基于信息融合的无人驾驶图像数据处理方法
2019-04-18戴耀威高正创唐树银李宏宇叶继铭
◆戴耀威 高正创 唐树银 李宏宇 叶继铭
(中国矿业大学徐海学院 江苏 221000)
0 引言
根据阿里巴巴达摩院公布的2019年十大科技趋势,无人驾驶技术进入冷静的发展期,无人驾驶技术的环境复杂性使得无人驾驶的研究方向不再仅仅局限于真正行驶在路上的汽车,而是面向于自动公交,无人车物流配送,园区循环利用等相对固定的应用模式。无人驾驶目前更加专用化、小型化、嵌入式化。
激光雷达有精确度高,探测范围广,受环境干扰小的优点,图像识别结合深度学习,可以自主学习,具有优化能力。因此以激光雷达、基于深度学习技术的图像识别为基础的无人车传感系统将是一个理想的方案。
本研究采用 MobileNet的轻量化网络结合 Movidius加速器对图像数据信息进行处理,再采用MK60主控板对激光雷达数据进行采样,将图像数据信息与激光雷达信息进行叠加生成深度图,最终完成对障碍物的识别。
1 基于MobileNet的图片数据处理
基于MobileNet的图像处理算法在小型化嵌入式系统中有着良好的应用,其以低功耗为主要目标,设计功耗低于15瓦。
1.1 图像预处理
图像信息采集中最为根本的是图像的处理,而采集到的图像往往是不准确的。首先,由于存在大量干扰信息,因此最初采集到的图像信息中往往含有错误信息,需要对图像进行初步的处理。本研究首先对最初的图像做中值滤波的处理,以减小噪声对图像质量的干扰。其次,由于图像采集装置往往与水平地面存在一定的夹角,因此对采集到的图像有一定畸变,需要对滤过波的图像再采取畸变的分析与矫正,以便采集的图像信息数据更为准确和方便以后使用。
1.2 图像信息数据的处理结果
经过多种网络模型的组合比较和试验,决定采用卷积神经网络(CNN)和MobileNet模型来进行图像信息数据的处理。处理结果如图1所示,原图经过预处理之后,成功识别到图中的人物信息,并返回坐标等信息。
1.3 模型优化
MobileNet模型配合使用TensorFlow深度学习框架,进行数值计算,可移植性更强。第一步,将数据集划分,通过代码转化,将采集和处理好的数据集分为训练数据集与测试数据集,再用MobileNet模型训练。第二步,当模型训练好后,储存测试数据集,并进行测试。如果模型没有训练成功,继续对模型训练,最终训练好模型。
2 激光雷达的聚类分析
2.1 激光雷达与聚类分析
激光雷达精度高,识别范围广,但其数据量大。所以,如何从海量的数据中挖掘有用的数据进行分析,是研究激光雷达的重中之重。聚类分析的基本思想,在于所研究的云点或变量之间存在程度不同的相似性,找出一些能够度量云点或变量之间相似程度的统计量,以此为依据划分,把一些相似程度较大的指标聚合为一类,直到把所指标聚合完毕。
目前常用的聚类分析方法有 K-Means、K-Means++以及ISOData,为了使设备小型化、低功耗化,并且在不影响性能的前提下,决定采用较为简单的斜率分析法对激光雷达返回的数据进行分析。

图1 成功识别到图中的人物信息,并返回坐标等信息
2.2 数据的聚类
单线激光雷达数据以无人车为中心,遵循一定方向与速度向四周未知环境进行扫描采集,经上位机处理后返回的数据为角度与距离,由此便可以直观地知道障碍物与无人车的位置关系,如图2所示。

图2 障碍物与无人车的位置关系
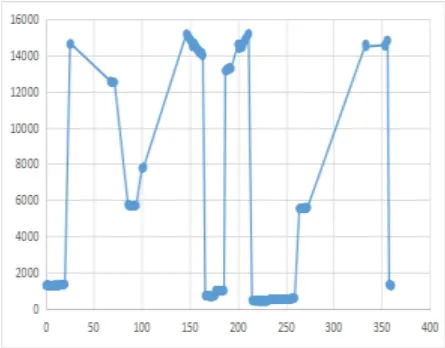
图3 散点图
如图2中所示,同一物体是由连续的点所组成,也就是雷达在物体表面所扫描出来的一系列点。以这些点为基准作散点图,如图3所示,同一类物体高度基本不变,所以点与点之间斜率基本为零,而两类物体之间存在距离的突变,临界两点间的斜率会有剧烈的波动。定义以下公式用于求数据的斜率:

其中θn为角度,dn为对应角度下的距离,σ 为误差容忍度,Δθn是角度差,Δdn是距离差,ρ是所求得的斜率,处理后的数据图如图4所示。
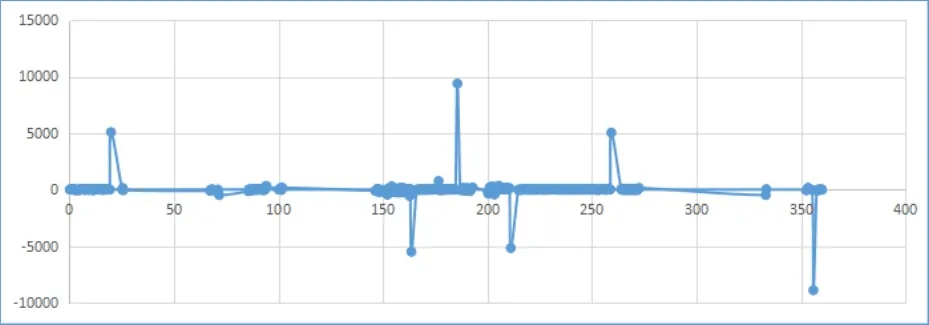
图4 处理后的数据图
由图4可知,如果检测到的是同一个物体,则激光雷达返回的云点数据经过处理后的ρ值基本相同,如果物体之间有间隔或者没有检测到物体则ρ值会发生突变,在图中表现为一个尖峰。两突变之间即为一类物体,规定当|ρ|>φ,即ρ的绝对值大于某一个阈值时,物体应该分类,否则归为同一类。根据以上分析,图4中有5类物体,与图2符合。

图5 激光雷达获取深度信息
3 信息叠加
由前所述可知,图片经 MobileNet处理后返回一系列数据,包括已识别目标在图片上的位置坐标等相关信息,但是缺乏目标的深度信息,因此通过激光雷达来获取深度信息。如图5所示,摄像头与雷达在同一铅垂线上,已知摄像头的视角为φ 并与雷达极坐标下的角度相对应,照片宽度为l,则每一像素点对应角度为φ/ι,通过目标的位置坐标可得到目标相对于摄像头的角度,也就得到了目标对应于雷达的角度θ。通过雷达聚类分析可知,在图像识别的目标处,雷达亦做好了物体的聚类,经上位机处理的雷达数据又包含角度与距离信息,因此可通过角度θ获得目标的深度信息,即L值,无人车与障碍物的直线距离,通过极坐标与直角坐标间的转换关系,也可求出障碍物相对对于无人车前进道路上的距离。获得目标的深度信息后,无人车能够判断车与物体的距离,从而更好地进行避障等功能。

图6 叠加效果
由这两部分数据进行固定角度于像素之间的叠加之后就可以在一张2D图片的基础上形成一张具有特定识别物体深度信息的深度图片,得到此图片后对于后续的无人车路径规划,避障与跟随等功能都可以很方便地实现,叠加效果如图6所示。
4 结论
该研究采用了MobileNet神经网络结合加速器对摄像头采集的图像进行处理,并采用聚类分析的方法对激光雷达的云点数据进行处理,最终将云点数据与图像数据进行叠加生成深度信息,经多次检测优化,本系统完成了对障碍物的识别和对所识别的障碍物深度信息的标定。
