基于步态能量图特征与稀疏编码的步态识别
2019-04-03王赛男
王赛男
(江苏联合职业技术学院南京工程分院,南京211135)
0 引言
近些年来,基于图像的生物特征识别技术得到了迅速发展,渐渐融入人们生活中,如人脸识别、虹膜识别和指纹识别等[1]。然而,此类身份识别方法均存在一个问题:需要被识别人参与和协作[2-3]。步态识别作为一种新兴的生物特征识别技术,其具有远距离识别、非侵犯性和不易被察觉等特点,可以较好地解决上述问题。现有步态特征识别方法可分为三大类:①时空描述法:主要通过研究人体在行走过程中步速、步长和单步时长来进行步态识别[4-6]。②模型法:该类方法主要通过构造与人体结构或运动相关的模型来实现步态识别[7-9]。③动静态特征法:其主要提取和分析人体在行走过程中的静态特征和动态特征,如步态能量图(Gait Energy Image,GEI)[10]、质心和轮廓关键点特征等[11-12],并 使 用PCA(Principal Component Analysis)和SVM(Support Vector Machine)等方法实现步态识别[13]。上述方法中,时空描述法相对出现较早,其识别精度有限,受摄像机位置影响较大;模型法则根据已有数据,经过大量计算后,才可以得到一定的识别性能,算法计算速度相对较慢,且鲁棒性欠佳;基于动静态特征法可以有效地提取人体行走过程中的信息,但目前大部分算法均将GEI 经过PCA 或改进的PCA 算法降维后,直接输入到分类器中进行识别。
上述基于动静态特征法的步态识别中,并没有对GEI 进行特征提取和处理,因此,本文使用SIFT(Scale-Invariant Feature Transform)算子[14]提取GEI 特征,引入稀疏表示和字典原子标签信息的方法,提出了一种基于步态能量图特征和稀疏编码的步态识别方法。该方法在生成识别字典时使用K-means 的方法对GEI 特征进行筛选[15],并将字典中每个原子加入标签信息,从而提高步态识别准确率,加快算法运行速度。由于步态图像数据量有限,即使通过人工模拟也达不到海量数据的要求。
1 步态能量图特征与识别字典
1.1 步态能量图特征
步态能量图是由Man 等人[10]提出的一种有效的步态特征,其计算公式如下:

上式中T 表示步态周期,Bt(x,y)为侧影轮廓二值图像中像素点(x,y)在t 时刻的值(人体所在区域取值为255,背景所在区域则为0)。图1(a)为不同时刻步态序列图像叠加结果,由于本文使用中科院步态数据库CASIA,该库中包含人体目标区域提取结果,故步态图像序列的预处理过程(主要为运动检测、目标提取、滤波去噪等)不在本文中讨论。图1(b)为提取得到的步态能量图,步态周期通常使用人体的侧影宽高比来确定,具体如图1(c)所示,其横轴为时间,纵轴为侧影宽高比,两个波谷间间隔即为步态周期。

图1 步态信息(取自中科院步态数据库CASIA A)
提取得到GEI 后,本文引入SFIT 算子对GEI 进行特征提取,得到步态能量图特征。为了去除噪声和不同目标共有特征带来的影响,本文使用K-means 聚类的方法,对步态能量图特征进行筛选,图2 为第i 个目标人物数据特征提取和筛选过程。图2 中Gij为目标人物i 第j 个视频由公式(1)得到的GEI,Yi为提取得到的GEI 特征,Zi为基于K-means 聚类方法筛选后得到的GEI 特征。本文根据聚类后类别中特征数量对类别进行排序,去除数量最多类别(如图2 中类别2)中离该类中心点距离最近的前5%GEI 特征,其可能是不同目标共有特征;去除数量最少类别(如图2 中类别3)中离该类中心点距离最远的后10%GEI 特征,其可能是噪声提取得到的特征。
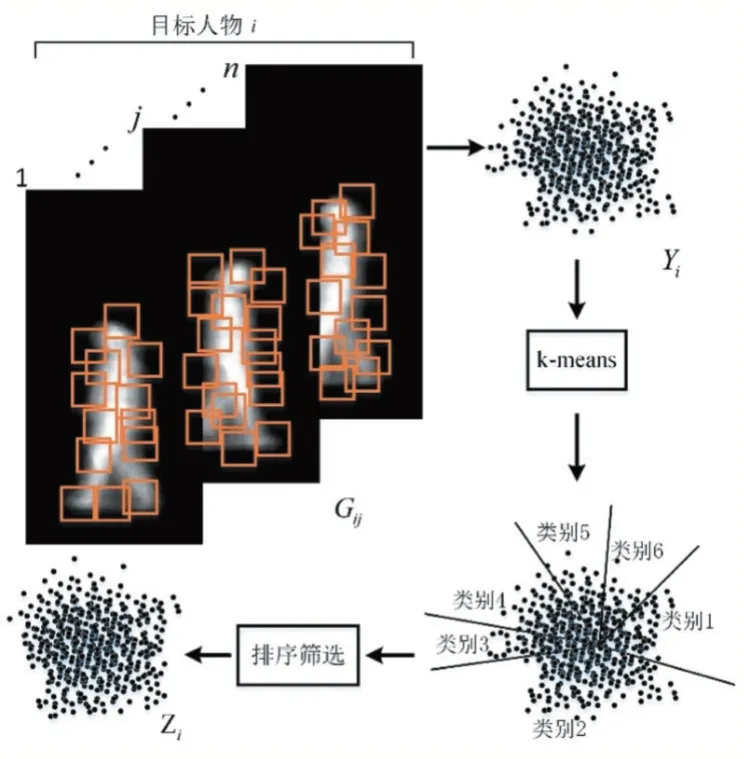
图2 步态能量图特征提取和筛选
1.2 识别字典和标签信息生成
本文使用SIFT 算子和基于K-means 的方法提取与筛选GEI 特征,并引入稀疏编码和投票的方法,对不同目标人物进行步态识别。本文识别字典D 中原子由筛选后的GEI 特征构成,并根据原子所属目标人物信息记录其标签信息,从而得到标签信息集W ,具体如图3 所示。
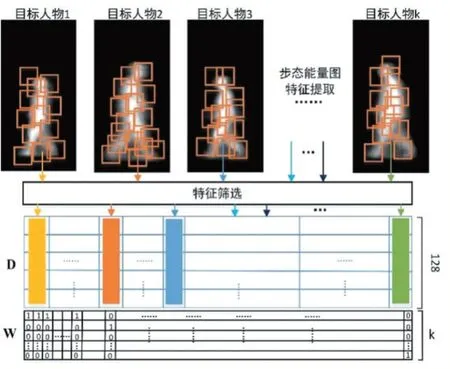
图3 识别字典和标签信息生成过程
图3 中W 即为标签信息集,其表示字典D 中每个原子所属的目标人物信息,如目标人物1 提取得到的GEI 特征为Z1,其对应的标签信息为,k 为目标人物总数,则Zk对应的标签信息为。本文识别字典原子由SIFT 算子提取得到,其尺寸为128×1,且与标签信息集W 中原子关系一一对应。
2 算法原理
在得到识别字典D 和标签信息集W 后,本文使用稀疏编码和投票的方法对不同目标人物进行步态识别。记待识别视频提取得到的步态能量图为Gtext,使用SIFT 算子特征提取和筛选后得到m 个GEI 特征,l=1,2,…m。为了实现步态识别,本文使用稀疏编码的方法,求取在识别字典D 上的解αl,并根据标签信息集W,通过投票的方法得到其识别结果。由于识别字典原子个数远远大于1,故得到的αl为稀疏解,根据稀疏编码的方法,可使用下式求取αl的近似解αl:


上式中l=1,2,...,m,即待识别视频共提取得到m个GEI 特征。Ll为一列向量,其长度与W 中列向量相同,以图3 中标签信息集为例,则可知Ll长度为k。
通过识别字典和标签信息集得到待识别视频GEI特征标签信息Ll后,本文使用投票的方法,得到最终步态识别结果,具体可由下式计算得到:

其中CL 为m 个步态能量图特征标签信息均值,长度和Ll相同,均为k。由于标签信息集W 在定义时其非零元素所在行号即为目标人物序号,故CL 中最大值所在的行号即为步态识别结果,如CL 中最大值所在行号为7,则该视频步态识别结果为目标人物7。
本文算法步骤如下所示:
1) 提取训练数据步态能量图特征,基于K-means 聚类的方法对特征进行筛选;
2) 生成识别字典D 和标签信息集W ;
3) 计算待识别视频标签信息
for l=1:m
3.1 提取测试数据步态能量图特征ztestl;
3.2 求取稀疏解αˆl(公式2);
3.3 计算标签信息Ll(公式3);
endfor
4) 计算识别结果CL(公式4)。
本文算法前两个步骤主要使用训练数据得到识别字典和对应的标签信息集,步骤3 和4 则使用识别字典等对待识别视频进行处理,实现步态识别。
3 实验结果与分析
本文实验在MATLAB 平台下仿真实现,CPU 为Intel i5-3210M 2.5GHz,RAM 为8GB。数据库使用中国科学院自动化研究所提供的步态数据库CASIA B,其包含140 个目标人物行走视频,帧率为25fps,图像分辨率为320×240。目标人物拍摄角度选为90 度(有利于GEI 的提取),行走条件分为三种:普通条件(每个样本共6 个视频)、穿大衣(每个样本共2 个视频)和携带包裹(每个样本共2 个视频),具体如图4 所示。
文中在对步态轮廓图像进行处理时,先提取步态周期T ,再计算一个周期内步态图像加权平均值,从而得到步态能量图,将其作为本文实验输入数据。

图4 不同行走条件下侧面轮廓图像
本文将目标在普通行走条件下所有样本前2 个视频作为训练数据集,生成识别字典D 和标签信息集W ,并将剩下的数据作为测试数据集,评价指标使用平均识别率(ARR)。 ARR 表示正确识别的目标人物数占总数的比例,其值越大,表示识别率越高,即算法识别效果越好。

3.1 实验结果
表1 为不同行走条件下ARR 值,为了评价算法性能,分别将本文算法与基于LDA[17]、W(2D)2PCA[18]、文献[19]和文献[20]的算法进行比较。表1 中本文算法识别字典原子数为9000,特征筛选时K-means 方法中聚为5 类,噪声特征去除比例为10%,共有特征去除比例为5%。由表1 中平均识别率对比可知,在不同行走条件下,本文算法ARR 有所提高,均优于其他4 种算法。本文在步态能量图的基础上提取其SFIT 特征,可以有效地减小前景分割时噪声带来的影响,并通过基于Kmeans 聚类的特征筛选方法,进一步减小噪声和共有特征带来的影响,从而可以提高不同行走条件下步态识别的鲁棒性。
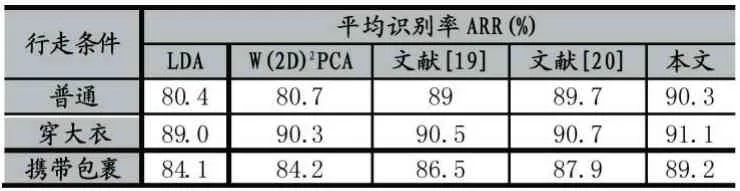
表1 不同算法平均识别率对比
表2 为不同算法平均运行时间对比结果,该表中各算法参数设置与表1 相同(只统计测试数据集不同行走条件下步态识别的平均运行时间,训练数据处理和步态能量图提取时间不计入)。由表2 可知,本文算法运行时间优于文献[19]

表2 不同算法平均运行时间对比
文献[19]和文献[20],略高于LDA 和W(2D)2PCA,但本文算法ARR 值均优于上述算法。从表1 和表2 对比可知,在不同行走条件下,本文算法平均识别率优于所对比算法,且运行时间快于目前主流改进算法(如文献[19]和文献[20])。
3.2 聚类类别数对算法的影响
本文在提取得到GEI 特征后,为了去除噪声和共有特征带来的影响,使用基于K-means 聚类的方法进行特征筛选,其聚类类别数对最终步态识别有着一定的影响。图5 为不同聚类类别数下本文算法三种行走状态的ARR 值,均去除最少类别的10%和最多类别的5%。由图5 可知,当聚类类别数较小时,在去除噪声和共有特征的同时也会去除有效的GEI 特征;当聚类类别较大时,则噪声和共有特征去除较少。因此,本文在实验中聚类类别数为5,其可以得到较好的平均识别率。

图5 聚类类别数对识别结果的影响
3.3 特征筛选对算法的影响
由图2 可知,本文在提取GEI 特征后,使用Kmeans 的方法对其进行筛选,筛选时去除特征的比例直接影响着识别字典。因此,本小节对特征筛选时特征去除比例进行研究,图6 为识别字典生成时不同筛选值对平均识别率的影响,聚类类别数均为5。图6(a)中共有特征去除比例取值范围为1%~10%,噪声特征去除比例为固定值10%;图3(b)中噪声特征去除比例取值范围为5%~14%,共有特征去除比例为固定值5%。由图6 可知,在生成识别字典时,测试数据ARR值与共有特征,噪声特征去除比例存在着一定的相关性。当共有特征和噪声特征去除比例较小时,识别字典中原子区分度下降,平均识别率低;当共有特征和噪声特征去除比例较大时,识别字典中原子所包含的特征信息减少,使得平均识别率降低。因此,为了提高步态识别率,本文在特征筛选时,共有特征去除比例选为5%,噪声特征去除比例为10%。
3.4 识别字典尺寸对算法的影响
本文实验部分还研究了识别字典尺寸对最终步态识别结果的影响,图7 给出了不同尺寸的识别字典对应的平均识别率和平均运行时间。为了便于分析,图7中平均识别率为三种行走条件ARR 的均值。由图7 可知,识别字典尺寸(原子数)与平均识别率存在一定的正相关性,但原子数大于9000 后,平均识别率增加不明显。平均运行时间则随着字典尺寸的增加而快速增加,因此,本文综合算法识别率和运行时间,在实验中识别字典原子数选取为9000。

图6 不同特征筛选值对识别结果影响

图7 不同识别字典尺寸对识别结果影响
4 结语
为了提高步态识别准确率,本文对步态能量图进行研究,提出一种基于步态能量图特征和稀疏编码的步态识别方法。该方法提取步态能量图特征,使用识别字典和投票的方法进行步态识别,并引入K-means聚类的特征筛选方法。在CASIA B 步态数据库上实验结果表明,本文方法平均识别率优于其他方法,下一步可将字典学习方法用于该方法中,进一步提高算法运行速度。
