借款陈述文字中的违约信号——基于P2P网络借贷的实证研究
2019-05-15谢彦妩
陈 林,谢彦妩,李 平,李 强
(电子科技大学经济与管理学院,四川 成都 611731)
1 引言
民间金融对中国经济发展具有重要作用[1]。P2P网络借贷(Peer to Peer Lending)正是近年来重要的民间金融之一。它是借贷双方通过互联网信息平台直接达成资金借贷交易,而不再依靠银行等传统金融机构。2005年第一家P2P网络借贷平台Zopa在英国诞生,2007年“拍拍贷”、“人人贷”等网络借贷平台网站将该模式引入我国。据零壹财经数据报告,截止2016年11月30日,国内P2P借贷平台约4800余家,但其中正常运营的仅有1613家,占比33.6%,问题平台达到3163家。网络行业表现出如此高比例的问题平台,其原因之一就是社会信用体系不健全,同时也没能有效解决借款者的信用风险识别问题。由于借贷交易通过互联网进行,投资者更难核实借款者信息的真实性,信息不对称问题可能比传统信贷更为严重。如何有效识别P2P网络借款者的信用风险,仍然是整个行业持续健康发展亟待解决的关键问题之一。与此同时,建立科学的客户信用评估模型,准确、有效地预测客户可能发生的欺诈行为意义十分重大[2]。
在P2P网络借贷模式下,投资者判断借款者的信用风险,规避借款者的逆向选择和道德风险的主要途径是依靠借款者在借贷平台上展示的信息。这些信息主要包括借款者的个人特征信息与财务信息[3]、社会资本信息[4-6]、以及借款者为了借款而展示的借款陈述信息[7-8]。借款者的这些信息又可以分为硬信息(hard information)和软信息(soft information)[9-10]。硬信息指能够被验证的客观信息,例如借款者的身份证号码、信用报告、收入信息等信息。软信息则指不能被直接验证的信息,如借款者的社会资本、借款陈述文本、还款意愿等信息。在银行等传统金融机构的借贷领域,一般通过硬信息度量还款能力,进而评估借款人的违约风险。由于借款人的还款意愿也是产生违约风险的根源之一,所以甄别借款人的还款意愿一直都是违约风险评估面临的重要挑战之一。
目前,P2P网络借贷的违约成本低,较小的借款金额使得借款者能否按时还款,更多取决于其还款意愿,而非还款能力。所以还款意愿的识别对于保护投资人的利益尤为重要。心理学研究表明,自然语言中运用的词汇能在一定程度上反映出作者的自我认知和社会地位[11]。所以,人们也早已认识到描述性文本信息在经济领域中有着重要作用,例如,关于组织认同的描述性信息能帮助企业家获取所需的经济资源[12],企业家的商业计划书在不确定性较高的金融交易中起到关键的信息桥梁作用[13],上市公司的信息披露之间的相似度与股权资本成本之间存在正相关关系[14]。基于同样的道理,借款者对借款项目的描述信息或许能为投资者识别借款者的违约风险提供有用的线索。因为借款陈述通过对借款者现状的表述和未来还款行为的塑造,也许在某种程度上会蕴含着借款者为了展示或者隐藏自己还款能力和还款意愿的相关信息。所以,本文从借款陈述文本中提取文字特征信息、还款能力和还款意愿信息、对资金需求紧急程度的情感特征等信息,并检验它们对识别借款者违约风险的作用。
当前对借款陈述的研究主要集中于借款陈述对借款成功率的影响。例如Larrimore等[15]分析了借款陈述中表现的诚信、成功、勤奋、经济困难、道德和宗教特征对借款成功的影响;Herzenstein等[16]从文本长度、人性化细节等能间接反映借款者财务状况的变量出发,分析对借款成功率的影响;廖理等[17]从语言长度与语言内容两个维度分析了借款陈述在P2P借贷市场的作用,语言长度越长,借款成功率越高,如约还清率越高;涉及某些话题(创业、家庭、急迫、诚信)影响借款成功率但与如约还清率无关。还有研究将借款陈述中的借款用途、总单词数、单词的平均音节数等作为控制变量,研究性别、种族等其它因素对网络借贷的影响[18],以及外貌对成功借款的影响[19]。
综上所述,现有研究还少有通过借款陈述信息提取有助于识别借款者违约风险的相关变量,与本文关注的违约风险相关的主要研究有Gao Qiang和Lin Mingfeng[8]、廖理和吉霖等的研究。Gao Qiang和Lin Mingfeng从文本的可读性、反映的积极态度、客观性和欺诈线索四个维度分析它们与违约之间的关系。廖理等[17]则主要分析了文本长度与违约风险之间的关系,认为文本越长,违约的风险越小。不过廖理等[17]的这个结论与Gao Qiang和Lin Mingfeng[8]的观点并不一致,在Gao Qiang和Lin Mingfeng研究中,文本越长可能代表文本的可读性下降,从而违约的可能性越高。
Gao Qiang和Lin Mingfeng[8]使用文本分析软件(Linguistic Inquiry and Word Count)处理英文的借款描述,廖理等[17]则通过编程实现对特定词语的查询得到研究变量。然而与违约风险息息相关的还款能力、还款意愿等借款者主动表述的信息还没有得到重视。这可能受限于目前语言分析软件还无法处理复杂的语言内容和情感。所以,本文基于国内网贷平台“人人贷”的借款项目数据,通过人工识别的方法,从借款陈述文本中提取反映借款者还款能力的收入信息、信用状态的补充说明信息以及对资金需求紧急程度的情感信息,然后检验这些信息变量对识别借款者违约风险的显著性。本文研究与Gao Qiang和Lin Mingfeng[8]和廖理等[17]的研究相比,关注于他们没有考虑的信息变量,即从借款陈述文本中发现是否存在能反映潜在违约风险的还款能力、还款意愿和对资金需求的情感等信息。人工识别的方法虽然处理的样本数量有限,但更能识别模糊性的信息,并且也为未来进一步通过编制程序分析借款陈述中的模糊信息提供校对标准。
全文内容安排如下:第一部分是引言;第二部分是借款陈述文本分析所涉及的变量定义、变量的统计特征和研究问题假设提出;第三部分是研究假设的验证和稳健性分析;最后部分是研究结论的总结分析。
2 借款陈述信息
2.1 借款陈述中的信息变量
我们拟从借款陈述文本中提取如下三类信息变量:
第一类信息:文字特征信息。主要从借款陈述的文本长度、语句中是否含有错别字、是否为了增加长度进行重复的语句粘贴三个维度描述文字特征信息,借款陈述例子见表1。Gao Qiang和Lin Mingfeng[8]的研究结论:文本越长,可读性下降,意味着违约可能性增加。这可能是因为借款者由于自身文化水平的限制,产生了较长的、重复性的、或者有错别字的借款陈述。但Gao Qiang和Lin Mingfeng结论是基于英文文本的结果。而廖理等[17]结论正好相反,即借款陈述文本越长,违约可能性越小。但是廖理等[17]未关注到错别字、重复这样的语法错误现象。因此,本文在继续考虑文本长度的同时,增加考虑错别字和重复语句信息是否对判断违约风险有显著作用。

表1 借款陈述中的文字特征信息示例
文字特征信息可能反映了借款者的受教育程度,而已有研究表明教育程度与个人信用水平相关。简洁、准确的借款陈述文本体现的是良好的教育水平,从而违约可能性更低。所以,与Gao Qiang和Lin Mingfeng[8]的研究类似,本文希望在中文语言环境下验证如下假设:
假设1:借款陈述文本越长、有错别字、有重复语句,则借款者违约风险越大。
第二类信息:表现还款能力和还款意愿的信息。P2P借贷平台为了保护借款者的个人隐私,在网站上进行信息展示的时候尽可能地隐藏了借款者的详细个人信息,只保留了借款者收入水平类别和公司行业类别信息。但借款者在借款陈述中可以自愿提供其它更为详细的信息来证明自己的还款能力或者还款意愿。比如对工作状况的补充,包括公司名称、主营业务、公司地址、兼职副业等,以及对收入状况的补充说明,包括具体收入金额、家庭成员收入、多种收入来源等(见表2)。

表2 还款能力与还款意愿的信息示例
另一方面,为了表达更强烈的还款意愿,借款者还可能对自己的信用状态进行说明,以及出现承诺性的保证语言,借此向投资者表达自己是一个值得信任的人。为此,本文将验证如下两个假设:
假设2:借款陈述文本存在还款能力信息,则借款者违约风险越小。
假设3:借款陈述文本存在还款意愿信息,则借款者违约风险越小。
第三类信息:情感特征信息。我们从两个方面挖掘借款陈述中的情感特征信息。一方面是在借款陈述中,是否使用了第一人称“我”、“我们”、“本公司”等表述,基于已有的研究结论表明,一个恶意欺诈的人一般会规避使用第一人称表述,以逃避某种“罪恶”感[20]。另一方面,如果借款人在借款陈述中表现出对资金的需求很强烈,则可能表明其经济状态比较差,从而将来违约的可能性较高。或者出于欺诈的因素,而急于想借到钱,因而在借款陈述中更多使用“谢谢”、“感谢”等感谢性语言和“拜托”、“帮忙”等请求性表达(见表3)。因此,本文还将验证如下两个假设:
假设4:借款陈述文本中存在第一人称表述,则违约风险越小。
假设5:借款陈述文本中表现出对资金需要意愿越强,则借款者违约风险越大。

表3 借款陈述中的情感特征信息示例
2.2 被解释变量、解释变量和控制变量
被解释变量为借款项目的逾期状态,用二元变量default表示,即借款者在规定时间内正常还款,default=0;借款者在规定时间内未还款,逾期30天(含)以内以及逾期超过30天由人人贷进行垫付,default=1。
因为借款金额、借款利率、借款期限及由平台给出的借款人信用分数已是借贷中用于评估信用风险的主要变量,所以本文将这四个变量设置为控制变量。除此外,利率和信用分数还用于控制不同时期平台的利率定价机制和审核机制对违约率的影响,因为,借款利率是在不同时期的利率定价机制下形成的。
最后,根据前一节关于借款陈述文本中的信息变量介绍,被解释变量、解释变量和控制变量如表4所示。

表4 被解释变量、解变量和控制变量
2.3 样本数据与变量的统计特征
本文以“人人贷”的“信用认证标”借款项目为研究样本。“信用认证标”借款是“人人贷”平台对借款用户的个人信用资质进行审核后,推荐在平台上的借款项目。该类借款项目没有其他机构担保,属于纯信用借款,因此对借款者的违约风险识别尤为重要。
“人人贷”平台成立于2010年5月,是我国最早发展P2P借贷的平台之一。由于初期P2P行业也还处于发展时期,所以2010年的借款标的数据较少。2011年开始逐步增加,但2011年期间违约的信用借款项目特别多。由于样本数据是通过第三方公司网络爬虫获取,所以在对2011年至2015年期间的信用借款项目数据进行整理后得约两万余条数据完整的信用借款项目信息。由于我们将个人信用评分(score)作为主要的控制变量之一,而平台所展示的个人信用评分(score)总是借款人的最新信用分数,而没有借款人过去的变化分数。因此就不能用这个最新的信用评分(score)去解释一个借款者过去所有的借款项目。为了解决这个问题,我们就选择同一个人的最后一笔借款作为研究样本,以保证个人信用评分(score)能在时间上与借款项目相对应。这样,剔除掉同一个借款人的多笔借款,而保留最后一笔借款,最后得到8453条借款项目信息。这些样本中,按照逾期还款就算违约的界定,发现其中有逾期还款的借款人约占三分之二。
选择个人信用评分(score)作为对借款者信用风险度量的控制变量后,不再需要将借款者的个人其它信息如性别、婚姻状态、学历、收入作为控制变量,因为平台给出的信用评分已经考虑了借款者的上述信息。如果再加入这些信息,会受到严重的多重共线性影响。另一方面,由于个人信用评分(score)是由平台根据借款者个人与资产信息评出的,所以选择个人信用评分(score)作为主要控制变量,也在一定程度上代表了平台的评价水平,对平台的评价政策的差异性进行控制。
自然语言表达的丰富多变使得要计算机自动理解其中蕴含的情感语义比较困难[21],研究的时间较短,很多技术和方法不够成熟[22],而中文比英文在语言结构以及句式类型更加复杂,导致针对英文文本情感分析的一些方法在对中文文本情感分析的应用并没有取得理想的结果。所以对借款陈述的语义识别,由研究团队通过人工识别分析完成。由于人工识别和核对有较大的工作量,所以暂时处理了部分样本,分别选择了1500名违约的借款信息和1500名未违约的借款信息进行人工识别。确定这些样本的借款陈述文本中是否存在错别字、是否有重复语句、是否有对工作和收入的补充信息、是否有信用状况补充说明或者还款保证、第一人称的使用、请求性的语言等信息变量。
人工识别和核对虽然也会面临语义理解问题,但由于识别人本身有较高的教育水平,也能准确识别语言语义。例如,如果仅仅依靠程序识别感谢性语言,程序设计可能只考虑到“谢谢”或“感谢”这样的词汇。但人工识别的情况下,能将“感激”等同义词也归为感谢性的表达。所以,人工识别自然也能识别“麻烦”、“帮助”、“帮帮我”、请”、“希望”等词语为表示请求性的语气。总之,本文希望在准确语义识别的基础上,研究这些语义信息是否能反映借款者的违约状态。
进一步,考虑样本中逾期还款的比例约占三分之二。从人工识别的3000条样本数据中,分别得到三组样本。每组样本数据为800条,由480条违约数据和320条未违约数据组成。这三组样本,按照借款时间逐一从3000条样本中选取。一组用于假设检验测试,下文称为测试样本组。另外两组用于稳健性检验,下文分别称为稳健检验样本组1和稳健检验样本组2。表5、表6、表7分别列出了测试样本组、稳健检验样本组1和稳健检验样本组2的统计特征。

表5 测试样本组变量的统计特征
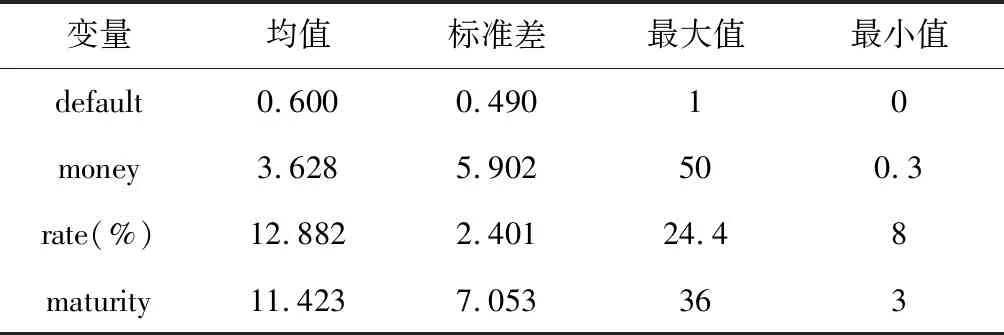
表6 稳健检验样本组1的统计特征

续表6 稳健检验样本组1的统计特征
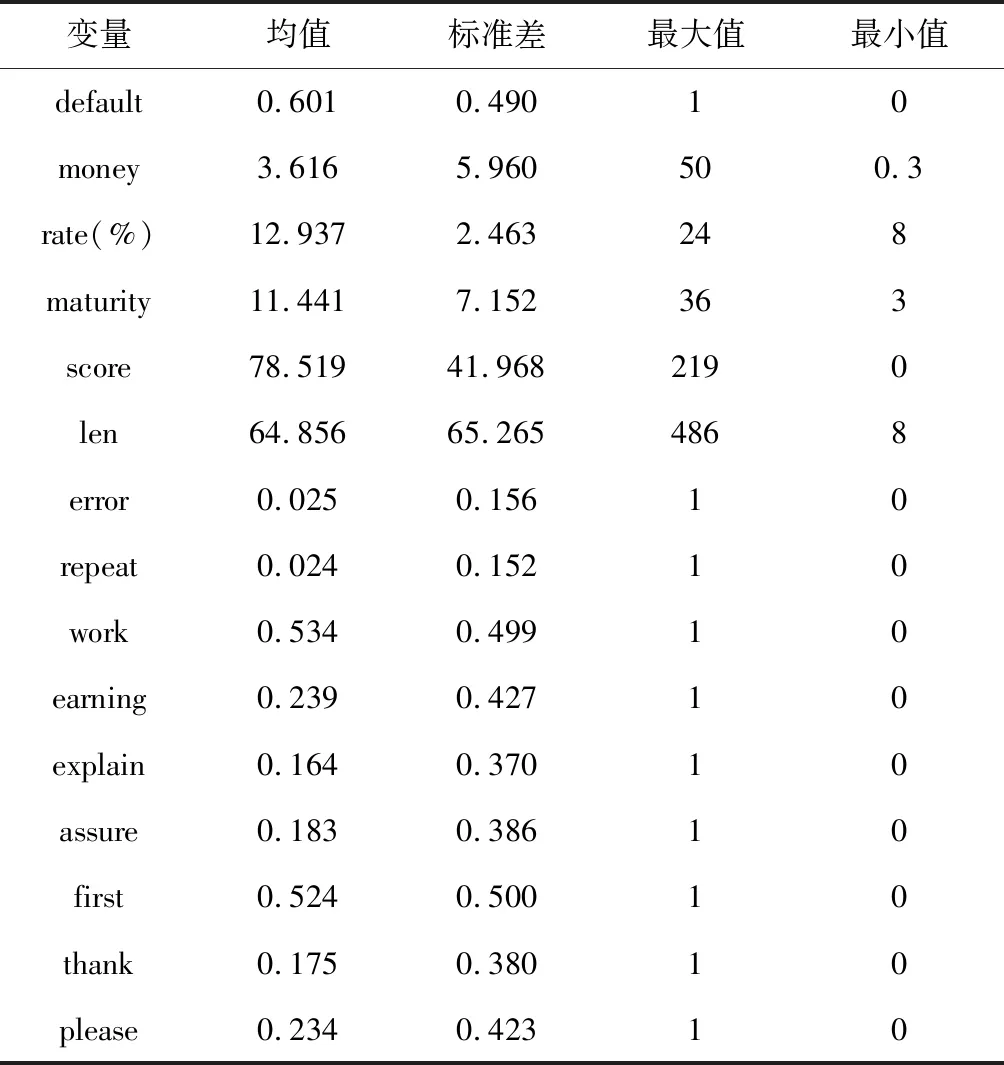
表7 稳健检验样本组2的统计特征
根据表5、表6、表7的描述性统计结果可知,借款金额平均在四万元左右,最少的借款额只有三千元,这体现了P2P网络借贷的小额性质。借款利率均值为12.9%左右,远高于银行的存款利率,对投资者有较大的吸引力;借款期限平均在11个月左右,体现了P2P网络贷款短期借款的特征;借款者信用分数平均在80分左右,说明信用认证标的大多数借款者的信用评分并不高。
为了初步考察研究问题所涉及被解释变量和解释变量之间的关系,以及分析变量之间是否存在严重相关性,表8给出了各个变量的相关系数矩阵和显著性水平。由表8可知,情感特征变量中的请求性表达(please)、还款意愿和能力补充信息变量(explain和earning)、是否有重复语句变量(repeat)、借款陈述中的文字长度变量(len)与违约状态(default)存在显著的相关性。这是进一步选择它们作为违约的解释变量的基础。除此外,控制变量借款金额(money)、利率(rate)、期限(maturity)和信用评分(score)也与被解释变量违约状态(default)存在显著的相关性,表明它们作为控制变量的合理性。从表8还可知,尽管一些解释变量之间、控制变量之间也存在显著的相关性,但这是由它们内在的经济含义所决定的。例如,借款金额、利率一定跟信用评分相关,评分越高,理所当然借款金额就越高、利率越低。所以信用评分与金额存在正相关性,信用评分与利率存在负的相关性。但是它们之间相关系数值并不大,远小于一般判断可能会导致严重多重共线性的参考标准(0.8)[23]。
表8 测试样本组的相关系数
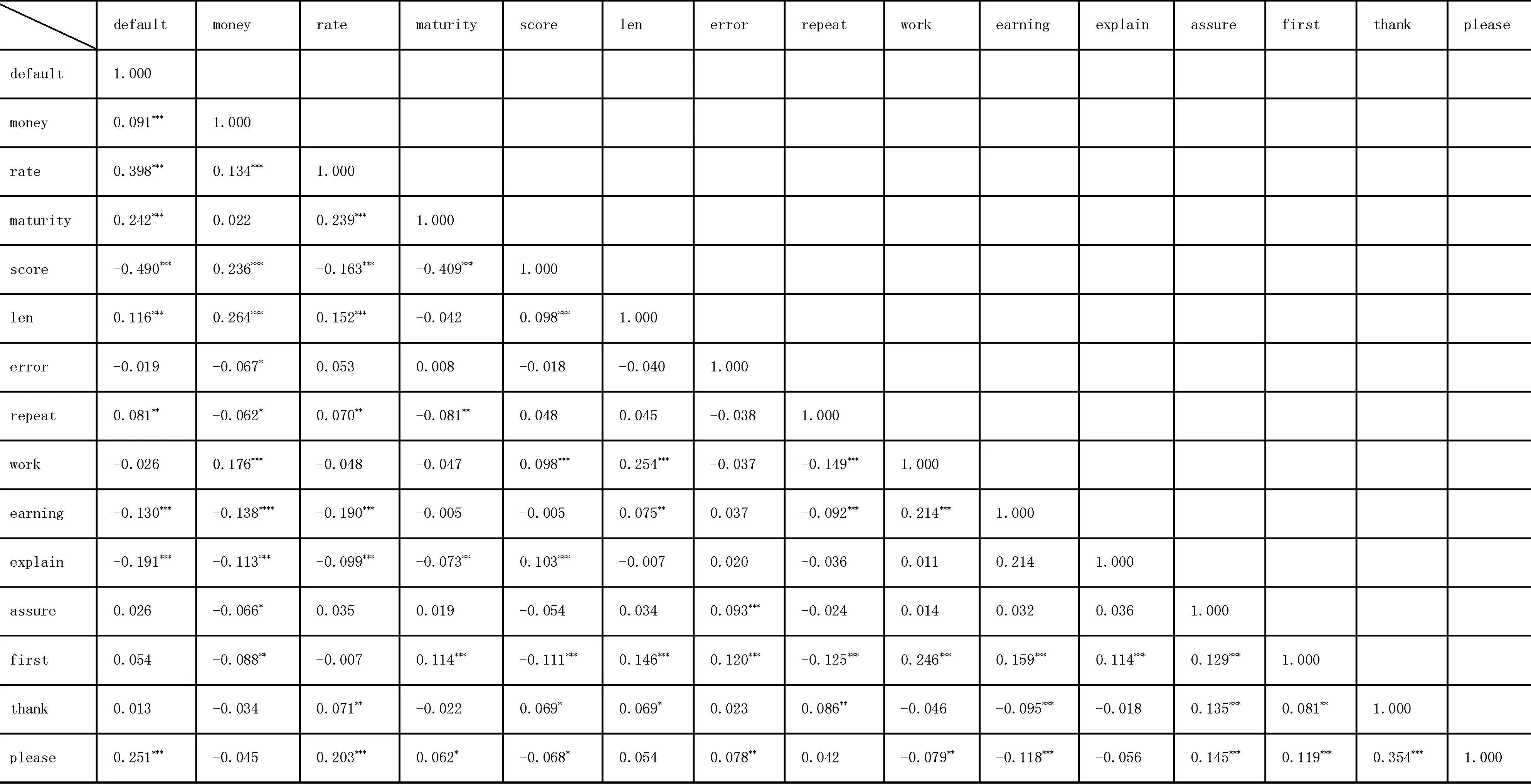
说明:***,**,*分别代表1%,5%和10%的显著性
当然,从相关性表中也发现一些有趣的现象,例如信用评分(score)和期限(maturity)存在显著的负相关,似乎表明信用越好的人,借款期限越短。其实这也符合逻辑,因为P2P网络借款的利率较高,信用评分较高的人,往往可能只是通过P2P借贷进行短期的周转,而不愿意承担长期的高利率。
总之,基于上述相关性分析,一方面表明控制变量与解释变量的选择逻辑是合理的,另一方面也可排除变量之间存在严重多重共线性的可能,这是进一步建模分析的基础。
3 借款陈述文字中的违约信号检验
3.1 测试样本组的统计特征
对假设1~5的验证,分别运用以下五个Probit模型,在验证样本组数据下,得到的结果见表9。
模型1:
P(default=1)=α+β1*money+β2*rate+β3*maturity+β4*score+β5*len+β6*error+β7*repeat+ε
(1)
模型2:
P(default=1)=α+β1*money+β2*rate+β3*maturity+β4*score+β8*work+β9*earning+ε
(2)
模型3:
P(default=1)=α+β1*money+β2*rate+β3*maturity+β4*score+β10*explain+β11*assure+ε
(3)
模型4:
P(default=1)=α+β1*money+β2*rate+β3*maturity+β4*score+β12*first+β13*thank+β14*please+ε
(4)
模型5:
P(default=1)=α+β1*money+β2*rate+β3*maturity+β4*score+β5*len+β6*error+β7*repeat+β8*work+β9*earning+β10*explain+β11*assure+β12*first+β13*thank+β14*please+ε
(5)
首先,根据表9中的参数结果可知,控制变量信用评分(score)、借款金额(money)、借款利率(rate)与预期的符号一致,并且显著。即表明信用评分越高,违约的可能性越低;借款利率越高,风险越高,违约的可能性也越高;同理,借款金额越高,风险敞口也就越大,所以违约的可能性越高。不过,借款期限(maturity)却没有和违约概率有显著的正相关,其系数反而是负的。这可能是因为期限与利率之间的相关性导致,即期限越长,利率通常越高,对此我们在模型1的基础上,分别单独只选择借款利率(rate)或者借款期限(maturity)作为控制变量,得到的结果都显著地与违约概率成正向关系。虽然可能同时把它们放在一起不合适,但并不影响解释变量的系数符号和显著性。

表9 模型1-5的参数估计结果
模型1对文字特征信息与违约之间关系的假设检验表明,借款陈述文本的字数越多,或者存在重复语句,借款者违约的可能性越大。这个结果与Lin和Gao的结果是一致的,因为在他们对借款陈述的分析中,字数越多表明文本的可读性较差,违约的可能性较高。但另一方面,错别字对借款违约的解释作用与预期相反,但与相关性分析一致。或许是通过计算机输入文字,由于输入法的原因,无法反应借款者真实的文化水平。
在模型2中,借款陈述中关于工作信息和收入信息的披露没有对违约状态有显著的解释效果。但正如上面对控制变量的讨论,当我们剔除了借款期限(maturity)后,进一步控制期限和利率之间的相关性后,即通过如下模型:
P(default=1)=α+β1*money+β2*rate+β4*score+β8*work+β9*earning+ε
(6)
则发现,对收入信息的披露在10%的置信水平下(β10=-0.226),与违约概率是负相关的,即有收入信息披露的借款人,违约概率会更低一些。但工作信息披露与违约的关系仍然不显著,且与预期的符号也不一致,这可能是由于平台的信用评分已经包含了借款者的工作信息,只是对投资者而言不可见。另外,可能因为在涉及收入信息时,不可避免将涉及到工作信息。由于收入信息更容易量化,所以,平台的信用评分也可能包括借款者的收入信息,如果投资者再补充收入信息,在信用评分影响的基础上,应该进一步降低违约率,所以,在(6)式中加入收入信息和信用评分交叉项:
P(default=1)=α+β1*money+β2*rate+β4*score+β8*work+β9*earning+γ1*score*earning+ε
(7)
此时β9=1.643,而γ1=-0.019,显著水平都为5%,其它变量的显著性与符号未发生改变,也就正好验证当加入收入补充信息的时候,能更显著的降低违约概率。由于我们将收入信息作为还款能力信息的代理变量,所以上述结果验证了假设2,即借款陈述文本存在还款能力信息,则借款者违约风险越小。
其次,从表9中模型3的结果,能看出如果有对自己历史信用状况的解释说明,则有更低的违约概率。能客观说明自己的信用状况,表明借款者还款意愿上的诚实性,因为具有欺诈想法的借款者,一般更不愿意提供更多的信息,或者往往倾向于隐藏对自己不利的信息,所以提供了对自己过去信用状况说明的借款者就显得更加可信,因此违约概率更低。单独分析保证性的还款意愿信息的系数,并不能对违约状况具有解释作用,如果借款者对过去信用状态做出相应的解释,而后给出保证性的承诺,是否更可信呢?于是在模型3的基础上加入对信用解释说明和还款保证说明的交叉项:
P(default=1)=α+β1*money+β2*rate+β3*maturity+β4*score+β10*explain+β11*assure+γ2*explain*assure+ε
(8)
在(8)式的回归结果中,其它变量符号与显著性未改变,但交叉项系数γ2=-0.764,显著水平为10%,正如上述分析,此时违约可能性更低,也就是借款人更可信,也即验证了假设3。
最后,借款者为了获得借款而做出请求性、感谢性的表达,表明了对资金的需求愿望越强。而从表9中模型4的结果可知,对资金需求的急切性越高,其违约的概率也就越高,因此验证了假设5。但是,无法验证假设4,是否使用第一人称的表述与违约与否的关系不显著。进一步的,根据表9中模型5得出的结果,也对上述结论进行了验证。下一步将在另外两组样本基础上分析上述结论的稳健性。
3.3 稳健性检验
首先相关性分析表明:稳健检验样本组1和稳健检验样本组2中的解释变量、控制变量与被解释变量关系与预期基本一致,各变量之间的相关性较小。然后,分别对这两组样本运用Probit模型分析,模型结果见表10(稳健检验样本组1)和表11(稳健检验样本组2)。
表10的结果与检验样本组的结论一致,而表11的结果在收入信息(earning)与被解释变量之间的显著性发生了改变。我们分析这可能是由于稳健样本组2中样本的信用评分可能更多包含收入信息、工作信息所导致相关性的结果。所以,当对稳健样本组2去掉信用评分和工作信息变量,只保留收入信息变量时:
P(default=1)=α+β1*money+β2*rate+β3*maturity+β9*earning+ε
(9)
此时,可知收入信息仍然显著地影响违约状况,β9=-0.191显著水平是10%。
综上所述,在本文样本的范围内,运用Probit模型得出的关于借款陈述文本中提取的文字特征变量、反映还款能力和还款意愿信息变量、以及反映主观对资金需求的强烈程度的变量与借款者违约状态之间的关系是稳健的。

表10 模型1-5的参数估计结果
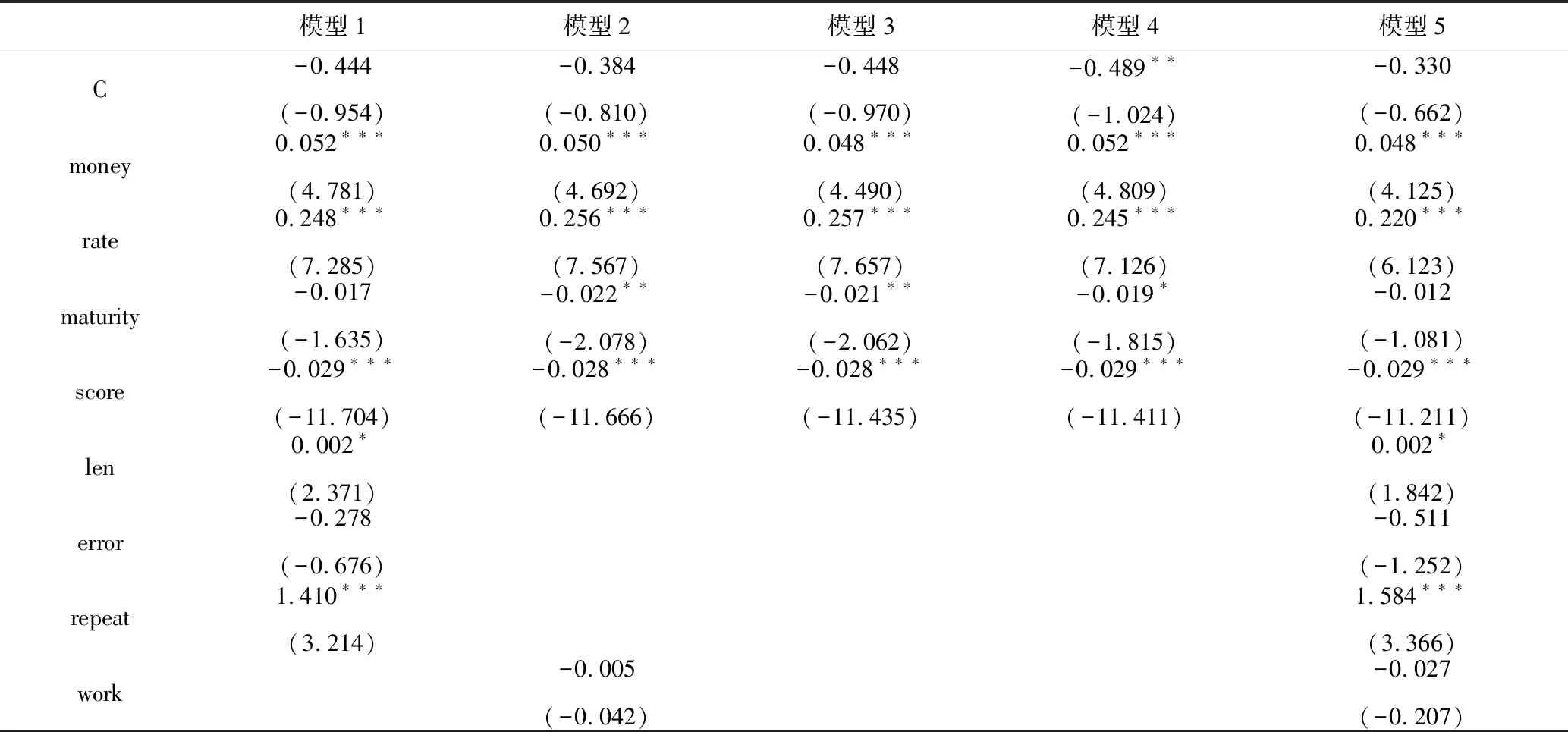
表11 模型1-5的参数估计结果

续表11 模型1-5的参数估计结果
4 结语
本文从“人人贷”网络借贷平台的借款项目陈述文本中提取了文字特征信息、反映还款能力和还款意愿的信息以及对资金需求的情感特征信息,并检验这些变量对识别借款者违约风险的可行性。研究发现:(1)借款陈述文本的字数越多,存在重复语句,借款者违约的可能性越大;(2)借款陈述文本中存在还款能力信息,则借款者违约风险越小;(3)借款陈述文本中同时存在表示还款意愿的保证性语言以及对自己信用状态补充说明的信息,则借款者违约风险越小;(4)借款者在情感上表现出对资金需求的急切性越高,其违约风险越高;(5)借款陈述文本中存在第一人称表述,没有表现出与违约风险的显著关系;(6)错别字对借款违约的解释作用不显著。这些结论虽然是在人工识别有限数据样本的基础上得到,但它们仍然为进一步通过程序软件实现文本挖掘算法来分析借款者的信用水平指明了研究方向。
另一方面,上述结论背后的一些深层次逻辑关系还有待进一步研究。例如文本长度影响违约状态,长文本究竟是反映借款者的教育水平、收入水平从而影响借款者还款能力,还是反映了欺诈的信息从而代表还款意愿影响违约状态。同理,资金需求的紧急程度是否也代表欺诈性的线索,还是代表还款能力线索还有待进一步分析。还有为什么存在第一人称表述没有表现出像心理学方面研究的一致结论。除此外,其它一些外部因素,如宏观政策、平台的信息披露政策等是否对结论有影响,有在待后续研究中进行控制。
总之,P2P网络借贷真正有别于传统的借贷,首先要在信用风险评估上面有突破,而不再是仅仅依靠传统的财务信息和历史信息。传统信贷领域,有经验的信贷员能在面谈后大致估计出一个借款人的可信程度。如何让计算机通过人工智能程序实现并超过“有经验的信贷员”的信用风险评估能力,都离不开文本和语义的识别技术。
