基于深度学习的嵌入式离线语音识别系统设计
2019-04-24许业宽
许业宽,黄 鲁
(中国科学技术大学 微电子学院,安徽 合肥 230027)
0 引言
语音识别技术在过去的数十年中得到了长足的发展。现今大多数语音识别都是基于在线云平台[1]和计算机,而应用在嵌入式终端上的离线语音识别技术尚不完善,无法满足移动机器人、声控机械等各类嵌入式终端在离线情况下对语音识别功能的需求。
目前在嵌入式移动平台上实现离线语音识别的方法大致分为三大类:一是利用专用语音识别芯片,一是使用传统的语音识别算法,一是移植讯飞、百度等大公司的语音库。文献[2]采用语音识别芯片内集成语音识别算法,虽然使用时方便快捷,但是具有硬件成本高、识别词简单固定等不足。传统的语音识别算法包括文献[3][4]采用的基于动态时间规整(Dynamic Time Warping,DTW)的算法和文献[5][6][7]采用的基于隐马尔科夫模型(Hidden Markov Model,HMM)的算法等。DTW算法虽然在特定人、少量孤立词识别方面具有较好的效果,但是无法适用非特定人、大量词的识别;基于HMM的算法,则存在识别时间长、识别率偏低的不足。若要移植大公司的离线语音库,则需要大量的存储空间,不适用于存储量有限的嵌入式平台,同时,还需要支付不菲的库使用费,大大增加了软件成本。
本文通过研究设计一种基于深度学习的嵌入式离线语音识别系统,在节省语音识别芯片带来的硬件成本和离线库带来的软件成本的同时,还解决了传统算法存在的只能适用于特定人、识别延迟高、识别率偏低等不足,为嵌入式离线语音识别提供了一种新的方案。
1 系统总体架构
如图1所示,系统主要由麦克风、音频编解码芯片、嵌入式处理器、PC四部分组成。麦克风采用的是型号为MP34DT01TR的MEMS数字麦克风,实现语音信号的录入采集,输出PDM格式的数字音频信号;音频编解码芯片采用的是型号为WM8994ECS的超低功耗保真编解码芯片,用以接收麦克风输出的数字音频信号,并将信号编码处理后输出至嵌入式处理器;嵌入式处理器采用的是型号为STM32F746NGH6的嵌入式MCU,通过芯片的SAI接口与音频解码芯片连接,对输入的音频数据进行处理识别,并将识别结果输出至串口;由于嵌入式平台有限的资源难以满足基于深度学习的声学模型训练的需求,因而利用PC实现声学模型的训练。
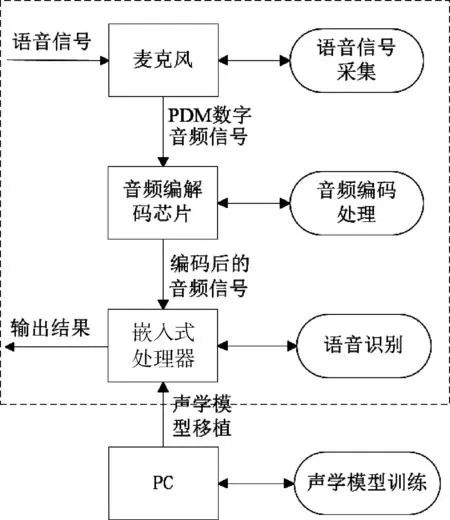
图1 系统总体架构
2 声学模型训练与移植
2.1 DS-CNN神经网络
文献[8][9]提出的DS-CNN神经网络作为标准三维卷积的有效替代方案,已经被用于在计算机视觉领域实现紧凑的网络架构。DS-CNN的核心就是将原本标准的卷积操作因式分解成一个depthwise convolution和pointwise convolution(即一个1×1的卷积操作)。简单讲就是将原来一个卷积层分成两个卷积层,其中前面一个卷积层的每个卷积核都只与输入的每个通道进行卷积,后面一个卷积层则负责连接,即将上一层卷积的结果进行合并。
若以M表示输入特征的通道数,N表示输出特征的通道数(也是本层的卷积核个数)。假设卷积核大小是DK×DK×M×N,输出是DF×DF×N,那么标准卷积的计算量是DK×DK×M×N×DF×DF。去掉M×N,就变成一个二维卷积核去卷积一个二维输入feature map;如果输出feature map的尺寸是DF×DF,由于输出feature map的每个点都是由卷积操作生成的,而每卷积一次就会有DK×DK个计算量,因此一个二维卷积核去卷积一个二维输入feature map就有DF×DF×DK×DK个计算量;如果有M个输入feature map和N个卷积核,就会有DF×DF×DK×DK×M×N个计算量。
DS-CNN则是将上述过程分为两步。第一步用M个维度为DK×DK×1的卷积核去卷积对应输入的M个feature map,然后得到M个结果,而且这M个结果相互之间不累加。因此计算量是DF×DF×DK×DK×M,生成的结果是DF×DF×M。然后用N个维度为1×1×M的卷积核卷积第一步的结果,即输入是DF×DF×M,最终得到DF×DF×N的feature map,计算量是DF×DF×1×1×M×N。即DS-CNN计算量为DF×DF×DK×DK×M+DF×DF×M×N。计算量与标准卷积计算量之比为:
以3×3的卷积核为例,卷积操作时间降到标准卷积的1/9。
可以看出,相较于标准的卷积神经网络,DS-CNN大大减少了运算量,这使得在资源有限的微控制器上可以实现更深和更宽的结构。将DS-CNN神经网络应用于语音识别的流程图如图2。

图2 DS-CNN用于语音识别的流程图
使用平均池,然后使用全连接层,提供全局交互,并减少最终层中的参数总数。
2.2 声学模型训练
声学模型训练采用Google speech commands dataset作为训练集,在Tensorflow框架中使用标准的交叉熵损失和adam优化器进行训练,批量大小为100,模型以20 000次迭代,初始学习率为5×10-4,并在第一个10 000 次迭代后减少到10-4。训练数据增加了背景噪音和高达100 ms的随机时移,以模拟复杂的背景环境,提高系统的鲁棒性。
2.3 声学模型移植
利用ARM开发的深度学习库arm_nn建立DS-CNN神经网络框架,将声学模型训练得到的各项模型参数输入至该框架中相应的位置。在后续新建嵌入式工程时移植已输入声学模型参数的DS-CNN神经网络,即可完成声学模型的移植。
3 离线语音识别
3.1 开发环境配置及工程建立
按照常规方法,在Linux系统下利用ARM开发的Mbed平台开发本系统的嵌入式程序。首先安装Mbed,然后在Mbed平台下编译代码。实际操作时,发现两个问题:(1)Mbed部分指令不可用;(2)使用Mbed无法在线调试以便于定位程序中的BUG。因此,本文提出了另一种解决方法,即采用Windows 10环境下的Keil 5.12开发本系统的嵌入式程序。方法如下:
在Keil中新建工程μVision Project,在“Options for Target→Device”中选择芯片型号STM32F746NGHx;“Options for Target→C/C++”中的“Define”选项卡添加“STM32F7xx,USE_HAL_DRIVER,ARM_MATH_CM7,_CC_ARM,__FPU_PRESENT,_FPU_USED=1”,以使之支持stm327xx_hal库和浮点运算。然后再移植工程组件stm32fxx_hal库和cmsis库,Arm开发的适用于深度学习的arm_nn库,以及用于硬件浮点运算的DSP库。经测试,该方法可以顺利新建工程,并实现程序的正常编译和在线调试。
此外,在开发过程中,发现程序编译时间过长,完整编译一次程序竟需10 min左右,严重延缓了程序编译和调试速度。研究发现,该问题是由移植的库中冗余的文件引起的。因此,对移植的库做出以下调整:
(1)对于stm327xx_hal库,注释掉stm32f7xx_hal_conf.h文件中本系统未用到的外设的define项,使程序编译时略过相应的外设库文件,仅使能DMA、FLASH、SDRAM、GPIO、RCC、SAI、UART等外设,如图3所示。

图3 stm32_f7xx_hal库使能外设
(2)对于庞大的arm_nn库,仅保留建立DS-CNN神经网络时会用到的文件,如图4所示。将其他文件从工程项目文件中移除。
图4 DSP库保留文件
经过上述调整,程序编译时间从10 min左右降为2 min左右,大大缩短了程序开发时间。
3.2 音频预处理
为便于后续的信号处理,需要对输入的音频信号进行分帧、加窗等预处理操作。采样点数设置为16 000,分帧时设置帧长为40 ms,帧移为20 ms。为了消除分帧造成的每帧音频数据首尾的重叠现象,选用Hamming窗来对每帧音频数据进行加窗操作。
3.3 MFCC特征提取
对音频数据进行分帧、加窗等预处理操作后,需要对每帧音频数据进行MFCC特征提取。具体步骤如下:
(1)对每帧音频数据,通过快速傅里叶变换(Fast Fourier Transform,FFT)得到对应的频谱。设置FFT运算点数为2 048,通过FFT运算得到每帧数据的实部和虚部,并以实部和虚部的平方和作为能量谱,获得分布在时间轴上不同时间窗内的频谱;
(2)创建Mel三角滤波器组,对每帧音频数据进行Mel频率转换。设置Mel三角滤波器组数为40,通过Mel滤波器组将线性自然频谱转换为能体现人类听觉特性的Mel频谱;
(3)在Mel频谱上进行倒谱分析。对得到的Mel频谱进行取对数操作,并通过离散余弦变换(Discrete Cosine Transform,DCT)来实现Mel逆变换。取Mel逆变换后得到的第2~13个系数作为这帧语音的特征。
整体的特征提取流程如图5所示。

图5 MFCC特征提取流程图
3.4 分类识别
将提取的MFCC特征输入到声学模型中,利用arm_nn库中的run_nn函数和arm_softmax_q7函数完成音频特征的分类过程。利用滑动窗口对分类结果进行平均运算,以得到平滑的分类结果。根据分类结果即可得到最终的识别结果。
4 测试过程和结果
将程序通过ST-Link下载到主频为216 MHz的STM32F746NGH6微处理器中,并开启在线调试模式。程序运行开始,初始化系统,并开启SAI外设和DMA通道,实时监听麦克风端的语音输入。用USB接口连接嵌入式平台与PC端串口接收程序,将识别结果输出到PC端。测试时,在麦克风端说出含有训练集中词语的语句,即可在PC端串口接收程序的接收窗口内看到相应的语音识别输出,如图6所示。

图6 语音识别结果串口打印
选取训练集中的50个词,对选出的每个词,分别在安静环境和噪声环境下进行20次测试,计算平均识别时间和平均识别率。为了方便比较,在同样的硬件平台上,使用相同的训练集和测试样本,应用传统的基于HMM的方法来进行语音识别。
最终得出的测试结果如表1所示。

表1 语音识别测试结果
综上所述,与基于DTW算法的嵌入式语音识别系统相比,本文所述方法可以突破特定人的限制,应用在非特定人的语音识别上,大大扩展了语音识别的应用范围;而与基于HMM算法的嵌入式语音识别系统相比,本文所述方法不但在识别时间上有所减少,在识别率上也有明显提高。
5 结束语
本文基于深度学习和DS-CNN神经网络,在嵌入式平台上设计实现了离线语音识别系统。与现有的基于传统算法的嵌入式离线语音识别系统相比,提高了识别率,减短了识别延迟;与基于专用语音识别芯片或离线语音库的嵌入式离线语音识别系统相比,则节约了硬件或软件成本。测试结果表明,系统能较好地实现嵌入式离线语音识别功能,在节约软硬件成本的同时,减少了识别时间,提高了识别率,是一种有效的嵌入式离线语音识别方案。
