三个未知样品,选取其同反应堆类型的样品数据重新构建数据库,再利用线性回归分析进行初始装料与燃耗的鉴别分析,结果如表6所列.
不难看出,在初始装料和燃耗的鉴别方面,线性回归分析的结果要好于前两种方法.这主要体现在两方面:首先,线性回归分析得到的结果更接近于真实结果,鉴别精度更高;其次,线性回归分析的假设与限制更少,更具有普适性.同时,如果数据库中自变量和因变量之间不是线性关系的话,回归分析也能给出相对更为准确的鉴别结果.
5 三种多元统计方法比较
综上所述,不同的多元统计方法针对的数据处理目的不同,可以实现的功能与适用范围也就有所差别.简言之,因子分析的主要作用是对数据进行降维,即简化数据结构,使问题得到简化而损失的信息又不太多.同时因子分析还具有初步的分类能力,但多偏于定性;判别分析的主要作用是对数据按照相似程度进行分类,且这种分类能力是定量的,相对于因子分析而言更为准确和实用.同时判别分析可以在一定条件下进行数值预测(在本文的场景里就是对未知样品的初始装料和燃耗进行预测);回归分析则侧重于对初始参数的预测,通过对已知样品的乏燃料组分和初始参量进行回归分析,来预测未知样品的初始参量,因此在本文的场景中更适于进行未知样品的初始装料与燃耗的鉴别.具体的分析结果如图4所示.

表5 线性判别分析与因子分析结果比较Table 5.The comparation of the results from discrimination analysis and factor analysis.

表6 利用线性回归分析进行初始装料与燃耗的鉴别分析的结果Table 6.Results for the determination of initial enrichment of uranium and burn-up by linear regression analysis.

图4 三种多元统计方法的比较Fig.4.Comparation of the three multivariate analysis methods.
图4中线性判别分析和线性回归分析在数据简化方面并不是不适用,而是其数据简化过程并不像因子分析那样可以直观展示出来,二者的数据简化过程都是为了后面的分类与鉴别做铺垫的.从图4不难看出,乏燃料的鉴别过程是首先通过因子分析进行数据简化,通过可视化初步展示鉴别的可行性,然后通过判别分析进行未知乏燃料反应堆堆型的判断,最后再用回归分析来确定未知乏燃料的初始装料和燃耗.这是一个串行过程,例如在进行完反应堆堆型的判断后,会对数据库进行一次缩减,将堆型不符合的数据舍弃,然后用剩下的数据再进行下一步分析.与此同时,因子分析在此过程中并不是必需的,可视情况决定此步骤是否进行.
6 结 论
本文对利用多元统计分析方法进行乏燃料鉴别开展了研究,主要应用了因子分析、线性判别分析以及线性回归分析的方法.通过研究发现,利用不同的多元统计方法可以实现不同的功能,通过这些方法的有机组合,可以形成一个比较完整的乏燃料鉴别方案.这样基本理清了乏燃料鉴别的流程框架,即利用不同的多元统计方法对乏燃料的不同来源信息依次进行鉴别,并根据鉴别结果精简数据库,然后进行下一步鉴别.研究表明,多元统计分析方法可以通过已知的乏燃料数据库来进行未知乏燃料鉴别,随着各国以及国际核取证数据库的不断发展以及核取证研究与应用的不断推进,多元统计分析方法在未来核取证溯源工作中可以发挥相应的作用.
