基于自适应深度网络的无人机目标跟踪算法
2019-03-29刘芳王洪娟黄光伟路丽霞王鑫
刘芳,王洪娟,黄光伟,路丽霞,王鑫
北京工业大学 信息学部,北京 100124
目标跟踪技术是无人机视觉领域的重要研究方向之一[1]。在无人机视频中,由于画面较大,目标在场景中所占面积较小,且目标易发生遮挡、形变、光照变化、相似背景干扰等情况,鲁棒的无人机视觉跟踪系统的设计与应用仍然面临着严峻的挑战。
在视觉跟踪问题中,基于目标特征跟踪是视觉跟踪中最为重要的一类方法,通常包括目标特征表达、目标状态搜索、目标定位等几个过程。其中目标特征表达是影响跟踪性能的重要因素之一,用来表达目标的特征应该能够适应目标外观变化,同时对背景具有很好的区分性[2]。传统特征(如哈尔特征(HARR)[3],方向梯度直方图(HOG))等被应用于视觉跟踪,但是这些特征大都是通过手工设计的底层特征,针对性较强,对目标状态变化不鲁棒。而无人机在很多实际应用中往往要面对更为复杂的环境,且目标易受到遮挡、形变、复杂背景等影响,基于传统特征提取算法进行目标跟踪效果不理想。
近年来,深度学习中的卷积神经网络(Convolutional Neural Network, CNN)[4]得到广泛的应用,对目标外观变化具有较强的鲁棒性,被引入到视频目标跟踪问题的求解中来。Wang和Yeung[5]基于消噪自编码器原理,将离线训练与在线微调相结合,提出了直接线性变换(DLT)跟踪算法,提高了跟踪效果,适应性更强。文献[6]提出一种在CNN的隐含层的顶端添加一个在线的支持向量机(SVM)层,用来学习目标对象的外观,提出了一种CNN-SVM的跟踪算法,取得了不错的跟踪效果。Nam和Han[7]提出了一种多域网络跟踪算法,通过对卷积神经网络增加目标分类层,在跟踪性能上取得了显著提升。文献[8]提出的全卷积网络跟踪(FCNT)模型通过分析深度网络模型不同特征层的特点,将不同特征层组合得到一个新的跟踪模型实现视频跟踪。赵洲等[9]针对简单背景下的高速高机动目标,提出一种改进时空上下文跟踪算法,有效解决不同光照强度下对高速、高机动目标引起的问题。因此,针对无人机视频中的目标易发生遮挡、形变、光照变化、相似背景等问题,通过深度网络可以获得目标更深层次的特征表达,为无人机视频目标跟踪算法奠定基础。
近年来,相关滤波器在目标跟踪性能和计算速度上的出色表现,使之成为当前的研究热点。基于相关滤波的跟踪算法最大的特点是可以利用快速傅里叶变换使得计算速度加快,且准确率比较高,相关跟踪的算法也层出不穷。Bolme等[10]首次将相关滤波的算法应用到目标跟踪中,并提出了最小化输出均方误差和(MOSSE)跟踪算法。在MOSSE基础上,Henriques等提出的循环结构的检测(CSK)跟踪[11]、核相关滤波(KCF)[12]跟踪算法,其跟踪速度也都达到了100帧/s以上。这些算法仅利用灰度特征进行跟踪,随后Henriques等[12]将CSK算法从单通道扩展至多通道,融合特征取得了不错的跟踪效果。KCF算法利用梯度方向直方图特征代替原始灰度特征,使跟踪精度得到提升。崔乃刚等[13]提出了一种自适应高阶容积卡尔曼滤波(AHCKF)算法,该算法在系统状态发生突变的情况下表现出良好的滤波性能,具有更强的鲁棒性和系统自适应能力,但其计算量较大,算法运行时间较长。因此,为了更好地满足无人机平台下目标跟踪对算法速度的要求,采用核相关滤波器作为无人机目标跟踪的算法进行研究。
综上所述,本文提出一种基于自适应深度网络的无人机目标跟踪算法。主成分分析(Principal Component Analysis,PCA)与受限隐层节点自编码神经网络的结果具有相似性[14],同时根据无人机图像的特点,设计了一个3阶自适应的多通道PCA卷积神经网络(Multi-channel PCA Convolutional Neural Network,MPCA-CNN),首先为了降低输入的冗余性和加快网络的学习速度,将MPCA作为深度网络的第1层;其次在网络结构中加入空间金字塔池化层,使网络可以输入任意尺寸的图像,提取目标更多的空间细节特征;再次对目标帧进行MPCA处理,将得到的特征向量初始化各层卷积核,优化了网络结构,提高了网络收敛速度和精度;最后通过核相关滤波算法构建滤波模板,获得该特征下的预测位置,完成稳定的跟踪目标。在模板更新模块,采用相邻2帧目标图像的协方差矩阵之间距离的度量算法计算相似度,调整分类器学习率,改善由于目标发生遮挡导致跟踪失败的问题。仿真实验结果表明,该算法能更好地适应目标发生遮挡、形变、光照变化、相似背景干扰等问题,有效提高跟踪算法的精度。
1 自适应MPCA-CNN的特征提取
针对无人机视觉跟踪中运动目标易受到遮挡、形变、光照变化、相似背景干扰等因素影响,提出一种基于自适应深度网络的无人机目标跟踪算法。该算法首先设计一个3阶的自适应CNN,利用MPCA降低图像信息的冗余,实现数据预处理,将预处理后的数据作为深度网络的输入,并将得到的特征向量组初始化各层卷积核以进行端到端的网络训练,提取目标更深层次的特征,然后通过核相关滤波进行目标跟踪,提高无人机视频目标的跟踪性能。
1.1 卷积神经网络
近年来,随着计算机性能的大幅度提升,出现了诸多高性能的卷积神经网络深层架构,其直接将多维图像输入网络,网络自动学习得到图像特征,避免手动提取图像特征这一复杂的过程,并已在图像处理领域取得较好的效果。
卷积是CNN的核心。输入图像和卷积核进行卷积,通过一个激励函数后就在卷积层得到了特征图。计算过程为
(1)

ReLU层是通过ReLU激活函数给网络加入非线性因素,极大地加快收敛速度,其公式为
ReLU(x)=max(0,x)
(2)
池化层是对卷积后特征进行池化的操作。n×n大小的邻域内进行求平均运算或最大值、最小值等运算,再经过一个激励函数f(x),得到了池化层中的m个特征图。计算公式为
(3)
式中:down( )表示下采样函数。
由于传统CNN中的全连接层需要固定的输入维度,当原始输入的图像大小不一致时,网络就会对输入图像进行缩放,导致图像信息的损失。因此,为了使卷积神经网络自适应处理任意大小的输入图像,采用空间金字塔池化(Spatial Pyramid Pooling,SPP)[15]层替换最后的池化层,将其输出的特征图作为全连接层的输入。SPP层结构如图1所示,SPP层增加了网络的尺度适应性,使得网络提取到更多不同尺度的特征信息,图像特征更丰富,从而提高了网络的识别性能。

图1 空间金字塔池化网络结构Fig.1 Structure of spatial pyramid pooling network
1.2 多通道PCA分层卷积
根据主成分分析与隐层神经元数量受限时的自编码神经网络特征提取结果之间具有高度的相似性,本文采用PCA求得的特征向量组来近似代替网络的卷积核以获得目标的深度特征。但是PCA学习只利用了图像的灰度信息,丢失了图像的颜色信息。HSI(Hue Saturation Intensity)模型是适合基于人的视觉系统对彩色感知特性进行处理分析的模型,可充分发挥色度的作用,因此使用HSI颜色空间模型作为目标颜色特征的描述,图像在H、S、I通道分别进行PCA处理,其主成分能够最大程度地表示局部特征的主要信息以及特征之间的差异,有效实现目标和背景噪声的分类。以CIFAR-10中Cat1数据为例,得到的3层MPCA卷积滤波如图2所示。
MPCA初始化卷积核的具体过程为
1) 将原始图像转化成H、S、I通道的图像,并对3个通道的灰度图像进行取片操作。

Xi=S(Ii)=[x1,x2,…,xs]∈
Rk1k2×(m-k1+1)(n-k2+1)
(4)
3) 对X进行PCA运算,可以求得特征向量组Vkk,取Vkk中前L个特征向量作为主成分特征向量,用于初始化卷积核组V,V可表示为
(5)
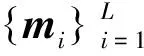

图2 3层MPCA卷积滤波Fig.2 Three-layer MPCA convolution filtering
1.3 自适应MPCA-CNN
CNN模型层数较多、结构复杂,将高维数据直接输入网络中进行训练,会使网络的训练时间较长。主成分分析利用高维数据之间存在的特征,将数据映射到正交的低维子空间上,减少输入数据的冗余,缩短网络训练时间,同时降低数据中的噪声[16],因此将MPCA作为深度网络的第1层,并将图像经MPCA处理得到的特征向量组对各层卷积核进行初始化,提取目标更深层次的特征,减少计算量。同时网络中还采用SPP层代替最后一个池化层,使网络对输入不同尺寸的图像自适应处理。研究表明,在卷积神经网络中第3个卷积层的卷积特征保留目标更多的空间细节,如目标的位置信息等。因此,针对无人机目标易发生遮挡、形变、光照变化和相似背景干扰等问题,本文设计了一个3阶的自适应MPCA-CNN用于提取目标特征输入到核相关滤波系统实现准确跟踪。网络的总体结构如图3所示。
具体地,在第1阶段将经MPCA降维的图像数据输入到由32个大小为5×5的MPCA卷积核组成的卷积层,再将得到的特征图输入到ReLU层,相比sigmoid和tanh函数,ReLU函数可以有效地解决梯度弥散问题。然后将得到的32个特征图输入到一个最大值池化层,使得卷积神经网络对于图像微小的平移具有一定的鲁棒性,更适用于目标跟踪。第2阶段的实现与第1阶段类似,首先将第1阶段的输出与64个大小为5×5的MPCA卷积核进行卷积,然后将得到的64个特征图输入至ReLU函数,之后进行最大值池化。
第3阶段的实现与第2阶段类似,用128个大小为5×5的MPCA卷积核对上阶段产生的输出进行卷积并进行ReLU运算。不同的是,将其特征图输入到SPP层,SPP层可以分配合适的尺度对不同大小的特征图作池化处理,再合并聚集其结果为一维向量,获得图像更丰富的特征。然后通过全连接层与该层所有节点相连把局部的卷积特征图转换为一个全局的特征向量。
自适应MPCA-CNN提供了一种直接从图像原始像素学习特征的模型。网络的总体结构如图3,首先对输入图像进行MPCA预处理,再输入到3阶的深度网络,其中第1、2阶包含卷积层,ReLU层和池化层,第3阶包含卷积层,ReLU层和SPP层,采用SPP层代替全连接层前的池化层,使得网络可以输入任意尺寸图像。其次利用MPCA得到的特征向量组初始化各层卷积核,加快网络的学习速度,从而构建一个3阶的自适应MPCA-CNN网络提取目标的深层次特征。

图3 自适应MPCA-CNN网络结构Fig.3 Structure of adaptive MPCA-CNN network
2 基于深度网络核相关滤波的目标跟踪
近年来,基于相关滤波的跟踪算法将信号从时域转换到频域,利用快速傅里叶变换进行滤波模板训练和响应图计算,提高了目标跟踪的精度和速度。因此本文通过自适应MPCA-CNN提取目标的特征训练核相关滤波器系数,然后根据连续帧提取的特征在核相关滤波器上的最大响应位置计算目标位置,较好地提高无人机目标跟踪算法的性能。
2.1 基于核相关滤波的目标跟踪
自适应MPCA-CNN中,卷积层输出的是多通道的特征图x=[x1,x2,…,xd]∈RM×N×D,M、N和D分别为特征图的宽、高和通道数。对于卷积特征图,利用核相关滤波(Kernel Correlation Filter,KCF)算法构建滤波模板。KCF跟踪算法采用核岭回归分类器,其目标是使给定一组图像样本经过滤波模板后与回归目标的结构化风险最小,其目标函数为
(6)
式中:h为滤波模块;y为期望输出;λ为正则因子。
设从样本空间到希尔伯特特征空间的非线性变换为xi→φ(xi),则目标函数的核化形式为
(7)
式中:w为权重参数;φ(x)为希尔伯特空间;·,·表示点积操作。可以把w表示为线性组合的形式,即此时需要优化的变量变为系数向量α。利用样本找到一个对回归目标最小平方误差的函数可以表示为

(8)
在非线性希尔伯特特征空间的点乘运算可以用核函数运算,即φT(x)φ(x′)=κ(x,x′),其运算结果是一个n×n的矩阵,称核矩阵K,其元素为
(9)
可以得到核化的岭回归问题的解为

(10)
在新的一帧图像中通过获取感兴趣区域图像块来完成目标位置检测,分类器的响应为
(11)
式中:z为预测包含目标的搜索窗口图像块;f(z)为检测样本z的响应矩阵,响应最大的位置即为目标所在的位置。相比于传统算法计算回归解,利用离散傅里叶变换能够将算法复杂度从o(n3)有效降低到接近线性的o(nlgn),大大提高了算法效率。
2.2 模板更新策略
跟踪过程中,目标易受遮挡、形变、复杂背景等影响,使用固定目标模板不能稳定地跟踪目标,需及时对其进行更新。核相关滤波器采用的模板更新方案为
αt+1=(1-γ)αt+γα
(12)
Xt+1=(1-γ)Xt+γX
(13)
式中:γ为学习率,采用固定值的γ来更新滤波器,难以处理复杂的目标运动问题。采用协方差矩阵之间距离的度量算法来分段调整学习率,该距离描述了两个协方差矩阵之间的相似性,值越小表示两个协方差矩阵越相似,反之,则表示其相似度越小。步骤为
步骤1 计算相邻2帧图像的协方差矩阵Ck-1和Ck。那么Ck-1和Ck之间的距离可以表示为
(14)
式中:{λi(Ck-1,Ck)}i=1,2,…,d表示Ck-1和Ck组成的特征方程的特征值。
步骤2 更新学习率γ。当ρ≤3时,表示相邻2帧目标图像变化较小,可以设置较小的γ;当3<ρ≤7时,表示相邻2帧目标图像变化适中,可以设置常规的γ;当ρ>7时,表示相邻2帧目标图像相似度较小,可能遇到遮挡等情况,设置较大的γ。其更新学习率γ的方法为
(15)
2.3 算法流程
所提算法流程如图4所示,主要步骤为
1) 构建自适应深度网络结构。根据无人机图像的特点,利用MPCA降低图像信息的冗余,实现数据预处理,并将预处理后的数据输入到3阶自适应深度网络中。
2) 网络参数设计。利用对输入图像在H、S、I这3通道上进行PCA处理后得到的特征向量组进行分层卷积。
3) 网络参数训练。利用跟踪目标的正、负样本通过误差反向传播算法进行网络参数训练,训练好的网络作为深度特征提取网络。
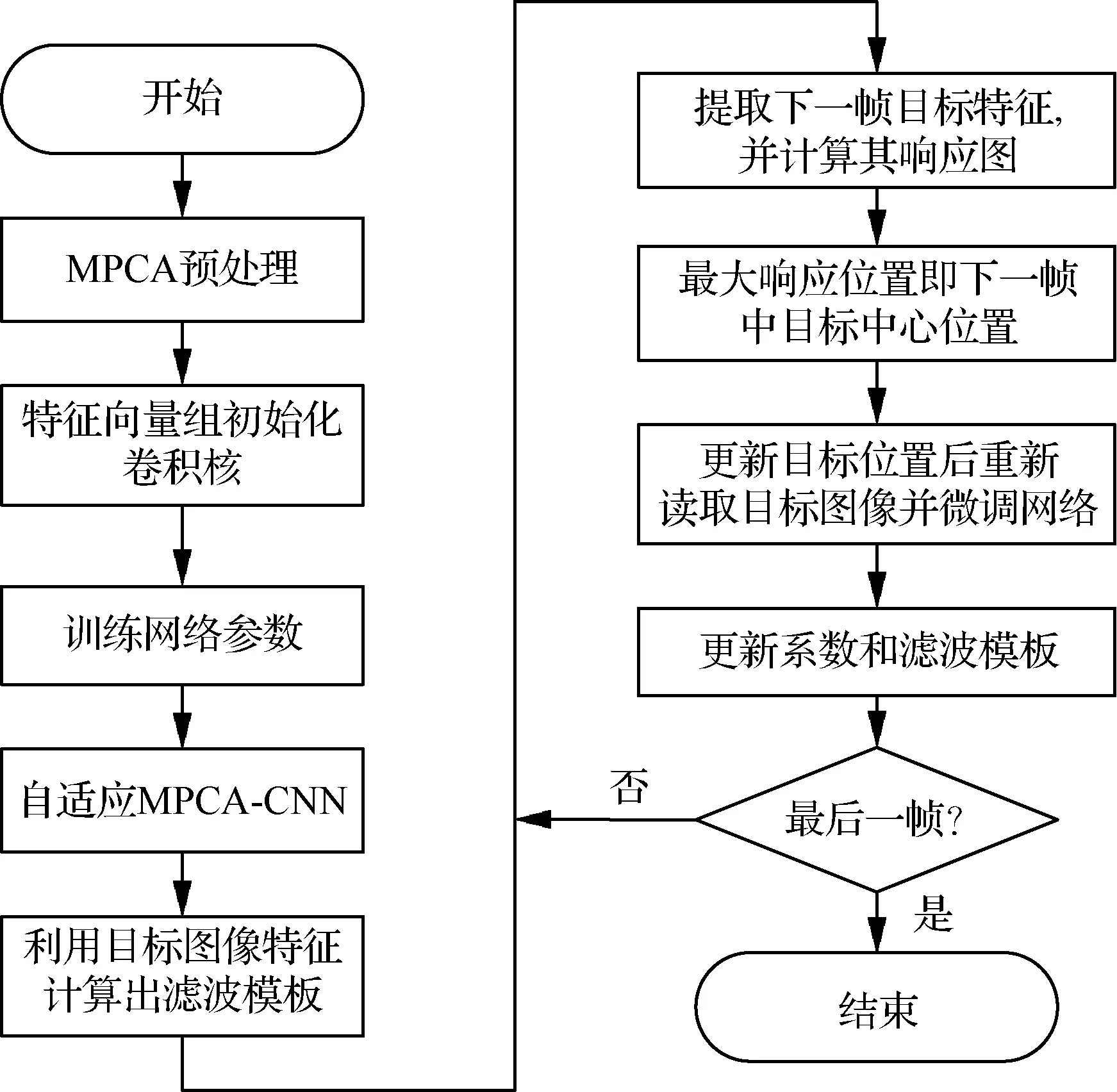
图4 所提算法流程图Fig.4 Flow chart of proposed algorithm
4) 核相关滤波。将得到的深度特征输入到相关滤波系统,通过核相关滤波算法构建滤波器,将响应图的峰值位置作为目标的中心位置。
5) 模板更新。采用自适应调整分类器学习率进行模板更新,适应目标表面特征的变化。
3 仿真实验
3.1 自适应MPCA-CNN设计
为验证自适应MPCA-CNN的有效性,实验采用VOC2012数据集训练深度网络,VOC2012数据集是国际权威的图像识别和物体分类的数据集,包括20个类别共17 125张彩色图像。随机选取该数据集中13 700张为训练集,3 425张为测试集。实验结果如表1所示。
仿真实验结果证明,通过MPCA-CNN进行目标特征提取时,不但分类效果好而且训练速度快。从表1中可以看出,该网络的所有层卷积核均进行MPCA初始化可以减少计算量,降低了网络的训练时间,并且准确率比随机初始化提高了11.6%,经过MPCA处理可以保留原图像中的有用特征信息,说明恰当的网络初始化可以促进卷积神经网络更快地找到全局最优解,在训练过程起到很重要的作用。
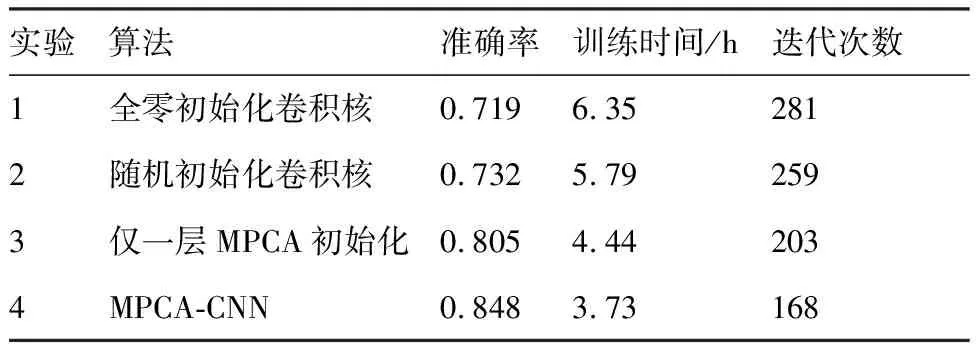
表1 MPCA-CNN训练模型效果比较Table 1 Comparison of MPCA-CNN training model effects
3.2 无人机视频目标跟踪仿真实验
为验证本文算法的有效性,选取UAV123[17]数据集和UAV视频数据集中的视频序列作为测试数据集,对所提算法进行测试,并与文献中7种主流跟踪算法进行实验效果对比,包括Struck[3]、CNN-SVM[6]、FCNT[8]、CSK[11]、KCF[12]、互补跟踪算法(Staple)[18]、空间正则化判别相关滤波(SRDCF)[19],其中Staple、SRDCF、KCF、CSK为基于相关滤波的跟踪算法,CNN-SVM、FCNT为基于深度学习的跟踪算法。这里使用了Car3、SUV、Bike1、Person15共4组无人机视频序列进行实验结果展示。
仿真实验中8种算法的部分跟踪结果如图5所示,其中不同的跟踪算法用不同的颜色表示,红色为本文算法,左上角数字为当前图像帧数。从以下4个方面对本文跟踪算法进行分析:

图5 部分视频仿真结果Fig.5 Partial results of video simulation
1) 目标姿态变化。Car3、SUV和Bike1视频序列中目标发生了明显的姿态变化。Car3的第462帧中,FCNT、Struck算法出现了明显的偏移,而本文算法利用构建的MPCA-CNN提取目标深层次特征,提高了目标外观模型的鲁棒性和精确性,使得跟踪算法在无人机视频中始终正确跟踪目标。
2) 目标遮挡。Car3和SUV视频中目标在运动过程中被不同物体不同程度遮挡。SUV的第517帧遇到遮挡时,SRDCF和FCNT算法发生了跟踪漂移,而本文算法采用自适应调整学习速率进行模板更新,在跟踪目标发生遮挡时仍准确跟踪目标。
3) 相似目标。Bike1视频序列中出现相似目标。由于无人机目标特征不明显,且当跟踪目标周围出现了相似目标时,CNN-SVM算法出现了明显偏差,由于自适应MPCA-CNN网络能够提取到比传统CNN更深层次的目标特征,使得本文跟踪算法始终能准确地跟踪目标。
4) 光照变化。Person15无人机视频中目标运动过程中光线的亮度变化使目标的颜色、亮度等特征随之改变,Staple、SRDCF和KCF算法均出现不同程度的跳动,由于本文算法使用多通道卷积特征减弱光照变化的影响,实现更准确的目标表征,实现稳定跟踪目标。
针对上述4组视频序列,采用中心位置误差和覆盖率2个评价指标对算法进行对比分析。中心位置误差是指跟踪结果中心点与真值中心点之间的欧氏距离。跟踪结果的边界窗口为rt,目标窗口为ra,重叠率定义为S=|rt∩ra|/|rt∪ra|,当t大于所给的阈值则表示当前帧跟踪成功。图6为8种跟踪算法在4组测试视频中的中心位置误差曲线。图7为8种跟踪算法在4组测试视频中的覆盖率曲线。
相比其他算法,本文算法的中心位置误差始终保持在较低水平,在跟踪过程中具有较好的跟踪效果,如图6所示。由图7可以看出,本文算法在不同无人机视频中始终保持了较高的覆盖率,由此表明本文算法在不同的无人机测试视频中都能保持较高的跟踪精度,具有较好的跟踪性能。
为了进一步分析本文跟踪算法的性能,与当前主流的跟踪算法在UAV123数据集上进行仿真实验对比分析。采用跟踪精确度和跟踪成功率2个通用的评价指标来进行定量分析。跟踪精确度(Precision)反映跟踪得到的目标中心位置和给定的实际目标中心位置的距离小于给定的某个阈值的视频帧数占总视频帧数的比例,因此,随着阈值的增大,精确度曲线不断上升。跟踪成功率(Success)反映跟踪得到的目标框和给定的实际目标框的重叠程度大于给定阈值的视频帧数占总视频帧数的比例,因此,随着对重叠程度的要求越高,即阈值越大,反而成功率曲线不断下降。

图6 中心位置误差曲线Fig.6 Curves of enter position errors

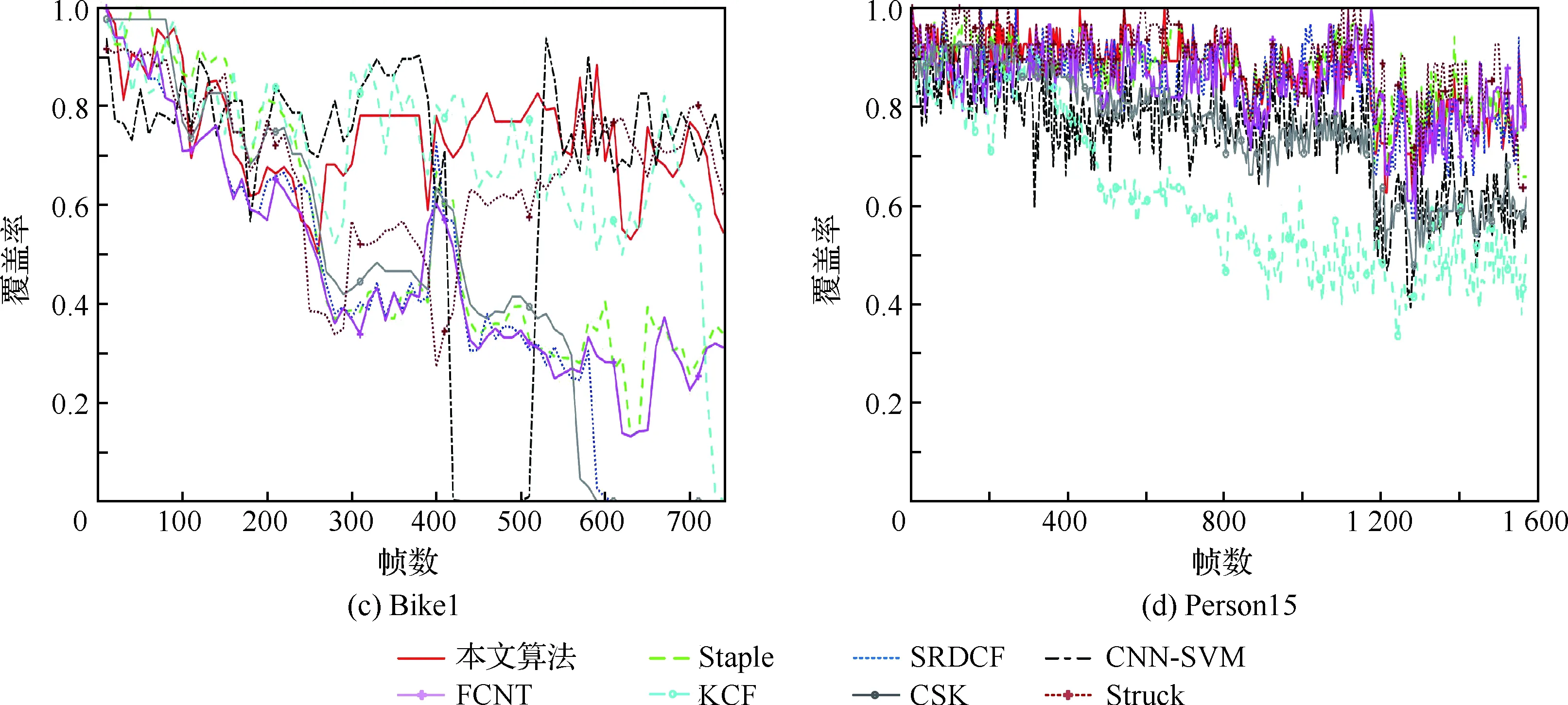
图7 覆盖率曲线图Fig.7 Coverage curves
图8表示8种跟踪算法对于UAV123数据集中所有视频序列的整体跟踪成功率曲线和精确度曲线,其中图例中括号中的数字分别表示中心位置误差取值为20时对应的跟踪精确度和覆盖率取值为0.5时对应的跟踪成功率。由图8可以看出,本文算法的跟踪精确度和成功率高于其他算法。在图8(a)中,跟踪精确度在中心位置误差阈值为20像素时,本文算法的跟踪精确度高于同样基于卷积特征跟踪的CNN-SVM算法的4.36%。当中心位置误差小于20像素时,本文算法的精确度值要高于其他算法,这说明了在高精度约束条件下,本文算法的鲁棒性更好。在图8(b)中,本文算法比SRDCF跟踪算法提高了9.79%。当覆盖率阈值处于中间范围时,本文算法的成功率高于其他对比算法,尤其是当阈值处于0.3~0.6范围内时,本文算法的成功率明显高于SRDCF算法,在阈值大于0.8时,本文算法的成功率略低,但也达到了次优。由于本文算法能够提取到目标更深层次的特征,提高了跟踪成功率。综上所述,本文算法具有较好的跟踪性能,满足无人机平台对目标跟踪算法的要求。
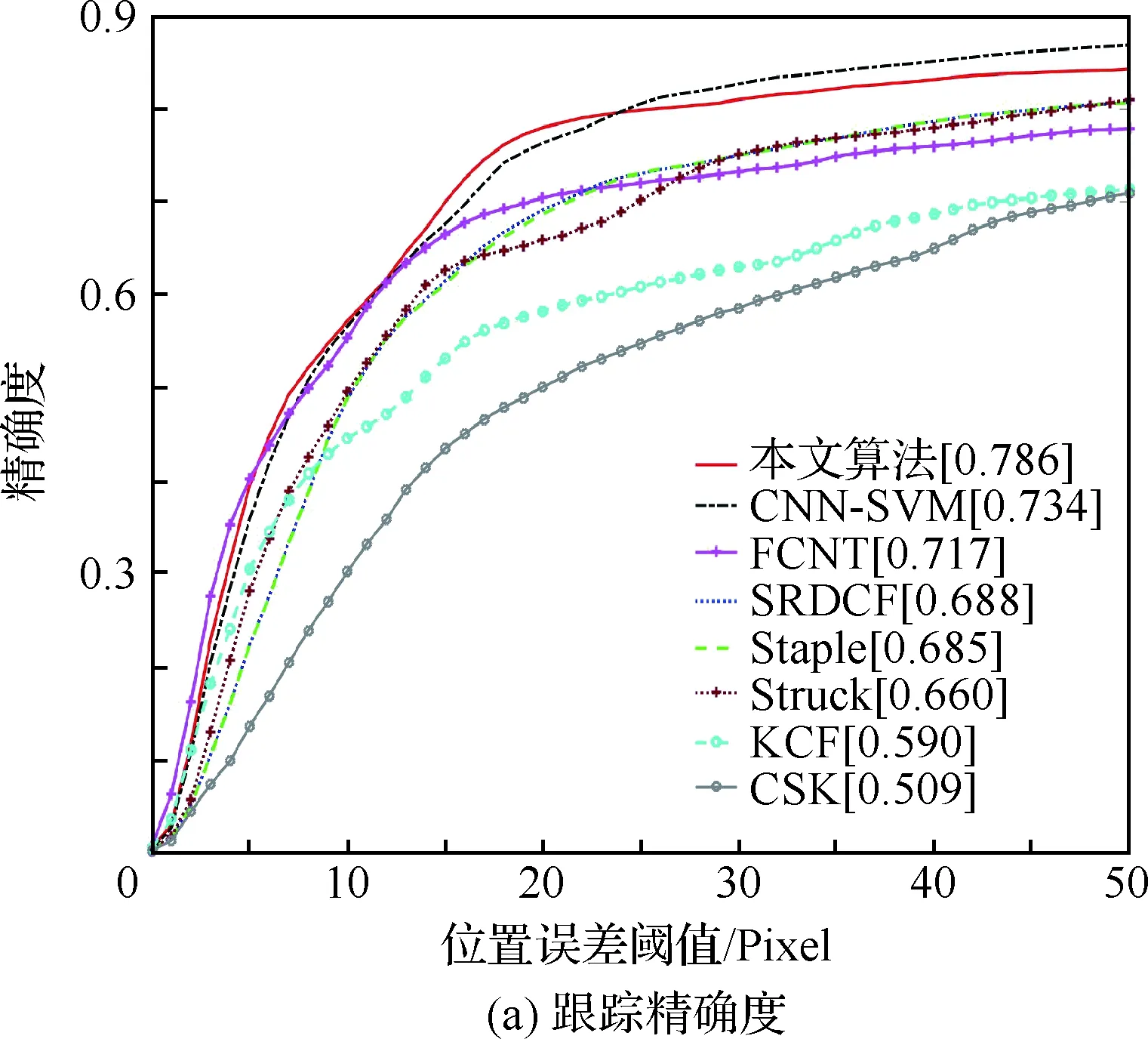

图8 在UAV123数据集的精确度图和成功率图Fig.8 Accuracy maps and success rates in UAV123 data set
4 结 论
本文提出了一种基于自适应深度网络的无人机目标跟踪算法,主要贡献为
1) 设计了一个3阶MPCA-CNN自适应卷积神经网络,为了降低输入的冗余性和加快网络的学习速度,将MPCA作为深度网络的第1层;并对图像的H、S、I通道分别进行主成分分析学习,将得到的特征向量初始化各层卷积核,提取到的特征比传统的卷积神经网络更有效地反映出目标的特征信息,优化了网络结构,提高了网络的收敛速度和精度。
2) 提出了一种根据视频图像的变化情况调整学习速率的算法,该算法通过分析相邻2帧图像的变化,采用分段自适应调整学习率的算法,进行目标模板更新,相较于固定学习速率的跟踪算法具有更强的鲁棒性,可以有效地解决目标遮挡等问题。
3) 仿真实验结果表明,与7种主流跟踪算法相比,该跟踪算法具有较高的跟踪精确度和跟踪成功率,并且取得较低的中心位置误差和较高的覆盖率。但是该算法对于跟踪目标出现长时间遮挡的情况时,容易发生跟踪漂移,若进一步与目标检测算法结合,将会更好地解决目标长时间遮挡等问题。
