基于互译特征词对匹配的老一汉双语句子相似度计算方法研究
2019-04-28李思卓周兰江周枫张建安
李思卓 周兰江 周枫 张建安


摘要:句子相似度的计算在自然语言处理的各个领域有很广泛的应用,但跨语言的句子相似度计算方法却非常少。文中提出一种基于互译特征词对匹配,构建老一汉双语句子相似度计算方法,改进了传统的依赖于词形词序通过计算相同词个数和共有单词的位置信息的相似度计算方法,充分考虑了老挝语和汉语句子中的词汇互译信息、相似概率,避免了由于特征词位置导致的精度丢失。此方法用来最终识别相似度较高的老一汉双语平行句对,依据相似度对源句子和目标句子进行对齐,在老一汉双语平行语料库的建设中使用。实验结果表明,此方法在一定程度上提高了老一汉双语句子相似度计算的准确率。
关键词:老一汉双语词典;相似度计算;算法改进;双语句对识别;词汇互译;实验验证
中图分类号:TN912.34-34
文献标识码:A
文章编号:1004-373X( 2019) 24-0079-05
0 引言
句子相似度计算是自然语言处理领域中比较重要的研究课题,在双语语料中,句子相似度本身是对齐的基础因素,而全局的优化调整能进一步提高对齐的正确率。因此,一直以来句子相似度计算都是自然语言处理领域中不断研究的重点问题。
在句子相似度计算研究方面,大致可以分为三类:基于表层信息,通常计算句子中词形、詞序、句长相似度等信息。邸书灵等对基于分词的语句相似度计算进行了改进,综合考虑了词形、词序和句子长度等多方面的信息[1]。基于句子结构,如基于词类串结构、本体结构[2]、词性及词性依存结构[3]等。蓝雁玲等通过计算词性及词性依存信息来把握句子间的相似性[4]。基于语义资源,主要通过已经建成的语义资源考察词间的语义关系[5]来计算句子相似度,如基于WordNet[6],HowNet或同义词林来计算。
本文在前人研究的基础上,针对双语语料库中的对齐块(段落对齐或者篇章对齐)提出一种基于互译特征词对匹配,并结合构建的老一汉双语相似词典的句子相似度计算方法,用来最终识别相似度高的老一汉双语平行句对,在老一汉双语平行语料库的建设中使用。
本文提取老一汉双语的特征词生成各自的特征词列表,根据排序后的特征词列表,选择在列表中分布相近的词汇作为候选相似对,依据特征词列表选取特定窗口的特征词对,最终生成候选相似对列表,并计算每一个相似对的相似概率。将候选相似对中的每一个相似对及其相似概率生成老一汉双语相似词典,并且根据特征词在语料中的上下文不断扩充双语词典。基于最终的老一汉双语相似词典,可以得到汉语句子中每一个特征词对应的候选相似集合,得到相似结果。依据相似结果和每一个相似对的相似概率,得到老一汉双语句子的相似度值。
1 筛选互译特征词
1.1 传统的词形词序相似度计算方法
词形相似度方法是通过计算两个句子的词形即相同词的个数来比较相似度的。首先对两个句子分词,用SiArr和S7Arr两个数组分别存放两句子分词后的单词,然后再计算出两个句子共同包含的单词个数sum,若共有单词出现次数不相同则取最小出现次数。Len (S1)表示S1分词后的词语数,则两个句子Si,S2词形相似度计算公式为:
CSim( Si,S2)= sum/max( Len( S1), Len( S2)) (1)可以看出,词形相似度取值范围为[0,1]。
词序相似度是通过共有单词在两个句子中所处的位置信息来反映两个句子的相似度,首先计算出S1和S2中都出现且只出现一次的词的集合onews。然后计算出onews中各个词语依次出现在S2中的位置向量,计算出逆序数count。利用onews中的词语在两个句子中的顺序来判断词序的相似度,容易得出词序相似度取值范围为[0,1]。词形词序的相似度能够反映出两个句子之间的相似程度,但在跨语言使用中并不是有很好的效果,必须转化为同种语言使用,但是翻译的过程中会导致计算的准确率下降。
1.2 特征词列表建立
无论哪种文本都存在一些没有实际意义,但是使用频率很高的虚词和功能词,这些词往往对于句子的区分度不大。针对汉语和老挝语中的一些无实际作用的虚词和功能词,构造停词表,将这些词在实际应用中过滤掉。进行特征词筛选之前,首先对句子进行预处理,进行分词,利用中科院开源的SharpICTCLAS分词系统[8]和本实验室开发的Lao Word Segmentation( LaoWS)老挝语分词系统分别对汉语文本和老挝语文本分词,得到汉语和老挝语词语序列。
TF-IDF是一种用于信息检索与数据挖掘的常用加权技术,用以评估字词对于一个文件集或一个语料库中的其中一份文件的重要程度。其中词频(TF)、逆向文件频率(IDF)表示如下:
TFw=在某一类中词条w出现的次数 (2)
该类中所有的词条数目
IDF=log 语料库的文档总数
(3)
包含词条w的文档数+1
TF-IDF= TF.IDF
(4)式(3)中,分母之所以加1是为了避免其为0。
在双语语料库的对齐块中,如果一个源语言句子和一个目标语言句子互为译文,那么在这个句对里面频率相同的词汇可能是互为译文的。在两个句子中,相同词、相近词体现了两个句子的共同点,对两个句子相似起到了较大的贡献作用。本文将TF/IDF值作为筛选特征词的依据,分别按照TF/IDF值的大小对老挝语和汉语的特征词列表中的特征词进行排序,在各自的列表中处于相似位置的词很可能是互为译文的。
2 相似度计算方法
2.1 候选相似对列表的建立
根据第一节得到的排序后的特征词列表,选择在列表中分布相近的词汇作为候选相似对,依次针对老挝语特征词列表中的每一个特征词,以对应的汉语特征词为中心选取特定数目的汉语特征词,作为老挝语特征词的候选相似;同理根据汉语特征词列表中的每一个特征词也选取特定数目的老挝语特征词,作为其特征词的候选相似。由于句子中特征词之间的联系取决于设定的窗口大小,为了更大限度地将特征词的对应关系建立出来,本文将选取的窗口控制在[-2,2]之间。
根据老挝语和汉语的特征词列表和候选相似生成候选相似对列表,此列表中的每一个相似对都是可能互为翻译的老挝语特征词和汉语特征词,此时需要计算每一个相似对的相似概率。在一个相似对中,定义老挝语特征词LWi、汉语特征词CWj,则这两个特征词之间的相似概率计算方法如下:
由式(6)可以看出,对相似概率公式起主要作用的还是汉语和老挝语某个词的词频,通过扩大窗口来挑选候选相似可以提高相似概率计算的准确性。但是一篇文章中,会存在某个词只存在一次的情况,这样利用式(6)进行计算,会存在相似概率为logl=0,为了避免这种情况,将词频为1的词进行词频加1,防止由于词频太低导致句子相似度计算不正确的情况。
为了更形象地展示特征词列表的建立过程,本文选取了老一汉双语平行语料库中的一段文本进行实验,将TF/IDF值作为筛选特征词的依据,构建的特征词列表如图1所示。
当特征词列表构建完成后,通过汉语一老挝语、老挝语一汉语两种语言之间候选相似对的选取(选取窗口[-2,2]),本文选择此窗口已经能够将老挝语和汉语的上下文对应关系尽可能多地包含其中。选取过程如下:图1中已经给出了特征词列表,针对汉语的特征词,根据选取窗口的大小,得到从汉语一老挝语的三个候选相似对。同理,对于对应老挝语的特征词,可以得到老挝语一汉语的三个候选相似对。通过从汉语一老挝語、老挝语一汉语两个方向候选相似对的选取,能够更大限度地将特征词的对应关系建立出来。相似概率之间的计算按照式(5)计算,最终构建的部分候选相似对列表如图2所示。若某个词只存在一次,会导致相似概率的计算结果为0,因此对词频进行加1,图2左下角显示。
2.2 老一汉双语相似词典的建立
通过实验发现,根据候选相似对列表中的每一个相似对生成最初老一汉双语相似词典,在控制的窗口内选择的相似对进行计算后,在每6对或者8对相似对中,会出现相似概率相同的情况,相似概率越大,将其放在老一汉双语句子中,两个句子之间的相似度值也就越高,成为平行句对的可能性就越大。为了更大限度地将互译关系体现出来,本文将相似对概率相同的相似对也考虑进去。选择相似对概率相同的以及相似概率最大的相似对进入到老一汉双语词典中,相似词典中的每一个条目包括了老挝语和汉语特征词对以及相似概率。
确定好最初老一汉双语相似词典之后,通过词典中的特征词在双语语料中的上下文来扩展双语词典,形成最终的老一汉双语词典。将双语词典中每一对特征词对作为种子翻译对,如果在原文中发现经常某个词经常同时出现在他们前面或者后面,那么将这个新的词对作为新的种子翻译对加入到双语词典中,这个过程是一个迭代的过程,直到不能再生成新的词典条目为止。
同样地,对于上文选取出的文本,在对相似对的选择与老一汉双语词典的扩充之后,筛选部分最终的老一汉双语相似词典如图3所示。
2.3 老一汉双语句子相似度计算
在得到最终的老.汉双语相似词典之后,通过查询所扩充之后的双语词典可以得到汉语句子中各个特征词对应的老挝语候选相似集合。假设汉语句子C=[CW1,CW2,…,CWn],老挝语句子L= [LW1,LW2,…,LWn]其中CWi和LWj分别表示汉语句子和老挝语句子中的第i个和第j个特征词。则对于每一个汉语特征词CWi都可以在相似词典中找到对应的老挝语,即:L=[CW1{ LW1.1,…,LW1.n), CW2,…,CWn{LWn,1,…,LWn,n)],其中老挝语特征词LWi,k,表示汉语特征词CW;对应的一个译文。
利用老挝语特征词在老挝语句子中的出现次数、汉语特征词在汉语句子中的出现次数以及老挝语和汉语特征词的相似概率计算老一汉双语句子的相似度值。老一汉双语句子相似度值计算公式为:
根据改进后的式(8)可得到两个句子的相似度值:
Simw( C,/)=0.336 589 961
通过实验可得,式(8)计算出的句子相似度值总是在[0,1]之间,句子中包含的特征词越多,句子相似度值越大,准确率越高。
3 实验结果与分析
本文实现的跨语言句子相似度的计算方法主要应用在用来最终识别相似度高的老一汉双语平行句对,在老一汉双语平行语料库的建设中使用,可以很好地促进各种汉老文化交流和双方的发展。上述实验结果证明,两个句子互译特征词对的匹配可以很好地反映出句子之间的相似程度,匹配越好,相似度越高。
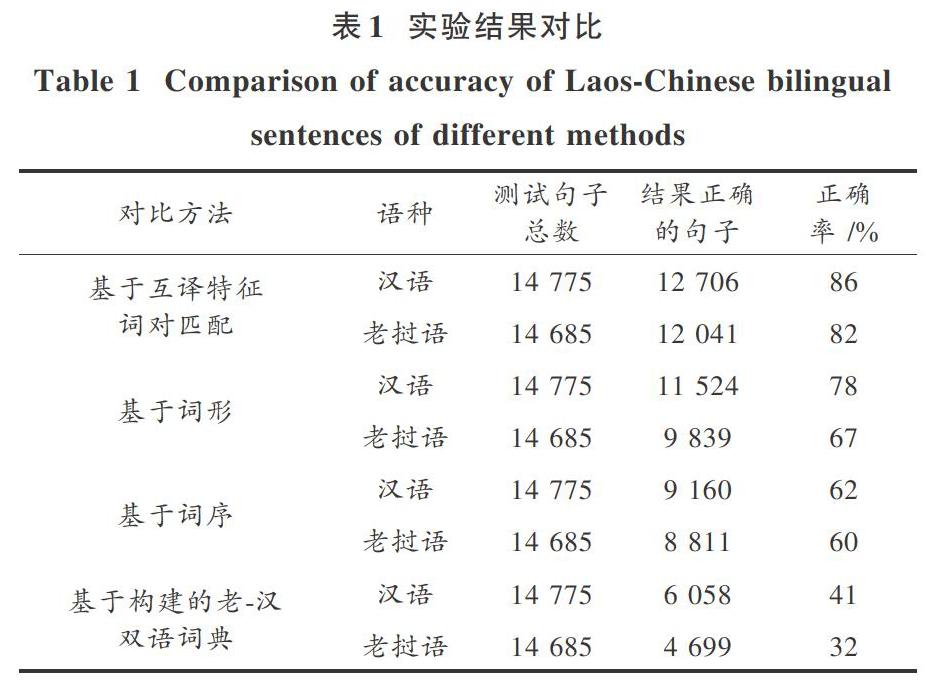
在本实验室整理的老一汉双语语料库中分别抽取文学、历史、教育、经济、社会等24个领域的相关文章,共630篇文章,从中人工抽取13 650个老汉双语平行句对作为标准集,同时加入在各个领域中选取的一到两篇非平行篇章作为噪音集,其中汉语句子共1 125个,老挝语句子共1 035个。标准集和噪声集合并得到14 775个汉语句子和14 685个老挝语句子作为测试集。
本文中首先从14 775个汉语句子中按顺序抽出一个句子,然后计算这个句子与14 685个老挝语句子之间的相似度,并按照所得相似度的大小对老挝语测试集中的句子进行排序并输出相似度最大的老挝语句子,如果该句子是抽取的汉语句子在标准集中对应的老挝语句子,则说明这个句子的相似度计算是成功的,对老挝语句子做相同的操作。
双语词典资源是机器翻译等自然语言处理领域中非常重要的基础资源,它的词汇量及翻译质量都会对实验结果评估指标的准确率造成直接影响。目前存在着已经成熟的汉英双语词典、汉日双语词典等,但是缺乏已经成熟的汉老双语词典。国内互联网上并没有可用的汉老双语词典,通过国外老挝语网站及英语一老挝语双语网站搜索到包含15 768个老挝语常用词的老挝语单语词典及大量的英老双语词典和一定规模的汉老双语词典。借助英汉双语词典当作媒介,整理获取到关于老挝语的单语言词典及双语词典,最终获得规模达到31 719个词汇的汉老双语词典。老汉双语词典如图5所示。在构建的老一汉双语词典中,其中常用相关领域的词典条目仅有6 000多条,较多的几乎都是一些学科的专有名词以及地名等词语,日常生活中使用量较少。经过筛选,日常使用的名词和动词等占比不大,不足3 000条。人名、地名是双语句子对齐的重要特征,但是它们大多为未登录词,无法利用双语词典进行互译匹配。因此,利用词典在老一汉双语句子相似度计算中实际实验结果收效甚微,不足以形成对比。
实验评价标准如下:分别用本文提出的基于互译特征词对匹配的方法和基于词形、基于词序、基于构建的老一汉双语词典的句子相似度方法做了实验,实验结果见表1。本文采用的评价标准为P(准确率),计算如下:
P=n/N×100%
(9)式中:P代表正确率;Ⅳ代表测试句子总数;n代表测试结果正确的句子总数。
从上述的实验结果可以看出,本文提出的基于互譯特征词对匹配的老一汉双语句子相似度计算方法具有较高的准确率,适合这种跨语言句子相似度计算。此方法改进了传统的依赖于词形、词序通过计算相同词个数和共有单词的位置信息的相似度计算方法,充分考虑了老挝语和汉语句子中的词汇互译信息,计算它们之间的相似概率,从老挝语一汉语、汉语一老挝语两个方向上考虑词对的互译信息,并扩大窗口,避免了由于特征词位置导致的精度丢失。根据特征词对之间的相似概率和构建的老一汉双语相似词典,计算老一汉双语句子相似度值,改进了基于词汇的方法,需要大规模的翻译词典,没有通过翻译来计算两种语言的句子相似度,避免了由于翻译的语料规模和质量导致的精度丢失。
此方法用来最终识别相似度较高的老一汉双语平行句对,依据相似度对源句子和目标句子进行对齐,能够简化句子对齐时的流程,从而提高句子对齐的效率,在老一汉双语平行语料库的建设中使用。
4 结语
本文提出的基于互译特征词对匹配,并结合构建的老一汉双语相似词典的句子相似度计算方法,一定意义上提高了跨语言相似度计算的准确率。但是由于特征词对的匹配并不能完全反映一个句子所包含的所有语义信息,只是在句子的特征结构方面进行计算,没有考虑词语蕴含的语义信息,对于同义词以及一词多义情况计算不佳,使得相似度计算的准确率不高。所以为了达到更好的效果,将对本相似度计算方法进行完善和扩充,加入一些词性和语义信息,可以把更能代表一个句子的词赋予更高的权重,引入到相似度计算公式中,还需要进一步研究老挝语句子的语法和语义的表示方式,随着研究的深入,肯定还能发掘更多完善算法模型和提高计算精度的方法。
注:本文通讯作者为周兰江。
参考文献
[1]邸书灵,刘晓飞,李欢.基于分词的语句相似度计算的改进[J]石家庄铁道大学学报(自然科学版),2011,24(4):94-97.
DI Shuling, LIU Xiaofei, LI Huan. Improvement of sentencesimilaritv calculation based on participle [J]. Journal of Shijia-zhuang Railway University (Natural science edition), 2011. 24(4):94-97.
[2]刘宏哲.一种基于本体的句子相似度计算方法[J]计算机科学,2013(1):251-256.
LIU Hongzhe. An ontology - based sentence similarity calcula-tion method[J]. Computer science. 2013(1): 251-256.
[3]邓涵,朱新华,李奇,等,基于句法结构与修饰词的句子相似度计算[J],计算机工程,2017(9):240-244.
DENG Han. ZHU Xinhua, LI Qi,et al.Calculation of sen-tence similaritv based on syntactic structure and modifiers [J].Computer engineering, 2017(9):240-244.
[4]蓝雁玲,陈建超.基于词性及词性依存的句子结构相似度计算 [J]。计算机工程,2011( 10):47-49.
LAN Yanling, CHEN Jianchao. Sentence structure similaritycalculation based on part of speech and part of speech depen-dence [J]. Computer engineering, 2011( lO): 47-49.
[5]张艳杰,邵雄凯,刘建舟.一种基于语义与结构的句子相似度计算方法J].湖北工业大学学报,2015(5):82-85.
ZHANG Yanjie. SHAO Xiongkai, LIU Jianzhou.A method forcalculating sentence similarity based on semantics and struc-ture [J]. Journal of Huhei University of Technology. 2015(5):82-85.
[6]陈丽莎.白动问答系统中基于WordNet的句子相似度计算研究与实现[D],广州:华南理工大学,2014. CHEN Lisha. Research and implementation of sentence similar-ity computation based on WordNet in automatic question andanswer svstem [Dl. Guangzhou: South China University ofTechnology, 2014.
[7]李春梅,徐庆生,基于多特征的汉语句子相似度计算模型的研究[J].计算机技术与发展,2014(6):136-139.
LI Chunmei, XU Qingsheng. Research on Chinese sentencesimilarity computation model based on multi-features [J]. Com-puter technology and development, 2014(6): 136-139.
[8]王全民,曹建奇,王莉.一种基于多特征混合句子相似度计算的改进[J].计算机与现代化,2015(7):31-33.
WANG Q M, CAO J Q, WANG L.Improvement of sentencesimilarity computation based on multi-feature mixture[J].Com-puter and modernization. 2015(7):31-33.
[9]李家南.IT领域问答系统的研究与实现[D].广州:华南理T大学,2016.
LI Jianan. Research and implementation of QA system in ITfield [D]. Guangzhou: South China University of Technology,2016.
[10] PEI Jing, BAO Hong. Application of Chinese sentence similar-ity computation in FAQ [J]. Computer engineering, 2009, 35(17):46-48.
[11] ALIGULIYEV R M.A new sentence similarity measure andsentence hased extractive technique for automatic text summa-rization [J]. Expert systems with applications, 2009. 36(4):7764-7772.
作者简介:李思卓(1994-),女,陕西西安人,硕士,研究方向为自然语言处理。
周兰江(1964-),云南玉溪人,副教授,研究方向为自然语言处理、机器翻译、信息检索。
