西双版纳普洱茶叶片生化参数高光谱估测模型研究
2019-04-16谢福明舒清态
谢福明 舒清态 字 李 吴 荣
( 西南林业大学林学院,云南 昆明 650224)
茶叶中的茶氨酸是茶叶和茶科植物特有的一种氨基酸,具有焦糖香和类似味精的鲜爽味,能消减咖啡碱和儿茶素引起的苦涩味,是茶叶的重要呈味物质,占茶叶游离氨基酸总量的50%以上[1-2]。氮素是合成蛋白质和叶绿素的重要组成部分,并参与酶的合成,是对植物生长、产量和品质影响较为显著的营养元素之一,其含量高低对茶树生长发育、矿质元素吸收以及茶叶内在化学成分的协调有重要影响[3]。通过对茶叶的光谱分析可以有效测定这些成分的含量[4]。遥感技术作为一种快速、宏观的地表资源监测技术手段,较之传统的地面调查,具有客观、无损以及实时获取信息的优势。高光谱遥感技术的出现和发展,给植被参数的定量化反演带来了新的机遇,高光谱遥感具有波段数量多,波段连线性好且分辨率较高等特性,能够记录作物叶片细微的生长变化,在目标物的分类、甄别、相关特征信息提取等诸多方面有着巨大的优势,已被广泛用于植被生化参数的提取、森林资源调查、农业经济作物病虫害监测等方面[5]。高光谱数据中包含植被更丰富的光谱信息,这极大地提高了对植被物理参数如叶面积指数和生物量反演的精度,尤其是使原来难度较大的除色素如叶绿素外的其他植被生物化学参数的遥感反演成为可能[6]。Liang等[7]基于曲线拟合、人工神经网络和随机森林回归模型,利用高光谱数据对作物的叶面积指数进行估测,模型反演效果较好;Jacquemoud等[8]以干叶鲜叶作为研究对象通过收集光谱信息利用PROSPECT叶片光学模型估算了叶片的多种生化参数;Kokaly等[9-10]利用光谱特征分析法来估测植被干叶片中氮、纤维素和木质素的累积量,利用回归分析方法选择出吸收特征波段中心位置波长,并建立回归方程估算其含量,结果表明该方法适于估算植被生化组分,同时可运用于不同植被生化组分的估测;Luypaert等[11]基于偏最小二乘法,建立了绿茶儿茶素没食子酸、总抗氧化能力及咖啡碱含量的近红外光谱估测模型,该模型对咖啡碱含量的估测效果较好。然而基于高光谱技术的主要研究对象为小麦、水稻和玉米等常见作物的色素(如叶绿素)或物理参数(如叶面积指数),针对茶树生化参数估测的研究较少。
云南普洱茶是指以符合普洱茶产地环境条件的云南大叶种晒青茶(Camellia sinensisvar.assamica)为原料,经特殊固态发酵加工工艺生产而成的具有特定品质特征的茶叶。本研究利用高光谱数据,运用统计法和遗传算法优化的BP神经网络(GA_BPNN)模型研究云南西双版纳普洱茶叶片茶氨酸与氮素含量与高光谱数据的关系,并利用其相关性分别构建茶氨酸含量与氮素含量的反演估测模型,以探索快速获取茶叶生化参数含量的技术,进而预测其长势、产量并鉴定茶叶品质,对未来深入研究普洱茶培育与精细经营具有重要意义。
1 材料与方法
1.1 研究对象
在云南省西双版纳傣族自治州勐腊县勐仑镇(地处东经 101°18′13″,北纬 22°1′56″,海拔1200 m),选取长势良好、无病虫害具有代表性的普洱茶古茶树作为研究对象对每株茶树顶层、中层、下层叶片先进行光谱测定后,分别采集每株茶树顶层、中层、下层不同方位叶片带回实验室作生化指标测定分析。
1.2 光谱及生化指标测定方法
1.2.1 光谱测定方法
采用田间叶片非离体状态法对茶叶光谱数据进行测定,所测叶片分别位于每株茶树顶层、中层、中下层。选用10°光谱仪视场角,探头垂直向下,与采集样本的垂直距离约10~20 cm,每次采集数据前都要进行1次标准的白板校正,并定时做系统优化,每个样本记录10~15个光谱数据,共计40个样本。数据采集时间为2016年12月,气压879 hPa,天气晴朗,风速小。
高光谱采集仪为美国ASD Field Spec 3便携式地物光谱仪,可获取目标地物在 350~2500 nm波长范围内的光谱数据,其中350~1000 nm波段范围内光谱分辨率为3 nm,采样间隔为1.4 nm;1500~2500 nm波段范围内光谱分辨率10 nm,采样间隔为2 nm。
1.2.2 生化指标测定方法
普洱茶叶片生化指标含量的测定委托云南省分析检测中心完成,检测统计分析结果见表1。

表1 普洱茶叶片生化参数检测结果统计Table 1 Detection results of biochemical parameters of Pu’er tea leaves
具体测定方法如下:
1)氮素含量测定:采用荷兰Primacy SN杜马斯定氮分析仪进行氮含量的测定,其原理是使有机物在纯氧环境下进行高温燃烧后通过氧化管和还原管使有机物中以不同形式存在的N定量的转化为氮气,并将其分离出来,通过计算氮气的体积来推导有机物样本中全氮的含量。
2)茶氨酸含量测定:依照国家标准(GB/T23193—2008)高效液相色谱法,在制备茶氨酸标准液后取10 μL净化液进行高效液相色谱分析,以绝对保留时间定性,用峰面积通过茶氨酸的标准曲线定量计算试样中茶氨酸的含量。茶叶中茶氨酸含量的计算方法见式(1)[12]。
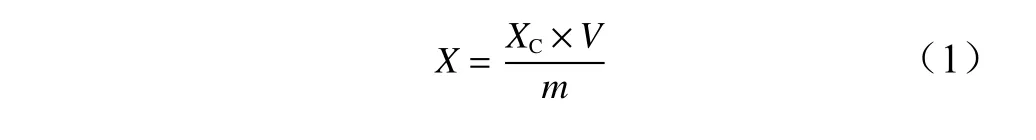
式中:X表示样品中茶氨酸的含量(g/100 g),XC表示样品浓度(mg/mL),V表示最终定容后样品的体积(mL),m表示样品的质量(g)。
1.3 数据预处理
1.3.1 异常波段剔除
由于水汽吸收和系统误差因素的影响,叶片波谱反射率在 1351~1400、1821~1950 nm 和2450~2500 nm波段范围内出现异常值,通过删除这些波段的波谱反射率予以剔除。
1.3.2 均值化
植物体各种生化成分在叶片内的分布是不均匀的,而且由于测量人员和环境的影响,同一叶片每次测量的光谱反射率数据都存在差异,故需要对每个叶片样本所采集的光谱反射率数据进行均值化处理,产生每一样本的新波谱反射率数据。
1.3.3 平滑滤波
由地物光谱仪的光电探测系统采集到的光谱数字信号分为两部分:探测器对地物响应信号和系统噪声。为消除噪声在提取地物光谱信息时产生的干扰,本研究采用Savitaky-Golay(S-G)卷积平滑法对原始光谱中存在的许多“毛刺”噪声进行平滑处理,其参数设置为:多项式级数为2,窗口点数为25。平滑处理后效果见图1。
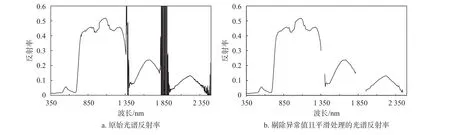
图1 预处理前后的普洱茶叶片光谱反射率Fig. 1 Spectral reflectance of Pu’er tea leaves before and after pretreatment
1.3.4 导数变换
在植被光谱分析中,导数变换可以消除不同程度的背景噪声、提高不同吸收特征的对比度以及确定光谱弯曲点、最大值和最小值等光谱特征值[13],其计算方法见式(2)。此外,本研究还对光谱反射率进行了对数运算后的导数变换处理,以凸显可见光区间内的光谱差异,减小光照强度变化对反射率的影响,计算方法见式(3)。
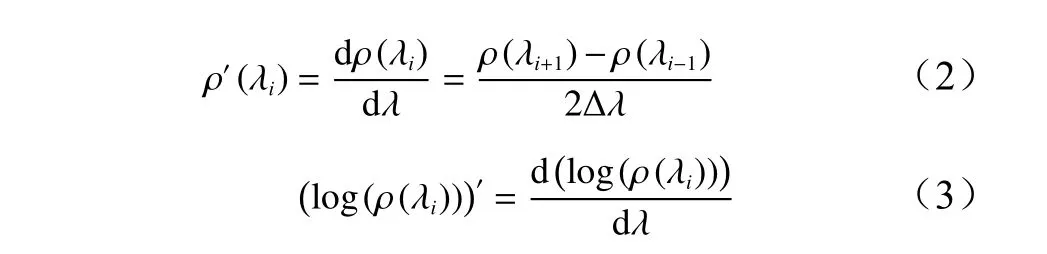
式中:λi为波段i的波长;ρ(λi)为波段i的光谱反射率;Δλ为波长λi-1到波长λi的距离;
1.4 高光谱特征参数提取
植物的光谱特性受到植物自身色素、水分、细胞结构和植物干物质的影响,随着植物本身生理生化性质的改变相对应在可见光和近红外区域特定范围内造成特定位置和面积大小的改变。本研究在这些变化区域内提取基于位置、面积的光谱特征参数见表2。

表2 高光谱特征参数[1, 14]Table 2 Hyperspectral characteristic parameter
1.5 基于遗传算法优化的BP神经网络模型
1974年,Werbos提出了BP(back-propagation)理论,为神经网络的发展奠定了基础;1986年,Rumellhart和McClelland提出了多层网络学习的误差反向传播算法,即BP算法[15]。BP神经网络的学习过程可以描述如下[16]:工作信号从输入层经隐含单元,传向输出层,在输出端产生输出信号。在信号向前传递的过程中网络的权值是固定不变的,每一层神经元的状态只影响下一层神经元的状态。如果在输出层不能得到期望的输出,则转入误差信号反向传播,在误差信号反向传播的过程中,网络的权值由误差反馈进行调节,通过权值的不断修正使网络的实际输出更接近期望输出。双隐含层的BP神经网络结构见图2,M为输入层,I为第1隐含层,J为第2隐含层,P为输出层。输入层与第1隐含层间的突触权值用wmi表示;第1隐含层与第2隐含层间的突触用wij表示;第2隐含层与输出层间的突触权值用wjp表示。
传统神经网络的权值和阈值一般是通过随机初始化为[-0.5, 0.5]区间的随机数,引入遗传算法(GA)就是为了优化出最佳的突触权值和阈值。遗传算法优化权值或阈值(w)的过程如下:1)初始化:随机生成大小为[初始化染色体群体个数npop,待优化权值或阈值数nf]的数组作为初始化群体,运用二进制(0/1)对基因进行编码,并计算每一个染色体的适应度(即预测误差),用于对初始染色体及子代染色体选择的评价指标;2)选择:采用随机遍历采样,根据自定义选择概率ps将已有的优良染色体复制后添入新染色体群体中,删除劣质染色体;3)交叉:利用交叉算子对染色体的基因编码进行重组,发生的概率为pc,通过交叉操作可以得到新一代染色体,子代的染色体组合了父辈的特性;4)变异:在染色体群体中随机选择一个个体,以pm概率随机的改变其基因的编码。本研究中遗传算法调用Sheffield遗传算法工具箱,其初始化参数分别设置为:初始化染色体群体个数npop:50,nf值取决于建模因子变量的个数,遗传迭代次数ngen:50,染色体选择操作概率ps:0.95,染色体基因交叉操作概率pc:0.7,染色体变异操作概率Pm:0.01。
1.6 精度检验方法
为准确的估算出茶叶氮素和茶氨酸含量,在建立相关模型进行预测的基础上,还必须对各类模型进行精度分析。本研究运用国际上常用的2种评价指标进行检验:
1)决定系数(R2)。R2可表示实测值与预测值间的拟合程度,其取值范围为0~1。决定系数越大,模型的精度就越高;反之,则模型的精度就越低。其计算方法见式(4)。
2)均方根误差(RMSE)。RMSE的值相对越小,模型的精度就越高;反之,则模型精度就越低。其计算方法见式(5)。

2 结果与分析
2.1 茶叶生化指标与光谱变量间的相关性分析
不同生化参数与光谱变量间的相关性分析结果见图3。
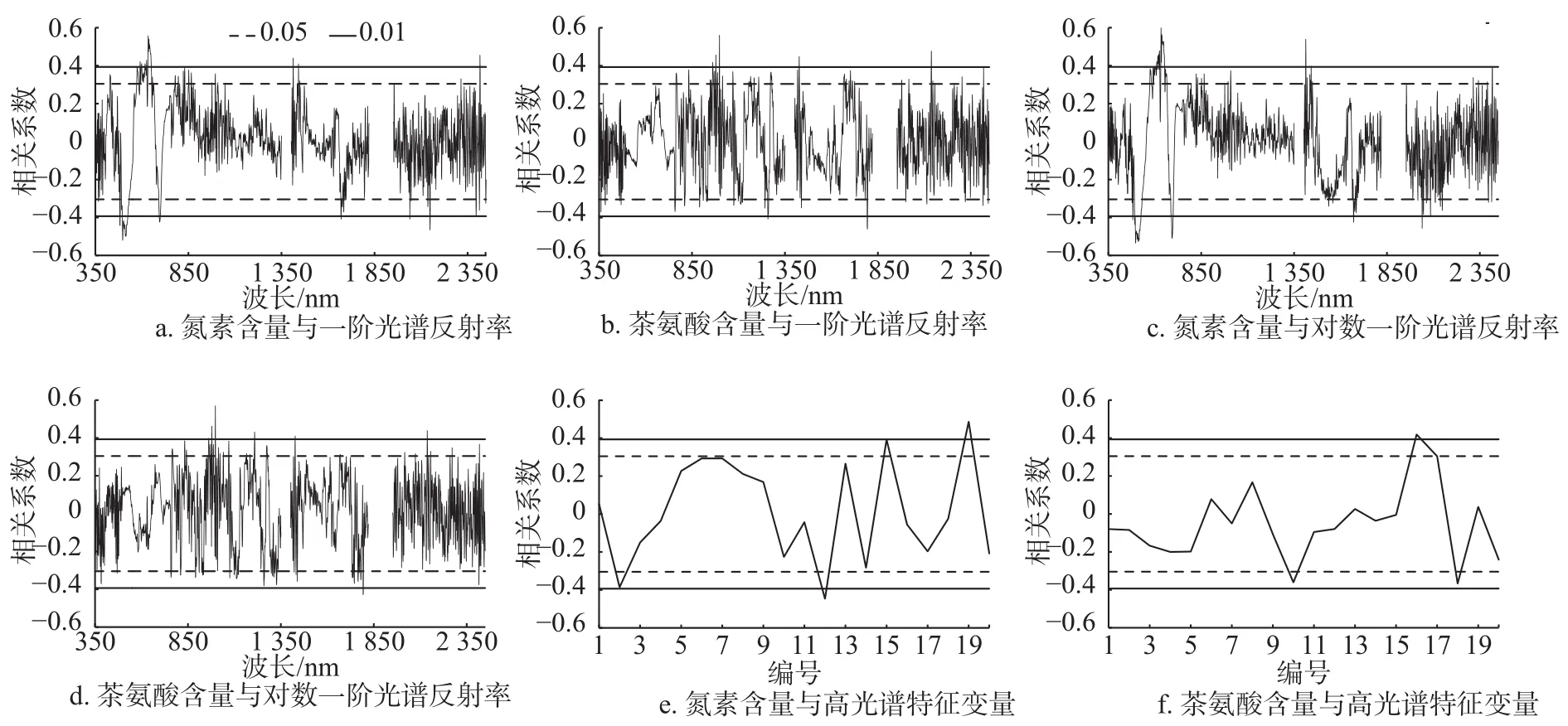
图3 不同生化参数与光谱变量间的相关性Fig. 3 The correlation between content of theanine and spectral variables
2.1.1 氮素含量与光谱变量间的相关性
氮素含量与原始光谱反射率之间相关性弱,不存在0.05水平下显著相关的波段。氮素含量与一阶光谱反射率在可见光波段范围内(390~760 nm)存在近80个极显著相关波段,在近红外和远红外波段范围内存在约11个极显著相关波段,最大相关系数出现在波长为633 nm的位置上,相关系数为0.58(图3a)。氮素含量与对数一阶光谱反射率在可见光波段范围内存在76个极显著相关波段,红外波段存在4个极显著相关的波段,最大相关系数也出现在波长为633 nm的位置上,相关系数为0.60(图3c)。氮素含量与高光谱特征变量的相关性弱,只有1个极显著相关的波段((ρg-ρr)/(ρg+ρr))和 2 个显著相关的波段(Db和(SDr/SDb))(图 3e)。
2.1.2 茶氨酸含量与光谱变量间的相关性
茶氨酸含量与原始反射率之间相关性较弱,不存在0.05水平下显著相关的波段。茶氨酸含量与一阶光谱反射率、对数一阶光谱反射率在可见光波段范围内不存在显著相关波段,在近红外和远红外波段范围内存在8个极显著相关波段,最大相关系数出现在波长为997 nm的位置上,相关系数为0.57(图3b和3d)。茶氨酸含量与高光谱特征变量存在3个显著相关的变量,分别为和 (ρg-ρr)/(ρg+ρr)( 图 3f)。总体上,茶氨酸含量与各光谱变量之间的相关性较弱。
2.2 GA_BPNN模型估测及验证
本研究中的BP神经网络及其优化算法均在MATLAB R2015a软件中编写、运行调试,主要函数有创建BP网络函数newff()、训练网络函数train()和仿真网络函数sim(),网络隐含层神经元的传递函数采用S型正切函数tansing(),输出层神经远的传递函数采用S型对数函数logsig(),训练函数利用Levenberg-Marquardt算法对网络进行训练。将40个实测样本数据按3∶1随机分成两部分:30个样本用于训练BP神经网络模型,10个样本用于模型测试。模型特征变量的选择上综合了一阶微分变量、对数一阶微分变量和高光谱特征变量,从中筛选出了相关性相对较强的因子作为建模变量。在估测茶氨酸含量时,选择了相关性>0.4或<-0.4的变量作为建模因子,共计17个;在估测氮素含量时,选择相关性>0.52或<-0.52的 变量作为建模因子,共计18个,详见表3。
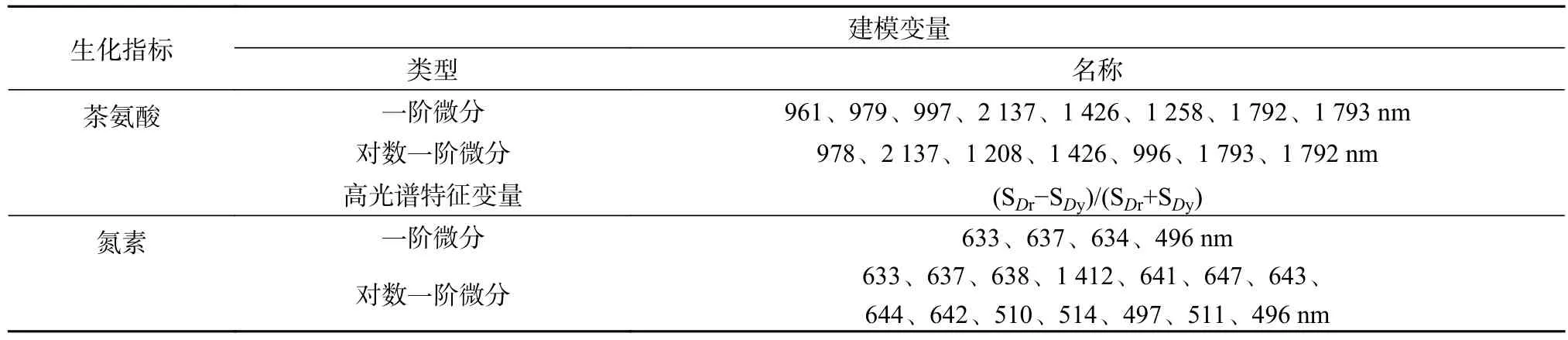
表3 茶氨酸和氮素含量估测建模变量Table 3 The feature variables of estimation model for theanine and nitrogen content
采用GA_BPNN模型,以提高对普洱茶茶叶生化参数含量的估测精度是本研究的核心内容之一。BP神经网络模型优化前后估测精度对比见图4。
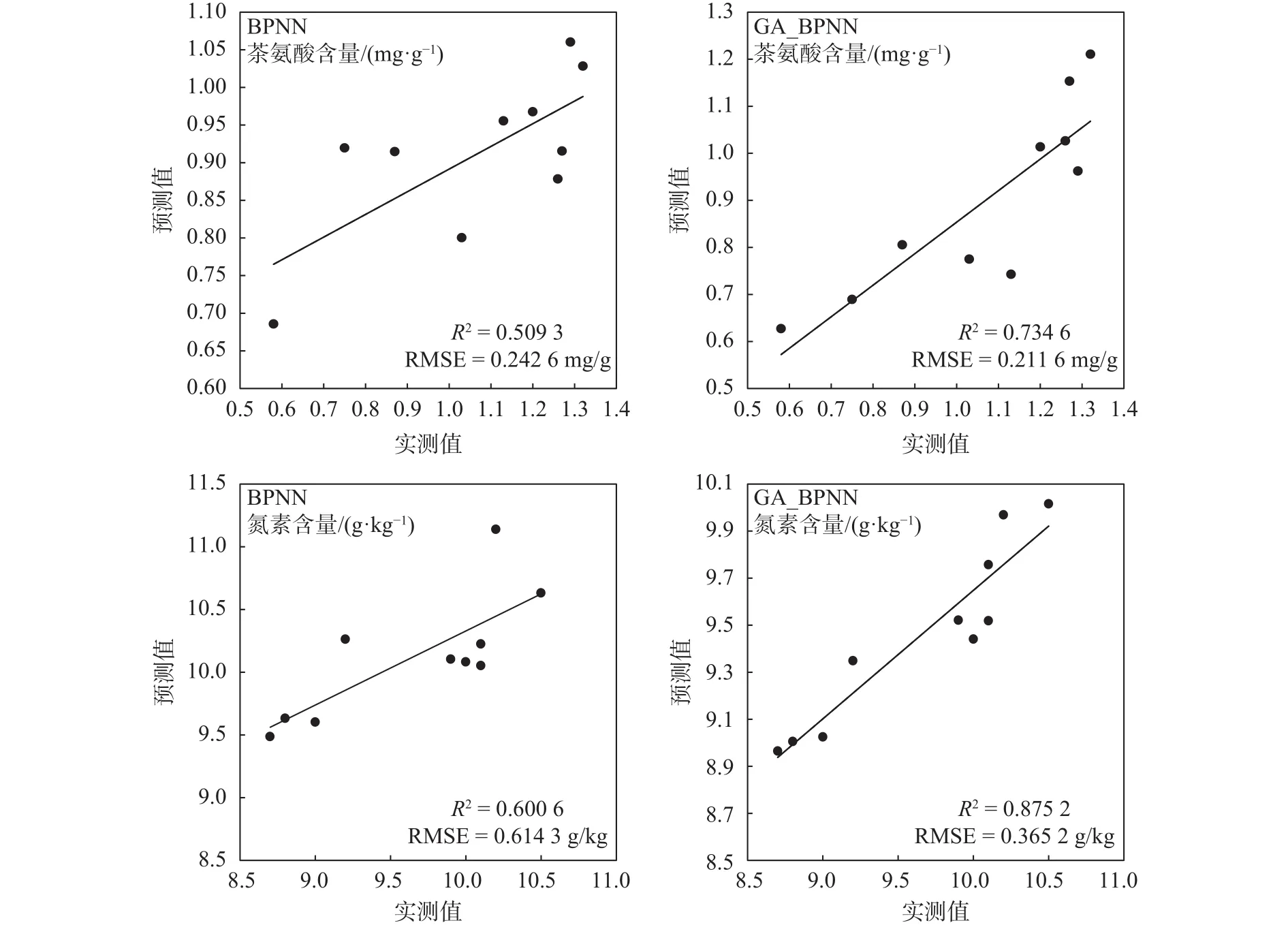
图4 BP神经网络模型优化前后估测精度对比Fig. 4 Comparison of estimation accuracy before and after BP Neural Network Model optimization
由图4可知,基于BP神经网络模型的氮素含量估测中,优化前RMSE为0.61 g/kg,R2等于0.60,GA优化后RMSE为0.36 g/kg,R2等于0.88。基于BP神经网络模型的茶氨酸含量估测中,优化前RMSE为0.24 mg/g,R2等于0.51,GA优化后RMSE为0.21 mg/g,R2等于0.73。遗传算法优化后的BP神经网络模型对普洱茶叶片生化指标含量的估测精度得到了提高,茶氨酸含量和氮素含量的估测均方根误差分别降低了13%和41%,R2的值均提高了0.2以上。
3 结论与讨论
本次测定叶片样本从采集地到实验室的运输过程中,虽然对其采用了1 ℃的低温保鲜处理,但对叶片自生的呼吸作用抑制有限,使得叶片内各种化学成分发生转化以及有效成分的分解,造成了部分决定茶叶功效的成分含量的变动。所以,寻求可行且效果优良的茶鲜叶储样手段可以有效保存鲜叶内的功效成分,对整个茶产业链与茶叶相关的科学研究有重要的意义。
高光谱数据所包含的信息量是巨大的,对高光谱数据的分析方法也多种多样。如何从海量的混合信息中提取针对茶氨酸或氮素等特定影响因子敏感的光谱参数,一直都是高光谱数据反演的重点难点。在高光谱数据的挖掘方面还有待深入和加强,尝试使用深度学习等机器学习方法对数据进行建模分析。
本研究所采用的反演模型是基于统计的经验模型反演,模型非常依赖于建模数据,对于不同地区、不同条件下获取的数据,需要重新拟合并对模型进行调整才能使用。后续的研究中考虑结合辐射传输模型和二向反射等物理方法建立混合模型,以提高模型的适用性。
本研究利用ASD地物高光谱仪采集普洱茶茶树叶片的高光谱特征,结合实验室测定的茶叶茶氨酸含量和氮素含量,对原始高光谱数据进行一阶导数变换、对数运算后一阶导数变换以及高光谱特征参数提取后分别与茶叶氮素含量和茶氨酸含量进行了相关分析,建立了估测茶叶生化参数含量的优化BP神经网络模型,并对模型精度进行了检验,主要结论如下:
1)茶叶生化参数含量与高光谱原始反射率之间不存在显著相关性;氮素含量与导数变换后的光谱反射率在可见光波段范围内有较强的相关性,在近红外波段和远红外波段范围内存在相关性的波段较少;茶氨酸含量在可见光波段范围内没有与之显著相关的波段,在近红外与远红外波段存在少数;对于高光谱特征变量,与氮素含量存在显著相关性的波段有 (ρg-ρr)/(ρg+ρr)、Db和(SDr/SDb),与茶氨酸含量存在显著相关性的波段有λr、 (SDr-SDy)/(SDr+SDy)和 (ρg-ρr)/(ρg+ρr)。
2)基于遗传算法优化的BP神经网络模型对普洱茶叶片生化参数的估测精度高于普通的BP神经网络模型:茶氨酸含量估测精度RMSE为0.21 mg/g,R2为0.73;氮素含量估测精度RMSE为0.36 g/kg,R2等于0.88。
