基于混合神经网络的人脸表情识别研究
2019-03-22张少巍倪绍洲
张少巍,倪绍洲
(安徽文达信息工程学院 计算机工程学院,合肥 230032)
面部表情是表达内部情绪和意图的最重要的非言语方式。面部动作编码系统(Facial Action Coding System,FACS)是一种功能强大的系统,它通过使用行动单元(Action Units,AU)在面部出现时对人的面部动作进行分类。现在,对情绪识别(Emotion Recognition,ER)的研究已经引起越来越多的科研人员的关注,而它在人机交互领域仍然面临很多问题。最相关的研究是在人类和计算机之间建立可靠的对话和交流。面部表情识别在医疗保健、人机交互和游戏领域具有广泛的应用。面部表情识别的挑战性主要体现在两个方面:首先,没有大量、可用的训练图像数据库;其次,根据输入图像是静态还是渐进帧进入面部表情,不能简单地分类情感。Ekman等人将六种情绪:惊喜、恐惧、快乐、愤怒、厌恶和悲伤,作为人类常见的主要表达情绪[1]。大多情感类别之间的重叠使得分类非常困难,目前大多数研究和应用都采用手动设计[2]。由于数据集的数量和种类不同,深度学习成为所有计算机视觉任务中的主流技术。基于情感识别的深度学习的研究工作已经取得了不错的研究结果[3]。此外,传统的卷积神经系统有一个约束,即他们只是处理空间图像。为了从图像中分类情感标签,本文提出了一种嵌入卷积神经网络的递归神经网络的深度学习模型。
1 相关工作
最近,卷积神经网络已经成为深度学习技术中最主流的方法。RNN已经成功地处理了序列数据,将图像的部分扫描成特定方向的序列,改进后的RNN用来处理图像。由于能够重新收集过去输入的信息,RNN有能力学习与图像的相对依赖性,这是CNN无法比拟的,由于CNN卷积和合并图层有局部性而无法学习整体依赖性。因此,RNN通常与CNN结合,以便在图像处理任务方面取得更好的成果。
2 数据模型
对于CNN训练,使用了两个大型情绪数据集,基本表情主要分为:愤怒、伤心、惊喜、快乐、厌恶、恐惧和中立,共7种。
对于给定的数据集,进行了预处理,主要的步骤如下:
第一步,在JAFFE和MMI准备集中利用卷积神经系统过程策略对所有图片的5个面部关键焦点进行区分。
第二步,对于每个数据集,平均形状已经通过平均主焦点的方向进行了处理。
第三步,通过利用平均形状之间的接近度变化来映射数据集。
此外,使用标准偏差和平均图像对JAFFE和MMI数据集进行标准化合并。为了实施和评估所提出的模型的正确性,将每个数据集的70%用于训练,其余30%用于测试。
2.1 卷积神经网络
情感识别数据具有各种尺寸和分辨率,因此我们尝试提出可处理任何类型输入的模型。在我们的方法中,考虑了一类具有6个卷积层和2个完全连接层的网络,每个网络都具有ReLU(Rectified Linear Unit)激活函数,2个完全连接层都带有ReLU激活函数。此外,我们对每个权重矩阵W执行正则化来限制单个层的权重大小。
(1)
其中,x是网络中特定神经元的输出,p是丢弃的概率。
两种深度学习初始化算法的组合已被用于Momentum和Adam的损失函数的梯度来执行参数更新。方程式(2)描述了这个更新。
(2)
其中,xt是迭代t时的参数矩阵,vt是迭代t时的速度矢量,a是学习的速率。
方程式(3)说明了Momentum和Adam更新。
(3)
其中,β1,β2∈0,1,ε是超参数。mt是迭代t时的Momentum矢量,vt是迭代t时的速度矢量,a是学习的速率。由于梯度信息的使用,Adam是实际的更新算法。
CNN主要用于特征提取。RNN是一种将输入顺序转换为一系列输出的神经网络形式。在独立的时间步t,未知参数ht由下式得到:
ht=σ(winxt+wrecht-1)。
(4)
其中,win是输入矩阵的权重,wrec是递归矩阵,σ是隐层的激活函数,xt是t时刻的输入。借助方程式(5),分别按时间步长类似地计算输出。
yt=f(woutht)。
(5)
其中,wout是结果加权参数,f是输出的激活函数。
2.2 混合神经网络
首先,使用单个CNN模型来训练数据集。对于网络训练随机梯度下降,批量大小设置为32,权重衰减设置为1E-4。此外,开始时的学习率设定为5e-3,每20个周期减少0.01。对于给定的时间t,我们取 [t-p,t]时间段的p帧。然后将时间t-p到t的每个帧传递给CNN,为每个图像提取p个矢量,并将每个矢量传递给RNN模型的一个节点。最后,RNN的每个节点返回结果。混合的神经网络体系结构如图1所示。
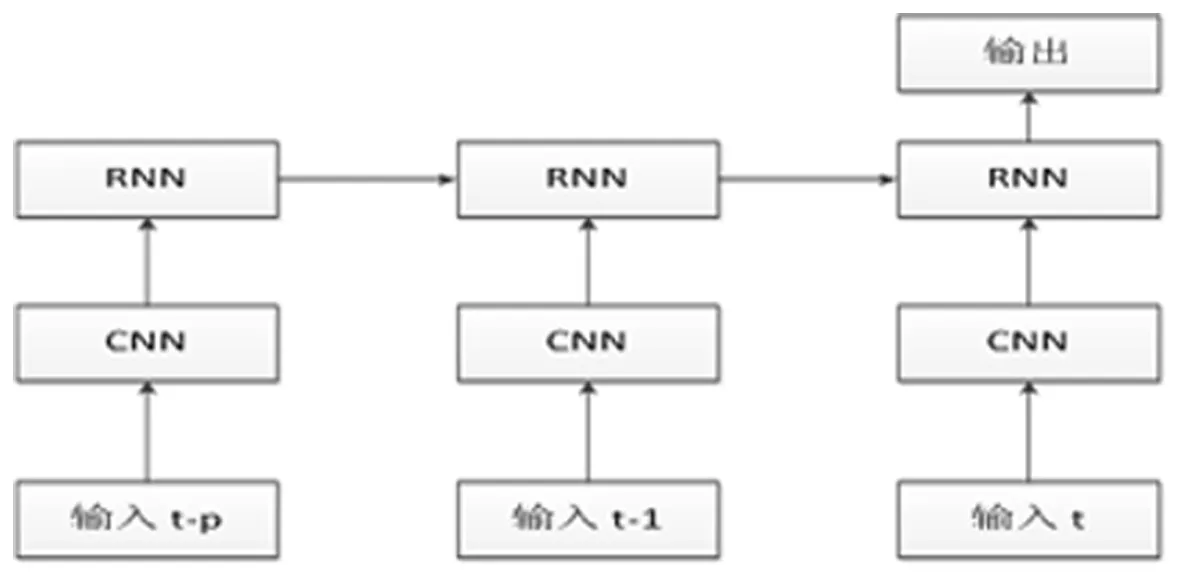
图1 混合CNN-RNN网络
3 实验分析
首先使用面部和兴趣点查找对面部表情进行识别,然后将显著的标志点映射到特征像素区域,以保证与轮廓相关的对应关系,同时通过CCN均值减法和对比归一化处理每个面部图像。
表1给出了单帧回归CNN和混合CNN-RNN技术的预测准确性。从中可以得出,使用混合CNN-RNN模型与ReLU激活函数可以显著提高性能。

表1 不同方法的准确率
我们分析了隐层单元的数量和隐层的数量两个超参数在混合模型中对预测结果的影响。得出的结论是,隐层单元数量是160时,预测精度最高,达到94.2%,见图2。从图3 可知,隐层数量的改变对所提出的模型的整体性能有影响,根据实验结果得出,6个隐层时效果最佳。
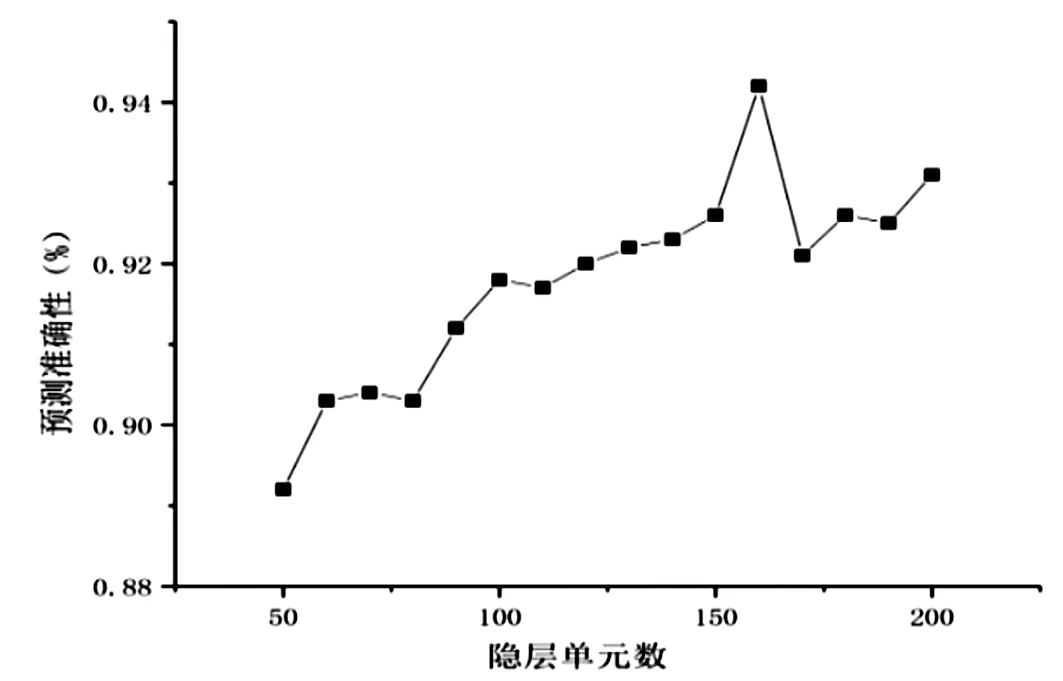
图2 不同隐层单元数对精度的影响
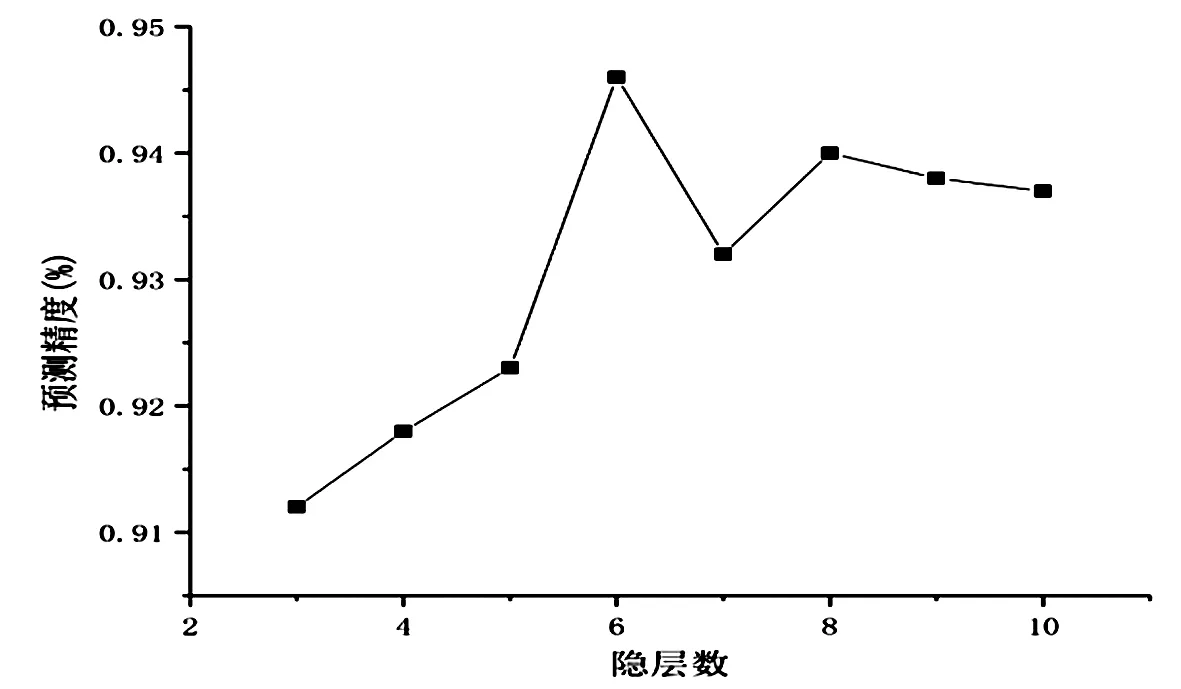
图3 不同隐层数对精度的影响
4 结论
本文提出了一种混合型深度CNN和RNN模型用于面部表情识别。另外,所提出的模型在不同情况下和超参数下进行预测以适当地调整所提出的模型。结果表明,CNN-RNN的混合模型显著提高了检测的总体性能,这验证了所提出的模型的效率。
