基于多核处理器的雷达多通道处理与优化
2019-04-26窦泽华黎贺
文/窦泽华 黎贺
随着作战场景的日益复杂,以及雷达技术的不断发展,雷达处理通道数越来越多,带宽(采样率)越来越高。以泰勒斯公司的GM200雷达为例,处理通道数大于20个,采样率5MHz,总数据率大于6.4Gbps;另一方面现代信号处理技术快速发展,运算量较传统雷达信号处理技术大幅增加。高数据率、大运算量,对后端处理的需求越来越高。
幸运的是处理器的能力也在不断进步,多核CPU,众核GPU的出现,使得高数据率、大运算量的处理成为可能。以目前市场上的商用服务为例,四颗CPU(E5或E7)架构的服务器,最大有60个计算核。如此多的计算核(并且按照发展趋势CPU核的数量会越来越多),雷达信息处理软件该如何设计,以便充分发挥其计算性能。
本文以实际工程中的某产品为例,探讨多核CPU下的使用方案,并在实施过程中对不必要的多余内存操作进行优化,进一步提高处理通过率。为后续雷达高数据率、大运算量处理提供工程参考。
1 需求分析
1.1 产品介绍
某雷达通道数24个,采样率5MHz,分6根光纤,每个光纤传输4个通道数据,总数据量6.7Gbps。如图1所示。
雷达阵面下行的每个光纤内4个通道的数据打包格式如图2所示。
对信息处理而言,第一级处理的任务是将6根光纤数据接收缓存,并完成光纤之间的数据同步、通道数据拆分(将属于同一个通道的数据整理在一起),以方便后续处理。其对内存数据的频繁操作,使其成为整个信息处理的瓶颈。本文就以通道拆分为例,研究多核CPU的高数据率、大运算量的应用。

图2:光纤内多通道数据格式
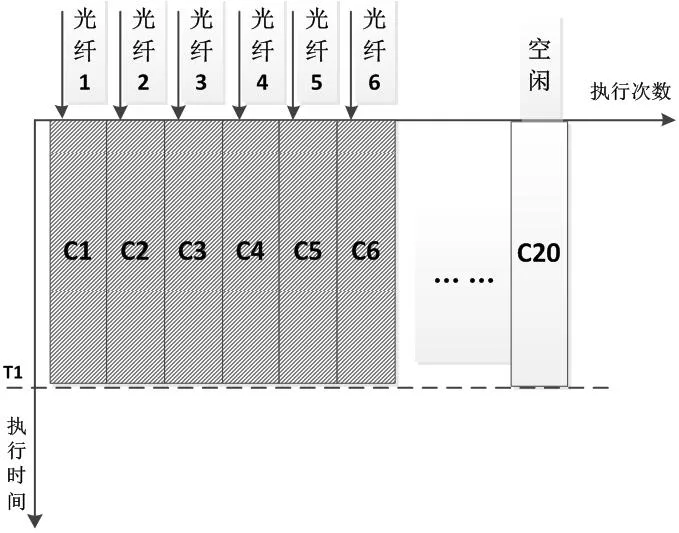
图3:方法(1)处理器执行示意图
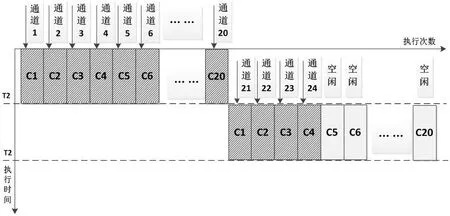
图4:方法(2)处理器执行示意图
1.2 处理平台介绍
本文使用基于2颗Intel志强E5处理器的刀片服务器作为处理平台,其关键参数如下:
(1)计算资源:双路Intel Xeon E5-2648L v3(12核,1.8GHz)
(2)内存资源:板载DDR4 2133MT/s 64GB
该处理平台除去操作系统、中间件驱动使用的4个核,总计有20个核用于计算。
2 方案设计
2.1 方案比较
根据上述需求,通道拆分需要完成6根光纤数据的拆分重组,基于多核处理器有多种并行处理方法:
方法(1)按光纤数量并行,6根光纤并行处理,按照此方法,只有6个核在运行,有14个核处于空闲状态,处理时间T1;
方法(2)按24个通道并行,由于处理平台只有20个计算核,一次并行20个通道,剩下的4个通道还得处理一遍,此时会有16个核处于空闲状态,处理时间2T2;
方法(3)按数据点数并行,一次并行20个点,依次执行,最后一次执行可能不足20个点,处理时间

三种方法的并行示意图如图3、图4、图5所示。
方案(1)和方案(2)并行颗粒度较粗,均会出现多个核的空闲,且每次执行时间较长,没有充分发挥多核的性能。只有在光纤数量、通道数量是核的整数倍时,效率最高,但实际工程中该情况较少;方案(3)并行颗粒度最细,虽然在最后一次执行也存在部分核的空闲,但每次执行只处理1个数据点,执行时间短,整体效率最高。在工程中,也可以考虑舍弃最后小于20(即核的数量)个点的数据,对雷达系统影响甚微。
根据上述分析,多核并行处理,要求并行的颗粒度越细,执行效率越高。
2.2 方案实施
根据上述分析,设计多通道收数预处理的处理流程如下(图6):
(1)6个核并行接收6根光纤的数据;
(2)通道拆分前,完成6根光纤数据的合并;
(3)通道拆分:6根光纤24个通道的数据整理;
(4)通道整理,按需求完成有效通道的整理。
2.3 方案优化
对初步方案的处理性能进行测试,整体数据通过率7.05Gbps。相比输入数据率6.7Gbps,系统余量只有5%,处理能力临界,存在系统饱和的风险,需要对方案进行优化。
对照流程图,步骤(3)的通道拆分经过方案的比较,提升空间不大。初步方案为考虑软件的通用性,在通道拆分前后对数据整理以满足步骤(3)通道拆分接口的简化统一,但其对内存访问频繁,占据一半的处理时间。
按照尽量减少对内存的访问原则,对初步方案作以下优化:2.3.1 多核光纤收数
步骤(1)设计6个核并行接收6根光纤的数据,同样存在并行颗粒度过粗,处理核空闲,效率不高。改进为6根光纤串行收数,每根光纤20个核并行访问内存。
2.3.2 舍弃多光纤数据合并,
步骤(2)的数据合并是为了方便步骤(3)通道拆分的执行。舍弃该步骤后,步骤(3)的通道拆分采用6根光纤串行,依次调用通道拆分函数完成6根光纤的数据拆分。因为通道拆分是按数据点并行,所以6根光纤串行处理,并不会降低效率改造后的流程图
2.3.3 舍弃拆分后的通道整理
通道拆分后,在某些应用模式下,24个通道中的部分数据并不完全需要,或者需要调整数据顺序,方便后续的处理,因此需要对拆分后的24个通道再进行一次整理。
舍弃该步骤后,结合第2.3.2条优化,在每根光纤数据拆分的同时,根据应用模式需求,完成拆分后的数据存放。
最终优化后的处理流程如图7所示。
优化后的整体数据通过率大于14Gbps,比初始方案提高1倍,系统余量50%,大大满足系统需求。可见内存作为处理器的外设存储设备,是多核/众核高性能处理器的性能瓶颈,对处理能力的影响巨大。工程使用过程中,应尽量减少对内存的频繁访问操作。
3 结束语
本文基于24核双CPU处理平台,探讨了雷达多通道的处理方式。
(1)多核并行颗粒度越细,对多核的利用效率越高。对于后续的脉冲压缩、CFAR等需要访问相邻数据的算法,可考虑将数据划分成若干片段进行并行,最大程度接近最优的方案;
(2)内存作为处理器的外设,已成为高性能处理的瓶颈,处理过程中应尽量较少对内存的读写操作,以此提高整体通过率。
基于上述多核多通道并行处理的方法,已经在某软件化雷达项目中成功应用。
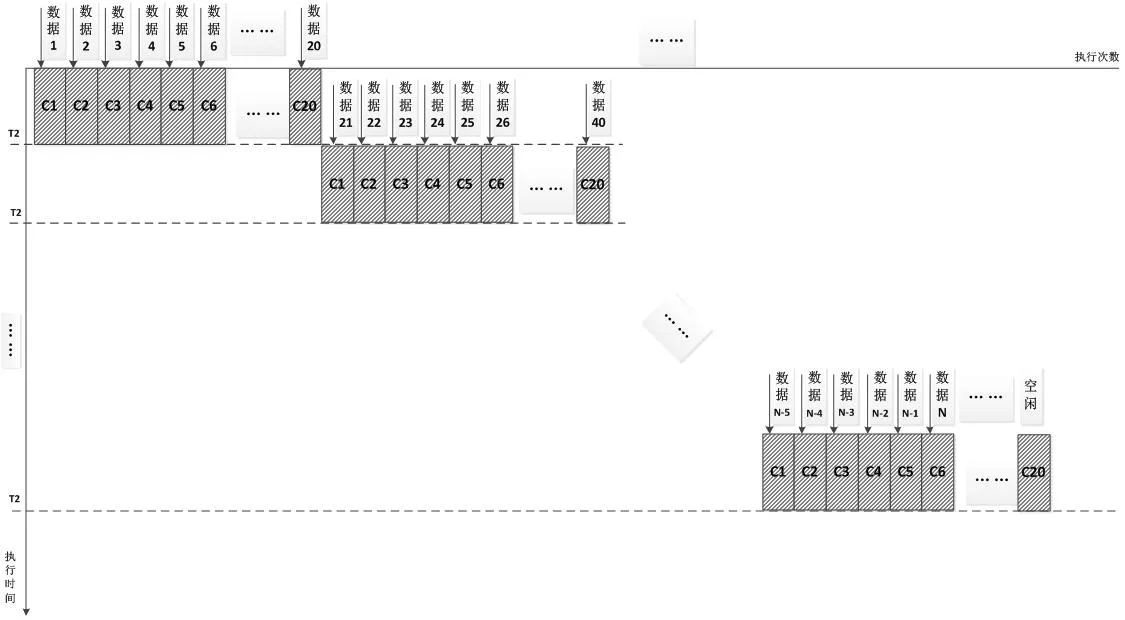
图5:方法(3)处理器执行示意图
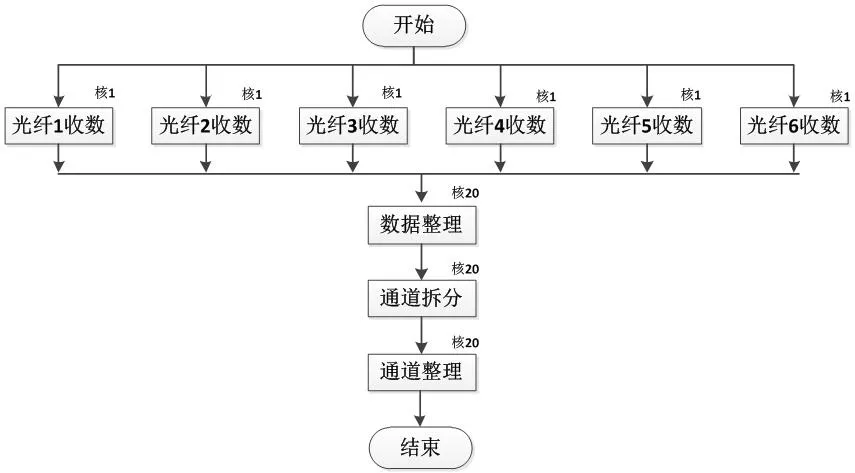
图6:多通道预处理流程图
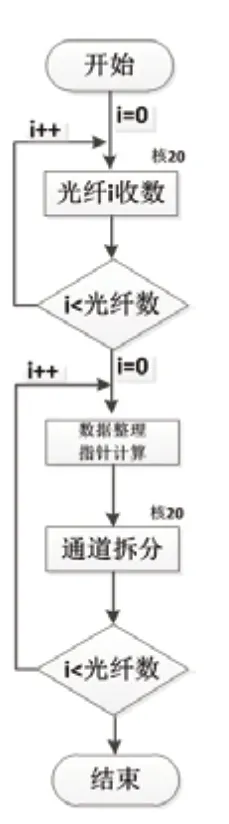
图7:多通道预处理流程图
