决策树分析技术在桥梁施工期的风险评估研究
2019-04-16李彦邹宗民徐磊王有志
李彦,邹宗民,徐磊,王有志*
(1.山东大学 土建与水利学院,山东 济南 250061;2.山东高速潍日公路有限公司)
1 前言
目前中国桥梁建设事业处于高速发展期,在挑战更险峻的环境、更大跨度、更先进的技术等的同时,施工安全事故也逐渐增多,如何建立一个稳定高效的桥梁施工风险评估体系越来越受到桥梁领域各专业人士的重视。Sexsmith曾在支架等临时设施方面探索过计算参数的调整问题,从而确保施工安全,结果指出,在桥梁施工中更要注意安全储备能力,而非寄托于加入的安全计算参数,这说明施工环境的复杂程度比仅由计算得出的安全参数更能影响施工风险。目前层次分析法(AHP)是一种比较成熟的风险研究理论,Tiryaki F曾指出该方法并不能找出并解决实际工程内部之间模糊的不确定的关联问题。柴干在此基础上建立了FCE法的桥梁施工风险评估模型,另外Tung-Tsan Chen改进的贝叶斯网络法对于处理这种模糊问题也有很好的帮助,但其研究体系过于庞大复杂便失去了良好的适用性。数据挖掘技术近年来发展十分迅速,该技术能够提取出隐含在大量数据中人们尚未探索出却又有重要潜在价值的信息或知识提供给管理者,以提高管理效率。数据挖掘算法已在信息安全、金融风险和疾病预防控制等众多方面取得了良好的应用效果。
在进行新工程项目的风险评估时,工程师往往更加注重以往的工程经验,而忽视以往的实际数据,即注重定性的经验判断而忽视定量地对数据本身的研究。该文通过改进数据挖掘的分类与预测算法,研究桥梁施工风险建立评估模型的一般方法,提出一种评估指标的选取与处理方法,把以往从实际工程中获得的数据作为训练样本,提炼出真实数据之间的关系,以改善当前工程风险管理的分析数据使用率低的问题,更加准确地评估施工风险。结合某桥梁专项风险评估实例进行评估模型的验证,定出其风险等级,为桥梁在施工期的风险评估提供一种基于数据挖掘技术算法的评估方法。
2 数据挖掘分析方法
数据挖掘技术在其发展过程中创新了大量不同类型的算法,如关联规则、分类方法、聚类方法和预测分析等,并且表现出与机器学习技术的交融度越来越深的特点,具有很高的智能化数据处理操作能力。在风险评估的辨识、分析、估测和评价4个阶段里,估测阶段的评估模型正是缺乏一种适用性强的数据处理方式,将分类与预测技术结合到评估模型研究中,从既有工程数据中筛选抽取训练集合按照决策树规则构造出一种分类器(分类模型),构造这样一个分类器的方法有概率统计、机器学习以及神经网络方法,该文建立评估模型所采用的决策树算法属于当前比较流行的机器学习方法里的一种数据处理方法。最后使用该模型进行风险目标预测,该功能可以很好地用来分析数据样本,发现数据流内部各属性间的关系,推导出相应的规则。
3 基于决策树算法的施工风险评估模型
3.1 桥梁风险评估的过程
使用数据挖掘的分类技术进行施工安全风险评估主要分为建模过程与使用预测两个步骤。首先要通过现有桥梁施工的风险分析数据库系统或采用桥梁施工安全风险分析方法,如FMEA分析法、HAZOP评估法、事故树分析法等,建立一组用于查找并整理出评估数据流的属性类别的样本组,作为训练数据集。在这里,可以将数据样本中的每个致险因子看作是一种影响属性。之后运用决策树规则在有指导的条件下建立影响施工安全的风险因子的分类器,并将每个样本各自设定一个与之相应的专属类标签,告知学习过程中各子样本训练在哪个归属类指导下进行,进而迭代逼近风险等级的分类目标,完成建模过程。导出相应的规则后便可对类标记未知的数据组(即测试样本)进行风险等级的预测分类,从而定出测试样本的属性值,即可能性等级或严重程度等级。
3.2 基于决策树技术的指标权重确定
在数据挖掘现有的分类技术理论中,决策树分析技术是一种较为成熟的构造分类器的方法,该方法可以很好地从杂乱的数据组中推理出内在的属性关系,从而进行样本分类。该文建模主要采用C4.5算法理论并在此基础上加以优化,在给定的训练集上,其所有既有工程实例都由相应的一组致险因子属性表达,通过算法学习得到一个从属性值到类别的映射,进而可使用该映射预测新的未知实例,其算法流程见图1。

图1 决策树构造基本算法流程
在对风险评估测试值的致险因素(即结点属性)进行分类时,选择的分枝指标SI(Splitting Index)为基于信息论中熵的准则进行判别。由于目前既有风险评估数据的各个指标分值大部分都是连续型值,而信息增益的分类标准是建立在离散值的基础上进行的且总是以增益最大的属性作为当前的节点属性,这种性质缺陷已不能满足实际评估需求,在此,适当引入信息增益比例指标,提高数据提炼纯度,克服了这一缺点。
分类指标核心部分计算方法表示如下:设影响施工安全的风险因素的数据集合(训练样本集)为S={s1,s2,s3,...,sm}。m为不同影响因素类别属性的个数,相应类别记为Ci;si为第i类风险因素的样本个数。pi为si发生的概率,则该训练集S的分类期望信息计算公式为:
Entropy(S)=I(s1,s2,s3,…,sm)=
当某一风险的测试属性A有v个不同取值{a1,a2,…,av}时,属性A把集合S分成v个子集{S1,S2,…,Sv},Sj为A取值aj的样本集合,把子集Sj中属于Ci类的样本个数记为sij,此时由该属性A划分当前子集合的熵值计算公式变为:
(1)
(2)
(3)

根据以上推导的期望信息便可计算出在某风险因素属性A上的分支获得的信息增益为:
Gain(A)=I(s1,s2,…,sm)-E(A)
(4)
该风险因素属性A的信息增益率计算公式为:
(5)
(6)
对于连续型值的处理方式的优化方案为:首先根据连续型属性的值对数据集进行升序或降序处理,然后根据属性A的不同取值分别依次作为阈值,将A的所有取值以阈值为界分为两组,最后依次计算出每种划分情况下的信息增益率,即得到所有可能的阈值及其增益率,选取增益结果最大的情况对属性A进行离散化处理。
采用上述改进后的C4.5算法在决策树的建模生长阶段的核心算法流程图如图2所示。
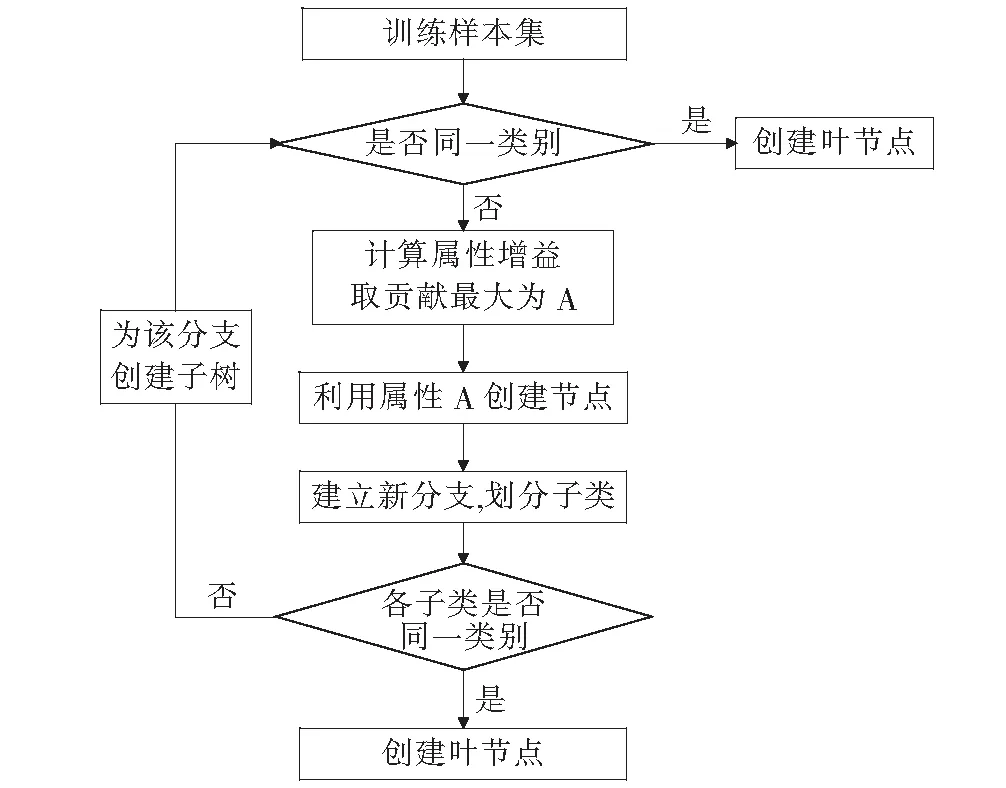
图2 改进后的C4.5算法的基本建模流程
3.3 风险评估指标的选取及等级划分
拥有一个标准化的数据仓库是运用数据挖掘技术的前提,这便需要根据桥梁风险评估指标建立一个数据库。影响桥梁工程施工安全的因素有许多,Fabian曾检验了150余座毁坏的桥梁,总结出引发危险的主要因素包括结构设计、施工管理、防护措施、材料归置、荷载伤害。目前大致从“人、机、料、法、环”5个方面进行风险分析获得普遍认可。但桥梁类型不同、施工环境差异等众多因素影响下,不可能事无巨细地把每种风险都考虑进去。因此选用合适恰当的指标建立一种使用性强的合理的数据组或数据仓库,对建模而言是很重要的。
风险识别与分析是整个评估过程的开始,也是风险估测、风险控制的重要基础。目前评估指标的选取通常是依靠工作人员的施工经验来判断,但由于个人水平差异难免出现评估分值时存在个人偏见的问题,在运用数据挖掘技术进行学习时,会造成很多噪声对结果产生影响,最常见的就是孤立点数据的拟合问题。采用文献[15]中推荐的风险分析方法,如经典的鱼刺图法、故障树分析方法等,结合最常见的6大风险源“高空坠物、物体打击、机械伤害、坍塌、触电、火灾”进行分析,可以很好地实现评估指标的划分与选取,这样也十分利于数据挖掘仓库数据组的数据属性归一化处理工作。
借鉴德菲尔法则建立专家组,针对要评估的目标建立分值评估系统。假设评估目标指标有n项,专家组人员为m人,则评分矩阵为:
矩阵中的xij(i=1,2,…,m;j=1,2,…,n)代表第i位专家对第j项指标的评分。将评价结果归一化处理,设等级集合为V={V1,V2,V3,…,Vp},其中Vk(k=1,2,…,p)表示第k个等级结果。如,针对第j个指标,若m位专家的打分结果中属于等级Vk的有mjk个,在专家意见等权重的原则下,对该指标的评分结果做出的映射处理为:
最终得到归一化的评分矩阵为:
根据决策树分析技术建模得到的权重结果B=(b1,b2,…,bn),最终得到该评估目标的风险等级结果为:

前面提到,数据挖掘的建模是在训练样本的学习下生成的,训练样本是从数据仓库中抽取的一组已有事实实例,所以为了保持对预测样本的评价结果标准的一致性,在分类构造器的分类属性设置上,依旧采用文献[15]推荐的风险等级划分方法,分为1~4级,分别代表:不太可能、偶然、可能和很可能。
4 工程实例
基于前文所述的数据组和数据建模的基本原理和构造方法,可以对桥梁施工的总体风险以及专项风险建立相应的风险评估体系,该文以某转体桥施工过程中常见的支架现浇法专项风险为例,进行风险等级的确定。
4.1 工程概况
现有某高架转体桥,主梁为现浇箱梁,每跨的跨径为70 m,转体部分的长度为2×65 m,桥面宽度为26.5 m,高度为13.3 m,桥梁下部是连续刚构体,采用Ⅴ形桥墩预应力混凝土结构。施工区内地形平坦,周围为耕地。地貌为剥蚀堆积山间平原地貌单元,地层主要由寒武系及第四系上更新统松散堆积层组成。该地区的气象条件为暖温带季风性气候,全年平均降水量615.3 mm,无地表水。夏季主要为东南风或南风,冬季为北风,全年平均风速3.5 m/s。该区段地震动峰值加速度为0.15g,地震基本烈度等级为Ⅶ度。
4.2 基于数据挖掘技术的风险评估
根据该文提出的风险评估指标的划分原则,对支架现浇法专项施工的风险因素进行分析。首先是训练组的选取,训练样本数量过多会导致模型的过分拟合,对一些偏差点往往会处理为噪声而过滤掉,而实际上某些偏差点往往更能描述问题,因此模型便失去了良好的预测功能。当然,训练样本过少会使模型过于简单,大大降低结果的准确度。为了保证学习结果的科学合理,该文在近3年里,通过专家认证的针对满堂支撑形式的支架现浇法进行的风险评估实例中,随机选取了8个实例作为训练样本,见表1。
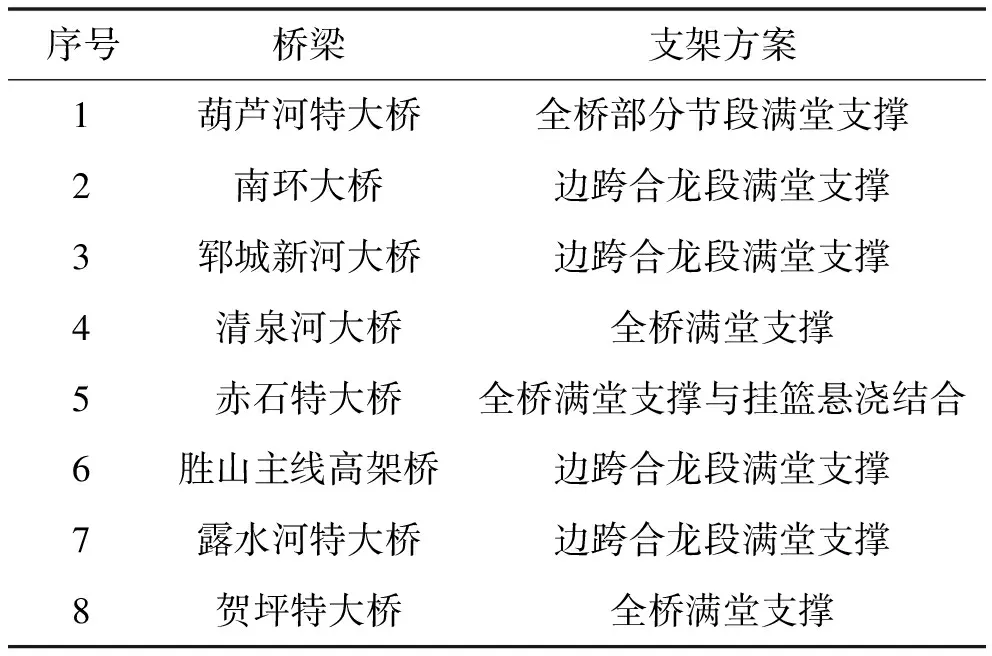
表1 支架现浇法训练样本概况
然后是评估指标的选取。结合已有训练样本里的基本属性及满堂支架专项施工实际特点进行风险源分析,结果见表2。经专家组讨论,选取支架规模、支架设计方案、气候环境条件、人员安全管理、地质岩土条件、机械设备6个风险源作为训练指标,并以百分制对各指标进行数据的归一化处理,见表3。
下面以确定风险评估的可能性等级为例,阐述运用该算法进行建模的基本过程。

表2 满堂支架施工事故风险源

表3 支架现浇法训练样本数据
注:表3中的支架规模主要考虑支架搭设范围,支架现浇施工方案是否详细以及工艺技术是否成熟等因素;设计方案主要考虑设计思路及方案是否全面,设计与施工的差异大小等因素。
首先计算该组训练样本集S的信息熵为:
之后计算每个属性对S集的信息熵与信息增益,以支架规模(Z)为例,针对数值属性的特点先进行递增排序,依次选择相邻值的中点作为阈值,对其计算EntropyZ(S)。
以邻值中点89为例,计算EntropyZ(S)。其他计算结果见表4。

表4 支架规模属性对样本集的信息熵
选择EntropyZ(S)最小的分裂点,即91.5作为支架规模属性的“最佳分裂点”。上述计算过程便是连续属性值的阈值确定过程,然后再计算该属性的Gain(Z)及GainRatio(Z):
Gain(Z)=Entropy(S)-EntropyZ(S)=0.61
同理可得:
Gain(PQADJ)=(0.595 0.544 0.5950.955 0.544)
GainRatio(PQADJ)=(0.38 0.67 0.38 1.00 1.00)
与之相应的信息分裂点为:(93 90 85 91.5 82.5)。
当测试属性较多时,为了提高训练速度与训练效果,可以进行指标的改进处理,根据待测样本的真实情况,进行属性的重要性排序,将影响较小、区别不大的属性分为1~3等级(依次代表差、一般、良好),然后进行离散化结果处理。在该例中,可以选设计方案属性进行上述改进,处理后的指标为[3 3 2 3 3 2 3 2]。
Gain(P)=Entropy(S)-EntropyP(S)=0.205
由计算结果可以看到:对于影响较小的属性,采用改进后的信息增益率0.215,比原来的计算值0.38更接近实际情况,训练模型的拟合效果更好。
4.3 评估结果
从上述建模结果知,地质属性对可能性2、3等级的划分影响最大,而机械设备属性对可能性3、4等级的划分影响最大,可以依次选取此两种属性为根节点,生成相应的两个分支并对每个分支继续重复上述计算过程,即可构造出此训练样本的评估模型。最终的属性节点确定的权重指标经过归一化后为:B=(0.16,0.06,0.17,0.10,0.26,0.25)。
针对该转体桥的实际情况,按照上述的评分原则,邀请了8位专家对满堂支架施工专项进行了分值评估,得到的评分系统为:
使用前文所述的结合算子计算结果为:F=(0.15,0.40,0.29,0.16),由此给出可能性等级结果为2级。采用相同的方法寻找训练样本构造模型,确定严重程度等级为2级,最终风险等级为中度(Ⅱ级)。
需要注意的是,在使用数据挖掘算法建模的过程中,选取训练样本时并不是完全随机的,而是在近年内施工状况相差不大的条件下进行选取。换句话说,训练样本需要与时俱进,那些年代较为久远、施工条件尚不成熟等的桥梁工程实例并不适合用来预测现在的桥梁施工风险。而且所选取的训练样本与预测样本越相似、数量越多,学习效果越好,获得的评估模型就越准确。
5 结论
(1)将数据挖掘技术算法与桥梁工程施工安全风险评估体系相结合,给出了一种比较准确的风险评估模型的建立方法,解决了利用既有工程数据确定风险指标权重的建模问题,并以某转体桥的满堂支架专项评估为例,得出该施工的风险可能性等级,证明数据挖掘算法可以很好地运用到风险分析的数据处理中,该方法为今后更深入地研究桥梁施工安全风险评估提供了一种新的思路。
(2)对桥梁风险评估体系的建立方法进行了新的探索,使用该方法可以根据实际情况进行相应的优化处理。比如数据组较大时或数据间的区分度不明显时,在选择属性上可以进行剪枝处理,能够极大提高构造器生成效率;又如工程实例中的改进方案,连续型属性阈值的选择规则采取适当的离散化处理,可以使训练模型具有更高的拟合性等。另外,上述的数据挖掘技术算法经编程语言实现后,通过程序找出影响风险评估的关键因素,有时这些因素之间会隐含某些易被忽略的、不易察觉的关系。
(3)利用数据挖掘技术的强大功能,可以把已有的桥梁施工安全风险评估信息进行数据处理后,建立数据仓库,运用数据挖掘工具发现里面的关联规则,进行分类、聚类分析,从而预测其发展趋势,为管理者提供可靠的风险管理依据。
