命名数据网络包处理流程性能改进
2019-05-08于广路
于广路

摘要:互联网用户对数据的内容感兴趣,而并不关心它的位置在什么地方。但是,当前的客户端/服务器架构仍然需要一个请求被定向到特定的服务器来获取响应。命名数据网络(NDN)是可以满足这种以内容为需求的全新的网络模式,这种网络的转发决策是基于内容的名称而不是IP地址,并很好的解决了当前TCP/IP网络设计上的缺陷。本文将会从微观架构探索NDN网络包处理流程中执行流水线的执行情况,并分析因为访存带来的流水线暂停的性能瓶颈问题,最终提出了两种指令预取的策略来提高CPU缓存命中率和系统吞吐量。
关键词:命名数据网络;NDN;指令流水;数据预取
一、命名数据网络的意义。
命名数据网络(Named Data Network,NDN)[1]是将内容的名字作为网络转发的核心信息,与当前的IP网络对比,NDN不再使用特定的IP地址,而是具有层次结构的内容的名字进行数据的发送和获取,NDN路由也不再按照IP地址进行数据包的转发,而是根据名字进行路由转发,这种全新的网络并不限制对于特定的名字是由哪个主机来提供数据,也不需要知道内容的提供者是谁,只需要将需要获取的内容以名字为核心封装为兴趣包发送到网络中,然后等待数据的返回。通过这种与IP主机网络完全不同的网络架构相比,可以获取如下优点:(i)路由节点缓存数据可以减少网络负载和延迟;(ii)数据包经过签名更加安全;(iii)不再固定地址,具有更好的移动性;(iv)减少了以内容的应用层的通信复杂度。
命名数据网络作为下一代的网络架构来设计,是要总结最近几十年网络模式实践中出现的一些问题并加以解决。其中该网络最大的特点就是路由节点不再单纯的只做存储转发,而且加入了数据包缓存的能力,这样对于相同的请求,可以从距离请求方最近一个缓存了数据的路由节点返回请求的数据包,网络请求可以立即结束,网络链路短,提高了内容资源的重用性,避免了网络中传输大量相同的数据,因而可以提高整个网络的吞吐量和资源的利用率。
尽管NDN这种全新的网络架构提供了非常好的好处,但是部署实施确是遇到了最大的挑战,如何克服IP网络向NDN网络的过渡和转换是不得不面对的问题。虽然网络功能虚拟化(NFV)给命名数据网络的部署实施提供了一种机会[2],可以避免现有NDN网络部署需要对大规模基础设施的升级,但是这种机会的前提是需要设计出一个高性能的,稳健的命名数据网络软件路由,可以运行在现有的商用硬件平台上,并提供高效的路由转发性能,使得NDN的实现不再只停留在实验的阶段。
二、命名数据网络的数据结构和包处理流程。
命名数据网络主要有兴趣包(Interest package)和数据包(Data package)两种数据报文类型,其中,名字在兴趣包和数据包是都存在的,相同名字的兴趣包请求相同名字的数据包,一个是发起数据请求的时候由消费方发送兴趣包,另一个是由网络中拥有相同名字数据的节点进行相应的数据包。
NDN网络的转发机制相对比IP网络单纯的路由转发机制是要复杂一些的,因为考虑到了数据的缓存。首先内容的消费者会根绝需要获取的内容名字来构造兴趣包,然后会将该兴趣包在网络内进行广播,当路由节点接收到该兴趣包的时候,路由节点需要首先查询兴趣转发表(Pending Interest Table,PIT),然后查询内容缓存(Content Store,CS),当没有缓存数据的时候,会通过查询路由转发表(Forwarding Information Base,FIB)来确定转发端口。在NDN网络中的FIB是与IP网络中的FIB相类似的,他们都包含了名字(IP地址)和转发端口的映射关系,并根据路由协议来对FIB进行生成和更新,该数据结构是路由转发的关键数据结构,并且转发端口并不限制单出口,可以像多个出口进行路由的转发。当有数据包到达的时候,会按照一定的策略将数据缓存在内容缓存(CS)中,这样当有大量请求相同名字的兴趣包到达的时候可以第一时间将CS中缓存的数据发送给请求侧,快速的完成网络的请求,而不需要像IP网络那样,每一个请求都只限定在端对端的通信范围内,无法复用相同的相应数据。
三、分析数据包处理流程的性能瓶颈。
指令预取是为了隐藏CPU指令周期中因为需要访问内存数据导致流水线中断的关键技术。因此需要分析在网络数据包处理流程中因为哪些访存操作导致了CPU流水线中断的情况。
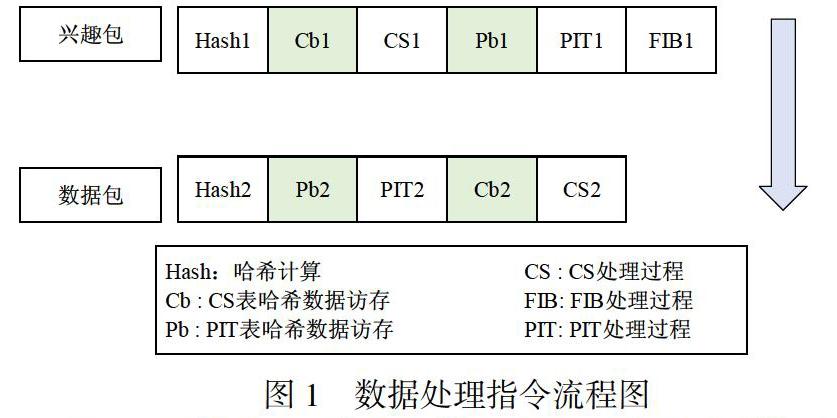
在NDN網络中,存储在内存上的数据有PIT、CS存储名字的哈希表,FIB中用于最长前缀匹配而设计的布隆过滤器和哈希表,对内存的访问主要就是哈希表自身和哈希表中的元素。因此知道转发线程何时访问这些数据结构地址就变得非常重要。图1显示了NDN网络中兴趣包和数据包的典型流程。在图中所示的是兴趣包和数据包前后到达的时候,CPU处理的指令流程。接下来使用序号1表示兴趣包,序号2表示数据包。同时因为处理兴趣包和数据包的指令流程是最长的,因此选择这2个包来进行分析。从图中可以看出,当兴趣包到达的时候,需要访问PIT、CS数据结构的哈希表,FIB的哈希表也需要访问,但是需要在布隆过滤器计算之后才得出需要访问的哈希表的位置。接着根据数据包的名字搜索CS来判断是否已经缓存了该名字的数据,当CS不会存的时候需要搜索PIT是否已经存在该名字的记录,然后会PIT进行修改。如果通过FIB进行名字前缀最长匹配,找到输出端口然后进行转发。同时,需要注意的是,当PIT不存在指定名字的记录的时候,还需要将插入一条记录到PIT中。
从图1中,很容易观察到2处因为CPU需要等待访存从而导致流水线暂停的情况。首先,Cb1和Pb2都是不能预取的,因为这两个访存操作依赖前一步名字的哈希计算过程,这样的情况下,地址计算和访存之间没有CPU的时间间隔,因此只能等待哈希计算完成后不得不停止当前流水线的执行等待Cb1和Pb2两个访存操作完成后才能进行后续的处理过程。第二个就是在访问CS或者PIT之后,才能决定后续需要访问的哈希表,因此这种后续操作需要依赖之前操作结果的过程会导致CPU流水线的停顿。
四、通过指令预取策略来消除访存导致的流水线阻塞。
本节设计了两种预取策略,即预哈希计算和预测哈希表(HT)查找,假设如下:因为系统提供了四个内存通道,内存中的多个数据段被并行地获取,即最多四个数据是可以同时获取的。处理PIT、CS和FIB的逻辑流程所消耗的CPU周期比哈希表查找过程更多,这意味着完全可以在计算哈希值的过程中进行数据的预取,这样就达到了通过预取的方式来隐藏CPU流水停顿带来的性能开销的目的。
下面根据图5-8来描述这两种策略。图5-8中的序列是从图5-7得来的,但是是基于应用预取策略的前提下得出的。首先,预哈希计算指的是将哈希计算的过程提前,因为哈希表查找的整个流程中,查找的Key都是名字对应的哈希值,而不是名字的自身,所有没有必要等到需要查询哈希表的时候再进行哈希值的计算,所以只有对哈希进行预计算,才可以对进行后面的数据并行预取。
因为在对兴趣包的名字哈希计算完成之后,需要进行数据的预取,因此在此時,对第二个包,也就是数据的哈希值进行计算,这样就可以避免了CPU因等待访存而引起的停顿。这种策略意味着在在多个数据包的情况下应该重新考虑计算的顺序。也就是说,选取的两个连续的数据包,在最坏的情况下,大量的数据包会导致同时处理多个数据包的状态,而这些数据包可能会存储在内存上。因此采用了一种预计算的方法来对哈希计算进行改进,在计算完第一个数据包的哈希值之后,紧接着计算后续数据包的哈希值。同时,从内存中获取CS、PIT的哈希表项,如图中的Cb1、Pb1所示步骤。哈希计算的过程隐藏了因为虚伪访存获取哈希表项所导致的阻塞。
其次,计算了第一个包的哈希值后,该兴趣包的所有哈希表(即CS、PIT和FIB)的哈希表项都可以从同时从内存中获取了。因此,所有哈希项,包括那些由于最长前缀匹配结果而无法访问的哈希项,都是基于推测性地预获取的,也就是说获取到的数据在后续的处理流程中可能根本用不到。这种策略被称为推测性的哈希查找。在获取后续数据包的哈希项之后,推测性的哈希查找将应用于该数据包的哈希项,需要注意的是,它适用于所有哈希表和哈希项。
对数据预取策略的实现结果显示平均包处理的CPU周期可以降低20%以上,这将大大的提高了数据包转发的速率。
五、总结。
为了解决通用平台网络包处理的性能瓶颈问题,本文从微观架构层面分析NDN网络处理流程中指令流水的执行情况,然后提出了两种数据预取的策略来降低访存对系统吞吐量的影响。在高性能软件的设计流程中,需要尤为注意内存访问的操作,因此访存的次数很大程度上影响了CPU流水线的执行,导致性能降低,所以该数据预取策略同样可以为其他对性能要求极高的软件设计的提供参考。
参考文献
[1] Zhang L,Estrin D,Burke J,et al. Named Data Networking(NDN)Project NDN-0001[J]. Acm Sigcomm Computer Communication Review,2010,44(3):66-73.
[2]Van Adrichem N L M,Kuipers F A. Ndnflow:Software-Defined Named Data Networking[C]// Network Softwarization(Netsoft),2015 1st IEEE Conference,London:IEEE,2015:1-5.
