ELAB:基于端系统的新型拥塞感知负载均衡机制
2019-03-28陈果张潍丰
陈果,张潍丰
ELAB:基于端系统的新型拥塞感知负载均衡机制
陈果,张潍丰
(湖南大学信息科学与工程学院,湖南 长沙 410082)
良好的负载均衡机制是有效利用数据中心网络带宽的必备条件。现有的等价多路径路由(ECMP)的负载均衡方法由于负载均衡粒度过粗,且不具备对路径拥塞状态感知的能力,因此负载均衡效率较低。为解决此问题,近年来出现了一系列细粒度且具备拥塞感知能力的负载均衡研究工作。然而,这些研究或者需要修改交换机硬件以实时搜集网络各部位的拥塞情况,难以部署;或者虽不需要修改交换机硬件,仅需对端系统的软件进行修改,但由于缺乏准确的网络拥塞信息而导致负载混合效果不佳。针对该问题,提出了一种实现于端系统上的软件解决方案ELAB,该方案不需要对网络中的硬件进行修改,就可以达到良好的负载均衡效果。ELAB创造性地采用了基于可用带宽的方式进行流量负载均衡,相比于现有的基于端系统的方法,ELAB性能提升达20%。
数据中心网络;负载均衡;基于边缘;拥塞感知
1 引言
数据中心承载着人们日常生活中所用到的各种各样的互联网服务,已成为当前云计算时代最重要的基础设施之一。为满足日益增长的性能需求,数据中心网络(DCN, data center network)作为连接数据中心内所有计算和存储资源的“交通枢纽”,需要提供越来越高的网络带宽以支持数据中心内部的大量通信需求[1]。因此,现有数据中心网络多采用基于Clos结构的密集网络拓扑架构[2],通过大量的并行路径,为数据中心提供极高的内部网络带宽。
为了有效地利用整个网络的带宽,目前,在实际环境中多采用等价多路径路由(ECMP, equal cost multi-path)[3]负载均衡机制将网络流量分发到DCN内部的多条并行路径上进行传输。在ECMP机制中,网络中的每个交换机对途经数据分组头部的五元组(源IP、目的IP、源端口、目的端口、协议号)通过散列函数计算散列值,随后根据散列值为数据分组选择传输路径,将不同的数据流散列至不同并行路径上。然而,ECMP方法主要存在以下2个问题:1) 基于流(五元组)进行负载均衡的粒度过粗,常常由于散列冲突导致网络负载不均衡;2) 缺少对路径拥塞状态的感知,因此无法在网络出现非对称的情况下根据各路径的状况进行流量分发。针对ECMP的这2个问题,近年来,出现了一系列工作研究如何为数据中心网络提供更细粒度且具备拥塞感知能力的负载均衡机制[4-8]。
将负载均衡的单元切分为比数据流更细的粒度较为容易,有基于小流(flowlet)[9]、流信元(flowcell)[10]、数据分组[11]等多种方式,但提供高效的动态拥塞感知能力却一直是研究难点。依据负载均衡机制实现拥塞感知的位置,可将现有研究方案分为2类:基于网络的拥塞感知[4-6]和基于边缘的拥塞感知[7-8]。基于网络的拥塞感知以CONGA(congestion aware balancing)[6]为代表。此类方案依赖于在网络中交换机各端口上进行实时的流量监控,判断路径的拥塞程度。由于是对网络内部进行检测,基于网络的拥塞感知可以动态地选择拥塞程度较轻的路径。然而,需要对现有交换机硬件做较大改动,因此难以在实际DCN环境中进行部署。基于边缘的拥塞感知以Clove[7]和Hermes[8]为代表。这类方案实现在端系统上只需修改端系统软件代码即可完成,易于部署。然而,由于缺乏对网络路径实时状况的准确监测信息,因此只能通过往返时延(RTT, round-trip time)或者显示拥塞控制通知(ECN, explicit congestion notification)等信号来猜测最优路径,进行启发式选路。这些信号往往只能从侧面反映路径的状态,而不能准确地表明路径的拥塞程度,尤其是在信号反馈时延较长时对路径拥塞程度的判断更加不准确。因此,这类方案在复杂的真实网络状况下往往性能表现不佳。
由上述分析可知,目前缺乏一种易于部署的具备良好动态拥塞感知能力的负载均衡机制。基于此,本文提出了一种基于边缘的利用可用带宽进行拥塞感知的负载均衡机制(ELAB,edge-based load balancing according to path available bandwidth)。ELAB结合了已有基于网络和基于边缘2类方案的优点,较好地解决了目前负载均衡拥塞感知的难点。ELAB实现在端系统上,不需要对现有网络硬件做任何修改。ELAB接收端通过检测数据分组到达速率,实时计算各条路径的传输速度,从而辅助发送端判断出各条路径的可用带宽。基于此,ELAB可以在不修改现有网络硬件的情况下,在端系统上实现效果良好的拥塞感知负载均衡。
本文在网络仿真平台NS2上实现了ELAB,并将其与现有基于边缘的拥塞感知方法Clove和Hermes进行对比。实验结果表明,在非对称网络情况下ELAB的吞吐率较Clove和Hermes提高了10%~20%。
2 相关工作
数据中心网络的负载均衡是近年来相关领域的研究重点,出现了一系列的相关工作成果。依据是否具备全局的动态拥塞感知能力,负载均衡的方法可总结为2类:静态负载均衡与动态拥塞感知的负载均衡。
静态负载均衡具有代表性的方法研究主要有Presto[10]、DRB[11]和Packet Spray[12]。这类工作主要通过减小负载均衡调度的粒度(如以分组为单位)来实现负载均衡最优的目标,流量均衡过程中不对网络状态进行感知。在对称的网络结构中,静态负载均衡方法能有效地提升负载均衡的效果,然而因为缺乏动态感知拥塞的能力,在网络出现非对称的情况下(如链路故障)表现不佳。
动态拥塞感知的负载均衡动态地监测网络的拥塞状态,从而做出相应的选路决策。该类型工作又可进一步细分为以下2类。
1) 集中式拥塞感知的负载均衡,其典型代表有Hedera[13]、MicroTE[14]和Mahout[15]。这类工作通过集中式控制的方式,监控网络中各部位的负载信息以及数据流情况,随后将数据流重新路由到负载低的路径上。得益于全局的集中式控制,这类工作可以很好地均衡调度数据中心网络中的长流。但其主要的缺陷在于集中式的监控和调度时延太长。具体来说,集中式方法从感知到网络路径状态的变化,到做出集中式调度,往往需要经历数十秒甚至更长的时延[13],难以适应突发短流的负载均衡需求(微秒级)。而本文提出的ELAB机制能在数十微秒内感知路径拥塞并做出相应的负载均衡调整。
2) 分布式拥塞感知的负载均衡,除前文提到的CONGA[6]、Clove[7]、Hermes[8]外,具有代表性的工作还有Flowtune[16]、DRILL[5]等。分布式的方式大大降低了这类工作获取网络拥塞情况的时延,使其可以更好地应对网络拥塞变化。但正如前文所述,这类工作或者需要修改交换机硬件以实时搜集网络各部位的拥塞情况,难以部署,如CONGA;或者虽仅需对端系统的软件进行修改,但无法达到良好的负载均衡效果,如Clove和Hermes。通过本文实验可见,现有最新的基于端系统的负载均衡机制的性能皆远低于理论最优性能。而本文提出的ELAB机制在现有方法的基础上显著地提升了性能,将网络平均流完成时间优化了10%~20%。
3 研究思路
本节首先简单介绍现有基于边缘的负载均衡机制如何进行拥塞感知,通过一个简单的例子论述现有机制选路性能不佳的原因;然后,分析基于可用带宽分配的负载均衡机制能很好地解决该问题,从而引出ELAB的设计出发点;最后,讨论如何在端系统中探测可用带宽,介绍ELAB的设计思路。
3.1 现有基于边缘的负载均衡机制
现有基于边缘的具备动态拥塞感知能力的负载均衡机制主要有2个代表性的方法:Clove和Hermes。与基于网络的方法不同,基于边缘的方法无法准确、实时地获取网络中各路径的拥塞程度,因此多采用RTT或ECN等信号来推测路径的拥塞程度。
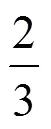
下面通过一个简单的例子,说明现有利用RTT或ECN信号的方法无法做出最佳的选路决策。考虑如图1所示情形(以下简称简单情形),网络中存在2条并行路径,其中路径2的带宽为6 Gbit/s,路径1因为发生故障带宽降为3 Gbit/s。存在一个TCP流经过这2条并行路径发送数据。为了考察网络负载均衡的性能,假设该流入口和出口带宽无限大,从而排除输入/输出端口的影响,使带宽瓶颈出现在网络中。在仿真环境中,流量产生端和接收端到叶子交换机1/叶子交换机2的带宽设置为10 Gbit/s,该网络中每一跳的时延根据实际数据中心环境设置为20 μs,端到端时延为160 μs,叶子交换机至骨干交换机的链路出口队列长度设置为1.8 MB(3倍带宽时延积),ECN阈值设置为600 KB(1倍带宽时延积)。图中spine表示骨干交换机,leaf表示叶子交换机。

图1 简单情形下的网络负载均衡
对图1所示简单情形网络采用不同的负载均衡方案进行仿真,不同方案下网络带宽利用率如图2所示。

图2 简单情形下各负载均衡机制的网络带宽利用率对比
理论上最优的负载均衡情况下,该TCP流应将网络中所有并行路径完全利用,利用率达到100%。然而,Clove和Hermes这2种方法都远没有达到最优的网络利用率,具体原因如下。
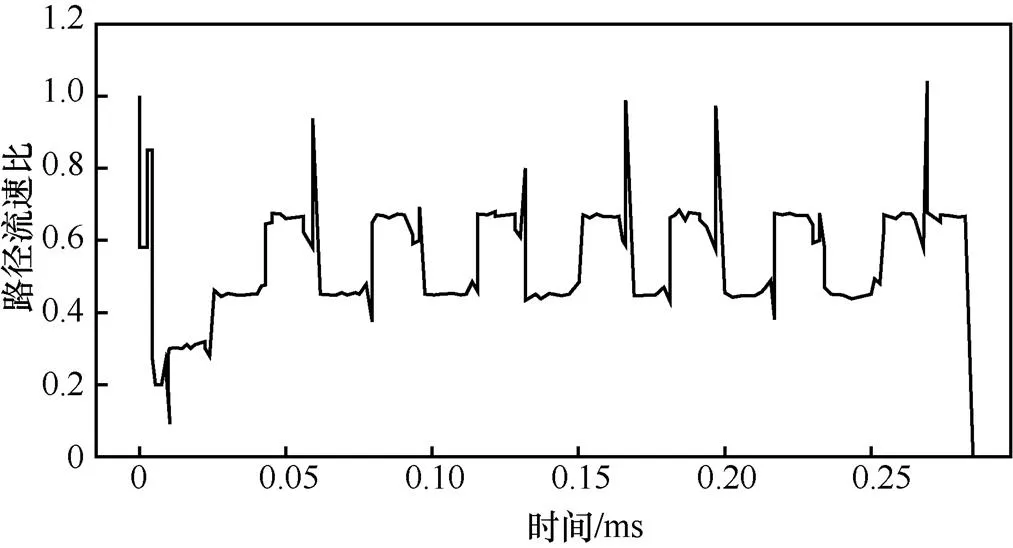
图3 简单情形下Clove中2条路径的流速比(路径1流速:路径2流速)
2) 在Hermes中,初始阶段2条路径的RTT都很小(无排队时延),也没有ECN,因此流量以1:1分到2条路径上。当TCP流速度增至6 Gbit/s,即2条路径速度皆为3 Gbit/s时,路径1的RTT开始上升并收到ECN,被判断为坏路。此时TCP流收到ECN降速并重新进入线性增速阶段。Hermes会将后续的流量全部分发至路径2。直至TCP流吞吐量达到6 Gbit/s时,路径2也会出现ECN且RTT上升,被判断为坏路,此时TCP流收到ECN再次降速。流量在2条路径之间振荡,而无法保持以最优的比例1:2同时将2条并行路径完全利用。图4展示了Hermes对2条路径分配的流量速度比例(路径1流速:路径2流速)。如图4所示,虽然Hermes分配速度比例的振荡中心在0.5附近,但流量一直在2条路径之间大幅切换。这会导致某条路径被用满时TCP流收到ECN降速,而此时另一条路径负载还比较轻。因此,Hermes也无法同时完全利用2条并行路径,达到最优的9 Gbit/s吞吐量。
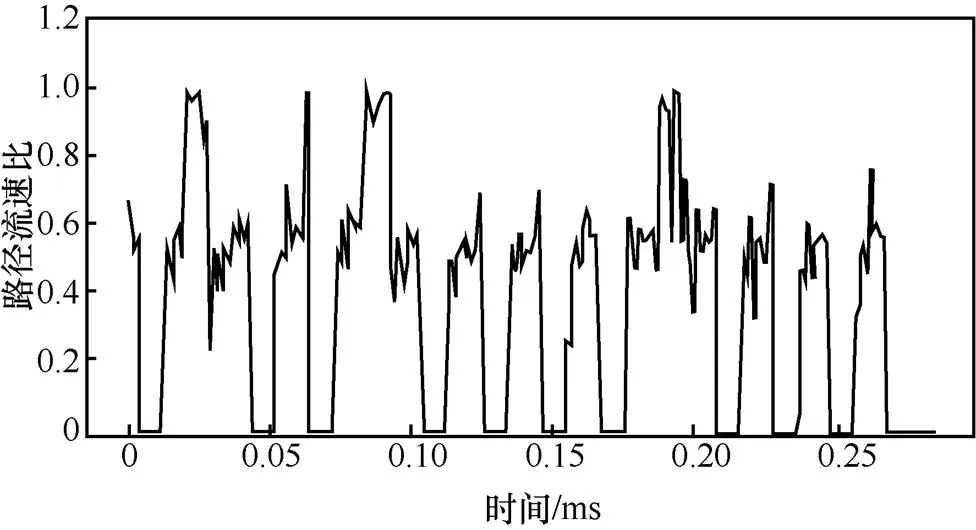
图4 简单情形下Hermes中2条路径流速比(路径1流速:路径2流速)
3.2 基于可用带宽的负载均衡
由上述实验分析可知,现有基于边缘的方法无法做出最优负载均衡决策,其原因在于,仅通过RTT或ECN信号无法准确地反映一条路径的拥塞程度。具体来说,一条路径只有被完全利用出现拥塞时才有可能出现ECN或RTT上升,此时再根据相关信号来选择其他路径为时已晚,TCP已经出现降速,因此无法达到最优吞吐量。此外,即使Clove刻意隐藏ECN信号,虽可避免在探测到某一条路径拥塞时立即出现TCP降速,但仍无法知道其他路径当前的拥塞程度,因此同样不能以最优的比例进行流量分配,后续依然无法使所有路径同时被完全利用。
若想使网络中数据流的吞吐量最大,最优的负载均衡决策需要让网络中所有并行链路利用率相等(即同时完全利用)。要实现这一目标,可以通过基于各条路径当前的可用带宽比例进行流量分配。
同样地,考虑图1所示的简单情形。如果严格按照实时可用带宽的比例进行流量分配,由图2可知,采用基于带宽的方案TCP流的吞吐量可以达到最优的9 Gbit/s,达到99.8%的网络利用率。
因此,基于以上观察,本文所提出的方案ELAB采用基于可用带宽分配流量的负载均衡原则。
3.3 在端系统中探测可用带宽
现有的商用网络设备不支持直接在网络中监测各路径的可用带宽。若想设计一种易于部署、不需要对现有网络硬件进行修改的负载均衡机制,需要在端系统上对网络路径的可用带宽进行探测,这也是ELAB的设计难点所在。

4 ELAB详细设计
本节将介绍ELAB机制的详细设计,描述ELAB如何在边缘上利用可用带宽进行拥塞感知的负载均衡。
4.1 设计综述
ELAB算法实现在端系统上,不需要对现有网络硬件进行修改,其结构如图5所示。ELAB作为中间层,实现在端系统协议栈中的网络层和传输层之间,通过隧道封装/解封装的方式在端系统上实现负载均衡选路。ELAB对上层传输层完全保持透明,不需要对现有传输层协议做任何修改。
在发送端,ELAB将传输层发来的数据分组进行隧道封装,加入一个传输层隧道分组头(L4 tunnel header)用于选路。因为现有数据中心网络硬件皆采用ECMP的选路方式(即对数据分组头的五元组进行散列选路),所以在不改变已有网络硬件的前提下,可以通过改变隧道头中五元组的方式来在端系统上进行主动选路。本文中每个不同的隧道五元组在被称为一条虚拟路径(VP, virtual path)。如前文所述,ELAB为每一对通信节点之间维护一个VP状态表,不断监测各条VP上的可用带宽,从而进行拥塞感知的动态选路。
在接收端,ELAB将接收到的数据分组去除隧道头,将数据分组还原后交给上层协议处理。同时,它也为每一对通信节点之间维护一个VP状态反馈表。该表的功能是记录每个虚拟路径上最近一段时间内接收到的数据分组数量,并在适当时将这个信息送至发送端以计算路径拥塞状态。
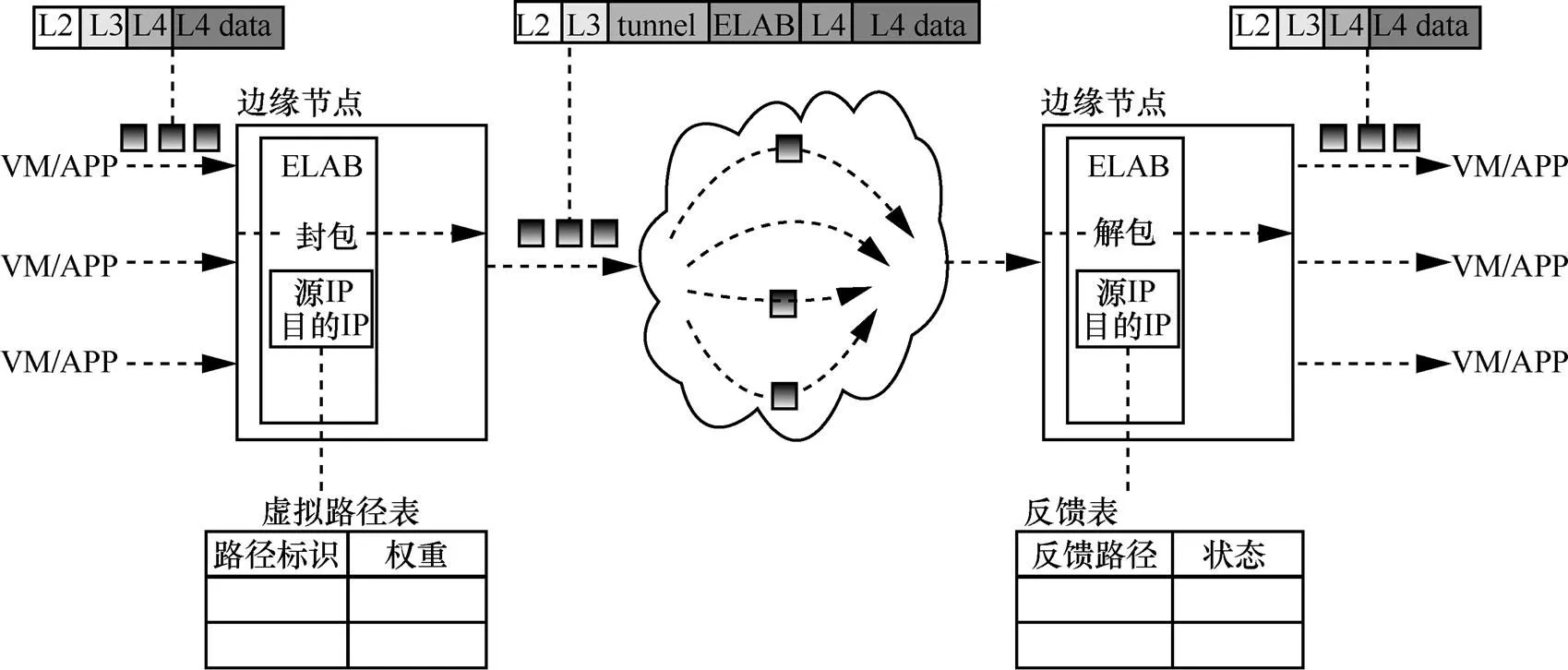
图5 ELAB总体结构
本文在没有特殊说明的情况下,所有的讨论均为一对通信节点之间。通信节点对可以通过源/目的IP地址来进行标识。所有的ELAB节点间通信为双向通信,即每一个节点既是ELAB发送端,也是ELAB接收端。
4.2 ELAB数据分组头部格式
ELAB数据分组结构如图6(a)所示。ELAB在原来数据分组的网络层头部和传输层头部之间加入了一个传输层隧道头(L4 tunnel header)。此外,ELAB在发送端和接收端之间还需传输一些必要的信息以计算路径的拥塞状态,因此,ELAB在传输层隧道分组头之后插入了一个自定义的ELAB信息头(ELAB info header),具体分组格式如图6(b)所示。
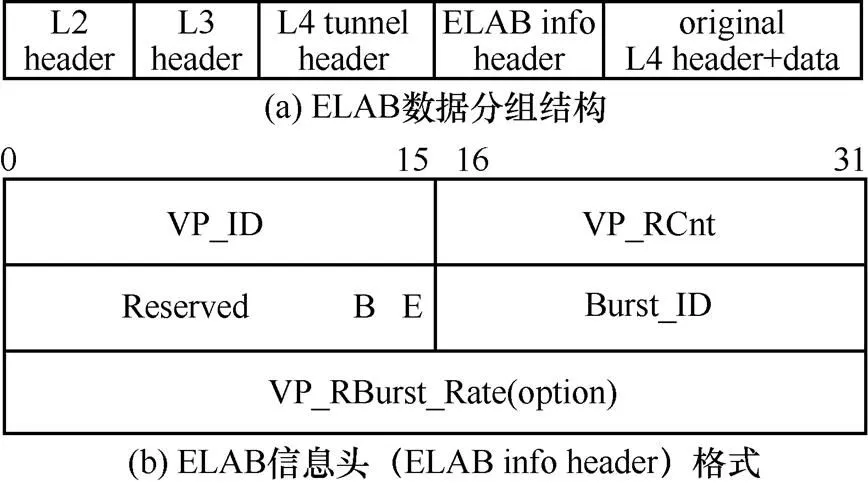
图6 ELAB数据分组结构及ELAB信息头格式
传输层隧道头在保持现有网络ECMP路由不变的情况下,在端系统上选择不同的网络传输路径。现有数据中心网络通常采用的传输层隧道格式有VXLAN[17]和SSTP[18]等。本文为描述简单,ELAB采用了分组头长度最小的UDP隧道头。具体地,在原有数据分组的三层分组头和四层分组头之间插入一个新UDP头部,其内容如下:1) 用一个特殊的UDP目的端口号来标识该流量是ELAB产生的流量;2) 将UDP头中不同的源端口号作为不同VP的标识。因此,ELAB通过对不同数据分组设置不同的UDP隧道头中的源端口号,即可实现主动选路。
ELAB信息头用于在ELAB发送端和接收端之间传输计算拥塞状态所需的必要信息。此处先仅对各字段的含义做简要介绍,后文将详细介绍在发送端和接收端如何设置这些字段以及如何利用这些字段计算各路径的拥塞状态。ELAB信息头具体包括如下字段。
1) VP_ID(16位)和 VP_RCnt(16位)。用于接收端反馈某条虚拟路径在最近一段时间内接收到的数据分组数量。VP_ID表示当前所反馈的VP的标识。VP_RCnt为VP状态反馈表中该VP接收的数据分组数目。
2) Reserved(14位)。保留字段,暂未使用。
3) B(1位)和E(1位)。这2个标志位皆由ELAB接收端反馈时设置。E位表示最近在该虚拟路径上是否接收到被ECN标记的数据分组。B位表示该数据分组中是否携带有路径探测速率的反馈信息。
4) Burst_ID(16位)。由发送端设置。若该数据分组为路径速率探测分组,则发送端将该字段设置为该探测分组的探测序号。
5) VP_RBurst_Rate(32位)。可选字段,由接收端反馈时设置。当B位为1时,该字段表示该路径的探测速率;B位为0时,无该字段。
4.3 虚拟路径空间的选取
本节简单介绍ELAB对虚拟路径空间的选取。前文提到利用传输层隧道头中的源端口号作为虚拟路径的标识。然而,不同的虚拟路径可能被底层网络的ECMP路由散列到同一条物理路径之上。如果盲目地选择一段源端口号范围作为传输中使用的虚拟路径空间,则既有可能无法覆盖网络中所有的并行路径,也有可能导致大部分虚拟路径对应的是少数相同的物理路径,这2种情况都会严重地影响选路效率。针对此问题,ELAB采用了经典Paris traceroute机制[19],在初始化阶段对虚拟路径进行探测,从而选出对应不同物理路径的虚拟路径。
在新通信节点对之间产生流量时,ELAB会对该通信节点对之间的虚拟路径空间进行初始化。初始化时,随机产生源端口号,向目的地址发送一组带有不同源端口号的traceroute。借助这些traceroute的反馈信息,即可知道不同源端口号经过的具体路径。为了完善虚拟路径表,需要随机产生多组源端口号不同的探测分组,尽可能地将网络中所有的并行路径探测出来。当反馈回的物理路径信息与已完成探测的虚拟路径不一致时,即被认为是新的并行物理路径,加入虚拟路径空间中。
值得注意的是,以上虚拟路径空间的初始化探测在新通信对之间第一次出现流量时进行,后续过程中仅需以极低的频率周期性地探测即可(为应对网络拓扑变化),引入的网络开销很低。
4.4 基于可用带宽的选路
本节将具体介绍ELAB如何根据可用带宽动态地选路。
4.4.1 选路函数
在ELAB发送端,为每一条虚拟路径维护上限带宽、实际发送速度以及可用带宽几个状态,分别如下。
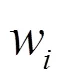
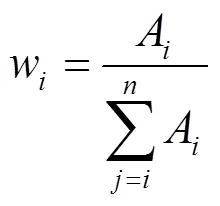
具体做法为在每次有数据分组从发送端发出时,ELAB都会以上述比例轮询地从各条VP中选择一条,将数据分组从该VP发送出去。
4.4.2 路径发送速度R的探测
ELAB发送端依赖于接收端的配合来实时探测每条路径的实时发送速度。ELAB接收端为每一对通信节点之间维护一个VP状态反馈表。该表的功能是记录每个虚拟路径上最近一段时间内接收到的数据分组的数量。具体来说,ELAB接收端每收到一个数据分组时,会将其对应的VP接收数量加1;而每当接收端有数据分组发回发送端时,ELAB会以轮询的方式依次将VP状态反馈表中各条VP收到的数据分组数量反馈给发送端,同时将该轮反馈过的VP接收到的数据分组数量清零。

4.4.3 路径上限带宽B的探测
如2.3节所述,网络可能出现故障或者有其他流竞争,所以需要动态地对VP的上限带宽进行探测。发送端对于第条VP的上限带宽B的更新有如下3种方式。
1) 初始化。B在初始阶段被初始化为链路的物理带宽,利用该值初始化能够减少选路稳定的时间。链路的物理带宽可由网络管理员手动输入。
2) ECN重置。当一条个路径收到ECN标记,则说明该路径当前处于满负载的状态。基于这一点,可以根据当前该路径上的实际发送速率来估计其上限带宽。具体地,当收到接收端发回的数据分组中E字段被置位时,则将该路径的上限带宽B更新为R。
5 实验评价
5.1 实验环境介绍
在NS2[20]网络仿真平台上实现了ELAB机制。为了对比性能,在NS2中还实现了目前已有的2个基于边缘的动态拥塞感知算法—Clove和Hermes。因为CONGA等方法需要修改网络硬件,无法满足本文的需求,所以故不做对比。
5.2 专门实验深入分析ELAB
5.2.1 简单非对称场景
第2节中对ELAB在图1中所示的场景进行评价,从图2所示的仿真结果可以看到,ELAB的网络带宽利用率达到了87%。
图7展示了ELAB对2条路径路所分配的流量速度比例(路径1流速∶路径2流速)。可以看出,可见ELAB的算法能很好地模拟出基于可用带宽的分配。
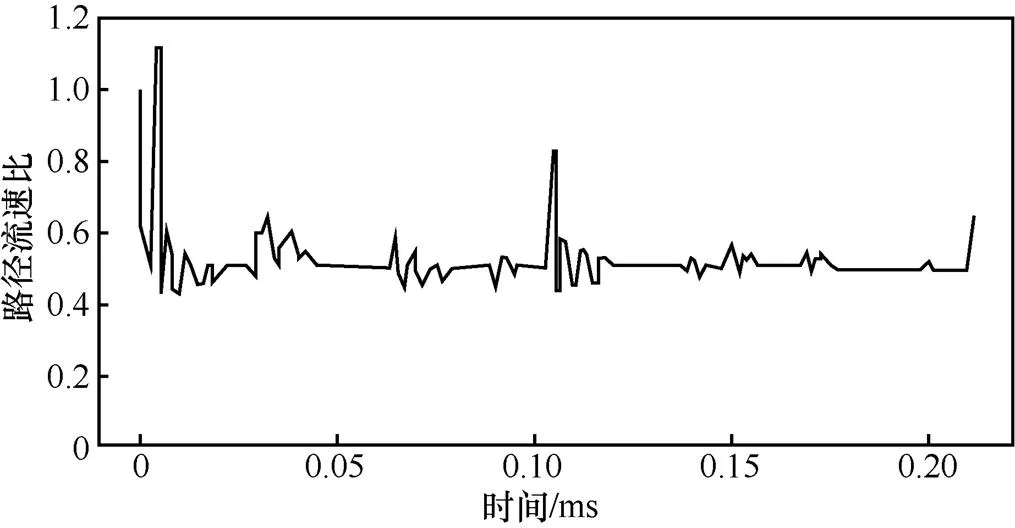
图7 简单情形下ELAB中2条路径路所分配的流速比(路径1流速:路径2流速)
5.2.2 非对称网络下与其他流竞争的场景
除上述简单非对称场景外,本文还进一步设计了非对称网络下与其他流竞争的场景(以下简称竞争场景),来评估ELAB的性能。实验网络如图8所示。
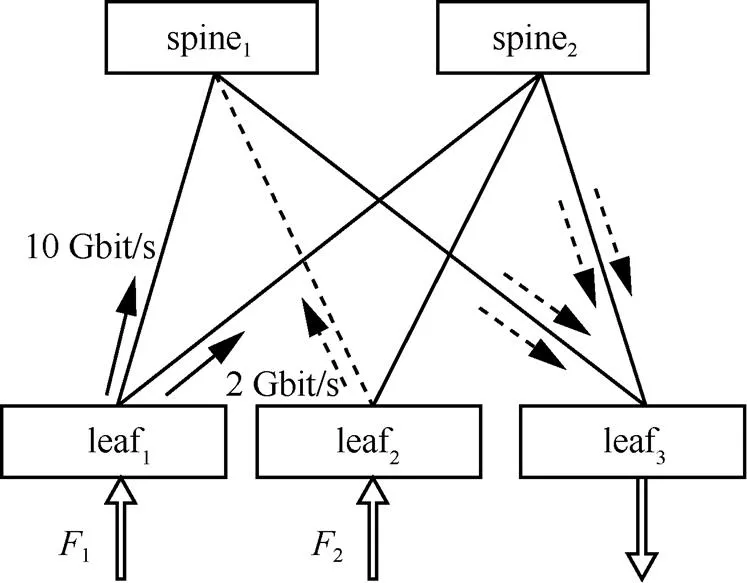
图8 非对称网络下与其他流竞争的场景

图9展示了竞争场景下各方法的平均流完成时间(FCT, flow completion time)对比。图中各方法的流完成时间均对基线方法ECMP进行了归一化。可以看到,在此场景下,ELAB的性能依然最佳,相比于ECMP、Clove和Hermes分别将流完成时间缩短了31%、24%、3%。
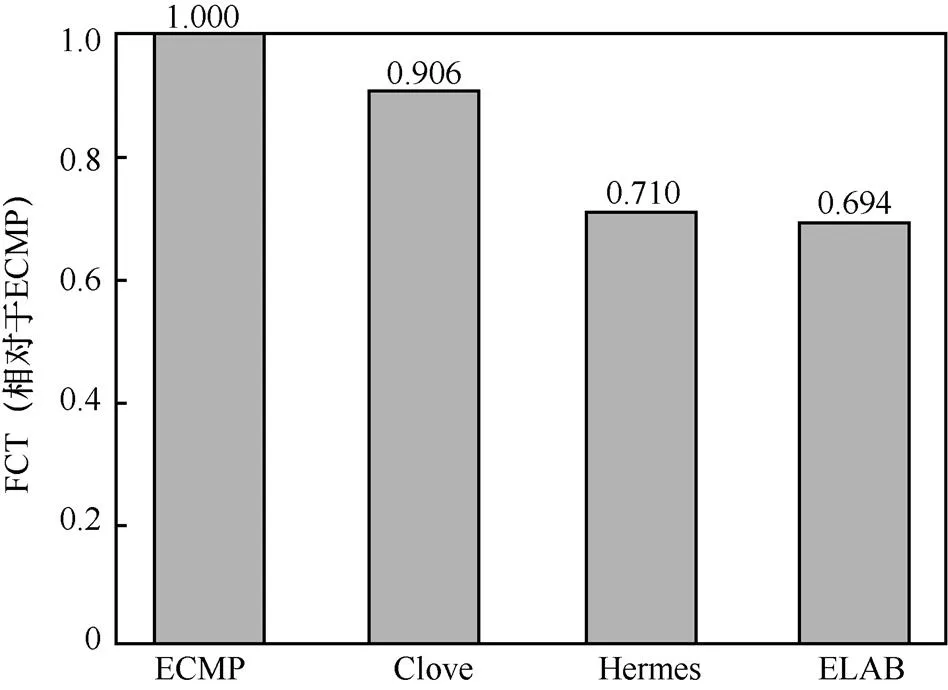
图9 竞争场景中各方法的平均流完成时间对比
图10展现了竞争场景下各方法中2条流1和2各自的分路比例随时间的变化。其中比例计算方式皆为经spine1发送的流量:经spine2发送的流量。从图10可知,ELAB中2主要将流量分配至经spine2的好路径,而避开了经spine1的故障路径;同时1也相应地将主要流量分配至经spine1的路径,从而避免了与2在spine2上竞争。因此,ELAB能在此情景下取得较好的平均流完成时间。相反,不论是Clove还是Hermes,从图10都能看出对于2条路径的分流比例并不合理。其中2还会频繁地将流量发送至故障路径spine1上,因此流完成时间不佳。
5.3 大规模仿真实验
本文构造了一个大规模leaf-spine拓扑网络。如图11所示,在该拓扑结构中有4个核心层交换机节点和4个接入层交换机节点。每个核心层交换机与所有的接入层交换机相连,组成了一个全链接的网络。每个接入层交换机与16台底部主机相连,整个网络共有64台主机。交换机之间的链路带宽为40 Gbit/s,交换机与主机之间的链路带宽为10 Gbit/s。交换机的缓冲队列长度设置为3 MB,并且ECN阈值设置为缓存队列长度的30%。网络中每一跳的时延设置为20μs。本文将利用这种拓扑结构分别评估各方法在对称网络和非对称网络(网络中某些链路出现故障)下的负载均衡性能。
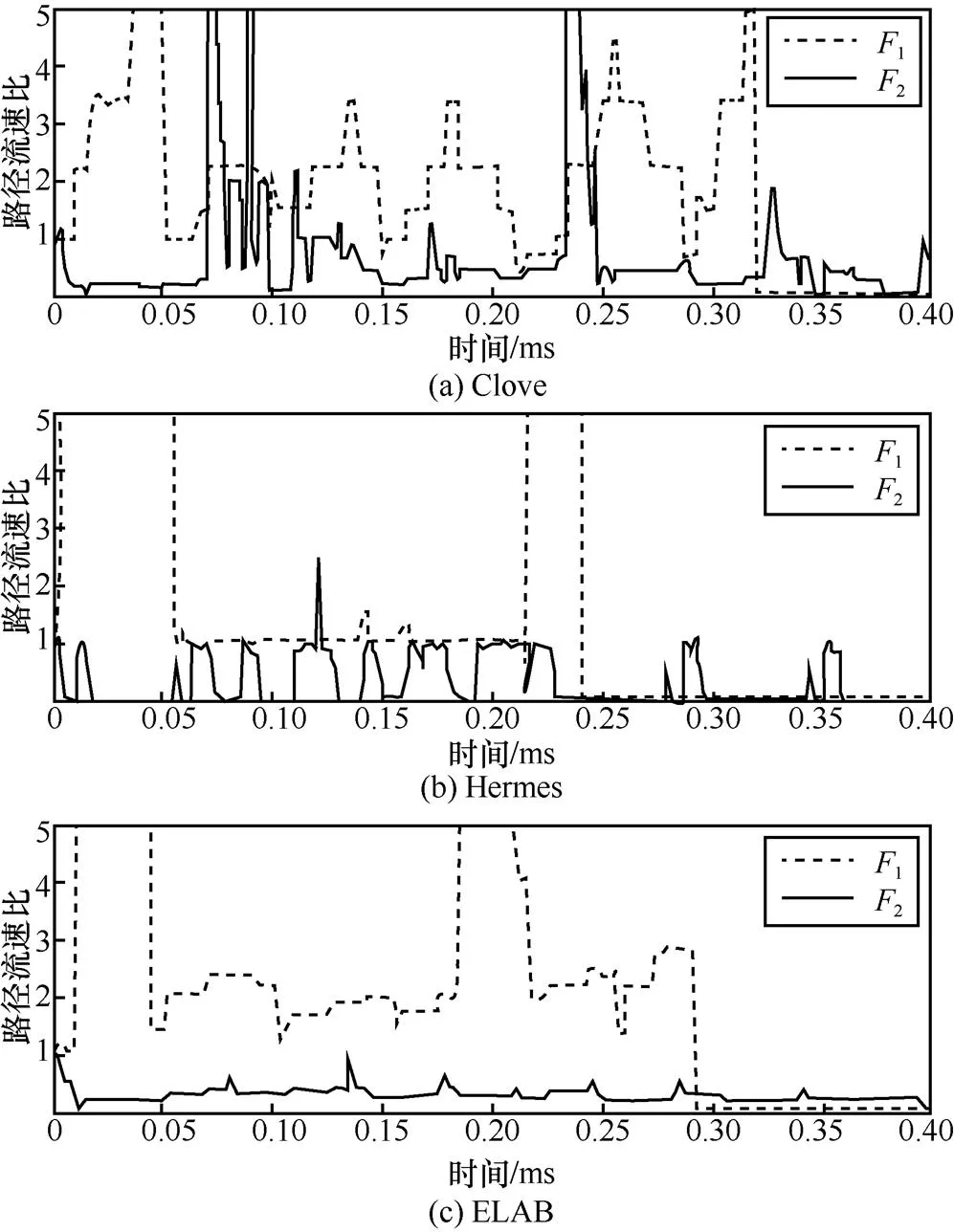
图10 竞争场景中各方法的路径流速比随时间的变化
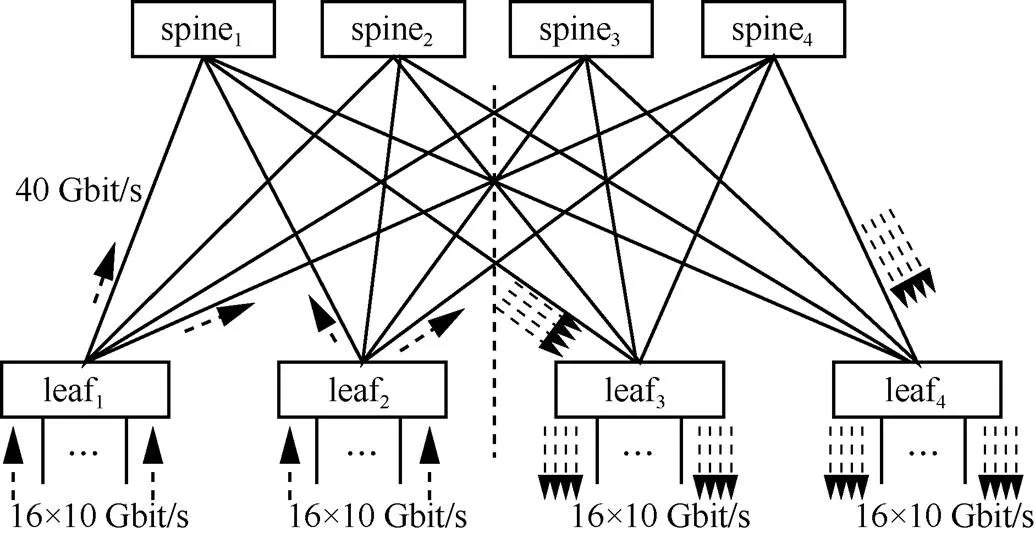
图11 大规模网络仿真
根据真实数据中心的网页搜索(Web-search)[8]流量记录,在该网络拓扑中生成流量。由于本文研究的是负载平衡对网络性能的影响,因此以图11左半部分网络的32台主机为每个流量的源主机,在图11右半部分网络的不同的位置随机选择每个流量的目的主机,从而使所有流量都经过网络。通过调整节点生成流量的间隔长度来达到不同的网络负载强度。遵循先前工作的惯例,本文使用FCT作为主要的性能衡量指标。
5.3.1 对称网络
图12展示了大规模网络情形下各机制的平均流完成时间(对ECMP进行归一化)。从图12可知,无论在轻度负载还是重度负载情况下,ELAB、Clove和Hermes表现都类似,稍微优于ECMP。ELAB整体较Clove、Hermes有1%~3%的优势。
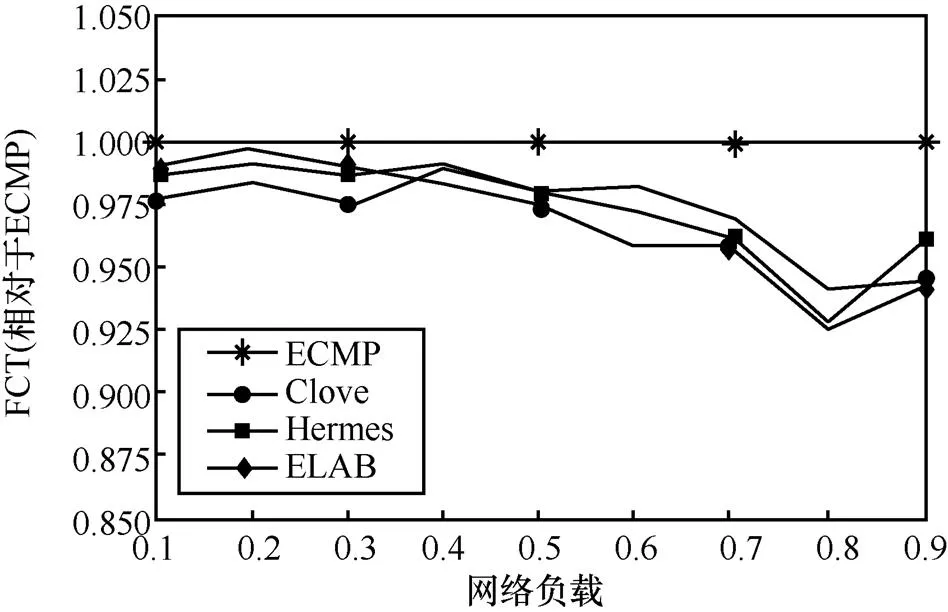
图12 对称网络中,不同负载下各机制的平均流完成时间(大规模仿真)
5.3.2 非对称网络
图13展示了该情形下各机制的平均流完成时间(对ECMP进行归一化)。从图13可知,在网络负载较轻时,ELAB、Clove和Hermes都表现类似,优于ECMP。当负载高于0.5时,ELAB开始呈现出明显的优势,平均流完成时间较Clove和Hermes分别降低了7%~22%和17%~26%。
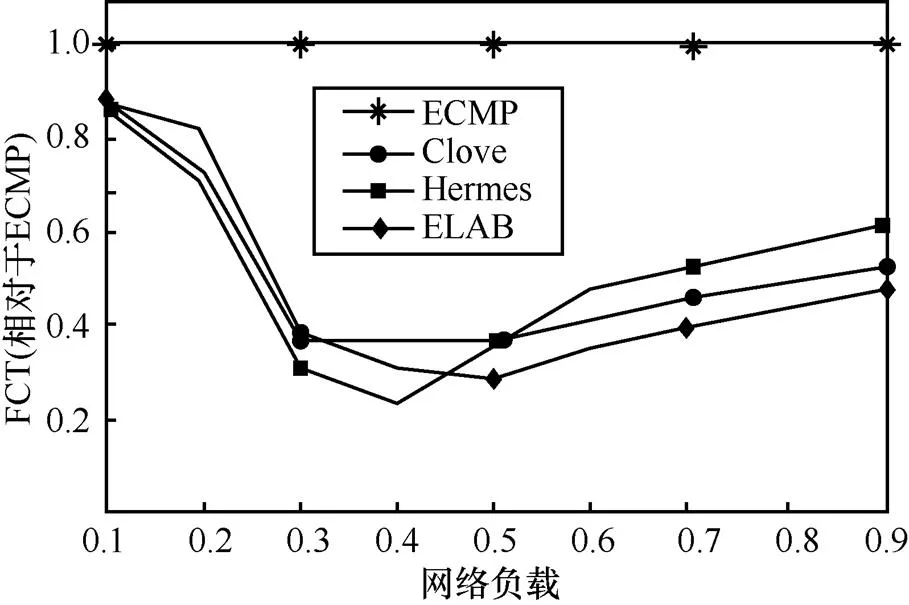
图13 非对称网络中,不同负载下各机制的平均流完成时间(大规模仿真)
6 结束语
人们对网络带宽需求的日益增高,也对数据中心网路的负载均衡机制提出了更高的要求。当前生产环境中采用的ECMP负载均衡机制选路粒度粗,缺乏动态拥塞感知能力,性能不佳。现有其他细粒度且具备动态拥塞感知能力的方案,或需要对网络硬件进行修改,难以部署;或仅需修改端系统软件,但拥塞感知不准,性能不佳。本文提出的ELAB方案是一种基于边缘的利用可用带宽进行拥塞感知的负载均衡机制,既不需要对网络硬件进行改动,又能准确感知拥塞实现良好的负载均衡效果。实验结果表明,在非对称网络情形下,ELAB能将现有方法的吞吐量提升10%以上。ELAB利用可用带宽进行流量分配的思路,解决了现有方法的难点,为数据中心网络的负载均衡机制提供了一种新的思路。
[1] BENSON T, AKELLA A, MALTZ D A. Network traffic characteristics of data centers in the wild[C]//The 10th ACM SIGCOMM Conference on Internet Measurement. 2010: 267-280.
[2] SINGH A, ONG J, AGARWAL A. Jupiter rising: a decade of clos topologies and centralized control in google’s datacenter network[J]. ACM SIGCOMM Computer Communication Review, 2015, 45(4): 183-197.
[3] HOPPS C E. Analysis of an equal-cost multi-path algorithm[R]. Request for Comments 2992, 2000.
[4] KATTA N, HIRA M, KIM C. Hula: scalable load balancing using programmable data planes[C]//The Symposium on SDN Research. 2016: 10.
[5] GHORBANI S, GODFREY B, GANJALI Y. Micro load balancing in data centers with DRILL[C]//The 14th ACM Workshop on Hot Topics in Networks. ACM, 2015: 17.
[6] ALIZADEH M, EDSALL T, DHARMAPURIKAR S. CONGA: distributed congestion-aware load balancing for datacenters[J]. ACM SIGCOMM Computer Communication Review, 2014, 44(4): 503-514.
[7] KATTA N, HIRA M, GHAG A. CLOVE: how I learned to stop worrying about the core and love the edge[C]//The 15th ACM Workshop on Hot Topics in Networks. 2016: 155-161.
[8] ZHANG H, ZHANG J, BAI W. Resilient datacenter load balancing in the wild[C]//The Conference of the ACM Special Interest Group on Data Communication. 2017: 253-266.
[9] VANINI E, PAN R, ALIZADEH M. Let it flow: resilient asymmetric load balancing with flowlet switching[C]//USENIX Symposium on Networked Systems Design and Implementation. 2017: 407-420.
[10] HE K, ROZNER E, AGARWAL K, et al. Presto: edge-based load balancing for fast datacenter networks[J]. ACM SIGCOMM Computer Communication Review, 2015, 45(4): 465-478.
[11] CAO J, XIA R, YANG P. Per-packet load-balanced, low-latency routing for clos-based data center networks[C]//The 9th ACM Conference on Emerging Networking Experiments and Technologies. 2013: 49-60.
[12] DITTMANN G, HERKERSDORF A. Network processor load balancing for high-speed links[C]//The 2002 International Symposium on Performance Evaluation of Computer and Telecommunication Systems. 2002, 735.
[13] AL-FARES M, RADHAKRISHNAN S, RAGHAVAN B, et al. Hedera: Dynamic flow scheduling for data center networks[J]. USENIX Symposium on Networked Systems Design and Implementation, 2010, 10: 19.
[14] BENSON T, ANAND A, AKELLA A. MicroTE: fine grained traffic engineering for data centers[C]//The 17th Conference on emerging Networking Experiments and Technologies. 2011: 8.
[15] CURTIS A R, KIM W, YALAGANDULA P. Mahout: low-overhead datacenter traffic management using end-host-based elephant detection[C]//INFOCOM. 2011: 1629-1637.
[16] PERRY J, BALAKRISHNAN H, SHAH D. Flowtune: flowlet control for datacenter networks[C]//USENIX Symposium on Networked Systems Design and Implementation. 2017: 421-435.
[17] MAHALINGAM M, DUTT D, DUDA K. Virtual extensible local area network (VXLAN): a framework for overlaying virtualized layer 2 networks over layer 3 networks[R]. Request for Comments, 7348,
[18] KIM Y J, KOLESNIKOV V, KIM H. SSTP: a scalable and secure transport protocol for smart grid data collection[C]//2011 IEEE International Conference on Smart Grid Communications (SmartGridComm). 2011: 161-166.
[19] AUGUSTIN B, CUVELLIER X, ORGOGOZO B, et al. Avoiding traceroute anomalies with Paris traceroute[C]//The 6th ACM SIGCOMM conference on Internet measurement. 2006: 153-158.
[20] ISSARIYAKUL T, HOSSAIN E. Introduction to network simulator NS2[M]. Springer Science & Business Media, 2011.
ELAB: end-host-based congestion aware load balancing for data center network
CHEN Guo, ZHANG Weifeng
College of Computer Science and Electronic Engineering, Hunan University, Changsha 410082, China
A good load balance mechanism is the key to effectively use the network of the data center network. In current production data center, ECMP is the de facto load balancing scheme. However, it has two drawbacks. 1) the load balance unit is too coarse-grained, 2) it’s not congestion aware. To solve these problems, several fine-grained and congestion-aware load balancing works have emerged in recent years. These works either need to modify the switch hardware to collect congestion in various parts of the network in real time, and it is difficult to deploy; or only need to modify the end system, but the inaccurate sense of congestion cannot achieve a good load balancing effect. A novel edge-based load balancing scheme ELAB was proposed, which addresses above existing problems and improves the network performance up to 20%.
data center network, load balancing, edge-based, congestion aware
TP393.1
A
10.11959/j.issn.1000−436x.2019054
2018−06−25;
2018−08−24
陈果(1989− ),男,湖南长沙人,博士,湖南大学副教授,主要研究方向为计算机网络系统、数据中心网络。

张潍丰(1997− ),男,广东新会人,主要研究方向为计算机网络系统、计算机系统结构。
