深度学习基础上的中医实体抽取方法研究*
2019-03-27张艺品吕荫润吴炳潮王永吉毕诗旋
张艺品 关 贝 吕荫润 王 翀 吴炳潮 王永吉 毕诗旋
(1中国科学院软件研究所协同创新中心 北京100190) (1中国科学院软件研究所协同创新中心 北京100190) (2中国科学院大学 北京 100049) (2中国科学院大学 北京 100049) (3中国科学院软件研究所计算机科学国家重点实验室 北京 100190) (1中国科学院软件研究所协同创新中心 北京100190) (1中国科学院软件研究所协同创新中心 北京100190) (2中国科学院大学 北京 100049) (2中国科学院大学 北京 100049) (3中国科学院软件研究所计算机科学国家重点实验室 北京 100190) (北京工业大学 北京 100190)
1 引言
中医知识图谱是对中医知识内容的结构化存储、语义化表示,有助于实现中医知识的检索、推送与可视化,也是中医辅助诊断系统的底层数据核心。知识抽取是知识图谱构建研究的重要问题,其分为两个模块,即抽取实体与实体间关系,本文在中医领域中就实体抽取问题进行研究。
中医典籍是中医知识的重要来源,从中医典籍中抽取知识是中医知识图谱规模化和知识全面化的必然要求。中医典籍作为一种非结构化的自然语言,其文法和词法与白话语言多有不同。以《备急千金方》的一段方剂为例,观察发现中医典籍中有大量的生僻词,且语法与现在普通汉语有极大的不同,分词困难。此外中医方剂往往参照其主药命名,命名实体间易存在嵌套关系,如“泽兰汤”与“泽兰”、“茯神煮散”与“茯神”、“半夏补心汤”与“半夏”等。另外不同医书对于中医内容的阐述习惯不同,没有统一标准。
传统实体抽取方法需要手动构建特征,如词性标注、解析语法树等,这些方法难以适用于中文文言文形式的中医典籍。为适应中医典籍的特点需手动构建更为复杂的特征,这无疑会在源数据中引入大量额外内容增加计算负荷。此外特征构建需要详细的设计,耗时耗力且迁移性较差。为解决上述问题,本文采用深度学习方法来实现知识获取模块的实体抽取。根据中医典籍文本特点,设计字级别的基于BiLSTM-CRF的实体抽取模型。通过字向量来表征字所携带的语义信息,利用双向的长短期记忆神经网络获取字的上下文表征向量。最后将上下文表征向量作为条件随机场的直接输入,利用其求取全局最优标注序列的特性,完成整个句子的序列标注。
2 相关研究
2.1 命名实体识别
实体抽取是知识图谱自动化构建的核心,决定知识图谱的质量与规模。实体抽取又称为命名实体识别(Named Entity Recognition,NER),是自然语言处理(Natural Language Processing,NLP)中的一项基础任务,是指从文本中识别出命名性指称项,如人名、地名和组织机构。在不同领域中其定义的实体类型也不同,本研究抽取的实体是中医领域的中药材、方剂、病症3类实体。命名实体抽取的技术与方法主要有3种:基于规则和知识的方法、基于统计的方法以及两者混合的方法。基于规则和知识的方法通过观察文本结构特征,人工设计规则,利用正则表达式等方式抽取实体,对于简单的命名实体识别任务十分简捷高效[1],但对于复杂的任务要避免规则间的相互冲突,制定规则需要消耗大量的时间和精力,可移植性差。基于统计学习的方法将命名实体识别看成序列标注问题[2],采用隐马尔可夫模型(Hidden Markov Model,HMM)、最大熵模型、条件随机场等机器学习序列标注模型[3-6]。Zhou和Su等[7]设计4种不同的特征,提高隐马尔可夫模型在实体抽取任务中的效果。Borthwick等[8]在最大熵模型中通过引入额外的知识集合提高标注的准确性。Lafferty等[9]提出将条件随机场用于序列标注任务,后来McCallum和Li[10]提出特征自动感应法,将条件随机场应用于命名实体识别任务中。
2.2 模型应用
近年来随着深度学习的兴起,将深度神经网络模型应用到NER任务中取得较好的效果。Collobert等[11]于2011年提出统一的神经网络架构机器学习算法,将窗口方法与句子方法两种网络结构用于NER,对NN/CNN-CRF模型进行对比试验。2013年Zheng等[12]在大规模未标记数据集上改进中文词语的内在表示形式,使用深度学习模型发现词语的深层特征以解决中文分词和词性标记问题。借鉴Collobert的思路2016年左右出现一系列使用循环神经网络(Recurrent Neural Network,RNN)结构并结合CRF层进行NER的工作[13-15],模型主要由Embedding层,双向RNN层以及最后的CRF层构成。2016年Rei M等[16]在RNN-CRF模型结构的基础上重点改进词向量与字符向量的拼接方法,使用Attention机制将原始的字符向量和词向量拼接改进为权重求和。模型通过双层神经网络学习Attention的参数,动态地利用词向量和字符向量信息,实验表明比原始的拼接方法效果更好。之后AkashBharadwaj等[17]在原始BiLSTM-CRF模型的基础上加入音韵特征,在字符向量上使用Attention机制来学习关注更有效的字符。2017年Yang Z等[18]采用迁移学习的方式在小量标注数据集进行实体识别任务。同年Matthew E. Peters等[19]使用海量无标注语料库训练双向神经网络语言模型,通过这个模型来获取当前要标注词的语言模型向量,然后将该向量作为特征加入到原始的双向RNN-CRF模型中。实验结果表明在少量标注数据上加入这个语言模型向量能够大幅度提高NER效果,即使在大量的标注训练数据上加入这个语言模型向量仍能提高原始RNN-CRF模型效果。本文采用基于BiLSTM-CRF的方法,利用双向RNN累积获取上下文信息的特性,条件随机场对全部特征全局归一化,获取全局最优解。
3 基于深度学习的中医实体抽取
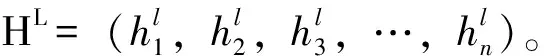
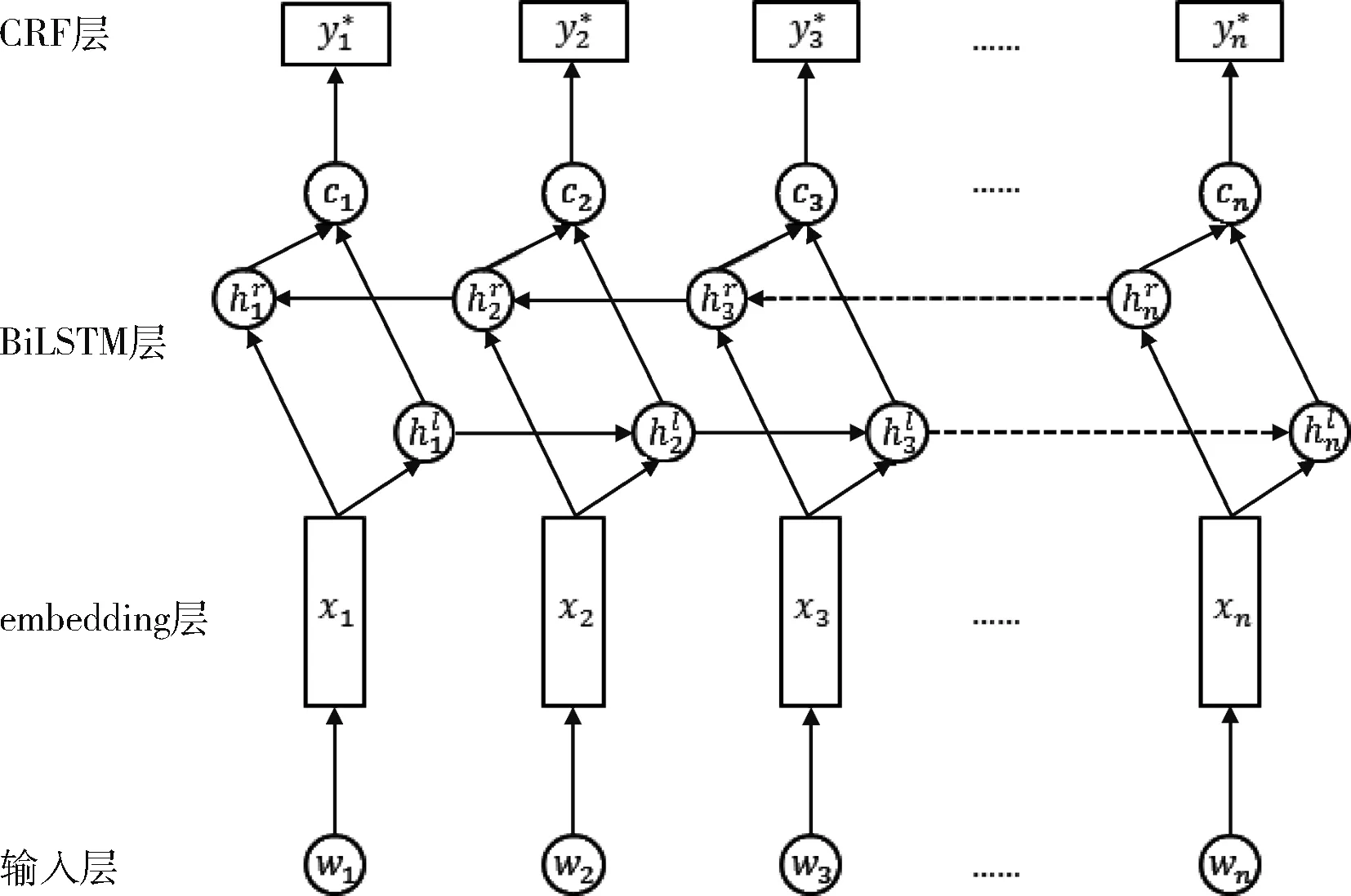
图1 基于字的BiLSTM-CRF模型结构
最后为CRF层,目标是依照上下文表征向量序列得到标注序列。可以依照每个词的上下文表征向量ci,使用分类算法如softmax直接得出每个字标注目标的概率。但是在命名实体识别任务中前后的标注结果之间具有强依赖性。如药方实体的起始(B-PRE),接下来一定不可能是中药材实体的内部内容(I-MED)。因此用CRF对整个句子进行联合建模,以保证在全局上生成最优标注序列。对于双向LSTM输出的C,通过全连接层(W,b),将其转换为n×k的矩阵P,其中k为目标标签的种类数量。pi,j表示第i个字标记为第j个标签的得分。对于给定预测序列Y=(y1,y2,…yn),其得分为:
(1)
其中A为条件随机场的状态转移矩阵,是k+2阶的方阵,Ai,j表示从标签i转移到标签j的得分。之后接入softmax层实现归一化,对于序列Y,其概率为:
(2)
在训练阶段,对于X的正确标注序列T=(t1,t2,…,tn),用梯度下降算法最大化log似然函数:
(3)
在预测阶段,预测结果记为Y*:
(4)
通常通过维特比算法等动态规划方法得到最优解。
4 实验结果与分析
4.1 Word2Vec
模型中embedding层使用Word2vec训练的字向量初始化参数,在模型训练时进行参数微调。使用Google开源的gensium[20]工具包,其提供python版本的Word2vec。语料方面,使用维基百科提供的Latest Chinese Article语料[21]与中医典籍语料的拼接作为Word2vec的训练语料。在经过opencc繁简体转换、移除non-utf8字符、统一不同类型标点符号、空格处理、分字得到2.01G的未标注语料。字向量的训练使用CBoW模型,窗口大小设为10,字向量维度设为300。
4.2 数据集和评价指标
实验选用中医典籍《备急千金方》、《千金翼方》、《神农本草经》作为语料。在实体抽取算法实验中,为减小模型训练的计算复杂度,加快训练速度,将长句分割为不超过50字的短句。通过字典匹配与人工校对方式构建试验语料,选用万方中医药知识库的病症方剂中药材字典。训练数据集共39 100条标注样本,其中32 000条为训练集,7 100条为测试集,共设置3类命名,即中药材、方剂、病症实体。数据集采用BIO标注体系,即B表示实体的起始,I表示实体的中间内容,O表示非实体内容,具体的标注方法与语料中各类实体,见表1。

表1 实体标注标签
注:B-MED中的B代表药材实体的起始,MED代表药材实体,依此类推
实验使用精确率(Precision, P),召回率(Recall, R)以及F-Score(F)来评价算法性能。精确率P在本文表示预测为正的样本中有多少是真正的正样本,召回率R表示样本中的正例有多少被预测正确。F-Score是对精确率和召回率的调和均值,表示对精确率和召回率的综合考量。F-Score计算公式如下:
(5)
其中α用于度量精确率与召回率的权重,当α>1时,召回率对F值的影响更大,当α<1时精确率对F值得影响更大,当α=1时,此时的F值即为F1-Score:
(6)
4.3 基于BiLSTM-CRF的实体抽取算法实验
将LSTM的维度设定为embedding层输出维度的一半。为防止过拟合,在训练阶段模型中引入dropout正则化机制,将其置于BiLSTM层的输出端,设定dropout层概率为0.5。模型采用反向传播算法拟合训练数据,针对每个训练样例更新参数。具体采用Adam梯度下降算法,学习率为0.001,共训练50轮,batch_size为16。LSTM基本单元选用无窥视孔,遗忘门初始化偏置为1,独立的遗忘和输入门限。为验证模型的有效性选取CRF、HMM进行效果比较。实验结果,见表2。HMM模型在3种模型中效果最差,F1值仅有68.01。CRF模型采用窗口尺寸为3的上下文特征。相比于HMM模型,CRF在F1等比增长23.71。HMM仅利用上一个字的信息,信息搜集跨度较小,而CRF采用取[-3,+3]跨度的局部特征,可以更好地搜集上下文信息,对训练数据的拟合性更好。此外HMM还存在标注偏置问题,对特征的融合能力也较弱,而CRF模型能够解决标注偏置与特征融合问题。本文提出的BiLSTM-CRF模型在中医实体抽取上效果最好,F1值较CRF增长3.62。BiLSTM-CRF模型通过BiLSTM层获取字的上下文信息。相比于CRF手工定义的窗口尺寸的语义跨度,BiLTM覆盖整个目标语句,可以更完整地接收上下文特征。此外深度神经网络具有拟合非线性能力,单独CRF更趋向于对局部特征的线性加权拟合,而对训练数据的拟合能力,深度神经网络更优于CRF。
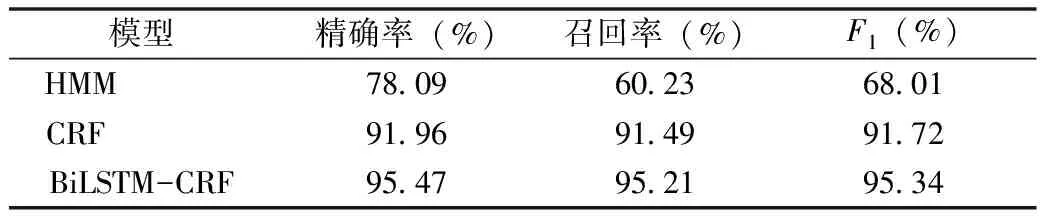
表2 不同模型实验结果
5 结语
互联网上存在大量非结构化的中医医疗知识,自动化构建中医医疗图谱方法尚不成熟,存在着需要大量中医领域专家参与、耗时耗力且难以形成规模等问题,本文针对知识图谱自动化构建中的实体抽取模块,采用深度学习方法,在以字为基本输入元素的基础上提出基于BiLSTM-CRF的序列标注模型,实验结果显示本文提出的算法具有高度准确性。该算法将抽取的目标实体限定为中药材、方剂和病症3类实体。但是在中医体系中实体种类并非如此简明,拓充中医实体的种类是下一步重点工作方向。
