分布式计算在券商营销推广活动中的应用
2019-04-26俞枫张忍郑爽
俞枫, 张忍, 郑爽
(国泰君安证券股份有限公司, 上海 200120)
0 引言
随着移动互联网技术的普遍应用, 券商行业开发客户从传统的线下营销推广模式逐步转变为线下、线上并行的营销推广模式。线上营销推广活动具有用户群体大、时效性强、规则变动大等特点, 保证并提升用户的参与体验、减少或消除营销推广活动对股票交易业务的影响、减少营销推广活动开发周期、变更周期是进行日常性、大规模线上营销推广活动需要解决的根本技术问题。
目前券商行业普遍采用的营销推广活动后台框架是恒生统一金融接入系统(UFX)服务节点和Oracle关系型数据库, 该框架存在以下弊端。
1)当参与营销推广活动的用户数目激增时将过度占用统一金融总线(目前券商业务大部分通过该消息总线接入和传递)的消息通道资源,此时股票交易客户的交易事件和营销推广活动参与客户的参与事件都会出现响应超时现象,影响用户体验乃至给客户造成经济损失。
2)采用传统的Oracle关系型数据库,不同的营销推广活动因需要记录的用户参与状态数据范式不同,需要预先定义不同的用户参与状态记录表,并实现与之相对应的数据库CRUD操作,活动难以实现动态、自由定义,拉长活动的开发、变更周期。采用传统的Oracle关系型数据库,需要额外的分库分表中间件(如Mycat)以水平扩展数据容量,当用户数目激增时难以快速扩展数据库节点。
本文采用分布式流处理架构[1],如图1所示。
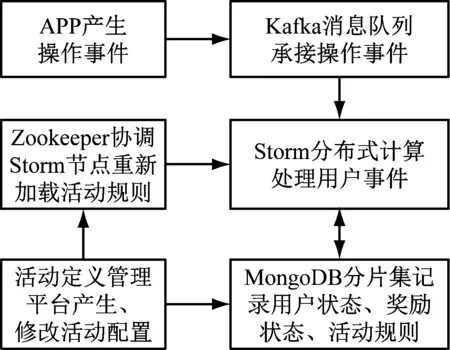
图1 系统架构图
消息队列中间件Kafka接收线上营销推广活动中各种渠道来源的用户操作事件,Storm分布式计算框架并行处理用户操作事件,MongoDB存储活动规则,记录用户的活动参与状态、用户的奖励状态、事件处理状态,Zookeeper分布式应用协调服务触发Storm节点动态加载活动规则。
采用该技术方案具有支持并发用户数大、事件流并发处理能力强、 营销推广活动可以模板化配置并动态生效、 不同活动用户记录可以同一个数据表记录且无须预先定义字段、基本不占用统一金融总线资源、具备消息缓冲能力、无须额外中间件便可分库分表等特性。
Apache Storm是目前主流的流式分布式计算框架之一,它是由Twitter开发,阿里巴巴发展的开源软件。Storm可以在工作进程、线程、任务3个层级进行扩展以提升并行计算能力,同时Storm还具有高可用、高容错特性以及完整的消息处理确认机制[2][3]。
Apache Kafka是目前主流的高吞吐量分布式发布订阅消息系统之一,他是由LinkedIn开发的开源软件。Kafka具有轻量级、分布式、可分区、分区多备份等技术特点,具有高可用、高可靠、高吞吐量等性能特点[4][5]。
MongoDB是基于分布式文件系统的非关系型数据库。MongoDB是基于文档存储的,文档的数据结构非常松散,类似于json数据格式的bjson格式。在使用MongoDB时无须预定义表字段,表里面的每条记录可以具有不同的数据字段[6][7]。MongoDB分片副本集是高可用、易扩展的分库分表数据库方案,提升数据存储能力及数据操作性能,同时不需要使用额外的数据库中间件][8][9]。
Apache ZooKeeper是一个分布式的分布式应用程序协调服务,是Hadoop大数据生态圈的基础设施之一。它可以在分布式计算框架Storm中作为计算节点的配置信息同步协调者[10]。
1 营销推广活动的特征抽取及规则原型的定义
1.1 规则原型提取
通过对常见的营销推广活动的规则进行分析,归纳总结出简单营销推广活动通用性强的规则,比如以下几个规则:
1)首次做某事送奖励,比如首次注册APP事件、首次上传头像事件等。
2)累计做某个动作达到N次即发放奖励,比如累计签到N天事件等。
3)每周期做某事,送奖励,比如每天签到事件等。
4)某指标在某范围内送奖励,比如账户资产超过某值事件,充值超过某值事件。
对简单活动的通用规则抽象是实现营销推广活动模板化配置的前提。规则原型的定义含有原型ID、原型名称、触发事件列表、具体事件处理类、用户状态记录字段定义信息,如表1所示。
表1中具体事件处理类是与触发事件列表无关的处理类,比如每周期做某事的处理类、首次做某事的处理类。触发事件列表包含了可以触发该原型的用户操作事件,比如用户登录APP。用户状态记录字段主要是记录用户发生操作事件后事件的处理结果,比如首次登录APP事件,将记录首次登录APP的时间,送过对应奖励的标志。实际开发过程中只有具体事件处理类是需要开发的。记录字段、规则入参、关联动作等都是通过配置实现。具体事件处理类通过抽象可以高度复用,比如处理首次事件的处理类,可以复用于首次注册APP、首次设置昵称、首次上传头像等规则原型,极大地减少了代码开发量、缩短了上线周期。规则原型配置可以在多个营销推广活动中复用,比如首次登录APP事件可以在多个APP促活活动中重复使用。
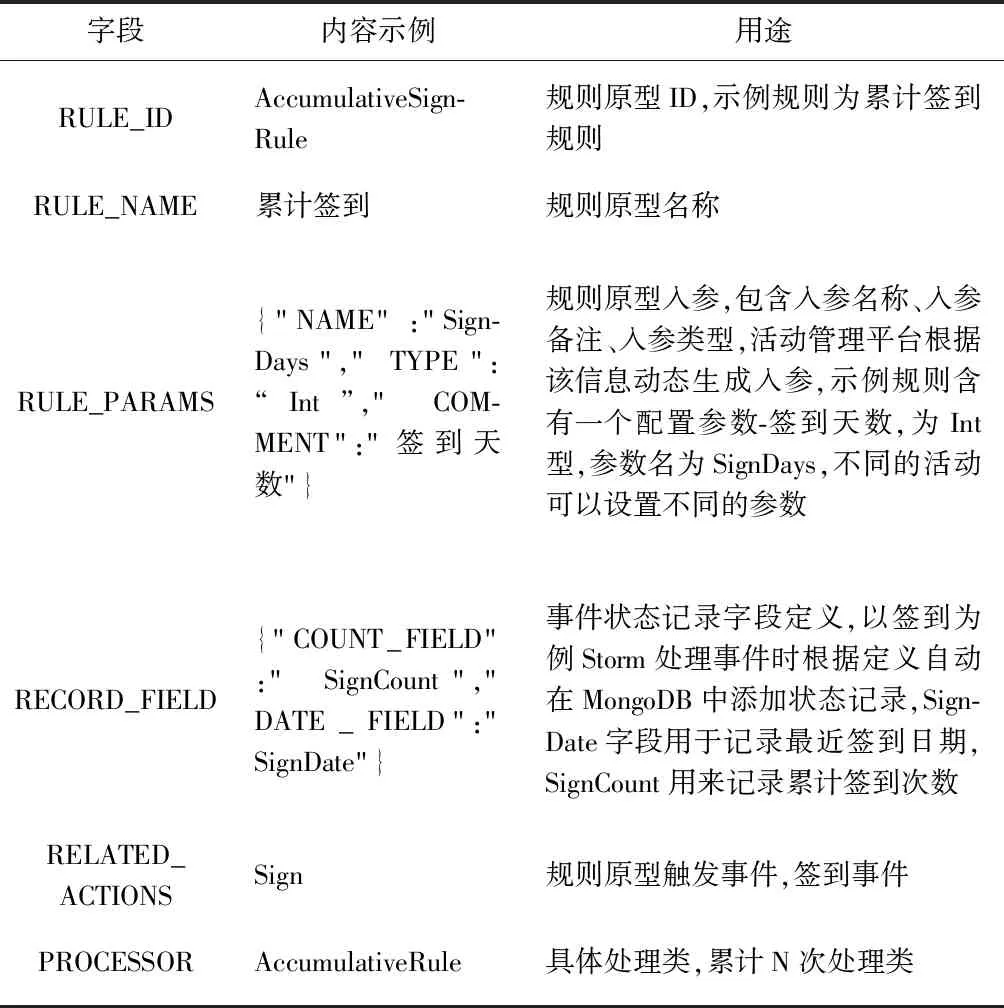
表1 规则原型表
1.2 规则原型实例化快速构建活动规则
选择营销推广活动所需要的规则原型,快速构建活动处理规则,比如APP签到活动,可以选择每次签到规则原型、累计签到规则原型、连续签到规则原型,设置每个实例规则的奖励条件(如累计签到多少天)和奖励类型、数目,设置活动开始、结束日期、面向的客户范围等必要信息就能产生一个活动完整的规则配置。规则具体处理类、规则原型高度复用可以减少上线新营销活动所需的开发测试时间,同时活动规则参数、活动规则奖励支持动态自由配置。
2 技术架构、组件详解
本系统的组件如图1所示,用户参与事件流转如图2所示。
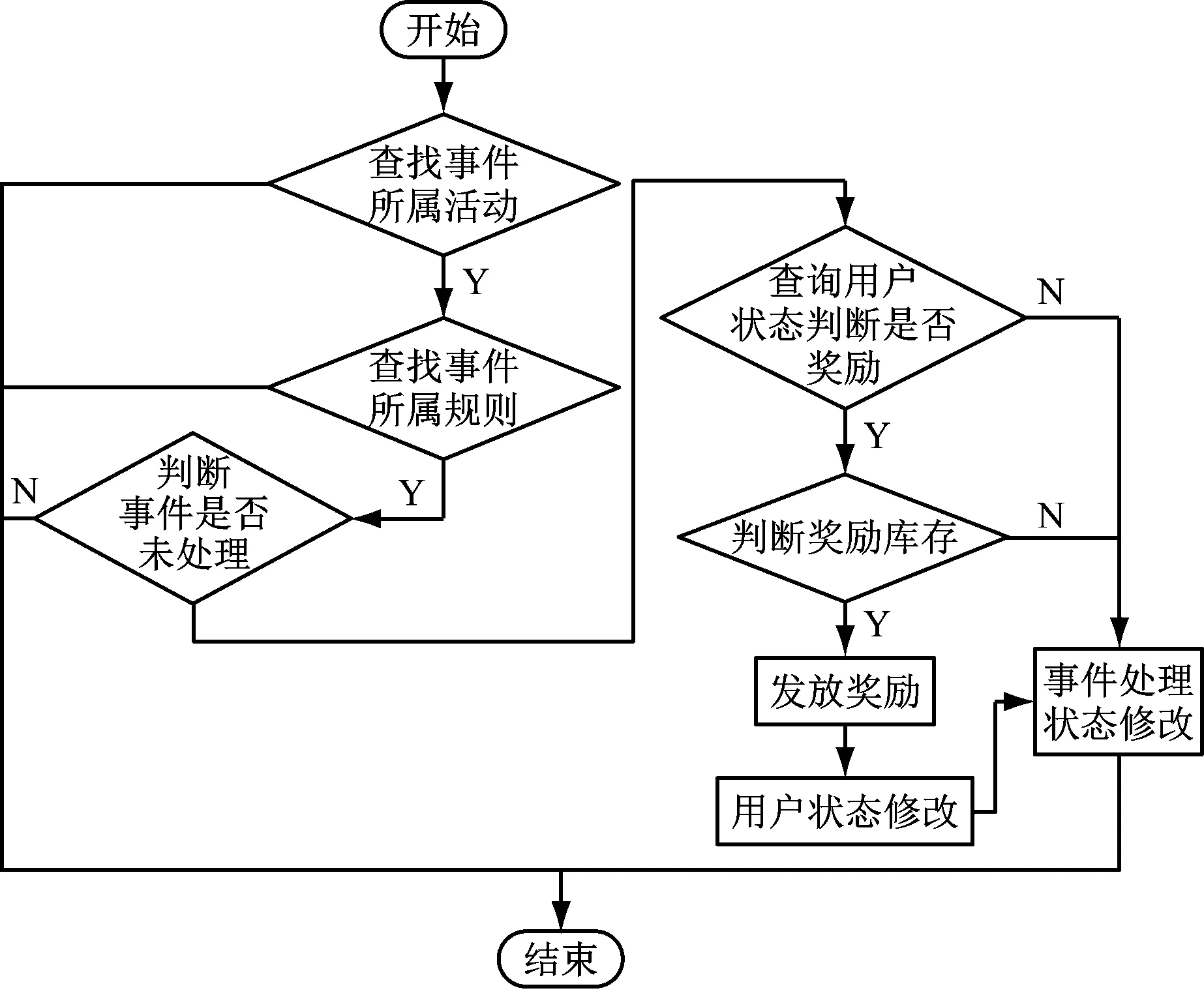
图2 用户事件流转流程图
2.1 MongoDB副本集
MongoDB主要作用是存储规则原型定义、活动规则定义、事件处理状态、用户的活动参与状态、用户奖励数据及发放状态等。如果采用传统的关系型数据库则每次创建新活动时要创建不同的用户参与状态记录表,因为每个活动需要记录的活动参与状态数据字段是不一样的,比如签到活动和新开户用户活动,一个活动需要记录的是签到状态,一个需要记录的新开户状态,两者在表结构上并不兼容。采用MongoDB的优点是MongoDB数据表中的字段无须预先定义,同一个表里可以容纳数据字段完全不同的记录,通过活动ID和用户ID作为MongoDB用户状态表的索引和公共字段,可以快速检索到每个活动下每个用户的参与状态,而用户的参与状态记录字段通过规则配置已经确定,无须再额外定义。为了满足大量线上用户同时参与活动的需求,MongoDB集群采用分片副本集群如图3所示。
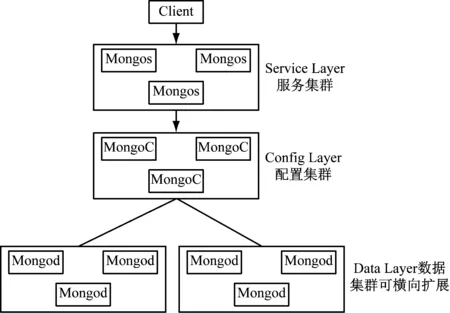
图3 MongoDB分片副本集
分片类似于传统关系型数据库的分库分表,可以提升数据容量,副本集通过数据多节点备份保证数据高可用,并可主从读写分离提升读写性能。MongoS节点主要负责数据路由,MongoC节点主要负责维持数据分片信息,MongoD节点主要负责存储数据,客户端Client通过访问MongoS从MongoC中获取数据所在数据副本集并从对应的MongoD数据副本集中获取、存储数据。以活动ID、用户ID作为数据分片依据,将用户参与状态、用户奖励数据分散到各数据副本集中,可以控制每个数据副本集的数据量,提高系统的数据容量、数据读写速度,以满足互联网化的应用需求。
2.2 Kafka消息队列
Kafka消息通道主要作用是采用异步消息发送模式将营销推广活动的用户操作事件快速从统一金融总线剥离,减少营销活动对统一金融总线资源的占用,使其更专注于证券交易核心业务。利用Kafka的高吞吐量、高可用特性以满足互联网环境下大量用户同时产生的操作事件消息的及时投递。对各种触发事件采用统一的Kafka通道和消息格式可以减少各种操作事件消息的对接时间,便于各类型消息的统一校验和备份。如图4所示。
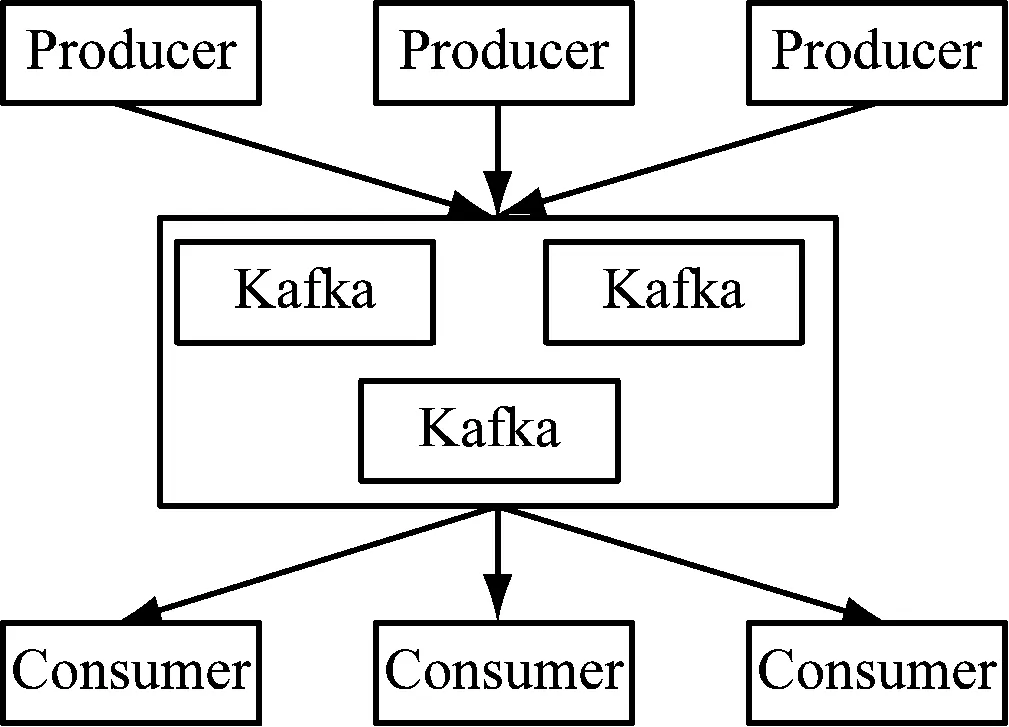
图4 Kafka分布式消息队列
Kafka Producer 异步发送消息到Kafka 集群,Kafka Consumer(Storm Spout)从Kafka消费消息。Producer和Consumer互不干扰,Consumer未能及时消费消息并不会阻塞Producer发送消息,Kafka会将未消费的消息存储到文件系统,Consumer按自己的消费能力从Kafka拉取消息,所以Kafka在本系统中还起到访问压力缓冲的功能。目前对接的事件包含注册、开户、登录、签到、邀请、点击页面、账户操作等事件。
2.3 Storm分布式计算框架
Storm流式分布式计算框架分为三级处理节点如图5,第1级 KafkaSpout按分区从Kafka获取数据。第 2级 MsgParseBolt进行Kafka消息格式校验、并转换为特定数据格式。第 3级 MsgProcessBolt匹配活动ID和触发事件,找出对应的处理规则,判断是否满足规则,记录事件处理状态和用户参与状态并决定是否产生奖励流水。MsgParseBolt转换消息格式后会将属于同一个用户的操作事件发送到同一个ProcessBolt 进行串行处理,这样可以减少同一用户数据并发操作时的锁等待时间,同时也可避免少量客户通过未知方式攻击系统时造成系统完全不可用的可能性,如图5客户U1、U2的操作事件EA、EB达到MsgProcessBolt时同一个客户的事件由同一个MsgProcessBolt处理。MsgProcessBolt 处理完用户操作事件会发确认消息给Spout,当Spout未确认处理的用户操作事件超过一定数目时,Spout会停止从Kafka拉取数据,避免Storm内部各节点消息堆积造成内存占用过多等问题。
Storm的三级处理节点可以按照需要独立灵活配置所需节点数目,可以在进程、线程、任务等多个层级进行配置,可根据用户流量快速进行系统扩容以满足互联网环境下大量用户参与活动的需要。
2.4 Zookeeper分布式节点同步服务
Zookeeper主要作用是协调Storm分布式计算节点间的数据同步。活动配置信息是Storm拓扑启动时加载到内存的,当有活动配置变更时,通过Zookeeper告知Storm各节点重新加载活动配置,保证不用停止Storm计算拓扑也可以重新加载规则并保证各计算节点活动配置一致。如图5所示。
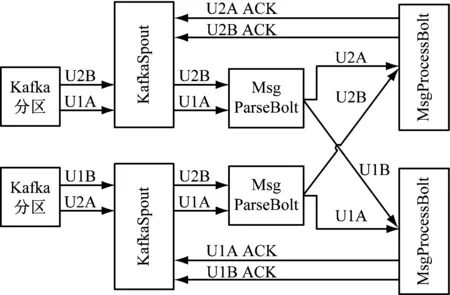
图5 分布式计算框架Storm
3 系统性能测试
3.1 Kafka消息接收能力测试
对Kafka性能测试结果,如表2所示。
可以发现采用异步模式能提升Kafka的消息接收能力,本文采用了该种模式,各种来源的用户操作事件统一成Kafka消息格式并异步发送到多分区的Kafka消息队列上由Storm统一消费并处理。采用多分区是为了提升Storm Spout节点的并发处理能力,Storm Spout的数目和Kafka分区的数目保持一致时能使Spout的性能最优,即不会有Storm Spout空闲也不会有Storm Spout要处理多个分区,每个Storm Spout专注处理一个分区。消息队列3个分区可以由3个Storm Spout并发处理消息,增加Storm第1级的并发处理能力。

表2 Kafka性能测试
3.2 MongoDB 性能测试
MongoDB性能测试结果,如表3所示。

表3 MongoDB数据库性能测试
通过上述测试可以发现分片副本集INSERT,UPDATE性能上优于普通副本集,因此本文采用的时MongoDB分片副本集。
3.3 Storm性能测试
测试不同Storm 节点下的Storm的消息处理能力。如表4所示。

表4 Storm性能测试
目前而言,本系统的峰值压力每秒1000个用户操作事件,通过测试可以发现目前系统架构能够承受该峰值压力。
3.4 传统架构和分布式流计算架构性能比较
传统架构和分布式流计算架构的性能对比(一个用户操作事件如图2触发1次消息处理状态查询、1次用户状态查询、1次用户状态修改、1次消息处理状态修改,1次奖励库存查询,1次奖励发放流水新增共6个数据库操作),如表5所示。

表5 架构性能测试
可以得出结论分布式流计算架构对总线通道的占用时间远小于传统的金融总线服务节点+Oracle架构的占用时间,极大地减少了营销推广活动对核心交易业务产生影响的可能性。在事件处理性能上,分布式流计算架构每秒处理用户操作事件数显著高于传统架构,且当用户操作事件数高于分布式流计算架构处理能力时,Kafka可以起到消息缓冲作用,操作事件并不会堆积在金融总线队列上,而使用金融总线服务节点是没有缓冲机制的,超过处理能力将导致事件堆积在金融总线队列上,可能影响正常交易。
4 总结
本文通过归纳总结一般营销推广活动常见的用户事件类型,演化出通用性强的活动规则原型,并基于MongoDB数据表无模式的特点形成可以动态配置无须预定义用户参与状态记录表结构的活动规则。通过使用Kafka异步多分区模式承接营销活动中大量用户同时产生的操作事件并起到缓冲作用,通过使用分布式Storm计算框架和MongoDB 分片副本集提升实时流数据处理能力,并可根据需要快速水平扩展计算能力,通过Zookeeper协调Storm分布式计算节点进行活动配置同步,实现活动配置的动态设置和动态生效并保证各节点活动配置一致,经性能测试本系统能够承受目前券商公司线上营销推广活动的用户并发操作压力。
