协同过滤推荐算法的改进
2019-04-17马佳琳
王 健,马佳琳
(沈阳师范大学,辽宁 沈阳 110034)
0 引 言
伴随着网上购物的不断发展,电子商务系统为用户提供了越来越多的选择。互联网的发展给人们的生活带来了巨大便利,同时一个迫切需要解决的问题也摆在面前:现今互联网的结构日趋复杂,用户经常会迷失在大量商品信息中,无法顺利找到自己需要的商品信息,即信息过载问题。个性化推荐系统正是在信息过载情况下出现的,能够根据用户喜好,推荐给用户所关心和需要的信息,给用户提供个性化服务,从而让用户获得更好的购物体验。但是,传统的推荐算法的推荐准确度不高。本文通过采用融合用户特征标签与协同过滤的方式,有效提升推荐系统的精准性。
1 协同过滤推荐算法
协同过滤推荐算法主要可分为基于用户的协同过滤推荐算法和基于物品的协同过滤推荐算法[1]。基于用户的协同过滤推荐算法的基本思想是根据用户的历史行为数据发现用户对物品的喜欢,如物品购买、收藏、内容评论等,并对这些喜好进行打分,然后根据不同用户对相同商品偏好信息计算用户之间的关系,从而在有相同爱好的用户间进行商品推荐。基于商品的协同过滤推荐算法的基本思想是根据用户对不同商品的打分情况计算商品之间的相似度,然后根据商品之间的相似性做出相应的推荐。
1.1 协同过滤推荐算法的基本步骤
步骤1:根据用户评分数据,建立用户-物品评分矩阵。
步骤2:计算目标用户和其余用户之间的相似性,根据相似性找到最相似的K个用户作为目标用户的相似邻居。
步骤3:根据用户相似邻居对目标用户未评分物品的评分信息,对目标用户未评分物品进行评分预测,选取预测评分最高的前N项作为目标用户的推荐列表,推荐给目标用户。
1.2 用户相似性计算
欧几里得距离法[2]:将用户对物品的评分转换成向量形式,由此得到n维的评分向量xi、yi,利用欧几里得公式计算两个向量之间的距离,距离值越小,相似度越高。其中,欧几里得公式为:
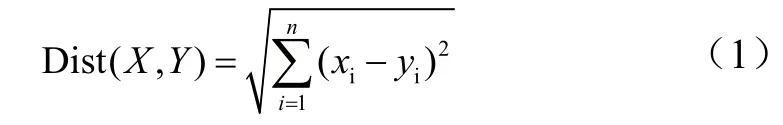
余弦相似性[2]:将用户i和用户j在n维对象空间上的评分向量分别表示为i、j,利用余弦公式计算两个用户向量的夹角余弦值,值越大,两个用户越相似。余弦公式为:
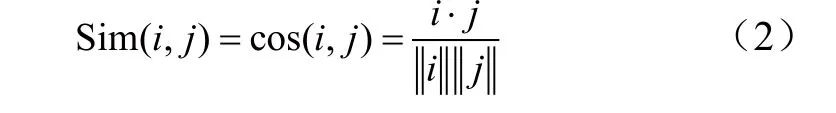
相关相似性[2]:将用户i和用户j共同评分的物品的集合用Ni,j表示,Ri,g表示用户i对物品g的评价,Rj,g表示用户j对物品g的评价,和分别表示用户i和j对物品的平均评分。利用皮尔逊相关系数算法计算两个变量的相关系数,绝对值越大,相关性越强。皮尔逊相关性公式为:
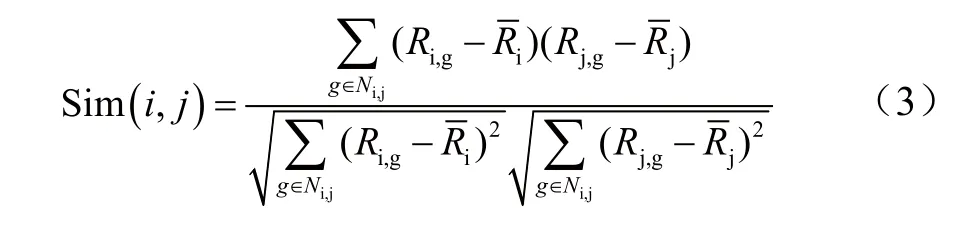
1.3 物品推荐
将Ptu,h表示为目标用户tu对未评分物品h的预测评分值,sim(tu,nu)表示为目标用户tu和邻居用户nu之间的相似度值,和分别表示目标用户tu和邻居用户nu对物品的平均评分,Rnu,h表示邻居用户nu对物品h的评分,Ntu表示为目标用户tu的邻居集合,预测
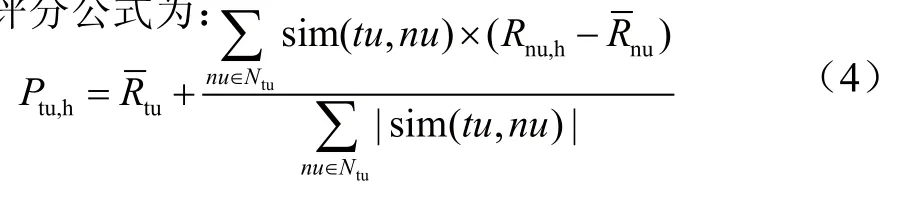
1.4 协同过滤推荐算法存在的问题
推荐算法是个性化推荐系统中最核心、最关键的技术[3]。推荐算法的好坏基本上决定了推荐质量的优劣。协同过滤推荐算法本身具有很多优点,但是也存在着一些不足,如系统开始时无法对新用户和新物品进行准确有效的推荐、算法中的数据稀疏性问题等。针对这些问题,本文提出融合用户特征与协同过滤的个性化推荐算法,以有效缓解数据稀疏性问题和冷启动问题,提高推荐算法的推荐质量。
2 融合用户特征与协同过滤的个性化推荐算法
网站一般在用户开始注册账号的时候,需要填写注册账号的相关信息,包括用户名、密码、手机号以及电子邮箱等信息[4]。但是,在计算用户之间初期信息相似性的时候,这些信息是毫无意义的。所以,本文采用用户的性别、年龄、职业以及地址4个特征标签信息来计算用户之间初始信息的相似性。
2.1 用户特征相似性计算
不同性别的用户在选择物品时会有不同的偏好。比如,男性用户选择物品时会更加注重物品的实用性,而女性更加注重物品的外观,则计算用户a和用户b的性别相似性公式为:
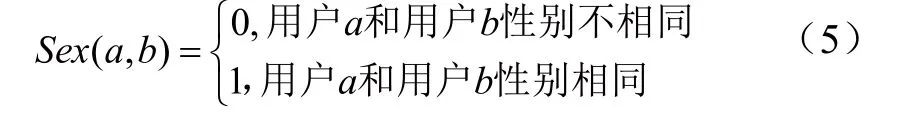
不同年龄的用户在选择物品时也不一样。将年龄划分为10个年龄组:6岁以下,7~10岁,11~14岁,15~17岁,18~28岁,29~40岁,41~48岁,49~55岁,56~65岁,66岁以上,则计算用户a和用户b的年龄相似性公式为:

不同职业的用户在选择物品时也会有差异。将职业分类看成一个树形结构,用H表示总层数,两个任意的职业结点的长度设为1,H(a,b)表示用户a的职业和用户b的职业在树中最近的共同双亲结点所在的层,则计算用户a和用户b的职业相似性公式为:

不同地区的用户由于受到当地风俗习惯的影响,也会在选择物品时存在区别。计算用户a和用户b的地址相似性公式为:

将上述四个用户特征融合,分别用a、b、c、d表示性别、年龄、职业、地址的权重系数所占的比重,得到用户的相似性公式为:

其中,a+b+c+d=1。
将融合用户特征的相似性公式加入传统的协同过滤相似性计算公式中,得到计算用户相似性公式为:
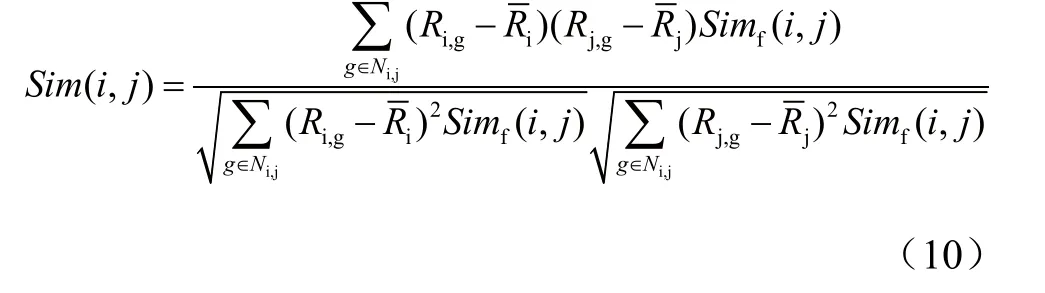
3 实验结果与分析
本文实验采用的是测试数据集,对衡量系统推荐质量采用平均绝对误差MAE进行评估。其中,实验使用的测试数据集为网络开源Movielens数据集,包含了943名用户对1 682部电影的10万条评分记录,评分区间为1~5分[5]。分数越高,表明该用户越喜爱这部电影。MAE表示通过计算用户对此电影的预测值与用户对该电影的实际评分之间的绝对误差值[6]。MAE的值越小,说明推荐的精准度越高。用Nt表示测试集合中评分的数量,Pc,m表示用户c对电影m的预测评分,Rc,m表示用户c对电影m的真实评分。MAE的计算公式为:

实验中分别取5、10、15、20、25、30作为最近邻居数用来进行测试,将传统的协同过滤算法和融合用户特征与协同过滤的个性化推荐算法进行算法推荐质量比较,实验结果如图1所示。
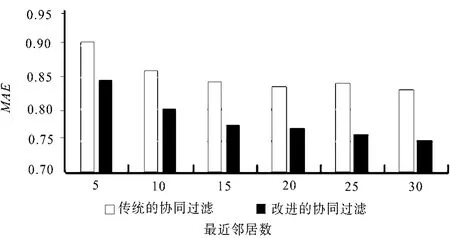
图1 实验结果对比
4 结 论
传统的协同过滤推荐算法中数据稀疏性问题和冷启动问题影响推荐结果的精准度,因此提出了将融合用户特征标签加入传统协同过滤算法的改进方法。从实验测试结果可以看出,改进的协同过滤推荐质量获得了显著提高。
