融合SURF与sEMG特征的手语识别研究
2019-04-26林亚飞曾晓勤
林亚飞,曾晓勤
(河海大学 计算机与信息学院,南京 211100)
0 引言
作为聋哑人群体的共同语言,手语是聋哑人之间以及聋哑人与健全人之间日常沟通交流与表达感情的重要方式,手语对于聋哑人而言在生活中、学习上以及工作中尤为重要,但由于手语不是一门大众化的语言,在听觉正常的人中只有极少数人会使用或者理解手语,导致聋哑人与外界沟通起来尤为困难。此外,近年来人机交互领域中手势识别的应用也越来越多,新一代人机交互技术实现了交互过程中“以人为中心”这一理念,用户可以通过手势、语音、表情、肢体动作等操作计算机,这样的交互过程更加符合人的交流习惯。因此本文对中国静态手势语识别进行了深入的研究。
中国科技大学的研究者提取手部的运动轨迹特征及手型特征,引入区分性字典学习和稀疏表示的识别算法对孤立词手语进行识别,对实验中采集的72个孤立手语词识别的平均正确率为98.61%; Ayman等人提出了主成分分析法结合定向梯度直方图对手语进行识别的方法,对30个阿拉伯字母的识别正确率达到了99.2%;Giulio等人将Kinect和LeapMotion相结合共同获取手部数据信息并将提取得到的手部信息特征进行融合后由SVM分类器分类识别;中国传媒大学的研究者通过Kinect获取手部骨关节点信息来识别静态的手势和动态手语的手部位置,提取其方向梯度直方图特征并结合黄金分割算法进行识别。
本文通过Kinect 2.0设备采集静态手语对应的深度图像及彩色图像,通过阈值分割算法提取手部区域图像并对其进行形态学开操作处理,从得到的仅包含手部区域在内的图像中提取SURF特征后通过K-means++算法聚类构造视觉词汇字典,继而用视觉词汇在图像中的出现频率来表示图像局部特征所对应的数值向量,将图像的局部特征与MYO臂环采集得到的肌电信号特征相融合后得到的特征向量通过SVM分类器进行学习,并通过学习得到的分类器对静态手势语进行分类识别。实验采用五倍交叉验证的方法将5个数据集分为测试集和训练集进行训练识别,对每一个数据集进行识别的正确率最高可达97.28%,本文所提出的总体架构图,如图1所示。
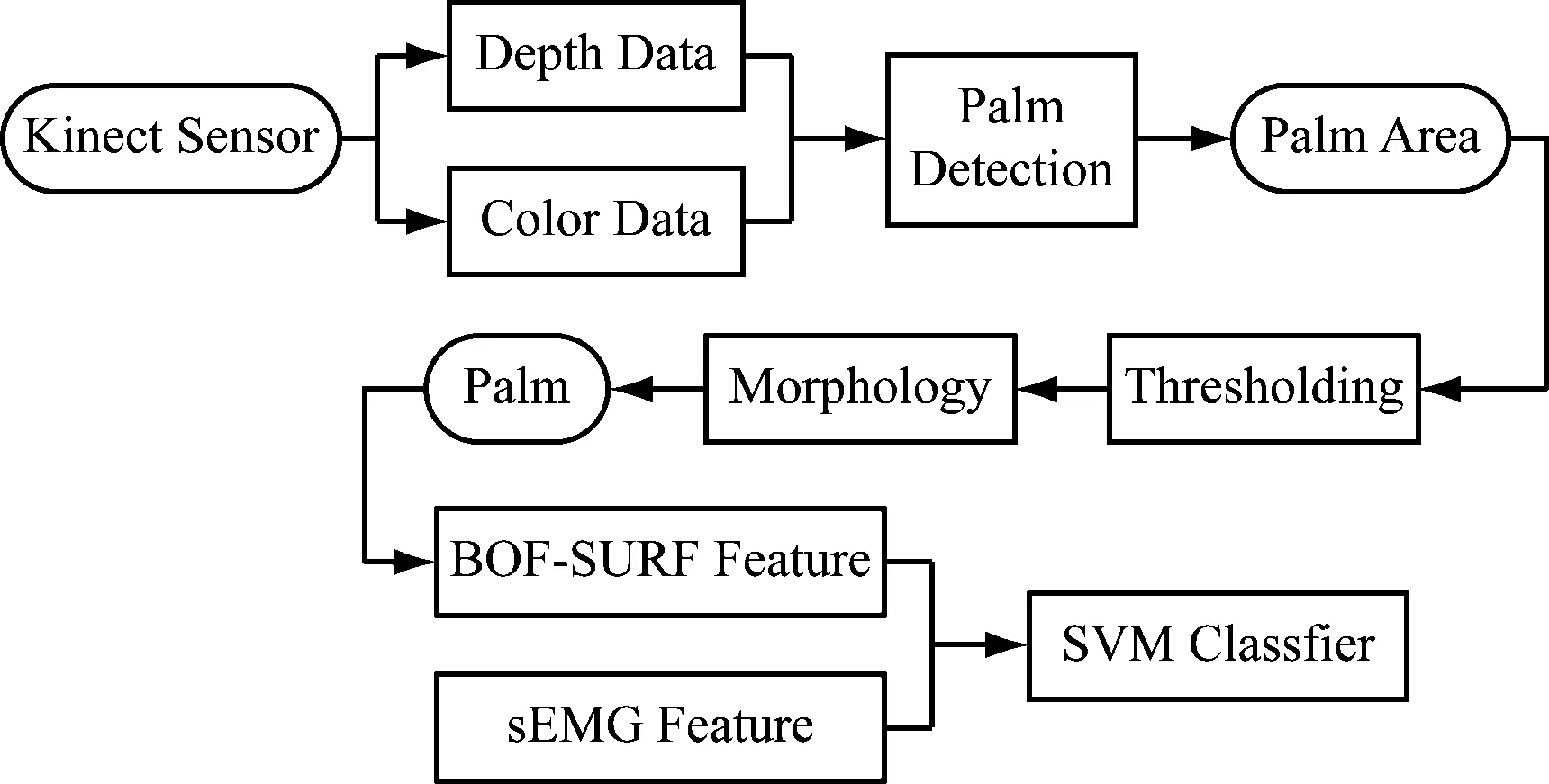
图1 系统总体架构框图
2 SURF特征提取及其BOF表示
2.1 静态手语像中手部区域的分割
主要的手部分割方法有两种,一种是基于颜色分割,通过对颜色变换并提取与肤色相近的区域来获得手掌的部位,另一种是通过深度分割,通过深度阈值等方法来实现提取具有特定深度的区域,当只有人的手掌在这一区域时,便可以应用基于深度的分割。结合两种分割的有点,本文提出了彩色图像和深度图像相结合的手部分割算法:(1)通过kinect获取到包含人体及周围环境在内的彩色图像及深度图像;(2)将深度图像帧映射到彩色空间;(3)选取落在彩色图像上的点并对复杂的前景和背景进行阈值分割,从而得到仅包含手部区域在内的彩色图像。
2.2 SURF特征的提取及BOF表示
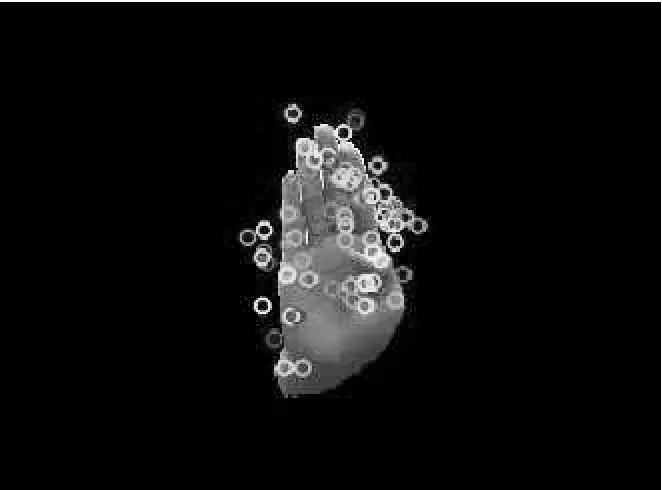
本文采用SURF特征提取算法对静态手语图像进行特征提取,其特征提取结果如图3所示。
BOF(Bag Of Features)模型仿照文本检索领域的Bag-of-Words方法,将每幅图像描述为一个由局部区域/关键点特征构成的无序集合,通过聚类算法对局部特征进行聚类操作,从而得到局部特征的多个聚类中心,每一个聚类中心即可作为词袋模型中的一个视觉词汇(Visual Word),所有视觉词汇共同构成词袋模型中的视觉词典。通过计算图像的局部特征到各个聚类中心得距离可以将图像的局部特征映射至视觉词典中的某个视觉词汇上。而后通过视觉词汇在图像中出现的频率来表征图像所具有的局部特征,通过统计不同视觉单词在图像中的出现频率可以得到能够描述该图像的视觉向量直方图,即Bag-of-Features。SURF-BOF模型构造过程如图4所示。
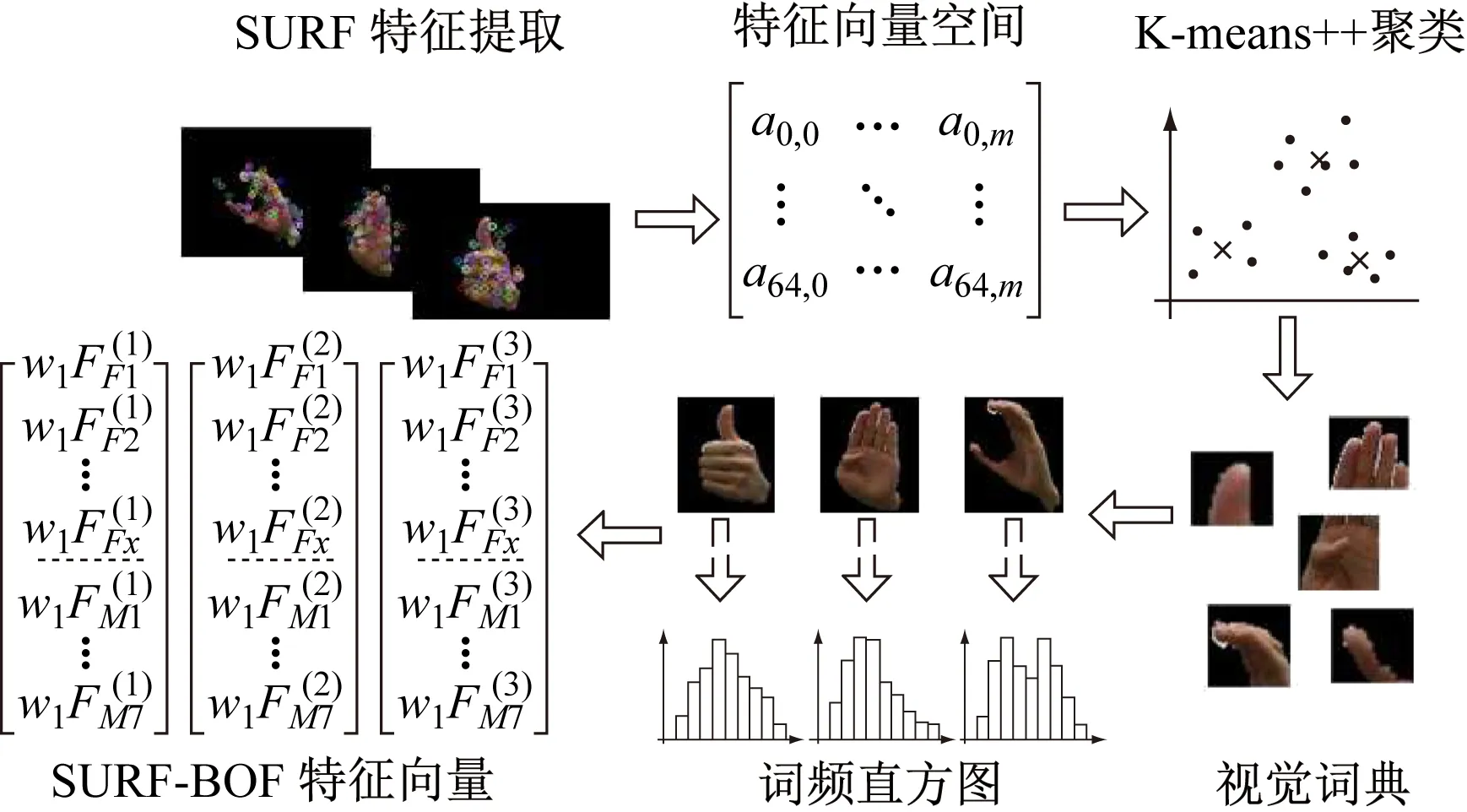
图4 SURF-BOW模型构造流程图
3 sEMG特征提取及与SURF-BOF特征的融合
3.1 表面肌电信号特征提取
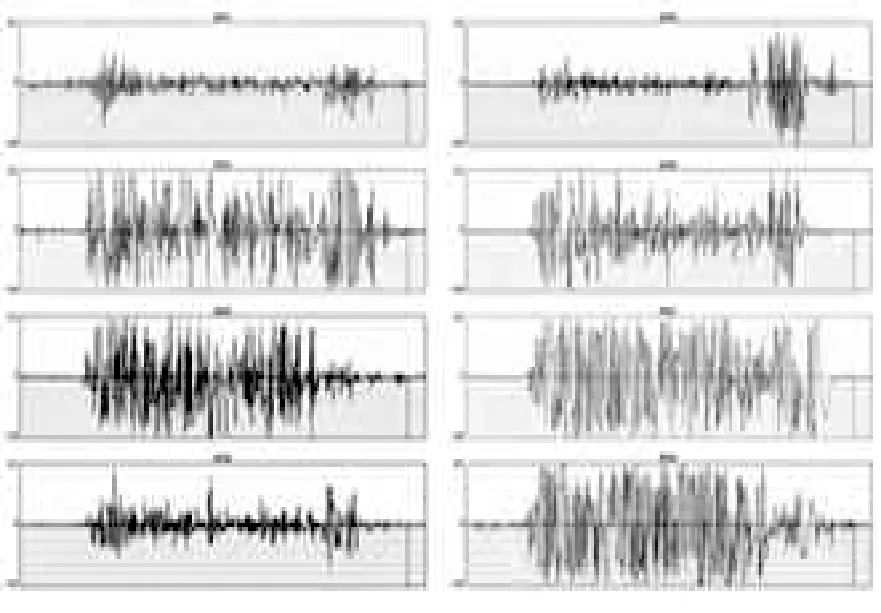
本文中使用MYO臂环通过8片肌电传感器和惯性测量单元可以测量被佩戴者的手臂肌肉活动状态并采集sEMG、ACC、Gyo等原始数据,同时将这些数据通过蓝牙传输给其他电子设备用于交互控制。不同的人做同一动作或者同一人做不同动作,MYO臂环的八片传感器采集到的表面肌电信号信息均会呈现出或多或少的差异,不同人做握拳动作时得到的表面肌电信号波形图,如图5所示。
在数据采集过程中,每个受试者需要进行连续重复的静态手语动作采集,不同静态手语动作之间会有3-5s的休息,而后对同一连续动作采用滑动平均能量的方法提取其有效的手势活动段用于后续研究。在手势动作执行过程中 ,传感器检测到的sEMG信号称为活动段,该信号可以作为受试者所做手势动作的sEMG信号样本。表面肌电信号的采集及特征提取过程如图6所示。

图6 MYO臂环采集SEMG信号及特征提取流程
3.2 图像特征与表面肌电信号特征融合
表肌电信号表征手势语的全局特征,BOF-SURF特征表示手势语的局部特征,两种特征对手势语图像的表征比重有所不同,所以将两种特征配以不同的权值进行线性融合得到最终的特征向量I,融合特征的特征向量表示为:
I=[w1*Fbow-surf+w2*FsEmq]
(1)
其中,w1和w2分别代表BOF-SURF特征及sEMG特征对应的权值,并满足w1+w2=1,其实际值通过实验迭代至正确率最高时得到。
4 手语识别实验结果及分析
4.1 样本数据库及实验数据集
本文所需的样本库由五个受试者佩戴MYO臂环在Kinect摄像头的可视范围内录入的手势语样本图像组成。受试者在距离Kinect设备1.5米,2米及2.5米的地方分别做30个中国静态手势语的手势,录入每一个字母手势语手形从中间偏左到中间偏右45度之间所有位置的手势语图像。将得到图像分为5组通过五倍交叉验证法进行实验,最终得到每一组数据集作为测试集时的识别正确率可达到97%左右。
4.2 对比实验结果分析及总结
本文算法与其他算法识别率的比较。该实验从样本库中共选取出18 750幅图像,将其平均分为五组,通过五倍交叉验证的方法分别对每一组样本集进行识别正确率检测。该实验分别通过SURF+SVM,BOF-SURF+SVM、sEMG+BOF-SURF+SVM三种试验方法来验证本文提出的算法的可行性,其识别正确率如表1所示。

表1 不同手语识别方法识别正确率的比较
从5个数据集中分别选出25张字母A到G的手语图像作为测试集由3种不同的识别方法识别得到的准确率如表2所示。
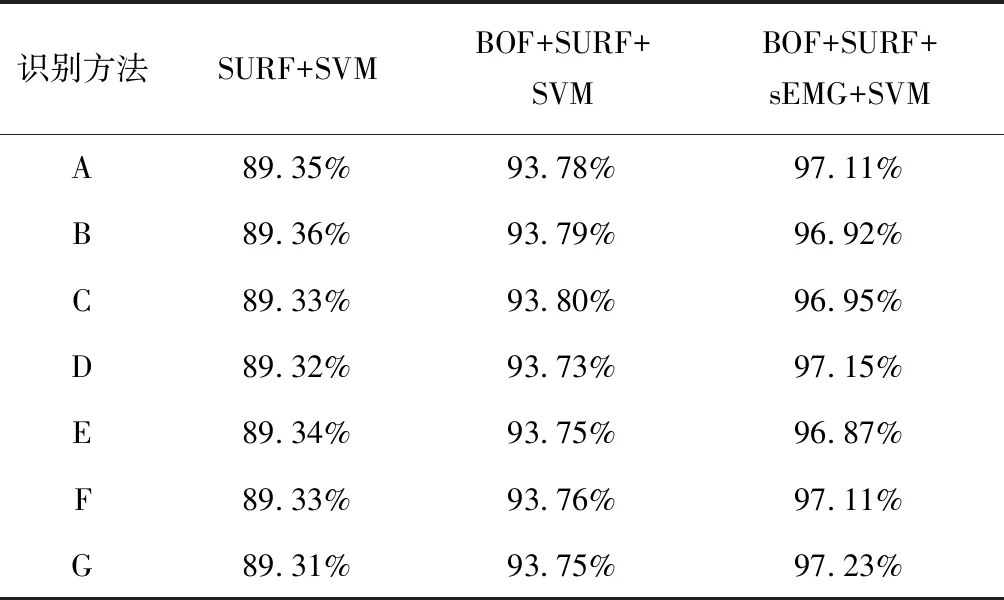
表2 手语字母识别正确率比较
5 总结
本文提出一种将从图像中提取出的SURF特征与人体表面肌电信号特征(sEMG)相融合来对中国静态手语字母进行识别的方法,将从图像中直接提取得到的SURF特征经由词袋模型进行二次表征能够使得对整个样本库而言,词袋模型中的视觉词汇表征的图像特征更加容易区分从而在一定程度上提高识别的准确率,将人体表面肌电信号特征单独用于手语识别时因为个体差异的存在会使得识别的结果较不稳定,但与SURF特征相结合后,并将人体表面肌电信号特征的影响因子控制在 一定范围内能够有效的提升识别的准确率并能显著改善因个体差异而导致的不稳定性。
后续将进一步改进特征融合的方法,尝试将更多的特征进行融合,提取人在做手语动作时的多重特征,从不同方面来表示手语动作从而提高算法的鲁棒性及识别的正确率。继静态手语研究之后考虑将该方法应用于动态手语识别中,对由视频表示的孤立词语进行识别。目前的研究所用的样本库均是借助现有设备自行采集的,国际上并未有标准的手语样本库,若将来公布标准手语库后,考虑将现有的样本库通过一定的编码转化方式与标准手语库进行对齐从而使得该识别方法具有一定的通用性。
