数据挖掘技术在政府项目资金监管的应用
2019-04-26李沁颖李智芬龙雨婷
文/李沁颖 李智芬 龙雨婷
1 引言
1.1 背景
国家经济实力是国家强大的重要依靠之一,其主要来源是依靠纳税人无偿上缴的资金,政府使用这些资金进行各项工作项目的投资开发,保证了资金的利润和国家建设的完善。
随着社会环境的稳定和社会经济实力的发展,政府越发注注重保护财政资金安全,不断本着为人民服务的宗旨,使得纳税人缴纳的资金可以得到保护。另外一方面,随着互联网的广泛应用和信息化办公的发展,政府也投入了大量资金用于信息化管理,这不仅是加强资金使用管理的重要手段,也是保证中国廉政建设,改善社会环境以及保障民生质量的重要措施。
1.2 存在的问题
如今,政府资金监管中存在诸多不良现象,如:擅自更改申请项目;挪用项目资金;多个单位套用项目资金等。
现有的人工监管手段单一,对于每一类型的项目申请没有统一规范的衡量标准,使得资金审批时效性差。在政府的职能分工下资金监管工作主要是由财政、审计部门负责。各个单位大部分更加注重项目资金的获取,反而忽略了一些资金的回报率。
2 数据挖掘技术在政府项目资金监管关键问题研究
2.1 项目资金监管数据挖掘框架
关于项目资金所存在的现有问题,如何进行资金监管是需要考虑的问题。对项目资金监管主要是考虑单位内部和各单位之间两个方面。
首先,项目资金所涉及的数据库在格式、内容等方面不同于一般类型的数据库,我们要先对项目之间的相似程度进行判断,根据每一类型项目所具有的共性进行分类,再对每一类型的项目提取其中的主要影响因素,作为之后项目资金预测和项目比对的主要衡量标准。
对于单位内部主要对其申请的项目以及申请的项目资金进行监督,防止出现重复申请项目或申请项目资金超标的现象。对于新申请的项目需要和以往本单位申请的项目进行比对,防止出现完全一致或相似度极高的项目。在比对项目内容之后,需要对项目申请资金进行核实,首先判断该项目的类型,再根据之前对每一类型的项目资金预测进行比对,如若超出资金预测区间则提出预警。
对于各个单位之间,主要考虑合作单位与非合作单位之间的关系。对于那些有合作的单位,要考虑两个单位之间是否存在重复申请,每个单位合作的项目都有各自负责的领域。其次,主要考虑非合作单位之间是否存在申请已审批或其他单位所申请的项目,占用项目资金。
2.2 数据预处理
数据中有项目具体属性表和项目资金属性表。由于数据量较大,因此需要对数据做出一系列的分析和筛选。对于标称数据,通过卡方检验(公式1)来判断两个属性的相关性。对于数值数据,通过皮尔森相关系数(公式2)来判断两个表中是否存在不同属性名的属性,从而对数据进行进一步处理。
公式1
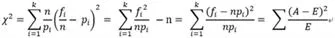
公式2
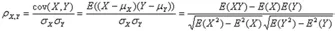
在完成上述所有的数据处理之后,对数据进行规范化整理,很多数据因为不同的内容对结果也会产生不一样的影响。
2.3 数据挖掘技术算法
2.3.1 项目聚类算法
在处理项目数据的过程中,首先要对数据的类别进行一个分析,采用的是遵循同一簇内中对象的相似度较高,而不同簇内中的对象相似度较小的K-means文本聚类算法。
2.3.2 提取项目主要影响因素算法
在数据处理时,需要对每个簇类数据的特征值方法进行重要特征值提取,主要采用的是随机森林方法。特征X是根据随机森林中的决策树计算每一棵树的袋外误差,记为errOOB1。再次随机修改特征值,再次计算袋外误差,记为errOOB2,即可得到特征X的重要性(公式3),对每一棵树的特征值进行计算,再对特征重要性进行排序,逐步剔除不重要的特征值。
公 式3 X的 重 要 性=∑(errOOB2-errOOB1)/N
2.3.3 项目资金预测算法
针对项目的特征选取,可以对每一类型的项目进行资金区间估计。通过从总体中抽取的样本,根据一定的正确度与精确度的要求,构造出适当的区间,以作为总体的分布参数(或参数的函数)的真值所在范围的估计,一般使用的估计某个指定值的区间方法是区间预测。
本文区间预测主要采用的是一元线性回归预测法,先选取一元线性回归模型的变量,再根据最小二乘法来确定自变量X和因变量Y的相关关系,建立X与Y的线性回归方程。一元线性回归方程(公式4)中X代表自变量的取值;Y代表因变量的取值;a、b代表一元线性回归方程的参数。这一直线是利用直线到各点的距离最近来确定的,之后再用这条直线进行预测。
公式4 Y=a+bX
3 总结
当前是大数据盛行的年代,对于成千上万的数据,我们需要充分利用好,不能忽视数据之间的联系,不能忽视数据背后真正的意义所在。本方案针对政府项目资金管理中遇到的问题给出相应解决方案,使得相关管理人员对于数据的管理更加简单的同时,可以帮助他们加强对政府事务的监督。不仅可以通过系统判断之前是否出现过相同或类似项目申请的同时,还可以判定所申项目资金分配是否合理,这加强了对政府部门工作的监督,是具有重大意义的。
