基于历史数据的虚拟机资源分配方法
2019-04-18王海涛李战怀卜海龙孔兰昕赵晓南
王海涛 李战怀 张 晓 卜海龙 孔兰昕 赵晓南
(西北工业大学计算机学院 西安 710129) (工信部大数据存储与管理重点实验室(西北工业大学) 西安 710129)
为了应对大数据的爆发式增长,目前云数据中心广泛应用了虚拟化技术[1]以实现服务系统的横向扩展.虚拟化技术使得单个物理机(physical machine, PM)的资源可以分配给多个虚拟机(virtual machine, VM),从而产生若干个相互隔离的运行环境以部署不同类型的应用.与传统的技术相比,虚拟化技术使得云数据中心在基本维持原有服务能力的前提下,能够提高数据中心的整体资源利用率,同时达到减少硬件成本以及运营成本、节约物理空间等目的.然而,虚拟化技术的灵活性和扩展性同时也带来了新的资源管理问题,即虚拟机如何进行合理地分配和管理的问题.
一般云数据中心的应用场景中,虚拟化技术为用户提供一个共享的物理资源池,该资源池中可能包含上千台物理服务器,各台服务器的CPU、内存以及网络等资源可能是异构或者同构的,这些资源的分配通常以虚拟机为单位.当用户需要在虚拟平台上部署自己的应用时,就会向该资源池提出申请,数据中心根据用户需求为其分配带有适当资源量的虚拟机,用户在该虚拟机上运行应用.数据中心的资源管理和调度模块必须能够及时地为数量庞大且不断变化的用户请求创建虚拟机,并为这些虚拟机分配适量的资源,以及确定虚拟机放置的目标物理机.这就需要有合适的虚拟机分配方案(即虚拟机资源分配方法和虚拟机放置策略).不合适的方案可能造成2种后果:1)物理机负载过重,导致虚拟机资源冲突率升高,降低用户体验;2)物理机的资源利用率过低,导致物理资源的浪费,增加运营成本.这2种结果都会造成数据中心的收益下降,应该尽量设法避免.因此,合理地进行虚拟机资源的分配和虚拟机的放置对于云数据中心至关重要.
针对上述问题,本文提出了2种基于历史数据统计分析的虚拟机资源分配方法,能够根据虚拟机的历史数据统计结果为其分配合适的资源,从而减少需要开启的物理机数量,提高物理资源的整体利用率,并尽量保证较低的物理资源冲突率.此外,针对现有的评价指标无法全面评估虚拟机分配方案有效性的问题,提出了1个综合有效性指标,从消耗的物理机数量、物理资源的利用率以及冲突率3个方面综合评估虚拟机分配方案的有效性.最后通过实际的负载实验,证明了本文提出的综合有效性指标能够合理地评估虚拟机分配方案的整体有效性,并且本文提出的虚拟机资源分配方法优于现有的常用方法.
1 相关工作
在虚拟机资源分配和放置方面,Meng等人[2]提出一种配对分配的方法,即首先通过分析虚拟机的历史负载,预测其未来一段时间的负载,根据负载预测值为虚拟机分配资源,然后选取2个负载模式负相关的虚拟机进行配对,将这对虚拟机分配到同一物理机上,从而提高物理机的资源利用率、减小冲突率.这种方法要求虚拟机的负载必须有较明显的周期性或者趋势性,否则预测效果会很差,造成虚拟机资源分配量不适当.此外,只能通过2个虚拟机进行配对,如果这对虚拟机的负载正相关,则会造成物理机资源冲突升高.
Mylavarapu等人[3]考虑了虚拟机负载的随机性,根据历史负载的平均值作为虚拟机资源分配值,利用遗传算法确定虚拟机的放置位置,并且在物理机上保留一定的空闲资源,目的是在保证服务水平协议(service level agreement, SLA)的前提下减少物理机使用量.Xu等人[4-5]提出了一个2层资源管理系统,通过位于虚拟容器层的本地控制器管理虚拟机资源,位于资源池层的全局管理器管理物理资源.本地控制器使用模糊逻辑的方法,将测量到的当前工作负载输入模糊模型,再将负载映射到需要分配给虚拟机的资源量上,然后向全局控制器请求资源.全局控制器将资源的分配视为多目标优化问题,使用分组遗传算法查找最优迁移策略,减小物理资源浪费、运行功耗以及热耗散.虚拟机的初始放置使用的是装箱策略,包括降序首次适应策略(first fit decreasing, FFD)和降序最佳适应策略(best fit decreasing, BFD).
Beloglazov等人[6]提出了一种改进的降序最佳适应策略,周期性地对物理机上的虚拟机进行重新分配,实际上相当于一种虚拟机迁移算法,目标是尽量减少物理机使用量,关闭空闲节点以节约能耗.Speitkamp等人[7]提出一种服务器整合方法,结合了历史工作负载的数据变化分析以及虚拟机的放置算法,目标是最小化物理机使用数量.该方法在进行虚拟机资源分配的时候,参考的是采样周期中的历史负载峰值,在进行虚拟机放置的时候使用的是分枝限界策略、首次适应策略(first fit, FF)以及降序首次适应策略(FFD).
李强等人[8]提出了一个云计算中虚拟机放置的自适应管理框架,通过带SLA约束的虚拟机放置多目标优化遗传算法来制定虚拟机放置策略.算法综合考虑了虚拟机放置策略中物理机消耗量以及虚拟机迁移次数2个目标,在保证满足SLA的情况下,能够有效减少物理机消耗量和虚拟机迁移次数,但是忽略了物理机的资源利用率问题.Gupta等人[9]提出了一种资源感知的虚拟机放置算法.目标是通过减小虚拟机放置所消耗的物理机数量来节约能耗,同时尽量保证各个物理机上的负载均衡.但是没有考虑虚拟机负载的动态变化及其导致的资源冲突问题.
Sharma等人[10]提出了3种不同的启发式算法,用于为虚拟机选择合适的物理机进行放置以提高整体的资源利用率,但针对的是虚拟机迁移而非分配的问题;魏蔚等人[11]提出了一种通用云计算资源调度问题的快速近似算法,利用非线性规划的数学方法,通过对资源需求分布函数以及资源总量的一系列反函数、求导等数学运算得出近似最优的资源分配方案,但是其中涉及到的复杂数学运算会增加调度延迟.
综上所述,对于虚拟机资源的分配,现有的研究主要使用虚拟机历史负载的峰值或者平均值来确定虚拟机需要分配的资源量.而对于虚拟机的放置,常用的是降序首次适应策略(FFD)、降序最佳适应策略(BFD)以及下次适应策略(next fit, NF)还有遗传算法和非线性规划等.这些方法的目标一般是减少虚拟机分配策略的物理机消耗量,从而节约物理资源并降低能耗.
然而,在实际场景中,云数据中心虚拟机负载可能变化率很大,不一定有明显的周期性.因此,通过历史负载数据的峰值进行分配容易造成物理资源的浪费,增大物理机消耗量,导致运营成本增高;而使用历史负载的平均值进行分配则可能造成虚拟机的资源不足,进而导致用户体验下降.遗传算法和非线性规划算法的计算比较复杂,且在负载多变的场景下得出的最优方案容易失效,不适应大量实时请求的处理.此外,现有的研究大多通过单一的指标来确定分配方法的有效性,例如比较分配方法的物理机消耗量或者对比资源冲突率,缺乏一种全面的综合性指标.过于强调节省物理机数量,可能造成物理机上虚拟机数量过多,使得资源竞争严重,进一步导致冲突率升高.反之,过于强调减小资源冲突率可能需要为虚拟机多分配过量资源,导致物理机利用率在大部分时间都比较空闲,从而造成资源浪费.
针对上述问题,本文提出了2种新的基于历史数据的虚拟机分配方法以及1个综合有效性评价指标.简而言之,本文的主要贡献有2方面:
1) 提出了2种新的基于历史负载统计的资源分配方法,并与常用的峰值分配法和平均值分配法进行了对比,整体上优于现有的分配方法.
2) 提出了1个综合有效性指标,将物理机数量、资源利用率以及冲突率综合起来进行考虑,能够合理地评估不同方案(虚拟机分配方法+虚拟机放置策略)的整体有效性,得出最优方案.
2 虚拟机资源分配系统模型
本节定义了虚拟机资源(本文指CPU)分配以及虚拟机放置的系统模型,以便于分配算法的实现和验证.表1列出经常要用到的符号以及对应的含义.

Table 1 Notation and Meaning 表1 符号和含义
2.1 虚拟机资源分配模型
假设系统中目前有Np个可用的物理机、Nv个需要分配的虚拟机.每个虚拟机的历史负载有Ns个采样值,每个采样值表示该虚拟机在该采样时刻的CPU资源利用率值.虚拟机资源分配的目的是根据每个虚拟机的历史负载数据确定其需要分配的CPU资源量,模型为
4) 资源分配(Fr)的目标为
Fr(Cw)=Vr,
(1)
Vr=(r1,r2,…,rn).
(2)
2.2 虚拟机放置模型
虚拟机放置的目标是将具有一定资源需求的虚拟机放置到合适的物理机上,尽量使得分配之后物理机的整体资源冲突率最小并且资源利用率最大.虚拟机放置的模型为
Fa(Vr,T)=(Vp,Nc,PT,Pc),
(3)
Vp=(p1,p2,…,pn),
(4)
其中,Fa为虚拟机放置策略,输入参数是虚拟机的资源利用率需求向量Vr以及资源利用率阈值T.经过该策略作用之后,输出结果是虚拟机分配需要的物理机数量Nc、虚拟机位置向量Vp、虚拟机放置完成之后物理机的总体资源利用率达到阈值T的概率PT(即4.2节所述的累积资源利用率),以及总体物理资源冲突率Pc.其中Nc,PT,Pc将作为评价虚拟机分配方案(即虚拟机资源分配方法与虚拟机放置策略的组合)有效性的指标,本文第4节将进行详细论述.
2.3 虚拟机资源分配方法
虚拟机资源分配的方法有多种,常用的是根据历史数据的峰值或者平均值确定虚拟机需要的资源量[2-3,7-8],本文分别用WMAX和WMEAN表示.为了解决现有方法资源分配有效性不高的问题,本文提出了通过负载分布概率以及期望值进行资源分配的方法.参照表1,令ri表示虚拟机mv,i分配到的物理资源利用率,wi,j表示虚拟机mv,i在采样时刻j的负载值,Ns为虚拟机负载采样值的数量,则各种资源分配方法的数学描述为

在实际应用场景下,历史数据会随时间不断积累,所以需要周期性地进行计算,根据新的分析结果调整虚拟机的放置.这可能会引入虚拟机的迁移工作,这一部分的讨论不在本文范围内.本文的目标是尽量使得虚拟机的初始分配能够适应负载的变化,提高物理资源的整体利用率,同时减小冲突率.
3 虚拟机放置策略
根据虚拟机的负载请求为虚拟机分配资源之后,需要将虚拟机以一定的策略放置到具体的物理机上.通常将该问题抽象为装箱问题,将物理机看作是固定大小的箱子,而虚拟机看作是具有不同体积的物品.如果在进行虚拟机放置时考虑多种资源限制,比如CPU利用率、内存利用率以及磁盘利用率等,则可抽象为多维装箱问题.多维装箱问题较为复杂,因此目前许多相关工作将其简化为1维装箱问题[12-14],通常考虑的维度是CPU利用率.在1维装箱问题中,常用的装箱算法有下次适应(NF)算法、降序首次适应(FFD)算法以及降序最佳适应算法(BFD)等.本文中,物品对应的是虚拟机,物品的尺寸即虚拟机的CPU利用率负载;箱子对应的是物理机,箱子的尺寸即物理机的CPU利用率阈值.当虚拟机分配请求到来后,组成1个虚拟机资源请求队列Lv(队列成员值为各虚拟机的物理CPU资源需求)以及可用的物理机队列Lp(队列成员值为各物理机CPU已使用率).本节描述了这种场景下的常用虚拟机放置算法.
3.1 下次适应(NF)算法
从虚拟机资源请求队列的队首开始分配,只要该虚拟机的CPU利用率请求没有超过物理机的CPU阈值,就将其分配到物理机队列的第1个物理机中,然后处理第2个虚拟机请求.如果第2个虚拟机请求可以分配到第1个物理机中而不超过其空闲CPU利用率,则将其分配到第1个物理机中,否则启用第2个物理机来放置虚拟机,而第1个物理机将不再考虑放置剩余的虚拟机,如此循环,直到Lv中所有虚拟机都被分配为止.算法伪代码如算法1:
算法1. NF算法.
输入:虚拟机CPU请求队列Lv、列表大小Nv、物理CPU使用量阈值T;
输出:物理机队列Lp、使用的物理机数目Nc.
①Nc=1,j=1;
② whilej≤Nvdo
③ ifLv(j)==0
④j=j+1;
⑤ else ifLp(Nc)+Lv(j) >T
⑥Nc=Nc+1;
⑦Lp(Nc)=Lv(j);
⑧j=j+1;
⑨ else
⑩Lp(Nc)=Lp(Nc)+Lv(j);
3.2 降序首次适应(FFD)算法
FFD算法首先将虚拟机按照资源请求降序排列为虚拟机资源请求队列Lv,然后通过首次适应(FF)算法进行分配.具体过程是:先顺序扫描物理机队列Lp,将当前虚拟机请求放入第1个能够容纳它的物理机中.如果当前打开的物理机不能容纳该虚拟机,则打开1个新的物理机进行放置,如此循环直至所有虚拟机放置完.算法伪代码如算法2:
算法2. FFD算法.
输入:虚拟机资源请求队列Lv、列表大小Nv、各元素降序排列、物理CPU使用量阈值T;
输出:物理机队列Lp、使用的物理机数目Nc.
①Nc=1;
② fori=1 toNvdo
③j=1;
④ whilej≤Ncdo
⑤ ifLv(i)+Lp(j)≤T
⑥Lp(j)=Lp(j)+Lv(i);
⑦ break;
⑧ elsej=j+1;
⑨ end if
⑩ end while
3.3 降序最佳适应(BFD)算法
BFD算法首先将虚拟机请求降序排列为虚拟机资源请求队列Lv,然后按照排好的顺序通过最佳适应(BF)算法进行分配.具体过程是:放置虚拟机时先按顺序扫描已经打开的物理机,将其放入第1个能够容纳该虚拟机且放置之后空闲利用率最小的物理机中,如果当前打开的物理机不能容纳该虚拟机,则打开1个新的物理机进行放置,如此循环直至所有虚拟机放置完.算法伪代码如算法3:
算法3. BFD算法.
输入:虚拟机资源请求队列Lv、列表大小Nv、各元素降序排列、物理CPU使用率阈值T;
输出:物理机队列Lp、使用的物理机数目Nc.
①Nc=1;
② fori=1 toNvdo
③j=1;
④sort(Lp)*将物理机列表按照CPU空闲利用率升序排列*
⑤ whilej≤Ncdo
⑥ ifLv(i)+Lp(j)≤T
⑦Lp(j)=Lp(j)+Lv(i);
⑧ break;
⑨ elsej=j+1;
⑩ end if
4 虚拟机分配方案的评价指标
第3节描述了多种虚拟机资源分配方法和放置策略,如何合理地评价这些方案的有效性是一个关键问题.单纯地使用某一方面的指标来评价方案的有效性比较片面.例如消耗的物理机数量少不一定表示该分配方法很有效,因为这样有可能造成每个物理机上的资源竞争比较激烈,导致资源冲突率升高.因此,本文认为:从虚拟机的分配所消耗的物理机数量、物理机的资源利用率以及总体冲突率3个方面来综合评价虚拟机分配方案会更合理.下面分别对这3个指标进行说明.
4.1 物理机的消耗数量
物理机的消耗数量指的是服务所有虚拟机请求需要开启的物理机数量.显然,在虚拟机请求量一定的情况下,分配方案消耗的物理机数量越少,则能源消耗越小.反过来讲,使用的物理机少也意味着每个物理机上平均承载的虚拟机数量多,这样能够提高物理资源的利用率,但是却容易增大物理机上的资源冲突率.
4.2 物理机的累积资源利用率
在云环境中,平均资源利用率并不能有效表示物理机的资源利用情况.主要原因在于,虚拟机的负载会随着时间变化,导致物理机资源利用率的时变性较大.例如物理机在时刻t1的资源利用率为70%,到了时刻t2可能会变为20%.所以使用一般的资源利用率统计值表示物理机的资源利用情况,容易造成资源分配出现较大的偏差,导致物理机过载或低载.
为了解决这个问题,本文提出了基于概率分布的累积资源利用率来表示物理机在一段时间内的资源利用情况.以CPU资源利用率为例,累积资源利用率定义为
1) 设物理机资源利用率的阈值为T,表示希望物理机的资源利用率能够达到T值以上,以确保物理资源得到充分利用.
2) 设物理机x的CPU资源利用率矩阵为
其中,ui,j表示该物理机上第i个虚拟机在第j个采样时刻的负载值,物理机x的资源利用率达到T以上的概率表示为
① https://www.planet-lab.org/,PlanetLab项目将分布于全球各地的上前台服务器通过互联网连接起来,用于在真实的全球分布式网络上测试新的服务.

(5)
(6)
其中,I(A)为指示函数,当条件A成立时I(A)=1,否则I(A)=0;NT,x表示采样周期内,物理机x的CPU资源利用率(即其上的所有虚拟机分配到的物理CPU利用率之和)达到阈值T及以上的次数.
当对比物理机资源利用率时,需要将所有已开启的物理机当作一个整体来看.假设物理机的资源向量为Pr=(pr,1,pr,2,…,pr,Np),其中pr,i表示第i个物理机的最大CPU利用率,Np表示消耗的物理机总数.因此,当物理机资源利用率阈值为T时,定义累积资源利用率PT为
(7)
为了简化问题,将物理机的资源利用率进行归一化,以机器上的物理CPU数量为缩放因子,使得每个物理机的最大CPU利用率标准化为100%,因此对任意i,j有pr,i=pr,j=100%,则式(7)可以简化为
(8)
将式(5)代入式(8),化简之后可得出
(9)
由式(9)可以看出,在需要分配的虚拟机数量以及虚拟机资源请求确定的前提下,最终物理机总体的累积资源利用率与虚拟机资源分配方法和虚拟机放置策略都有关系,前者主要影响NT,i的值,后者主要影响Np值.
4.3 总体资源冲突率
总体资源冲突率指的是某台物理机上的所有虚拟机在某一时间段内的资源冲突率.由于目前的主流虚拟平台(如Xen,VMWare)都支持虚拟机之间的物理资源共享,所以各个虚拟机的资源需求总和可能超过物理资源总量,此时就会造成资源冲突.例如某台物理机上分配了2个虚拟机A和B,初始CPU资源利用率都是40%,则物理机CPU总利用率为80%,此时没有资源冲突.假如一段时间之后,虚拟机A的CPU利用率需求增长为80%,此时虚拟机A和B所需要的CPU资源总利用率达到120%,超过了物理机的CPU总利用率,从而导致资源冲突,进一步造成虚拟机的性能下降,影响用户体验.为了描述资源冲突的可能性,定义总体资源冲突率为采样周期内物理机资源利用率超过100%的概率,其计算方法与PT相同,只是将阈值T设为100,即:
Pc=PT(T=100).
(10)
4.4 综合有效性指标
第4节第1段已经论述过,单独通过某一指标评估虚拟机分配方法的有效性具有片面性.本文认为,在比较各种虚拟机分配方法时,需要考虑3个指标,即分配虚拟机资源请求需要的物理机数量Np、虚拟机放置之后物理机的累积资源利用率PT以及总体资源冲突率Pc.为了从整体上考虑这3个指标,本文提出了一个虚拟机分配方法的综合有效性指标E,其计算方法为

(11)
其中,Nv为需要分配的虚拟机请求的数量;Nc为虚拟机请求消耗的物理机数量;α,β,γ∈(0,1)表示各个指标的权重值,且α+β+γ=1;E∈(0,1).
式(11)的含义是,当需要分配的虚拟机请求数量一定时,E越接近1,则方法的综合有效性越好.实际意义是,综合有效性高表示物理机资源利用率高,消耗的物理机数量少,同时资源冲突率小,分配方案总体上更优.对于不同的应用场景,主要关注的指标可能有所不同,可根据实际需求调整上述3个权重值.
5 实验与分析
为了验证综合有效性指标的可行性,并对比虚拟机分配方案的有效性,本节使用4.4节所述的数学模型,利用真实的虚拟机负载进行实验评估.简而言之,首先通过Matlab程序实现了第2节的数学模型和第3节的放置策略,然后设置不同的参数调用各种虚拟机分配方案对应的函数来处理实际的虚拟机负载,输出第4节描述的各项指标,最后通过这些指标来评估虚拟机分配方案.实验使用的虚拟机负载集来自PlanetLab①项目,这些负载数据都是真实的虚拟机所占用的物理CPU利用率数据.该数据集共有10天的虚拟机负载,每一天的虚拟机数目都是1 000左右,每个虚拟机每天的负载数据包含288个采样值(每5 min采样1次).评估的目标包括3种常用的虚拟机放置策略(NF,FFD,BFD)以及4种资源分配方法(WMAX,WMEAN,WMIR,WEX).评估的指标是第4节叙述的虚拟机分配消耗的平均物理机数量、物理机累积资源利用率、资源冲突率以及综合有效性.
一般来说,历史数据越充分,统计结果就越有代表性,为虚拟机分配的资源应该越合理.但是,实时统计大量数据会增大调度系统的延迟.因此,没有必要统计所有历史数据,选择部分近期的数据作为代表也可以反映虚拟机近期的负载情况.本文的实验中使用1/8的负载数据作为历史数据,以此为基础为虚拟机分配资源.对于云数据中心来说,最关键的目标是满足客户的需求,在此前提下充分利用物理机资源.因此,一般来说,资源冲突率指标(γ)占的权值最大,资源利用率(α)次之.所以本实验设置式(11)的有效性指标各部分权值为:α=0.3,β=0.2,γ=0.5,设置物理机CPU利用率阈值T=80%.下面从4个方面分别讨论实验结果.
5.1 物理机的消耗数量
图1展示了不同虚拟机资源分配方法与虚拟机(VM)放置策略的组合导致的平均物理机(PM)消耗量(越低越好).
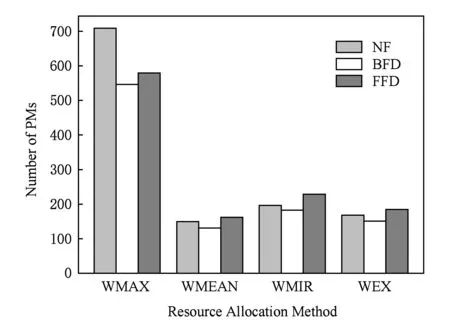
Fig. 1 The number of PMs consumed by VMs’ allocation图1 虚拟机分配消耗的物理机数量
从图1可以看出,不论采用何种放置策略,WMAX方法消耗的物理机数量最多.这是因为WMAX方法根据虚拟机历史负载的峰值进行资源分配,使得每个物理机上能够放置的虚拟机数量最少,因此消耗的物理机最多.WMEAN方法消耗的物理机数量最少,这主要因为这些虚拟机大部分时候的负载都比较小,因此根据历史负载计算出的平均负载也比较小,使得每个物理机上分配到的虚拟机数量较多,消耗的物理机数量少.WMIR和WEX计算出的资源需求量接近,因此消耗的物理机数量接近,都略高于WMEAN(不超过20%),但是相对于WMAX的物理机消耗数量大幅减少了约60%.
3种虚拟机放置策略消耗的物理机数量差别较小.在WMAX方法下,NF策略消耗的物理机明显多一些,而在其他方法下则差别不明显.BFD策略消耗的物理机数量最少,FFD策略消耗的物理机数量略多.这是因为BFD策略放置虚拟机的时候中心思想是尽量把每个物理机都放置满,每一轮放置都要扫描剩余的所有虚拟机,找到最接近剩余容量的虚拟机请求,这样使得物理机上的虚拟机放置在这3种策略里面最“紧凑”,从而消耗的物理机数量最少.因此,从物理机消耗量来看,WMAX方法代价太大,不推荐使用,BFD策略最节约,应该优先考虑.单独从节省物理机资源的角度来看,使用BFD+WEX,BFD+WMEAN基本是最优的.
5.2 物理机的累积资源利用率
图2展示了在设置物理机资源利用率阈值为80%时,不同虚拟机资源分配方法与虚拟机放置策略的组合对应的累积资源利用率对比(越高越好).
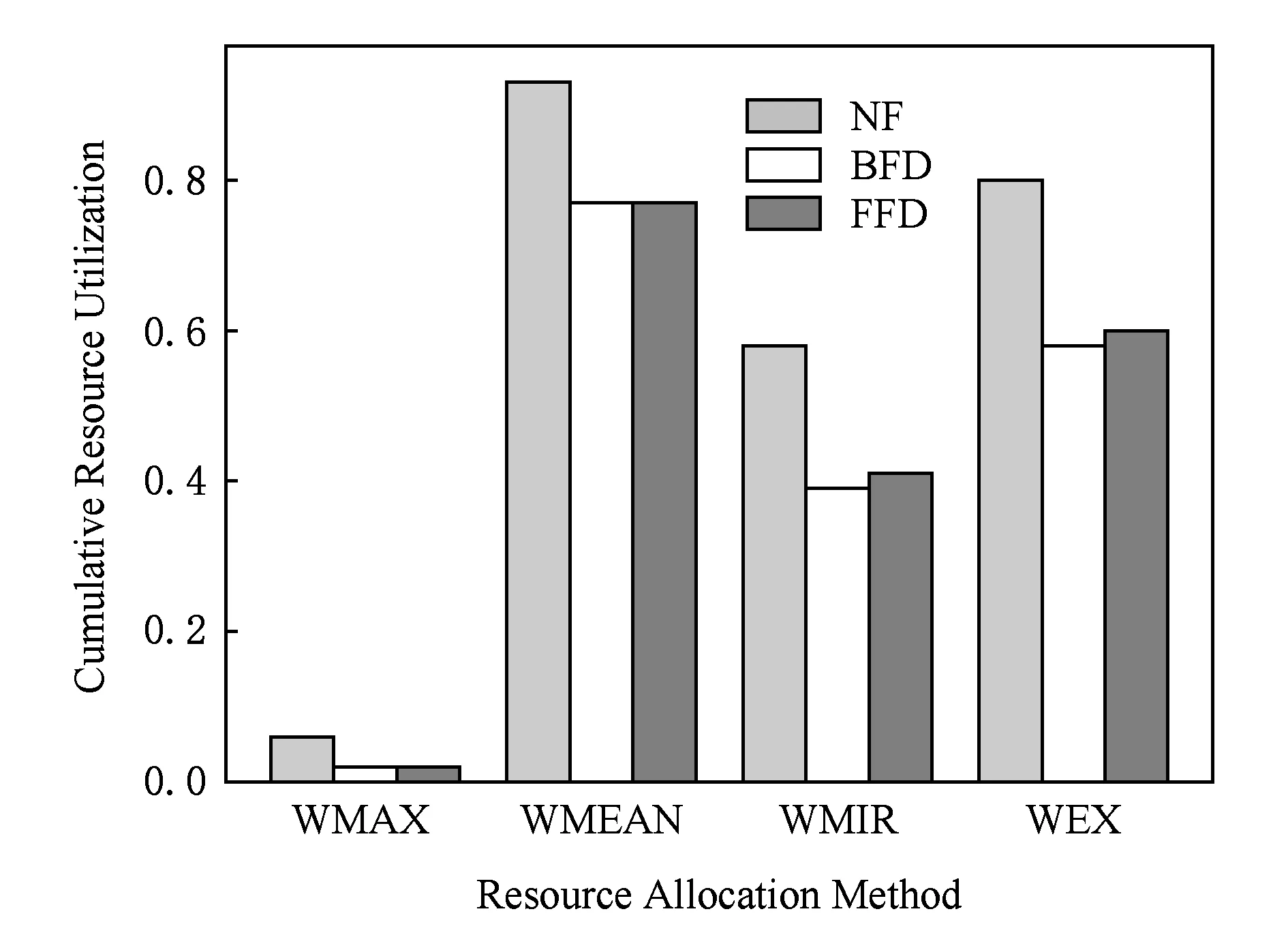
Fig. 2 The cumulative resource utilization of PMs图2 物理机的累积资源利用率
从图2可以看出,WMAX方法下物理机的累积资源利用率很小(0.1以下),原因是该方法使得物理机上分配的虚拟机较少,且由于虚拟机的负载较小,因此无法充分利用物理资源,造成比较严重的浪费.这种情况在虚拟机负载变化率大时会更严重.WMEAN方法整体上的累积资源利用率最高,其次为WEX,接着是WMIR.这3种方法的累积资源利用率高于WMAX的原因是,能够在一定程度上规避少量突发大负载对资源分配的影响,尽量根据负载的整体水平来分配资源.在3种虚拟机放置策略中,NF策略的资源利用率最高,FFD略高于BFD.所以从资源利用率方面来看,接近最优的方案应该是NF+WMEAN,NF+WEX次之.
5.3 总体冲突率
图3展示了不同虚拟机资源分配方法与虚拟机放置策略的组合导致的总体冲突率,即物理机平均资源冲突率对比(越低越好).

Fig. 3 The average resource collision rate of PMs图3 物理机平均资源冲突率
从图3可以看出,WMAX的冲突率最小(不超过0.05),而WMEAN的冲突率最大,WMIR与WEX则介于2者之间.结合图2和图3可知,累积资源利用率与总体冲突率之间存在一定程度的正相关关系.正如5.2节的分析,由于WMAX策略使得每个物理机上分配的虚拟机数量最少,因此其总体的累积资源利用率最小,这种情况下发生资源冲突的概率最小.而其他3种分配方法虽然提升了资源利用率,却由于物理机上的虚拟机分配较多,更容易造成资源冲突.此外,NF策略造成的冲突率比其他虚拟机放置策略大约高1倍.所以从资源冲突率来看,首选方案应该是BFD+WMIR,FFD+WMIR次之.
5.4 综合有效性
结合图1、图2以及图3可以得出,关注的指标不同会导致不同的最优方案.在实际环境中,负载模式的差别也会造成最优方案的不同.然而,云数据中心需要有能够兼顾3个指标的方案,使得在满足用户需求的同时能够充分利用现有物理资源,减小消耗的物理机数量,从而降低成本.本文提出的综合有效性指标可以将3种指标统一起来,便于为云数据中心选择合适的虚拟机分配方案.本文实验设置3个指标的权重为:α=0.3,β=0.2,γ=0.5,根据式(11)计算不同分配方案的有效性指标E值,得出表2:
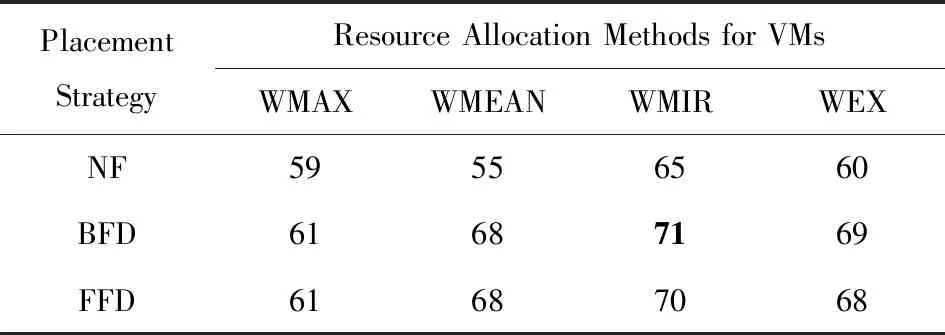
Table 2 Integrated Effectiveness Comparison表2 综合有效性对比 %
Notes: Bold value means BFD+WMIR scheme is able to get the highest integrated effectiveness.
由表2可以看出,在PlanetLab的应用场景下,使用BFD+WMIR方案能够达到最高的综合有效性,FFD+WMIR次之.这表明,BFD+WMIR方案最能够在充分利用物理资源的同时减少消耗的物理机数量,并降低资源冲突率.结合图1、图2以及图3可以发现,该结论与5.1节、5.2节以及5.3节的分析相吻合,也就是说综合有效性指标能够合理地综合评价虚拟机分配方案.但是要注意的是,如果应用的需求发生变化,则需相应调整α,β,γ的值,得出的最优组合会相应地变化.虽然粗略看来,综合有效性指标的通用性似乎较小.但实际上这样的灵活性对于负载多变的数据中心来说更加有利.数据中心可根据实际需求设置综合有效性指标的各部分权值,选择最合适的虚拟机分配方案,从而减少成本、增加收益.
6 结果与讨论
从实验结果来看,首先,本文提出的综合有效性指标能够从整体上合理地评估虚拟机分配方案,且具有较强的灵活性.其次,本文提出的虚拟机资源分配方法WEX和WMIR的综合有效性都高于常用的方法WMAX和WMEAN.因此,在要求提高物理机资源利用率同时减少资源冲突率的场景下,本文提出的WMIR方法以及WEX方法表现比常用的虚拟机资源分配方法更优异.
需要注意的是,不同的应用场景要求的指标权重值有所不同,得出的最优策略也不尽相同,不能一概而论.实际上,在确定应用需求后,就可以大致设置这3个评价指标的权重,然后根据虚拟机的历史负载数据通过仿真测试得出最优方案,再按照最优方案进行实际的虚拟机分配.这种思路具有很大的灵活性和可操作性,可应用在数据中心进行自适应的虚拟机最优分配.通过这样的一个自适应机制,就可以动态地根据虚拟机负载的变化以及用户的需求进行方案的调整,从而达到节约物理资源、减小成本、提高收益的目的.当然,本文是基于PlanetLab的应用场景进行的实验,与生产环境中的云数据中心场景有所不同.在实际应用时还需针对相应的平台进行改进,这也是作者未来的研究方向之一.
7 总 结
本文提出了2种根据历史数据统计信息进行虚拟机资源分配的方法以及1个综合有效性指标,能够从整体上评估物理机消耗量、资源利用率以及冲突率3方面的指标,得出整体最优的方案.通过实际的虚拟机负载实验验证,本文提出的资源分配方法在3种常用的虚拟机放置策略下能够达到整体最优.本文提出的根据历史数据统计信息进行虚拟机资源分配的方法以及综合有效性指标能够应用于云数据中心的虚拟机分配,在满足用户服务需求的同时,达到提高资源利用率并降低冲突率的目标.
