基于深度神经网络的入侵检测技术
2019-04-18杨印根王忠洋
◆杨印根 王忠洋
(江西师范大学计算机信息工程学院 江西 330022)
0 引言
随着互联网的发展,人们的生活和生产方式发生了前所未有的变化,互联网已经成为社会不可或缺的一部分,但网络攻击对互联网的发展构成了威胁,因此对网络入侵检测系统(IDS)的研究越发受到研究者的重视。
入侵检测问题本质上是一个分类问题,当只需要判别是否发生了入侵时,其是一个两类分类问题。当需要进一步细分入侵种类的时候,例如入侵是否为 DoS((Denial of Service attacks)、R2L(Root to Local attacks)、U2R(User to Root attack)和Probe(Probing attacks)中的一种时,其便是一个多类分类问题,本文只考虑两类分类问题。
机器学习方法已被广泛使用在IDS中[1]。例如Pervez等提出了基于支持向量机(SVM)的过滤算法[2];Shapoorifard等基于KNN提出了KNN-ACO方法[3];Ingre and Bhupendra等提出了基于决策树的入侵检测方法[4]。
近十年来,深度神经网络(Deep Neural Networks)在语音识别,图像识别和人脸识别等领域取得令人瞩目的成果[5],其也被研究者们应用于入侵检测中。Tang.T.A等针对软件定义下的网络环境,提出基于的异常检测算法,该算法可以应用于软件定义网络中的异常检测[6]。Javaid A.等提出了一种基于半监督模型的方法,在网络入侵检测系统中对基准NSL-KDD数据集使用自学习(STL)方法来检测攻击[7]。Wang等通过将流量数据类比为图像,提出了一种基于卷积神经网络的恶意软件流量分类算法[8]。Staudemeyer等提出了基于LSTM的入侵检测算法,该算法适用于检测具有独特时间序列特征的DoS攻击和Probe攻击[9]。贾凡等将卷积神经网络模型应用到网络入侵检测,通过提取特征的局部相关性从而提高特征提取的准确度[10]。李春林等通过深度学习中的自编码网络模型对网络特征进行提取,然后使用softmax分类器对特征数据进行分类[11]。CL Yin等将RNN(Recurrent Neural Networks)运用到网络入侵检测中,通过选取不同的隐藏层节点数和学习率来进行二分类和五分类实验[12]。
网络入侵检测研究中,常用的KDD CUP 99、NSL-KDD数据集中通常包含类别数据和数值数据[13]。以往的机器学习方法是将类别数据进行one-hot变换后再与数值数据拼接,然后作为输入传递至模型。然而这种处理方式无法度量不同类别值之间的内在关系,并且使用one-hot 方法编码的向量会导致输入向量稀疏。受自然语言处理中词嵌入和句子嵌入研究的启发,本文提出了一种基于词嵌入和LSTM(Long Short-Term Memory)的网络入侵检测模型(LSTM-RESNET)。该模型通过词嵌入方法提取输入中类别数据的词向量,然后通过LSTM对词向量提取特征并构成句子向量,再将其与数值数据进行拼接,送入判别器,从而识别网络入侵。
本文其余部分安排如下:第一节对相关概念和研究思路进行介绍。第二节具体介绍本文提出的新模型。第三节在NSL-KDD数据集中对新模型、Knn、决策树、随机森岭等基准算法以及深度学习方法CNN进行比较与分析。第四节总结与展望。
1 相关概念与研究思路
记(x,y)为数据集D中的一个样本对。其中x为输入,通常包括网络的协议类型、时间戳、用户登录数量和失败登录记录数量等特征,x=[xc,xn]中既包含有类别数据xc∈R1×Nc(通常类别数据采用 token离散编号表示),也包含数值数据 xn∈R1×Nn。y∈{0,1}表示标签,其中0表示正常访问,1表示为网络入侵。IDS问题即构建并训练模型=f(x;ϴ)来预测当前访问为入侵类型的概率。
与图像识别和自然语言的处理不同,图像识别中输入均是表示像素灰度或者颜色的数值数据;自然语言处理中,例如情感分析中,输入则是列别数据,例如词汇。然而,对于网络入侵检测问题而言,输入中即包含类比数据也包含数值型特征。
传统上对类别数据的处理方式是将类别数据转换为 one-hot向量,然而这种处理无法计算不同类别之间的距离。随着 DNN的研究的深入,词嵌入在NLP(Natural Language Processing)中取得了广泛应用,词嵌入技术基于对上下文的分析,提取出词汇在低维空间的特征向量。词嵌入技术以及在此基础上发展起来的句子嵌入技术在文本理解、情感分析、chatbot以及机器翻译中发挥了巨大的作用。
近几年来,也有学者使用基于 NLP的词嵌入和句子嵌入来改进协同过滤算法。例如汤敬浩基于词嵌入方法提出了混合推荐模型[14],MG Ozsoy提出了一种基于改进的Word2Vec的推荐系统[15]。邢宁提出了主题强化的词句嵌入模型,通过分析长程上下文依赖关系来提高文本分类性能[16]。
目前句子嵌入中主要的方法可以分为基于 LSTM、CNN以及Attention三类。其中基于LSTM的方法由于可以很好地捕捉前后之间的依赖关系,受到众多学者的重视。例如Bowman 等基于LSTM分别对前提句和假设句进行编码,然后将得到两个句子表示向量连接后送入 tanh 层中,最后通过 Softmax 层进行文本蕴含识别分类[17]。刘阳等提出了一种基于双向 LSTM 的句子表示模型用文本蕴含识别任务[18]。H.Palangi等在对信息检索分析和应用时使用LSTM网络进行深度句子嵌入[19]。
LSTM(Long Short-Term Memory)是长短期记忆网络[20],是一种时间递归神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件。LSTM的巧妙之处在于通过增加输入门限,遗忘门限和输出门限,使得自循环的权重是变化的,这样一来在模型参数固定的情况下,不同时刻的积分尺度可以动态改变,从而避免了梯度消失或者梯度膨胀问题。
受上述研究启发,本文提出了一种基于 LSTM 和 RESNET的IDS模型。新模型首先通过词嵌入层获得类别数据的词向量,然后将类别数据集合类比为“句子”,采用通LSTM提取类别集合的句子特征,再与数值数据拼接,送入Resnet(残差网络)构成的判别器中。
下面该将对新模型进行具体的介绍。
2 LSTM-RESNET模型介绍
2.1 研究方法
在网络入侵检测数据集NSL-KDD中,其中的41个属性并不都是连续型属性,有3个字符型的离散变量。而神经网络不能处理这类数据,传统方法是将这类数据用0、1、2等数字标号或者使用one-hot转换成矩阵向量。然而这些方法会导致数据关系不平衡或者数据变得过于稀疏。鉴于LSTM在句子表示问题中有着良好的表现,本文将LSTM结合Embedding对NSL-KDD数据进行处理。将数据再利用LSTM提取特征,最后使用句向量表示,并为后续使用Resnet训练做好准备。
在深度学习中,随着神经网络层数加深,得到的训练效果在理论上应该是逐渐提升的。但是在实验中,随着网络深度的增加,训练效果反而下降。产生这种问题的原因是梯度消失,Resnet的出现解决了这个问题,使得可以训练非常深的网络。考虑到Resnet在图像处理方面的表现卓越,本文将Resnet运用到网络入侵检测中,相对于传统深度学习方法,其可以通过加深网络来提高性能。
2.2 模型
本文使用的模型如图 1所示(图中省略了中间的若干网络训练层,)。首先将数据集数字型和字符型特征分为2部分。字符型特征使用one-hot属性映射处理后进行Embedding词向量化,然后使用LSTM进行特征分析和处理,最后和数字形特征合并成为处理过的数据集。然后将训练数据集放入残差网络中进行训练,从中得到模型最好的超参数,然后使用测试数据集进行结果测试。
2.3 算法

然后将映射后得到的one-hot编码通过word embedding转换成词向量矩阵[18]。实现方法如图2所示:

图2 word embedding过程
其中输入为one-hot编码,经过神经网络隐层的计算,会得到一个权重矩阵,矩阵的列数代表了词向量的维度,让后通过输出层得到结果。输出层是一个softmax回归分类器,它的每个节点将会输出一个0-1之间的值(概率),最大的值(概率)代表了期望的结果。这些所有输出层神经元节点的概率之和为 1。其中softmax函数如下所示:
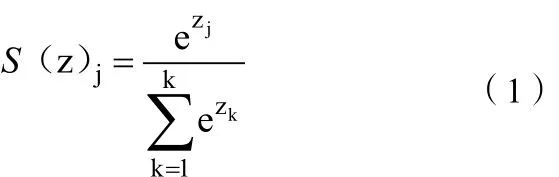
它能将一个含任意实数的K维向量 Z压缩到另一个K维实向量 S(z)中,每一个元素的范围都在 (0,1) 之间,并且所有元素的和为1。之后将得到的词向量通过LSTM进行抽取转换得到句子向量[21]。其计算公式如下:

其中x,W,b分别代表输入的词向量、网络权重矩阵和权重偏置。ft表示遗忘门限,it表示输入门限,表示前一时刻cell状态、Ct表示当前cell状态(这里就是循环发生的地方),ot表示输出门限,ht表示当前单元的输出,ht-1表示前一时刻单元的输出。
最后将句向量送入残差网络中训练并通过softmax得到预测结果。其中残差网络基本思想和计算如图3所示:

图3 残差模块
残差网络由图3所示的若干残差块组成,假设该部分神经网络的输入为x,要拟合的函数映射(即输出)为H(x),可以定义另外一个残差映射F(x)为H(x)-x,则原始的函数映射H(x)可以表示为F(x)+x。He通过实验证明,优化残差映射F(x)比优化原始映射H(x)容易得多[22]。
在未来,标准化研究机构想要发展壮大,就必须开拓进取、与时俱进,及时转变思想观念,牢固树立品牌意识,增强品牌经营能力,无论是对接政府,还是对接市场,都应该在工作中体现自身机构的独特性和品牌价值。简言之,标准化研究机构应以品牌建设为抓手,稳步提高核心竞争力,从而为做强做大做优奠定坚实基础。
网络模型的损失函数为分类交叉熵函数:categorical_crossentropy,其计算公式如下:
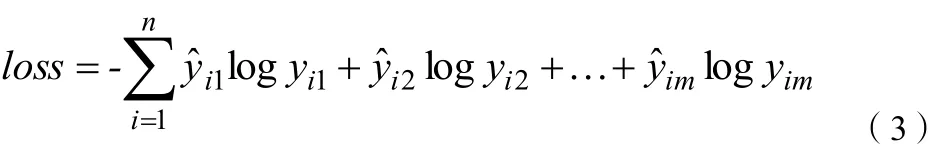
n是样本数,m是分类数,yim与ŷim分别代表标签值和预测输出值。
算法流程如下:

算法 权重更新算法输入
其中y为预测值,y为实际标签值。η为学习率,k为迭代次数。θ为权重矩阵和偏置,L(y:y)是测量模型预测值y和实际标签值y之间的偏差。
3 实验结果与分析
3.1 数据集介绍

表1 数据集特征
目前,入侵检测系统通常在 KDD 99和 NSL-KDD两个benchmark数据集上进行实验。
KDD99是1999年KDD竞赛建立的入侵检测基本数据库。数据库由许多的网络连接数据组成,每条记录都有41个属性,其中34个属性为连续属性,7个属性为离散属性。这7个属性中由3个属性为标称变量,为字符型数据。除了41个属性外,还有一个标识属性,表明该网络连接的类型。其中包括一个Normal正常网络行为,以及四大类攻击:DoS、Probe、R2L、U2R。
NSL-KDD数据集是对于 KDD99数据集的优化处理。其主要将KDD99大量冗余数据进行剔除并把KDD99数据集划分为固定的训练集和测试集。训练集和测试集数据都是选取合适的数量大小,使得不同的方法和实验论证都可以进行合理的比较。NSL-KDD数据集作为KDD99数据集的改进,数据的每条记录由41个属性特征和1个类标签特征组成,其中41个属性特征包含38个数字形特征和3个离散型(字符型)属性,具体如表1所示。
NSL-KDD和KDD99标签特征都分为五类(1类Normal和四类攻击),其中NSL-KDD训练集具体攻击方法有22种,测试集有17种。
3.2 实验设计
(1)实验环境
本文实验环境系统为windows10,使用Anaconda开源库,编程语言为python,深度学习工具为Keras等,使用GTX1070显卡作为GPU进行加速计算。详细环境配置如表2所示:
表2 实验环境
(2) 实验过程
我们采用NSL-KDD数据集进行实验。其中将四类攻击类别合并为abnormal类型,实验变为二分类问题。将数据集预处理后按照2.3算法流程训练模型并得出测试结果。
鉴于新模型存在诸多超参数, 我们针对 NSL-KDD训练集进行100次迭代训练,选取准确率最高的超参数作为模型参数,然后在测试集上进行验证。
新模型的主要超参数和值如表3所示:

表3 模型参数列表
实验结果和KNN、决策树(Decision tree)、AdaBoost等几种主流的基准方法进行比较分析[20],除此外还和主流的深度学习方法进行比较。评估指标分别是准确率(accuracy)、召回率(recall)、精确度和F值。
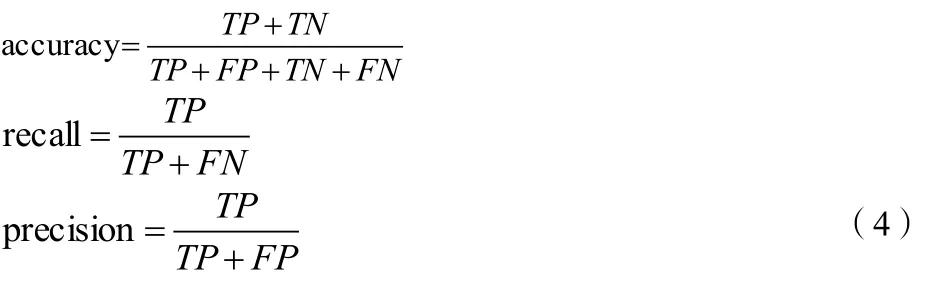

TP、FP、FN和TN含义如表4所示:

表4 TP、FP、FN和TN含义
考虑一个二分问题,即将实例分成正类(positive)或负类(negative)。对一个二分问题来说,会出现四种情况。如果一个实例是正类并且也被 预测成正类,即为真正类(True positive),如果实例是负类被预测成正类,称之为假正类(False positive)。相应地,如果实例是负类被预测成负类,称之为真负类(True negative),正类被预测成负类则为假负类(false negative)。
3.3 实验结果与分析
实验采用准确率来评估实验结果。如图4所示。
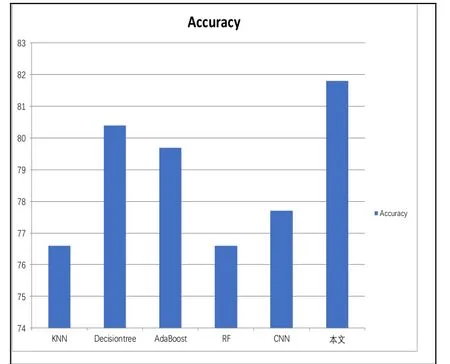
图4 不同算法准确率对比
实验中对比了采用KNN、决策树、AdaBoost、随机森林(RF)等基准算法和CNN、RNN等深度方法的实验结果,图4展示了不同算法的准确度。KNN、决策树、AdaBoost、随机森林和CNN的准确率分别为76.6%、80.4%、79.7%、76.6%和77.7%,可以看到本文提出的算法相比于传统机器学习算法和深度神经网络CNN在准确度上有一定的提升,达到了81.8%。
混淆矩阵如表5:

表5 混淆矩阵
从表 5中可以看出模型将异常样本误判为正常样本个数为3471,将正常样本误判为异常样本个数为298。
实验其他评估参数如表6所示。因为使用CNN方法的文章并未给出其他指标,所以不予对比。本文模型实验结果结合表5和表6分析可知Recall值相比较传统基准算法有了一定的提升,precision值和传统算法差别不大。因为IDS旨在提高recall值,即减少将异常样本误判为正常样本的个数。本文在此方面对比一些方法有了一定进步,但是总体来看误判数仍占总体样本数较高,所以导致准确率没有显著提高。
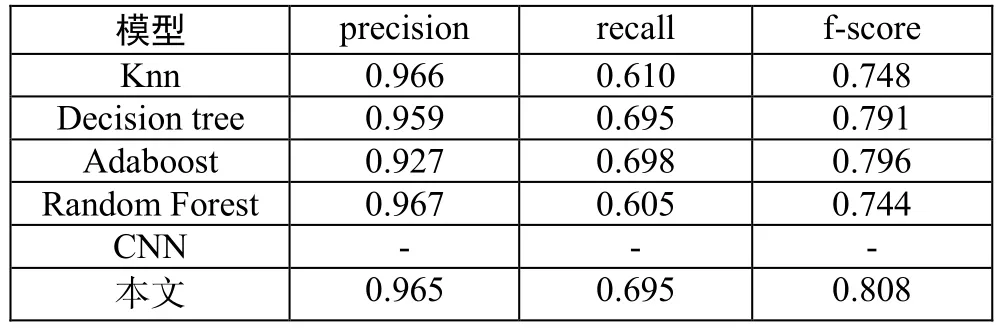
表6 不同模型算法评估指标对比
实验训练过程如图5所示,当迭代次数达到100时,实验结果趋于稳定,准确率为稳定在81%附近。
实验过程中fpr和tpr变化如图6所示。实验训练100次后得到最终模型,然后在测试集上计算fpr和tpr的值,最终画出Receiver operating characteristic curve(ROC)曲线。
4 结束语
本文将LSTM和Resnet引入到网络入侵检测问题中。和以往的传统基准算法相比,本文的模型可以处理更加庞大的数据量和复杂的特征,处理时序性特征可以考虑一定的上下文关系。可以更好地对数据之间的关联性和相似性分析,网络模型上可以训练较深的层次,通过神经网络深度提高模型性能。本文也有一些不足之处和改进空间,比如对于41维特征可以进行特征选择和网络结构模型细化,如何减少FP值等。进一步对这些问题进行研究,可以更好的提高网络入侵检测的准确率。

图5 迭代次数对应的准确率

图6 ROC曲线
