多源空间数据融合的城市人居环境监测模型与应用研究
2019-04-08武文斌何建军乔月霞
陈 婷,武文斌,何建军,乔月霞,刘 烽,文 强
二十一世纪空间技术应用股份有限公司, 北京 100096
人居环境监测作为城市人居环境建设与管理实践提升的基本,是目前人居环境研究落地的重点。有效地监测,必须通过高效的手段获取数据,进而研究监测指标与发展状况的关系,分析发展问题,判断发展趋势,进而提升城市管理水平。目前,我国人居环境监测的数据主要来自住房和城乡建设部编撰的《城市建设统计年鉴》和《城乡建设统计年鉴》,以及环境公报等基于城市(县城)和村镇进行的建设统计和环境监测评估[1-4]等的公开统计数据。然而,面对日益增长的城市发展需求,这种传统的统计数据来源在开展监测工作中会存在若干局限性,包括:更新频度较低,统计年鉴、年报的特质,多为每年一版;统计口径不统一,自下而上、层层上报的统计资料,容易造成各地区(城市)的标准尺度不一致,且缺少校验机制。因此,数据的时效性和准确性成为政府人居环境监测业务化的瓶颈。
伴随信息通讯技术的发展,互联网的普及和政务公开的有效推进,形成了大数据和开放数据组成的新数据环境,相较于传统调查统计数据,新数据具有高频的时空性,同时具有自下而上、覆盖面广、一致性程度高、粒度细致、可获得性强、易验证性强等特点,可有效改善传统数据在数据质量、更新频率方面的不足,给传统人居环境监测的更新乃至演替带来了可能。
卫星遥感数据观测范围大、综合、宏观,且信息量大、获取信息快速,为人居环境监测提供了数据源。但是如何自动、高效、准确的获取地表覆盖信息,实现业务化是当前的核心技术问题,同时,由于遥感数据仅能反映地表覆盖情况,部分人工信息无法通过影像直接反映,尤其是人居环境中最关注的建筑物信息,无法直接获取使用属性,限制了它在人文、社科类人居环境监测的应用。因此,本文提出利用遥感数据与互联网的兴趣点(POI, Point of interest)数据结合,建立自动、快速获取城市人居环境监测指标模型,选取典型居住社区进行精度和效率评价,并计算自然、社会经济类监测指标,应用于实验区的人居环境质量监测,为区域化、业务化开展人居环境质量监测提供依据。
1 城市人居环境监测模型
城市人居环境评价是由人居环境评价指标体系定量或定性描述来体现的,因此,城市人居环境质量监测应首先分析指标体系,选取主要指标开展长期监测。我国在人居环境评价指标体系方面尚无统一标准,通过分析中科院地理所发布的《中国宜居城市研究报告》、住房和城乡建设部发布的《国家园林城市评估指标体系》、全国绿化委员会和国家林业局发布的《国家森林城市指标体系》,可以发现,空间数据在设施、交通、生态环境、经济等方面指标均有优势,适合长期监测使用。其中,城市建筑物是城市人口、居住、经济的重要载体,成为人居环境评价指标体系的核心数据之一。道路是城市人群出行重要基础,便捷的交通能缩短居民居住区与各种设施之间的距离,从而反映人居生活的便利性。绿地是居住区内重要的自然要素,在改善环境质量、调节气候、消声吸尘方面有重要作用,是反映居住区人居环境质量优劣的重要组成。良好的水资源环境是城乡人居建设与发展的基本需求,因此,居住区的水环境和水资源成为人们选择居所的优选条件。因此,综合分析城市人居环境指标认为,建筑物、道路、植被、水体是人居环境质量监测的重要空间信息,也是城市人居环境监测指标的主要数据来源。
本文主要融合了互联网兴趣点数据(POI)和遥感影像数据,构建城市人居环境监测模型,包括两个关键环节,一是空间信息的自动获取,二是运用地理空间分析理论的城市人居环境监测指标计算。
1.1 空间信息自动提取算法
为准确提取城市地表信息,首先构建面向人居环境质量监测的地物特征空间,再将空间信息自动提取分为两部分:一是非建筑物信息的自动提取;二是建筑物的自动化提取。
绿地、水体、道路等地物的特征显著,差异性较大,可通过特征空间进行提取,其中的难点是特征阈值的自适应性问题,本文提出利用全局最优算法计算阈值,实现绿地、水体、道路提取。针对建筑物表面复杂性,特征差异不显著问题,为提高精度,提出使用POI点获取单体建筑物的样本,再根据特征空间,自动寻找相似对象组成建筑物空间信息。整体如下:
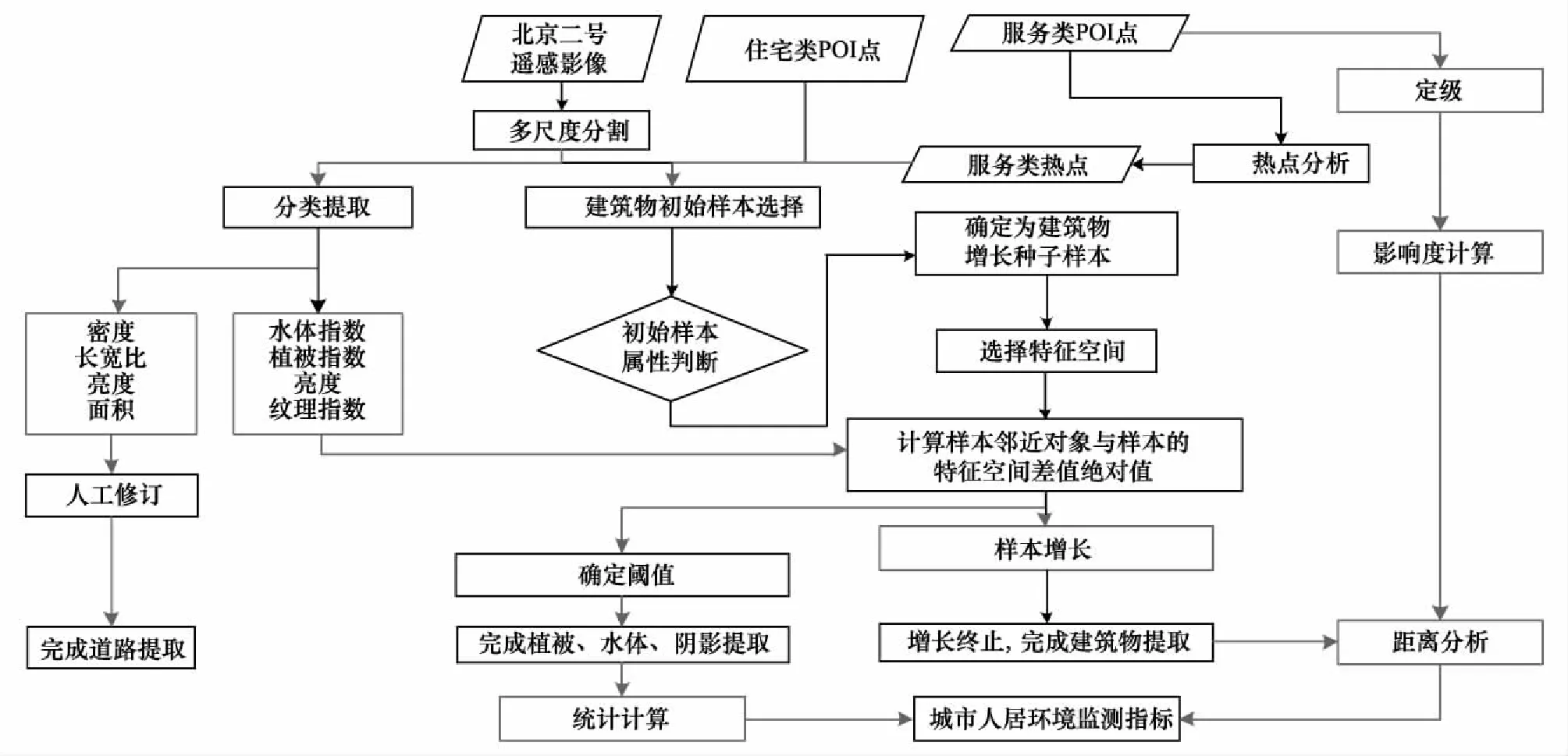
图1 城市人居环境监测空间信息自动提取模型Fig.1 Automatic extraction model of spatial information for urban human settlements monitoring
为了进一步分析人与经济、社会环境关系,本研究将人居的载体——建筑物,划分为居住区类和服务类建筑物。居住区类建筑物集合是城市人口居住的区域,在城市中相对独立的居住空间,有一定的建筑规模,并有与之相配套的公共设施以及室外绿化等,同时通过道路、建筑物等某类障碍与外界相隔并且区内建筑等景观具有形态上共性的区域。服务类建筑物主要指具有一定的社会、服务和经济功能的大型单体建筑物。
该模型中关于POI点的处理,是由于原始POI数据的类型较多,为了便于应用,将其进行归类。其中住宅区建筑物在POI数据中即为住宅小区类;服务类主要包括了餐饮、休闲娱乐、购物、学校、广场、医院等类型,集中多类型服务类POI点的区域,认为是大型单体建筑物,该类建筑物对周边居民的生活影响力较大,借助POI点辅助,根据POI点的标签,地理分布特征,基于地理分析中的热点分析,获得大型单体建筑物空间位置,为建筑物提取提供辅助信息。
1.1.1 特征空间构建
选择能够反映地物差异的主要特征参与面向对象分类对分类结果精度尤其重要。为了筛选有利于地表地物提取的特征构建特征空间,研究选取城市主要地物类型(公园绿地、建筑物、水体、裸地、道路)的样本对象,另遥感影像成像时,太阳光遇到不投光物体形成的暗区,包括建筑物阴影、树木阴影等也作为样本之一,统计光谱和纹理特征如图2,其中光谱特征主要包括各波段光谱均值(红光波段Mean_Red,绿光波段Mean_Green,蓝光波段Mean_Blue,近红外波段Mean_Nir)和所有波段均值(亮度Brightness),以及由波段运算取得的指数(归一化植被指数NDVI,归一化水体指数NDWI,比值居民地指数RRI、RMI),纹理特征主要通过灰度共生矩阵法计算方差、熵、同质性、异质性等[5](方差GLCM _StdDe、同质性GLCM_Homog、对比度GLCM_Contr、非相似性GLCM_Dissi、角二阶矩GLCM_Ang、熵值GLCM_Entro)。结果显示,建设用地与绿地在多个纹理特征指数上的特征曲线相近,难以区分,但在植被指数方面的差异显著;在光谱及纹理特征指数统计值上,建设用地与裸地较为相似;建筑物与道路在光谱和纹理特征上相似度较高,较难区分,需采用其他特征加以区分。因此,选择NDWI、NDVI、亮度指数初步区分水体、植被和建筑物,GLCM _StdDe区分水体和阴影时效果不佳,且计算耗时较高;考虑到建筑物与道路在形状类特征上的特点,增加密度(Density)、长宽比(Length/width)和面积(Area)区分道路与建筑物;阴影与水体在光谱和纹理特征上都没有明显区别,但建筑物阴影的形状较为方正,故采用矩形度区分阴影与水体。
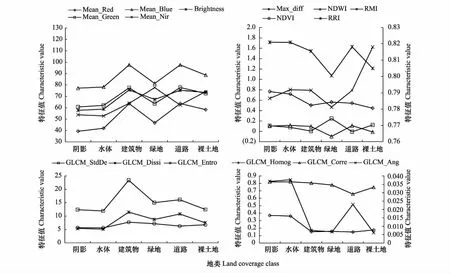
图2 各地类样本特征统计图Fig.2 land coverage type sample characteristic value line chartsMean_Red:红波段均值 Mean of red band; Mean_Green:绿波段均值 Mean of green band; Mean_Blue:蓝波段均值 Mean of blue band; Mean_Nir:近红外波段均值 Mean of near infrared band; Max_diff:最大差分值 the value of max difference; NDVI:归一化植被指数 Normalized difference vegetation index; NDWI:归一化水体指数 Normalized difference water index; RRI:比值居民地指数 Ratio resident-area index; RMI:比值水分指数 Ratio moisture index; GLCM_StdDe: 灰度共生矩阵的标准差 Standard deviation of gray-level co-occurrence matrix; GLCM_Dissi: 灰度共生矩阵的异质性Dissimilarity of gray-level co-occurrence matrix; GLCM_Entro: 灰度共生矩阵的熵Entroy of gray-level co-occurrence matrix;GLCM_Homog: 灰度共生矩阵的同质性Homogeneity of gray-level co-occurrence matrix; GLCM_Corre: 灰度共生矩阵的相似性 Correlation of gray-level co-occurrence matrix; GLCM_Ang: 灰度共生矩阵的角二阶矩Angular second moment of gray-level co-occurrence matrix
1.1.2 全局最优算法
分割后影像对象特征值均呈现连续分布特点,基本上符合数值的正态分布,故可通过确定直方图获得分类阈值。本研究利用全局最优算法,基于迭代的方式将两个或两个以上正态分布的概率密度函数做近似表示,每次都取其中最显著的波峰来划分区域,然后依据各个区域的平均值选择合适阈值,重复该过程直到阈值收敛[6]。算法实现如下:
遍历对象读取特征值,获得最小特征值T1以及最大特征值T2,设定初始阈值T(0),T(l) = (T1+T2) / 2;根据阈值T(k),统计大于或小于该阈值的所有对象特征值,再次计算出此区间内的最大值和最小值,再计算均值T(k+1),计算△T,迭代上述过程,直到△T为0。公式如下:
T1=Min(T)
(1)
T2=Max(T)
(2)
T(k)=(T1+T2)/2
(3)
△T=T(k+1)-T(k)
(4)
式中,T1为最小特征值;T为指定类别对象的特征值集合;T2为最大特征值;T(k)为本次特征阈值;△T为相邻两次阈值偏差值。
1.1.3 区域生长算法
建筑物的提取一直是高分辨率遥感影像提取的热点,高精度、自动化获取其分布也是遥感产业应用的难点。目前,利用遥感数据进行建筑物信息提取的研究众多,主要分为两类:一是以数据或特征驱动的方法,例如:基于几何边界的方法[7-9]、基于区域分割的方法[10-11]和基于辅助特征或辅助信息的方法[12-15];二是从建筑物模型驱动的方法,例如:基于语义模型分类的方法[16-17]、基于先验知识模型的方法[18-19]和基于视觉认知模型的方法[20]。建筑物模型驱动方法在面对先验知识不足情况下的多样性人工建筑物目标识别方面精度无法达到预期,成为其发展的主要问题;数据或特征驱动是目前研究最多且获得较好结果的方法,尤其是基于区域分割理论,结合特征、上下文语义关系的面向对象识别,成为工程化、专业化遥感信息提取的发展方向。因此,本研究提出利用面向对象区域生长算法,实现自动化、工程化的提取城市建筑物,并结合POI信息,提高识别精度,增加建筑物的使用属性。
区域生长算法最早由Levine等学者提出[11],该方法由于其速度快、针对性强、可交互等特点得到了广泛应用[22]。算法的核心是种子的选取、相似区域的判定准则和终止条件,种子的选择可以人工和自动两种方式实现,但其准确度对结果影响较大;相似区域的判定准则一般通过特征值小于某个阈值来表示。针对对象的区域生长,是在影像分割的基础上,依据同一目标物体的同质性来依次归并对象[23],以某个对象区域为初始种子区域(x0,y0),从邻域对象(x,y)颜色、平均灰度值、纹理等信息上度量相邻对象的相似性,本研究采用欧几里得距离(见公式(5)(6))计算相似度,将种子区域与目标区域之间满足相似度条件的对象合并,再以合并后的对象为新的种子区域,重复上述操作,进行8邻域生长,最终形成具有相似特征对象的最大连通集合,完成区域增长,达到目标地物识别提取的目的。
区域生长从初始种子点开始,按照生长准则查找与之相符的像素点归并到初始种子点,直至满足条件。本研究通过POI获取初始种子对象,保证所有的种子对象都为建筑物本体或周围一定范围内,建筑物样本生长终止条件是道路。主要分为6个步骤:
(1)对所有对象特征向量中特征值标准化Xi;
(5)
(2)对对象集顺序扫描,找到第i个还没有归属的对象,设该对象为X0;
(3)以X0为中心,计算它与邻域对象特征向量X的距离Di,如果距离满足生长准则,就将他们合并在同一区域内,同时将其压入堆栈;
(6)
(4)在堆栈中取出一个对象,把它作为X0,返回到步骤3;
(5)当堆栈为空时,返回到步骤2;
(6)重复步骤2—5直到所有对象都有归属,生长结束。
1.2 人居环境监测指标计算
人居环境质量监测指标主要通过地理分析的方法获得[24],从地理分析方法层面,将指标分为密度类、距离类指标计算。
据《中国储运》记者查到的更多的披露信息显示,阿里将设立一家控股公司,作为本地生活服务的旗舰公司,并已收到来自阿里集团和软银集团等投资者的超过30亿美元投资承诺。
1.2.1 密度计算
自然环境类指标主要通过密度计算实现,对空间上各类地表覆盖物占比,或其他社会经济属性占地表覆盖范围的比例。包括:绿地覆盖率、建筑密度、容积率、人均绿地占有率和人均土地使用率等,该类指标的快速监测有利于对社区的自然资源改造和生态环境建设评估与规划。其计算公式为:
(7)
式中,Gi为某类指标占比结果,Si为第i个区域的占地总和;Sij为第i个住区内的建筑物面积或社会经济统计结果。
1.2.2 距离计算
社会服务类指标主要通过距离计算获得,例如服务类建筑物对住宅小区居住人群的生活、教育、医疗等的满足程度,主要通过空间缓冲区分析,来反映各实体对其邻近住宅的影响程度,依据缓冲主体的几何形态,分为点、线、面缓冲区分析。实际指标计算中,应首先建立等级,进而根据等级科学的计算不同形态主体的影响度。以医疗设施影响度为例,社区内的医院,将按照医院等级进行划分。根据不同等级设施面积中位数,利用最大标准化方法确定设施综合规模指数。现实生活中,影响度随着距离中心越远,影响度衰减,因此,本研究选择指数模型进行缓冲区分析[25]。公式为:
(8)
(9)
式中,Fi为主体对邻近实体的实际影响程度;f0为主体自身的综合规模指数;di为邻近对象离开主体的实际距离(欧式距离);dmax为主体对邻近实体的最大影响距离。
(10)
式中,最大影响距离依研究区面积S,研究区内及周边的j等级以及以上等级的基础设施数量n,计算j等级基础设施的最大影响距离dmaxj。
2 结果与精度评价
2.1 实验区与数据
本研究选取北京市北部的回龙观社区作为实验区,回龙观社区是一个具有850万m2的超大规模社区,常驻人口达到30万人,被公认为亚洲第一大社区,可以作为一个居住环境监测的典型。
针对社区级监测,建议采用高分辨率遥感影像进行信息提取,本研究选用北京二号遥感数据。北京二号卫星星座,于2015年7月11日搭载印度极轨卫星运载火箭发射升空,星座由3颗第三代灾害监测星组成,卫星运行高度647 km,倾角97.8°的太阳同步轨道,搭载1 m全色与4 m多光谱成像仪。对数据进行了“配准、融合、正射纠正、增强”处理。其中,配准采用自动配准;融合采用Pansharp法对全色和多光谱波段进行融合;正射纠正通过读取rpc文件、选择有理函数模型、借助数字高程模型,选择控制点进行正射纠正,完成数据处理。
2.2 结果与精度
利用北京市回龙观社区的北京二号遥感数据和POI点数据(如图3),首先通过POI点聚类,提取服务类建筑物分布区域以及重新生成聚类中心点(FOI);将遥感数据、服务类建筑物分布矢量、聚类中心点(FOI)参与数据分割;基于本研究所构建的模型,选取分割尺度30,形状参数0.1,紧致度参数0.5,构建NDVI、NDWI、亮度、面积等特征空间,自动确定阈值,提取大型社区的建筑物、道路,以及绿地和地表水体(如图4)。

图3 2018年4月2日北京二号遥感影像和感兴趣点数据 Fig.3 Beijing-2 remote sensing image and Point of interest (POI) data April 2, 2018

图4 回龙观社区地表覆盖自动提取结果图 Fig.4 The result of automated land coverage extraction of Huilongguan community
为了检验该方法提取结果的精度以及提取效率,随机选取每个地类的100个图斑,与实际地物边界对比,建立混淆矩阵,计算提取精度(表1)。本研究对比人工目视解译上述四类要素需要4 h,而本文方法分割过程2 min,分类、聚类等处理需要10 min,人工修订1 h。
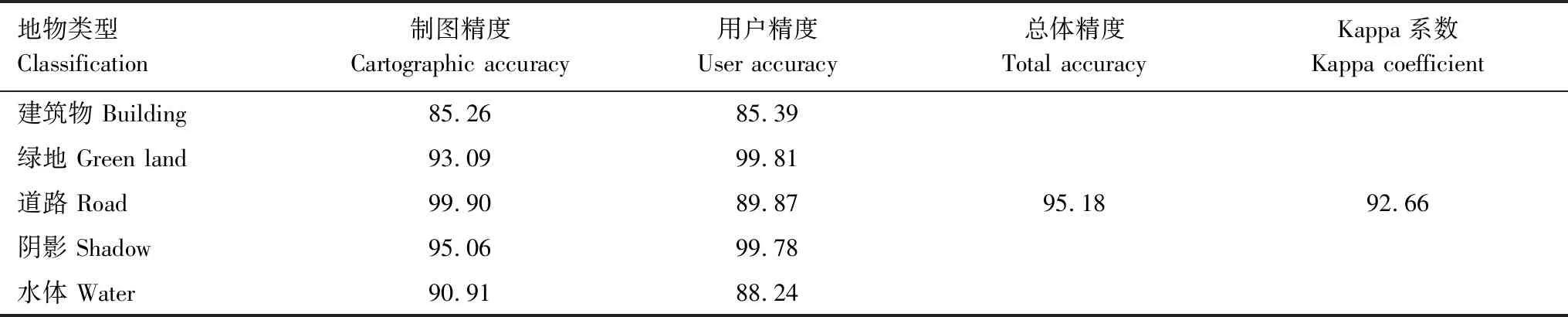
表1 回龙观社区信息自动提取结果精度评价表/%
由结果精度可知,本研究所用方法的用户精度和制图精度均高于85%,总体精度超过95%,kappa系数超过92%,说明识别精度很高而且可信,从效率角度分析,提升了2.3倍。综合上述信息提取结果,认为该方法适合工程化、区域化监测使用。
3 人居环境指标监测分析
社区的人居环境监测、评价重点围绕物质环境的舒适度、健康度、便利度以及非物质环境的人文性、社会性等方面,这些指标的监测可通过居住地周边的服务设施、自然环境以及配套环境的计算获得,北方地区受季节影响,生态环境变化显著,因此通过高频的地表覆盖信息计算居住环境质量指标,为社区的自然资源改造和生态环境建设评估与规划提供依据。从服务类行业的影响度分析,增加互联网数据提供的信息,可以明显提高监测频率与正确性,使人居环境质量监测更有时效性,有利于指导人们选购房产,也为政府的社区规划与管理提供帮助。本研究以回龙观社区的部分小区为例,将前述的空间信息与POI点信息结合,利用地理分析方法,对自然环境类与社会服务类指标进行计算,为人居环境监测的常态化提供依据。
比较回龙观15个小区的绿地覆盖率、建筑密度和容积率(表2)可知,绿地覆盖率高、建筑物密度低和容积率低的小区是北店嘉园小区,而且从数据可知,回龙观社区中大部分小区的建筑物高度相近,而且内部生态系统以植物环境为主,缺少水环境,生物多样性不足,从舒适度、自然环境角度,整体设计缺乏个性化和生态化。
比较回龙观社区各小区受周边服务类影响程度(表2),各小区差异性较大,龙禧苑二区距离周边的大型综合性商场较近,综合得分最高;社区医疗水平总体偏低,各社区得分均不高,相较而言,龙腾苑二、三区距离稍近;社区公立中小学共有四所,从整个社区分析,主体教育资源也相对缺乏,龙跃苑周边的中小学相对较近。通过计算各辐射类行业对小区的影响度认为,回龙观地区的商业发展比较快,包括大型商场、超市、餐饮、娱乐等,使各小区居民的生活便利性和舒适性较高,但是教育和医疗资源相对缺乏,尤其是大型的、公立的教育和医疗资源比较匮乏,有待提高。
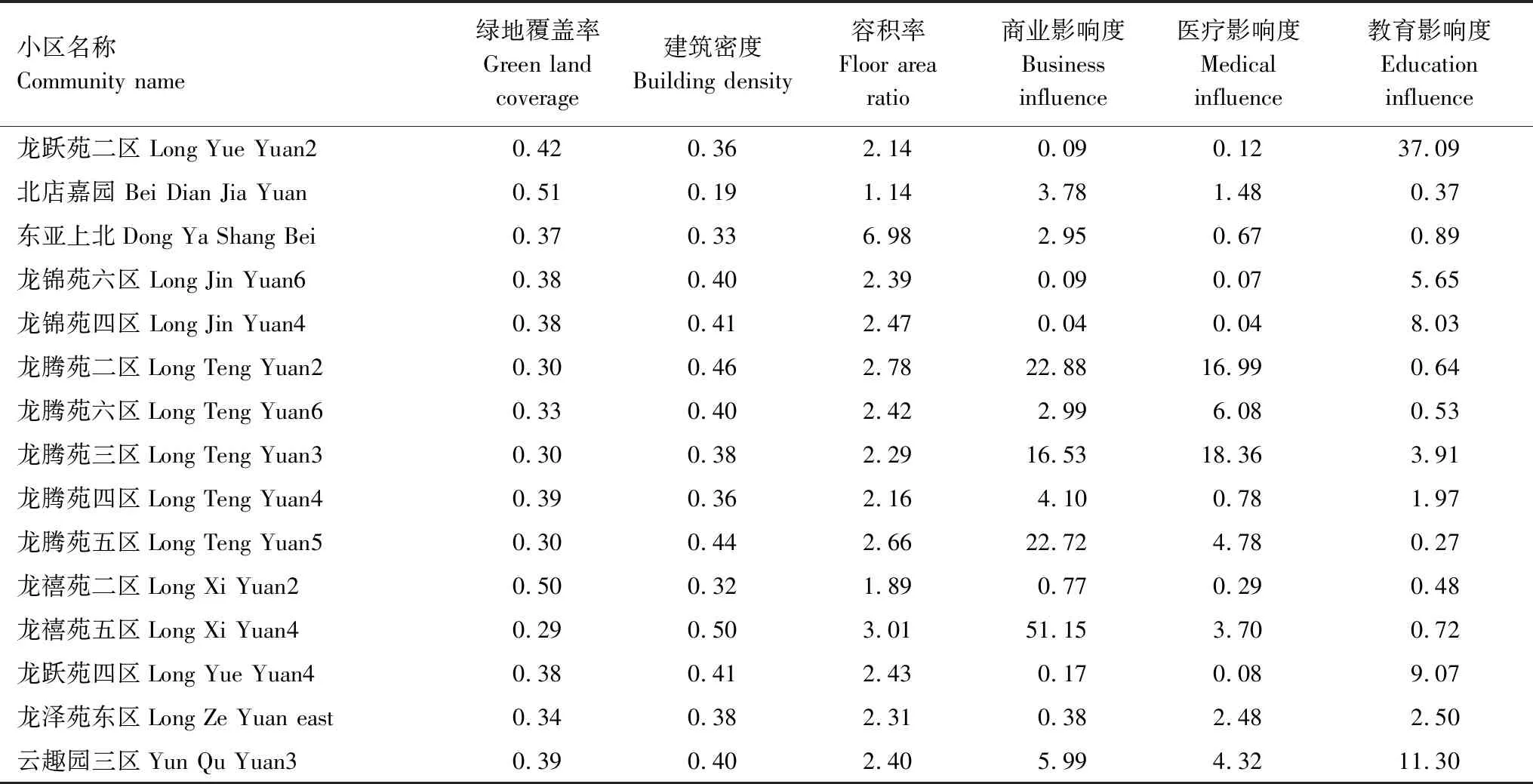
表2 回龙观15个小区的人居环境监测指标值
4 结论与讨论
(1)本文构建了城市人居环境监测模型,该模型包括两个关键环节,一是构建自动化提取建筑物算法,该算法通过建立地物特征集,以POI点对应样本为种子,利用全局最优和区域生长算法,自动提取城市建筑物,再利用全局最优算法确定其他地类的阈值;二是人居环境指标计算,将建筑物、绿地、水体信息提取结果与POI数据结合,利用密度类与距离类空间分析算法,分别计算自然、社会经济类指标。
(2)以北京北部回龙观社区为例,利用2018年4月的北京二号遥感影像和POI点数据进行实验验证,总体精度超过95%,Kappa系数超过92%,效率提高2倍多,认为该方法精度和效率高,适合推广应用。监测人居环境质量,根据计算结果分析,认为回龙观社区大部分小区的建筑物密度不高、服务设施齐全基本满足居民生活需求,但是也存在缺少水环境、教育和医疗设施的问题。
(3)本文在信息的自动获取方面显著提高了效率和精度,但评价指标方面,只选取了部分客观指标进行了监测,缺少空气、声环境质量乃至社会性环境要素,没有形成综合评价分析,下一步将扩展互联网数据在空气质量、声环境、人文、社科类的评价应用,并结合多种互联网数据进行满意度评价,增加主观评价数据获取方法,完善整体人居环境质量监测业务化技术体系。
