新时代背景下环境保护政策对雾霾防治的效应分析
——基于PM2.5浓度变化视角的实证研究
2019-04-08张立文程东坡许玲丽
张立文, 程东坡, 许玲丽
(1. 上海财经大学 统计与管理学院,上海 200433; 2. 上海大学 经济学院,上海 200444)
一、引 言
量化评估政府相关环境政策效应,并以此为依据实现雾霾治理政策的调整与再实施,已经成为目前政府和社会各界共同关心的重要课题。改革开放以来,中国在实现经济高速发展的同时出现了大气环境恶化问题。2013年以来,雾霾在全国各地频繁爆发甚至规模较大,引起全社会的广泛关注。虽然经过各级政府的多方治理,但环境问题依然严峻,已经成为影响国计民生的重大问题。以PM2.5为首要污染物的雾霾污染不仅影响了人们的日常生活与健康,而且对我国社会经济产生诸多负面影响。环境恶化问题已经成为中国吸引海外资本和国际人才的一大障碍,对发展旅游服务业也存在不利影响。因此,环境问题的负外部性影响远超经济利益损失本身(陈诗一和陈登科,2016)。我国正处于经济转型的关键时期,党的十八大以来环境保护被推上新高度,大气污染防治成为重中之重。十八大之后我国开启了保护环境、谋求绿色发展的新篇章:从《大气污染防治行动计划》到《中华人民共和国环境保护法》的修订,再到《中华人民共和国大气污染防治法》的修订,这一系列政策法案的出台为环境保护与大气污染防治工作提供了重要依据与操作指导。五年间,大气环境质量得到明显的改善和提升,如产业、能源和交通这三大重点领域结构得到优化,大气污染防治的新机制基本形成。在党的十九大会议上,中央对大气污染防治提出了更高的要求,习近平总书记在报告中明确提出要着力解决突出环境问题,并指出要“持续实施大气污染防治行动,打赢蓝天保卫战”。近年来,各级政府从财政补贴到立法保障,大气污染治理的投入巨大。环保政策实施效果,将影响政策目标的实现。因此,了解相关政策实施效果过程中可能存在的问题及实际政策效果,有助于对相关政策作出合理调整与再实施,这有利于最大程度地提升相关政策实施的有效性,并降低政府治理污染的经济成本,从而实现相关治理目标。有鉴于此,如何量化评估环境政策效应,动态调整环境政策,实现环境长效治理目标,是本文尝试回答的核心问题。
现有文献对于雾霾的研究主要集中在以下几个方面:雾霾的危害(张燕萍等,2007;谢元博等,2014;崔亮亮等,2015;Lee等,2014;Gao等,2016)、雾霾的成因(何小钢,2015;李云燕等,2016;Zheng等,2016;张立辉等,2016;吴建南等,2016)、雾霾的防治(温晋锋和王赟,2016;李永友和文云飞,2016;岳利萍和马瑞光,2016)以及雾霾主要污染物PM2.5的预测(彭斯俊等,2014;胡玉筱和段显明,2015;戴李杰等,2017;Zhou等,2014;Yu等,2016;Wang等,2017)。研究宏观环境政策对雾霾防治影响的文献则不多,政策评估中研究方法是难点,本文主要采用机器学习方法进行研究。现有文献对政策效应的研究方法,主要有双重差分法(DID)(赵绍阳等,2014;王兵等,2017;石庆玲等,2016)和合成控制法(SCM)(刘甲炎和范子英,2013;陈晔婷等,2016;黄启才,2018)。两者都是基于自然试验条件的假设,研究适用全国的环境政策显然已经不满足于“自然试验”条件。机器学习方法的优点是可以放松“自然试验”条件,可以从预测角度量化环保政策对雾霾防治的影响,为研究不满足自然试验条件的政策效应研究提供可能,因此对本文的研究是比较合适的研究方法。
本文以北京、兰州、天津、太原四个城市的雾霾首要污染物PM2.5浓度为研究对象,采用时间序列算法建立PM2.5的预测模型,通过基于历史数据预测“如果没有中共十九大政策影响(以下称为“政策缺失状态”)”的潜在PM2.5浓度(即政策评价中的反事实状态),然后将其与实际的PM2.5浓度进行对比,二者之间的差值即反映出政策的实施效应。因此,本研究的关键工作便是如何科学准确地基于历史数据来预测政策缺失状态下的PM2.5浓度。本文在研究方法上,采用传统的ARIMA和HW时间序列模型以及机器学习算法RF和Prophet,建立PM2.5浓度的预测模型,通过模型优越性对比,选择表现最佳的Prophet模型进行样本外预测。本文的研究结果表明,中共十九大一揽子环保政策对雾霾防治的正向作用明显。本文进一步考察中共十九大政策效应的区域异质性,探讨了政策执行过程中的“两会蓝”现象及政策乏力问题,根据实证研究结果,本文最后给出相应的政策建议。
本文的研究贡献主要体现在以下两个方面:(1)丰富了雾霾主要污染物PM2.5浓度的预测研究。现有文献从雾霾成因角度建立PM2.5浓度的预测模型,往往不能很好地解决内生性问题,本文采用机器学习的时间序列预测方法,可以很好地缓解内生性问题。(2)拓展了政策效应的研究,为我们在研究条件不满足“自然试验”的情况下提供了新的研究思路。
其他部分的内容安排如下:第二部分是文献综述;第三部分是相关理论基础;第四部分介绍样本数据和研究的设计思路;第五部分进行实证研究,并对实证结果进行政策分析;最后是对全文的总结并提出政策建议。
二、文献回顾
(一)雾霾的危害、成因、防治研究
雾霾给国家和人民的生产生活带来了较大的负外部性。在此背景下,国家投入大量的资源用于雾霾研究,期望通过相关研究成果指导雾霾防治。雾霾的主要污染物是可吸入颗粒物PM2.5,由于PM2.5的颗粒物直径小,活动范围广,且易于吸附有毒或有害物质,会对人体健康造成极大的危害。研究表明,雾霾颗粒物会严重破坏人体呼吸系统功能(谢元博等,2014;崔亮亮等,2015;Fang等,2016;Gao等,2016),诱发心脑血管疾病(杨海兵等,2010;孙兆彬等,2016),造成新生儿先天缺陷(Bell等,2007;王玲玲等,2016;冯仁杰等,2017),同时还会削弱人体免疫系统(Lee等,2014)。统计数据显示,雾霾对我国经济造成严重的影响,导致经济下行压力加大(王桂芝等,2016)。因此,雾霾成因研究以及基于成因进行雾霾的有效防治研究成为诸多学者关注的焦点。现有文献主要从两个角度探究雾霾成因:一是从政府角度探究。研究表明,政府不合理的经济结构和产业布局,是北方地区雾霾高发的根本原因(何小钢,2015;石庆玲等,2016;李云燕等,2016;冷艳丽和杜思正,2015)。二是从能源结构、工业聚集和轨道交通等角度探究(席鹏辉和梁若冰,2015;于文金,2016;吴建南等,2016)。在采取源头减排的环境政策下,我国雾霾防治已经取得了阶段性成果,但形势依然严峻。为进一步提高雾霾防治的效果,一些研究关注了政府现行政策以及企业的排污行为(周景坤和杜磊,2015;温晋锋和王赟,2016),希望能通过源头减排和末端治理并举,发挥市场机制(岳利萍和马瑞光,2016;李永友和文云飞,2016)的作用,提高防控效果。
综上所述,当前学者对雾霾的研究主要集中在雾霾的危害、成因以及监管等方面,很少有学者研究全国范围的政策效应。本文从预测的角度研究全国范围内的环境政策效应是一种新的尝试。
(二)PM2.5的预测研究
预测是一项数据科学任务,是组织内部许多活动的核心。例如跨行业的部门必须进行目标规划,在资源约束条件下有效地分配稀缺资源。由于PM2.5浓度影响因素的复杂性,准确预测PM2.5浓度一直是一种挑战。现有文献中提出的预测模型大致分为两类:第一类是单一预测模型,第二类是混合预测模型。单一预测模型主要有线性回归模型、时间序列、灰色模型、贝叶斯等传统方法以及支持向量机、神经网络等算法为主导的人工智能方法。已有大量文献运用ARIMA和MLR等线性模型对空气污染物(PM2.5和PM10)浓度进行预测(胡玉筱和段显明,2015;彭斯俊等,2014;王勖之等,2017;Elbayoumi等,2013)。当空气污染物浓度序列是线性时,ARIMA和MLR预测结果具有更高的可靠性和可解释性,但其局限性在于过度依赖这种线性映射能力。实际上,污染物时间序列大多是非线性、非平稳和不规则的序列。为了克服线性模型的缺点,ANN等人工智能算法被广泛应用于预测颗粒物浓度(戴李杰等,2017)。但是,人工智能模型也有其局限性,诸如神经网络模型容易陷入局部最优和训练过度,而支持向量机对参数选择比较敏感。为了提高模型的预测性能,近年来越来越多的学者尝试使用混合预测模型以提高预测性能(Díaz-Robles等,2008;Lin等,2011;Perez,2012;Antanasijević等,2013)。随着“分解和集合”的思想得到发展,该思想逐渐被运用于时间序列预测(Yu等,2016)。这种方法可以弥补确定性模型和统计模型的缺点,学者已经证明“分解—集合”方法用于时间序列预测的有效性,由此PM2.5浓度的预测精度大大提高(Zhou等,2014;Yu等,2016;Wang等,2017)。
上述研究都是采用离线的处理方式,然而,PM2.5预测和股价预测、天气预测、交通流量预测等一样,时间序列数据往往以数据流的形式贯序到达,且数据的潜在分布和变化趋势随时间不断发生变化,在此情形下,能够捕捉序列变点的非线性时间序列模型更适合处理这些非平稳时间序列预测问题。先知(Prophet)模型是Taylor和Letham(2018)提出可以捕捉序列变点的一种大规模时间序列数据预测算法。Taylor和Letham(2018)运用Prophet模型对脸书(Facebook)事件(events)平台话题数量进行预测分析,相比ARIMA、指数平滑法以及随机森林模型具有更快的拟合速度和更好的预测性能。本文将采用Prophet模型对PM2.5颗粒物浓度进行预测。该模型是数据驱动研究政策效应的一种方法,没有传统模型需要考虑的内生性问题,可以为政策效应的研究提供新的思路。
三、理论模型
自回归移动平均模型(ARIMA)和三次指数平滑法(Triple/Three Order Exponential Smoothing,Holt-Winters)是以随机理论为基础的时间序列方法,当所研究序列服从线性关系时,其预测结果具有可靠性和可解释性。本文首先采用这两种传统方法进行PM2.5的预测。但ARIMA和HW方法过于依赖线性映射能力,本质上属于线性模型。考虑到实际中PM2.5的序列可能是非线性、非平稳和不规则的序列,本文进一步利用随机森林(RF)算法,克服序列的非线性问题。由于PM2.5的数据往往以数据流的形式贯序到达,数据的潜在分布和趋势可能不断发生变化。在此情形下,能够捕捉序列变点的非线性时间序列模型更适合处理这些非平稳时间序列预测问题。本文使用先知Prophet模型进行预测分析(Taylor和Letham,2018)。
Prophet模型是一种应用场景丰富的通用模型。与传统模型相比,Prophet模型更加简单、灵活并能获得优良的预测结果。模型如下①ARIMA·HW和RF算法结果将用于比较分析。:

模型整体由三部分组成,增长趋势、季节性趋势、节假日模型对预测值的影响,ϵt是噪声项,表示模型未预测到的波动,这里假设ϵt是高斯分布。
(1)增长趋势。增长趋势是整个模型的核心组成部分,它表示整个时间序列是如何增长的,以及预期未来是如何增长的。这部分有两种可选择模型:非线性增长和线性增长。非线性增长的公式采用分段的逻辑回归模型:
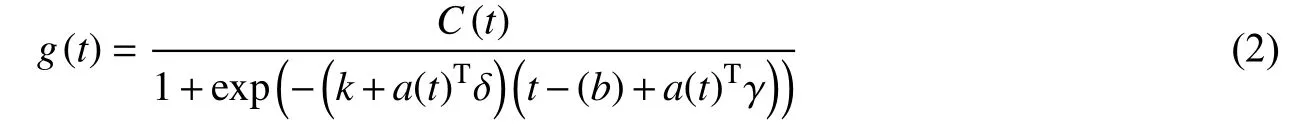
其中C(t)为承载能力,其定义了所能增长的最大值,k、b分别表示原始增长率和原始偏移量。Prophet模型首先定义了增长率k发生变化的点,称为变点,用sj(j=1,2,…,S)表示,每个变点相对应的斜率调整值为δj,其中S表示变点的个数。δ=(δ1,δ2,…,δS),aj=I(t≥sj),a(t)∈{0,1}S,其中I为示性函数,当t≥sj时取1,反之取0。每个变点对应的增长率为k+a(t)Tδ。调整原始增长率k后,偏移量b也要相应调整为b+a(t)Tγ,其中γ为变点的调整。线性增长模型为:
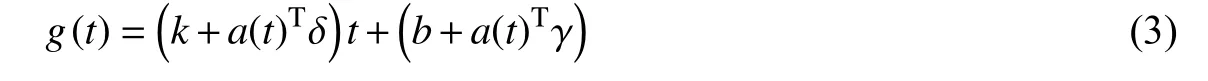
(2)季节性趋势。时间序列中可能包含多种周期类型的季节性趋势,Prophet模型利用傅里叶级数近似表达周期属性,公式如下:

其中P表示固定的周期(年、月、周、日、小时等)。令s(t)中的所有季节性时间序列模型组合成向量X(t),最终的季节性模型为:

其中,β~N(0,σ2),以提高季节性模型的平滑性。
(3)节假日模型。节假日或者一些大事件都会对时间序列造成较大影响,而且这些点往往不存在周期性。一些时候这些点甚至比常规点更重要。节假日模型将不同节假日在不同时点下的影响视作独立。考虑到节假日应该有一个时间跨度,因此为每个模型设置了时间窗口,并将模型统一窗口期中的影响设置为相同的值。用i表示节假日,Di表示窗口期中包含的时间t,则节假日模型h(t)可表示为:

其中,ki表示窗口期间假期对预测值的影响。
Prophet模型的优势是可以分别得到例如趋势、周期、假日效应,以及一些异常值。在趋势方面,它支持变点选择,实现分段线性拟合。在周期方面,它使用傅里叶级数来建立周期模型,在节假日和紧急情况方面,可以通过表格以及之前和之后的相关N天来指定假期。考虑到PM2.5数据的非线性、非平稳性和不规则性,以及数据的分布和变化趋势随时间变化等性质,运用Prophet模型刻画数据更为合适。
四、样本数据和研究设计
(一)研究区域和样本数据
本文选取2014年1月至2018年8月北京、天津、太原、兰州四个城市PM2.5浓度月度平均数据作为研究样本,分析中共十九大一揽子环境政策对PM2.5防治的效果。北京、天津、太原、兰州这些省会城市,经历了城市化的快速发展,城市人口、能源消耗、机动车辆增加,形成了大气污染加剧的局面(Marshall等,2008;Zhang等,2012)。自2013年以来,雾霾污染在全国大范围爆发,主要集中在北方城市。本文选择北京、兰州、天津和太原四个省会城市,主要基于以下两个原因:一是考虑到中共十九大政策的影响范围;二是考虑到不同地区的地理位置,不同地区的地形、气候条件各不相同,选择跨度较大的四个城市也有利于说明模型的稳定性以及研究的可靠性。PM2.5数据来源于中国环境监测总站(http://www.cnemc.cn)。中国国家环境监测中心每月发布每个城市的PM2.5数据及监测报告。四个城市PM2.5浓度的月度平均数据手动获取。
本文的数据集划分如下:训练集为2014年1月至2017年6月测试集为2017年7月至2017年9月。政府2014年1月至2017年4月期间发布了一系列环境政策,形成了一个较为完善的环境治理体系;2017年5月至中共十九大召开前,政府并未进一步推出大气环境治理政策。因此,以2017年6月作为时间节点划分数据集。本文所有实验均在Python3环境下完成。
(二)研究设计思路
本文研究步骤如下:(1)从中国环境监测总站搜集北京、兰州、天津、太原四个城市2014年1月至2018年8月的月度数据。(2)分别建立ARIMA、HW、RF以及Prophet算法的时间序列预测模型。(3)进行模型的对比分析,选择最优模型。(4)基于最优模型建立时间序列算法,建立PM2.5的预测模型基于历史数据预测如果没有中共十九大政策影响(以下称为“政策缺失状态”)的潜在PM2.5浓度(即政策评价中的反事实状态),然后将其与实际的PM2.5浓度进行对比,二者之间的差值即反映出政策效应。(5)进行政策评价和异质性分析。
五、实证结果及其分析
(一)描述性统计分析
四个城市的PM2.5月度平均浓度变化曲线如图1所示。从图1可以看出,PM2.5浓度在不同的城市变化趋势大致相同,但绝对水平上有显著差异。PM2.5浓度变化具有较为明显的季节性,进入冬季供暖时期,PM2.5浓度逐渐增加。其中北京市在中共十九大后的冬季供暖期,PM2.5的浓度变化异常,供暖期过后,PM2.5浓度不降反升。表1对四个城市PM2.5浓度变化的数据特征进行概括。根据表1,可以看到,在四个城市中,PM2.5浓度水平有较大差异,地理位置越靠近西部地区,PM2.5浓度水平越低。
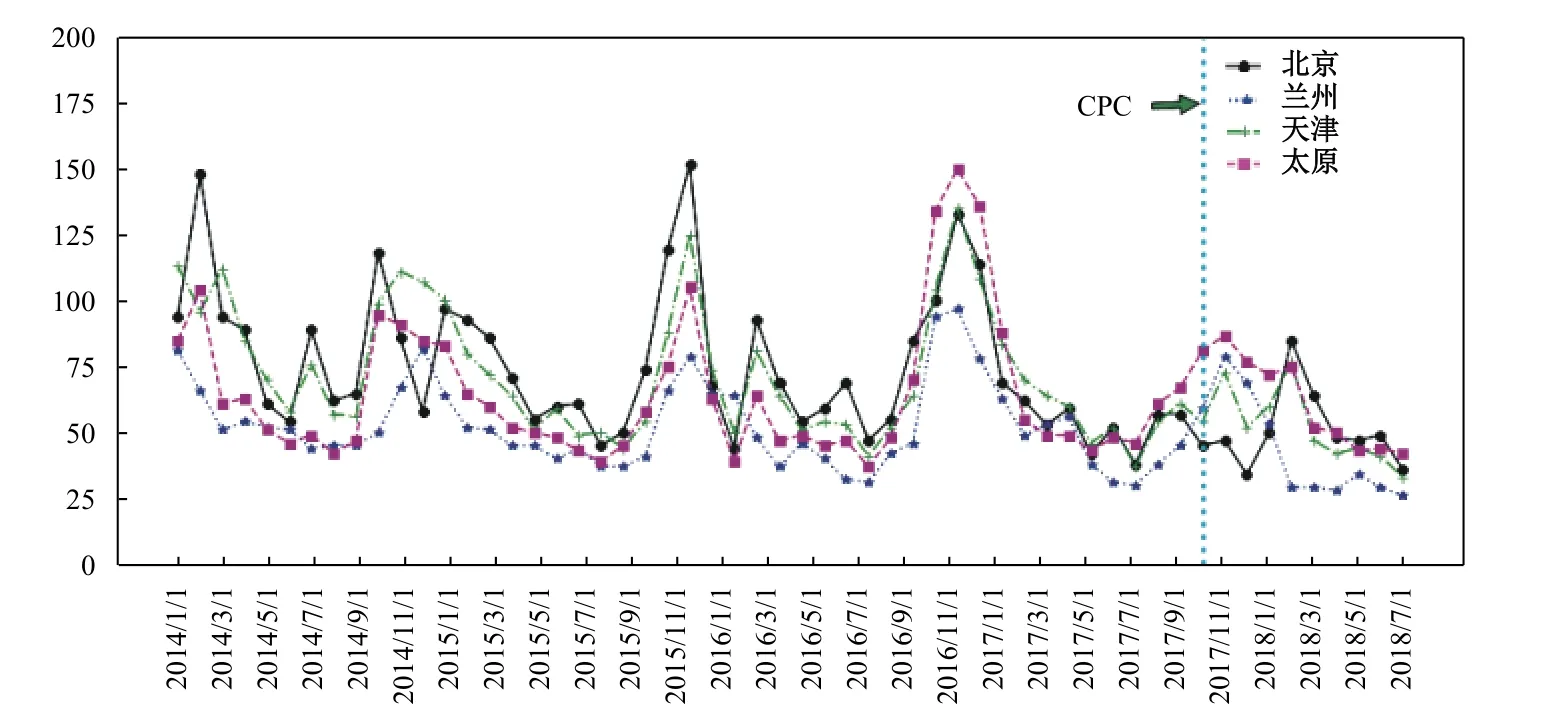
图1 四个城市的PM2.5月度平均浓度走势图

表1 四个城市PM2.5浓度变化的数据特征
(二)评价准则
我们通常使用平均相对误差(MAPE)作为评价指标,来看预测值靠近观测值的程度,从而对模型的表现进行评价。用yt表示观测值,表示t时刻的预测值,表示观测结果的均值。评价标准MAPE度量和之间的相对误差。定义如下:
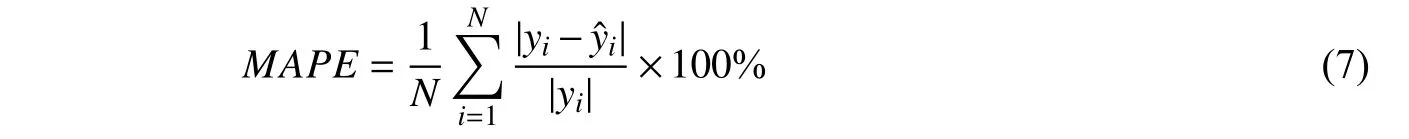
(三)预测结果和讨论
1. 模型比较与模型选择
基于PM2.5浓度月度数据以及影响因素的复杂性,本文分别选择差分自回归移动平均模型(ARIMA)、三次指数平滑(HW)以及随机森林算法(RF)建立PM2.5浓度变化的预测模型。ARIMA和HW算法是时间序列预测的经典算法,在金融领域具有广泛的应用。当所研究的序列是线性时,ARIMA和HW预测结果具有更高的可靠性和可解释性,但其局限性在于过度依赖这种线性映射能力。因此,本文在传统时间序列预测方法的基础上选择常用的机器学习随机森林算法(RF)以及Facebook开源的时间序列Prophet模型,解决数据序列的非线性问题。
实际运用中,HW算法的精度非常依赖于参数的选择。现有文献大多数使用经验给定的参数范围,通过格子点搜索法选择最优参数。本文使用改进的HW算法,通过格子点搜索法在拟合结果最优以及接近的最优参数中,选取一组预测效果最好的参数。对于β与γ,本文采用了0到1之间,50等分的格子点。对于α,由于α≠0,本文选用了0.01到1之间,50等分的格子点。文中使用训练集和测试集的MAPE指标来判断拟合效果与预测结果的优劣,然后选择拟合效果最好的5%参数组作为备选参数,再通过判断备选参数的预测效果,选择一组拟合效果最好的参数。为了使模型具有更好的预测性能,本文采用格子点搜索随机森林的最小叶子结点、树的棵树以及随机森林使用特征的最大数量,同时采用五折交叉验证,对训练数据进行训练,建立PM2.5浓度预测的随机森林模型。表2给出了各个模型对四个城市PM2.5浓度的预测表现。
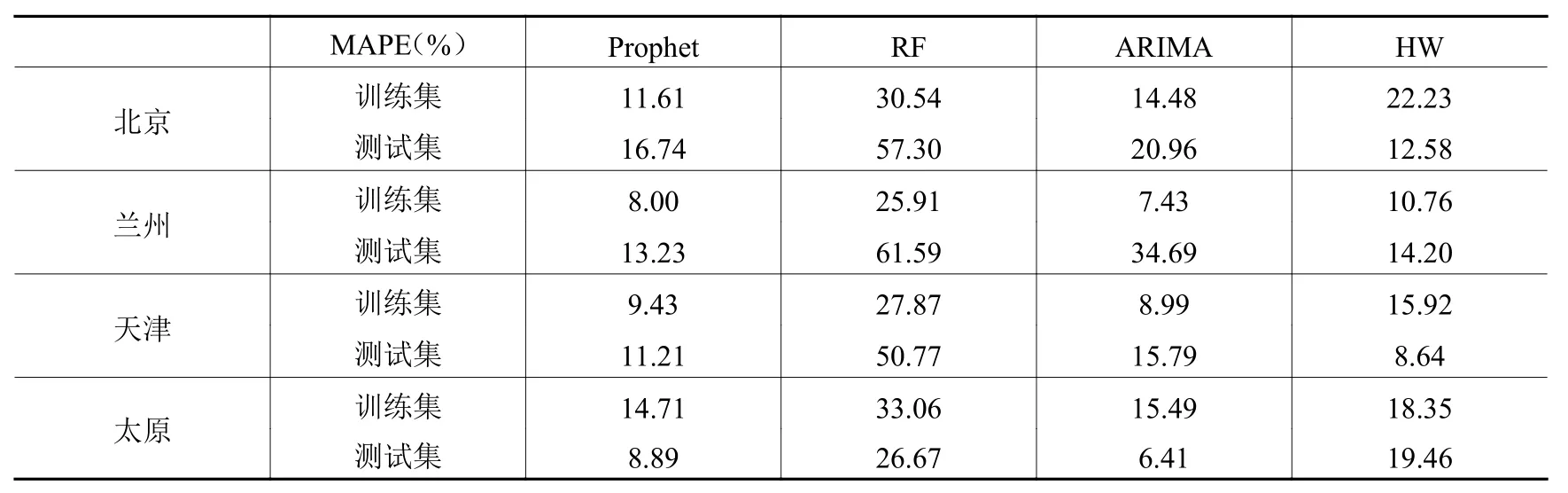
表2 各模型对四个城市PM2.5浓度的预测表现(MAPE)
根据表2,可以发现,Prophet模型的预测结果中,对天津和太原的预测效果较好,同时,对北京和兰州PM2.5浓度的预测精度也达到了可以参考的标准。
由于ARIMA和HW算法本质上适应于线性模型,无法捕捉到数据间的非线性关系,而RF算法仅对大样本才表现出良好的预测性能,因此本文的研究目标与研究设计,下面将使用Prophet模型进行样本外预测,分别对四个城市在中共十九大政策缺失状态(反事实状态)下的PM2.5浓度进行预测,然后与中共十九大后的实际PM2.5浓度进行对比,来评价中共十九大推行的环境政策对PM2.5防治产生的效果。
2. 政策评价
完成样本外预测工作后,通过将预测所得的反事实状态下的PM2.5浓度与实际PM2.5浓度进行对比,便可以反映出中共十九大召开与之后的政府行动在大气污染防治方面的实际效果。图2给出了北京市的训练集拟合和样本外预测情况。图2中Target和Predict分别指政策实行后的真实PM2.5浓度和政策缺失状态的PM2.5预测浓度。
反事实状态下,在冬季供暖期,北京市潜在的PM2.5浓度会逐渐上升,度过冬季供暖期后进入春夏季节PM2.5会逐渐下降,在夏季达到最低。中共十九大召开后,在2017年10至2018年2月4个月间,PM2.5浓度真实结果平均下降41.52%。进入2018年3月至今,北京市PM2.5浓度出现反弹,后又逐渐下降,总体曲线高于预测结果,相对平均偏差18.57%。
因此,不难看出,在中共十九大之后的4个月,北京的PM2.5浓度得到明显改善,说明中共十九大后政府的大气防治工作收到显著效果,但是从2017年12月至2018年3月PM2.5浓度的急剧回升,大气污染防治工作效果不明显。这可能与政府的环境监管力量不足、执法力度不够有关。
图3、图4和图5分别给出了兰州、天津、太原三个城市的样本拟合以及样本外预测情况。

图2 北京市的训练集拟合和样本外预测情况
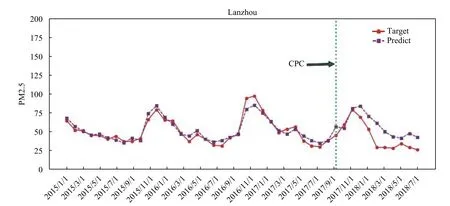
图3 兰州市的训练集拟合和样本外预测情况
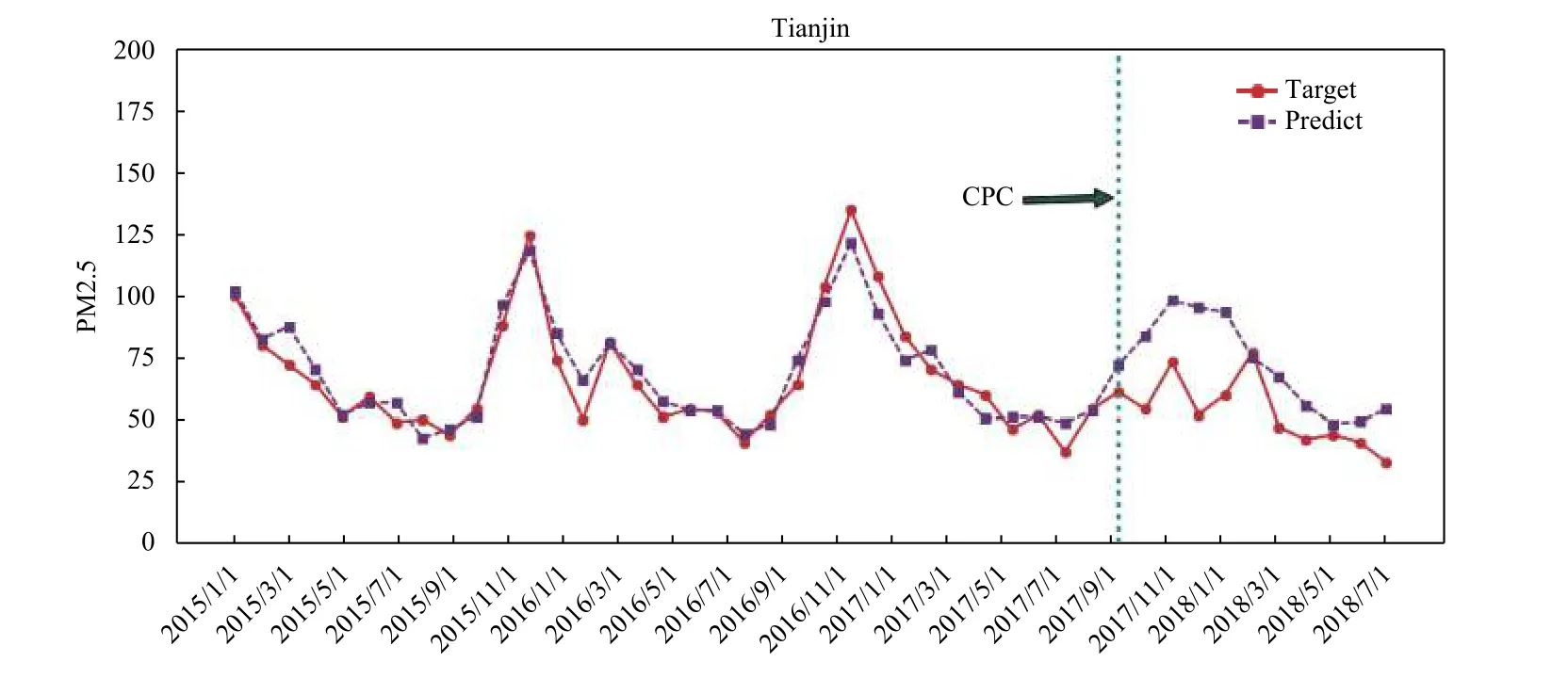
图4 天津市的训练集拟合和样本外预测情况
根据兰州、天津、太原三个城市的样本外反事实预测曲线,潜在的PM2.5浓度均明显高于中共十九大后的真实值。这说明中共十九大之后的各级政府在大气污染治理方面的行动效果显著,各地PM2.5浓度得到有效控制。可以计算出,兰州、天津、太原的PM2.5浓度分别下降25.5%、24.90%、24.29%。2017年10月到2018年2月为北方城市供暖期,PM2.5浓度逐渐上升,处于较高的水平,度过供暖期进入春夏季节,PM2.5浓度逐渐下降到较低的水平。供暖期间兰州、天津、太原三个城市的PM2.5浓度下降平均百分比分别为11.06%、31.53%、25.73%,可见,供暖期间天津市对PM2.5的防治效果相对更好。三个城市春夏季节PM2.5浓度降幅分别为37.61%、20.35%、14.05%,可见三个城市在春夏季对PM2.5防治效果也比较显著,特别是兰州,其PM2.5浓度降幅最大,甚至大于其在2017年底供暖期的下降幅度。
如果进一步对四个城市的政策效应进行对比,计算四个城市实际PM2.5浓度相比其反事实状态(政策确实状态)潜在值的下降幅度,不难发现,北京、天津在供暖期PM2.5浓度降幅分别为41.52%、31.53%,明显高于兰州和太原的11.06%和25.73%。这在一定程度上说明北京、天津作为直辖市,其政策体系相对健全,地方政府对中央精神响应更快,执行力更强,因此其大气污染防治工作效果更显著。相比之下,太原的大气污染防治工作效果略低于天津,而兰州的响应速度要相对滞后,到2018年的春夏季节,兰州的环境政策效应开始显现,PM2.5浓度下降37.61%。因此,实证结果也反映了中共十九大环境政策效应的地区异质性。
综上所述,中共十九大之后的一段时间内,北京和天津的PM2.55浓度得到显著改善,而后期PM2.5浓度出现回升。PM2.5浓度变化出现反季节趋势的现象,究其原因是中共十九大的召开,各级政府为了提升地方形象和政绩,利用运动式、政治性动员,甚至采取临时性管制措施来治理大气污染,营造碧水蓝天的和谐景象(石庆玲等,2016)。实际上,这种改善在中共十九大召开前就已经开始,政策影响持续1到4个月,过后空气质量又出现了迅速恶化,恶化幅度甚至比中共十九大政策对污染改善的幅度还要大。换言之,这种因为特殊“环境保护”而出现的“短暂蓝”有悖于可持续发展理念,不利于雾霾的长效治理,同时也产生了巨大的资源浪费问题。与此不同的是,我们从图4和图5中可以看出,兰州、太原的雾霾防治更加注重可持续性,对于大气改善效果较好。
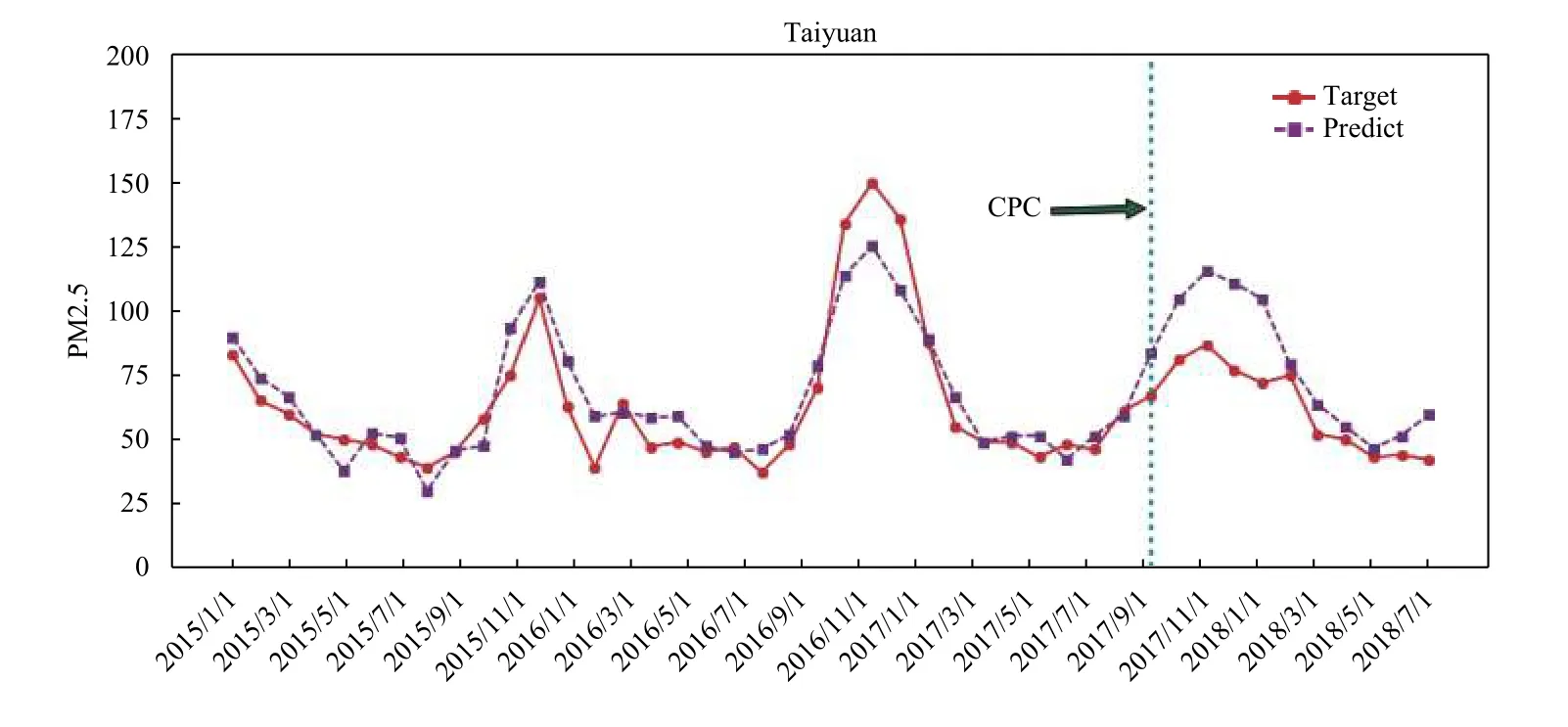
图5 太原市的训练集拟合和样本外预测情况
六、研究结论和政策启示
本文选择北京、天津、太原、兰州四个较有代表性的城市作为研究样本,通过机器学习算法预测PM2.5浓度,量化评价中共十九大召开在大气污染治理方面的政策效应。研究发现,中共十九大的召开对于各地的大气污染防治工作开展具有积极的正面促进作用,各地政府围绕“打赢蓝天保卫战”展开的行动也收到显著的良好效果。同时,中共十九大的政策效应对于北京、天津这样的直辖市,相较兰州和太原这样的省会城市要更加明显一些,即更具政治性,但持续性较差。而从兰州的结果来看,其政策效应略显滞后,但持续性较好,更加利于雾霾的长效治理。此外,研究发现不同地区在政策执行中出现的一些问题,例如,北京、太原在PM2.5浓度的治理上明显存在春夏季节乏力的状况。
对于上述现象,解决问题的关键在于政府必须清醒地认识到,雾霾的治理绝非短期内就可以完全实现,雾霾的高发可能还将持续很长一段时间,必须有长效的制度安排。基于此,本文提出以下三个方面的建议:(1)在环境保护执法上,加大相关部门对污染企业的处罚权限,走可持续发展的常态化轨道,而不是行政命令式的强制执行;(2)在产业转型上,必须稳步淘汰落后产能,将其列入政绩考核项目,而不能为了实现地方经济指标而缺乏有效管理;(3)在治理机制上,进一步完善空气质量监测体系和地方考核指标,利用大数据技术建立快捷高效的空气质量预警机制,并针对不同情况制定相关应急措施。
对于出现政策乏力的问题,政府应该为雾霾治理注入新的活力。雾霾治理不仅仅是政府的事,也是每一个人的事。政府需要进一步开放环境治理市场,让公众和企业参与进来。鉴于此,本文提出以下三个建议:(1)明确排污单位治污主体责任和第三方治理责任,排污者承担污染治理主体责任,第三方治理单位依据合同履行相应责任和义务;(2)加强政策的支持和引导,创新第三方治理机制和实施方式,支持第三方治理单位参与排污权交易;(3)鼓励排污企业、政府、第三方治理信息的公开。通过进一步开放环境治理市场,有助于实现排污单位达标排放和环境质量改善,促进环境污染治理向“市场化、专业化、产业化”转变,推动建立排污者付费、第三方治理的污染治理新机制,最终实现污染防治的有效性和稳定性。
