基于成功历史自适应的混合克隆选择算法
2019-03-22张伟伟张卫正孟颍辉张秋闻
张伟伟,高 奎,张卫正,孟颍辉,王 华,张秋闻
(郑州轻工业学院 计算机与通信工程学院,河南 郑州450002)
0 引言
最优化问题与人们的生产生活密切相关.一个最优化问题可以描述为:

其中,X=[x1,x2,…,xD]是可行域Ω中的D维决策变量;f(X)是目标函数.优化问题可以是最大化问题或是最小化问题.随着现实中最优化问题复杂度的增加,传统的借助微分学、变分法等数学工具进行逻辑推理分析获得解析解的方式不再适用,而自然启发式算法异军突起,逐渐成为求解最优化问题的核心力量[1-2].其中,人工免疫算法受生物免疫系统免疫机制启发,在学术界和工业界受到关注并得到广泛应用[3].
克隆选择算法是人工免疫算法在最优化领域应用最为广泛的代表性算法之一.它来源于对B细胞自适应免疫反应的原理抽象,主要包括克隆、超变异和选择3个算子.
虽然克隆选择算法被广泛应用到实践中,但随着优化问题复杂度的增加,比如多峰、旋转、复合以及高维等,克隆选择算法往往会遭遇早熟收敛和易陷入局部最优的缺点.针对这些缺点,国内外学者对克隆选择算法做出了各种改进,并在各自领域取得了很好的应用成果.高斯和柯西变异策略被引入到克隆选择算法中构造了一个快速克隆算法[4].焦李成等[5]把量子学的思想与免疫机制相结合,提出了量子启发式重组算子和量子变异算子,并提出了受量子启发的免疫克隆算法,应用在最优化问题上.公茂果等[6]把拉马克学说应用在克隆选择算法上构造了相应的基因重组和变异算子,并提出了拉马克克隆选择算法.文献[7]提出了适应性Lévy变异算子,并通过实验证明了该变异算子在解决多峰函数时比高斯和柯西变异效果好.文献[8]将免疫克隆算法和粒子群算法结合以加强算法的性能,正交实验被引入到克隆选择中解决函数优化问题[9],实验证明该算法能够有效保持种群多样性,避免算法不成熟收敛.针对传统算法全局搜索效率降低的问题,文献[10]提出了模糊非基因信息记忆的双克隆选择算法提高全局搜索速度和精度.文献[11]引入了粗糙集中的核值概念,提出了一种基于粗糙集核值的克隆选择算法以提升算法的收敛速度、抗体多样性和避免早熟.通过文献检索发现,混合免疫克隆选择算法通过引入新的策略和克隆选择算法改进自身算子成为现阶段研究和应用的重要方向.
笔者提出了一种混合的免疫克隆选择算法,该算法通过引入免疫重组算子来提升种群的多样性,并提出了成功历史自适应免疫超变异算子来促进算法收敛能力.通过全局搜索与局部搜索的平衡,达到寻求全局最优的目的.
1 克隆选择算法
根据克隆选择学说[12],文献[13]最早提出了克隆选择算法CLONALG,并应用到字母识别、多模函数优化、组合优化等问题上,奠定了免疫克隆选择算法的基础.基本的克隆选择算法主要包含3个算子,分别是克隆、超变异和选择.根据克隆选择学说,其克隆产生的子代的数量与父代的适应度值成正比,而变异率与父代的适应度值成反比.在克隆选择算法的具体实施过程中,高斯变异是最常用的变异方法,但是研究表明,其搜索过程具有一定的盲目性,且收敛精度不高.另外,克隆选择算法依靠克隆大量的子代提供候选解,往往需要消耗很多的计算资源,限制了实际应用.
2 笔者提出的算法
2.1 基因重组策略
除克隆选择以外,基因重组在B细胞的免疫反应中也充当了重要的角色.免疫B细胞分化过程中,通过基因库中基因片段在DNA级别上组合生成不同的B细胞实现了抗体基因的多样化.文献[14]研究了B细胞的Y型抗体结构,提出了基因重组策略,其子代产生的方式为:
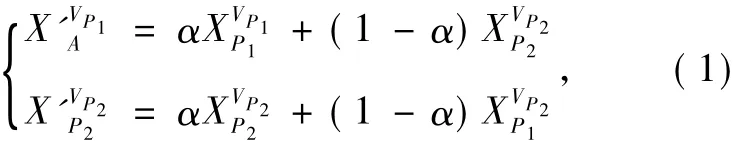
式中:XP1和XP2是随机选择的父代;VP1和VP2是随机选择的m维,m∈[1,D];α∈ (0,1)是服从均匀分布的随机数.在实施过程中,考虑到随着种群的收敛,种群中个体的相似度越来越高,这时种群内部的信息融合已不能满足多样性的需求,所以笔者将生成的子代中表现不好的个体存储在集合Archive中,在实施基因重组时,XP1取自当前种群,而XP2则从当前种群和集合 Archive的并集中随机选取.通过这种改进,可以缓解种群收敛对多样性缺失造成的影响,提高算法的寻优能力.
2.2 成功历史自适应克隆选择
文献[15]提出了基于成功历史的自适应差分进化算法解决全局优化问题.笔者将成功历史自适应策略与克隆选择算法相结合,提出了成功历史自适应克隆选择算法.
(1)克隆:每个父代个体Xi产生Nc个子代
(2)成功历史自适应超变异:每个克隆个体有M维发生变异[16]:
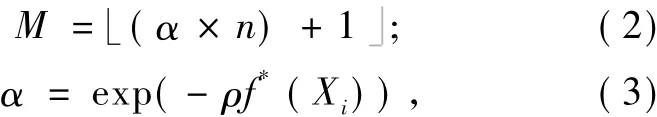
其中,f*(Xi)∈[0,1]是归一化的适应度值;ρ是衰变常数,这里采用的变异策略隐式服从克隆变异的变异率与适应度成反比的规则.每个个体经历如下的变异操作

式中:是第i个个体的第j维是从种群的最优100p%,p∈(0,1]的个体中随机选择的个体;randM(n)∈{1,2,…,n}是无重复随机选择的M维索引向量;r1和r2是[1,Np]中的随机数,且r1≠r2≠i;Fi是控制变异幅度的参数,服从历史最优自适应更新策略[15]:设定一个大小为H的集合MF来存储Fi的值,其初始值被设定为0.5.在每一次迭代中

其中,是随机从MF中选取的ri∈[1,H];randc(μ,σ2)是服从均值为 μ,方差为 σ2的柯西分布的随机数.在每一代,如果采用当前的Fi生成的子代个体的适应度值优于父代,则该Fi被存储在集合SF中,在每一次迭代结束,即所有个体更新完成后,按式 (6)逐次循环更新MF中的值

其中,k∈[1,H]初始值为1,然后递增并循环在[1,H]中取值.如果在本代中没有产生更优的子代,即SF=φ,则不更新.
(3)选择:选择子代中最优的个体取代父代个体.
2.3 算法流程
综合以上基因重组策略和成功历史自适应克隆选择算法,笔者提出了新的克隆选择优化算法,该算法的步骤描述如下.
Step 1初始化:随机产生规模为Np的抗体种群{X1,X2,…,XNp}.
Step 2评价每一个个体的适应度值.
Step 3基因重组:对每一个抗体Xi,实施基因重组,若产生的子代个体比当前抗体优,则取代当前抗体Xi,否则不更新Xi,较差子代存入集合Archive.
Step 4成功历史自适应克隆选择:对每一个抗体Xi进行克隆,成功历史自适应超变异和选择操作进行更新.
Step 5判断是否满足终止条件,若满足,则输出最优值并结束,否则退回Step 3.
3 算法仿真分析
采用25个测试函数[16]进行试验仿真,对所提算法进行分析比较.这些测试函数涵盖了5个单峰和20个多峰函数,并进行了旋转、平移和复合等操作,决策变量维数从10维到50维,为问题的求解提出了很大的挑战.
3.1 参数设定
算法中所涉及的参数设定如下:种群个体数Np为10×D,其中D是问题的维度,基因重组率为0.7,克隆个体数Nc为1,变异中的衰变常数ρ设置为5,优秀个体的百分比p为0.2.
测试函数的最大评估次数mFES设置为10 000×D.为了确保对比公平,文中涉及的试验除特别说明外,选取的参数都是相同的,结果引用自算法提出的原文献.
3.2 基因重组和变异的策略对比分析
算法一共引入了两种策略,分别是基因重组和成功历史自适应克隆选择,为了验证这两种策略的有效性,下面在10维的测试函数上进行了仿真试验,并对其结果进行了对比.首先为了避免其它操作对算法的影响,选择只有克隆、超变异和选择3种基本操作的克隆选择算法(记为CSA),在CSA上分别添加基因重组策略(记为RCSA)和成功历史自适应克隆选择策略(记为HCSA),最后合并基因重组策略和成功历史自适应克隆选择策略(记为RHCSA).在CSA和RCSA中采用的是高斯变异的随机数进行超变异,其余的参数保持一致.实验结果如表1所示,受篇幅限制,截取了前10个函数的误差(均值±方差)的对比结果.从表1中可以看出基本的克隆、超变异和选择的操作在函数求解时表现较差,通过加入基因重组,一定程度上提升了算法的搜索能力,在除f5和f8以外的函数上都使误差减少了一个数量级.基因重组主要的功能是提高种群的多样性,避免陷入局部最优,但仅依靠基因重组策略算法的局部搜索能力还差强人意.成功历史自适应克隆选择策略可以大大提升算法的搜索能力,其搜索结果在f1~f6上都找到了最优值,除f7和 f8外都达到了很好的效果,甚至比两种策略相结合的效果还要好,但是在f7陷入了局部最优值,搜索结果比较差.两种策略相结合后的RHCSA在函数f1~f6上都定位到了全局最优值;虽然在函数 f9~f10上稍差,但基本可以接受;而在f7上的结果也比较让人满意.经过对比分析可以看出,基因重组策略和成功历史自适应克隆选择策略的引入能够有效提升算法的寻优能力和提升算法的稳定性.
3.3 与其他先进算法的对比分析
为了进一步测试所提算法的性能,将算法应用在25个测试函数在50维时进行仿真试验,并与 其 他 先 进 的 算 法 (CoDE[17]、EPSDE[18]、SaDE[19]、jDE[20]、JADE[21]) 进行对比分析,其误差结果(均值±方差)如表2所示.25个测试函数中前5个是单峰函数,笔者提出的算法在函数f1、f2、f4上均找到了全局最优值,在 f3和 f5上未能成功寻找到全局最优值,但比其他5个算法的效果好.可见所提算法RHCSA在单峰函数的寻优效果是值得肯定的.
f6~f12是基本多峰函数,主要考察算法在面对多峰函数时跳出局部最优的能力.RHCSA在f7找到了全局最优值.在 f6、f9和 f10上表现不够让人满意,在其余的函数上表现与其他算法相当.可以看出,在问题维度较高且存在多个局部最优的情况下,对算法提出的挑战更大,算法在求解时极易陷入局部最优值,从而影响最后的寻优效果.总体来看,RHCSA在求解基本多峰函数时表现尚可.
f13和f14是扩展的多峰函数,RHCSA未能成功寻找到全局最优值,但对比其他算法,表现尚可.f15~f25是混合复合函数,将基础的单峰
和多峰函数经过各种变换复合构造而成,这些函数大多拥有大量的局部最优值,且各种特性不可分割,部分函数还引入了旋转、噪声等,并人工设置了一些极易陷入的局部最优,为算法的求解提出了极大的挑战.
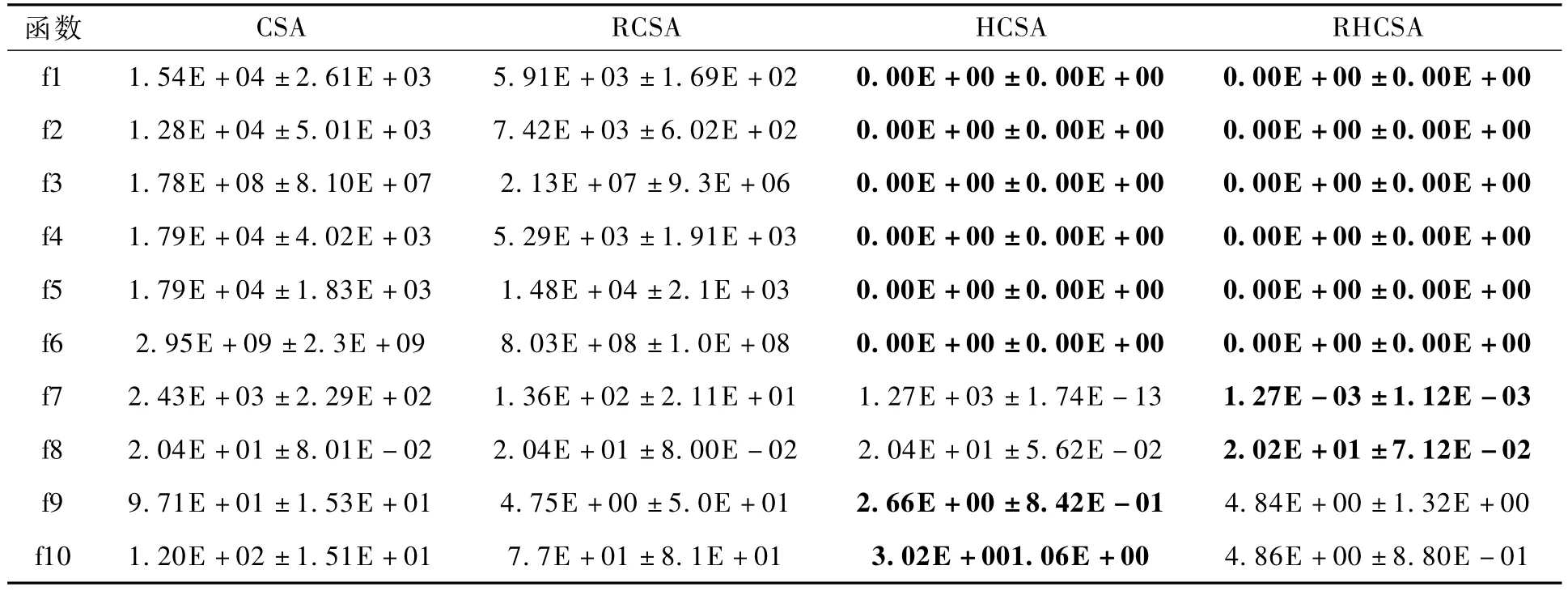
表1 10维测试函数上基本CSA和添加了基因重组和变异的策略对比Tab.1 Comparison of Basic CSA,CSA with recombination and RHCSA on 10D benchmark functions

表2 笔者所提算法与先进算法在求解25个测试函数在50维时的结果对比Tab.2 Comparison of RHCSA with other algorithms on 25 benchmark functions with 50D
RHCSA在混合复合函数上均未能找到全局最优值,但是其在 f18~f20、f22和 f25上的表现是算法中最好的,在 f15、f16和 f17上表现稍差,其余函数上的表现与其他算法不相上下.总体看来,新提出的 RHCSA在混合复合函数上的表现还是比较突出的.
从25个测试函数的整体比较来看,RHCSA在单峰函数上的处理效果较好,多峰函数上的求解能力一般,对于更复杂的混合复合函数的表现较突出,所以笔者提出的 RHCSA是非常有竞争力的.
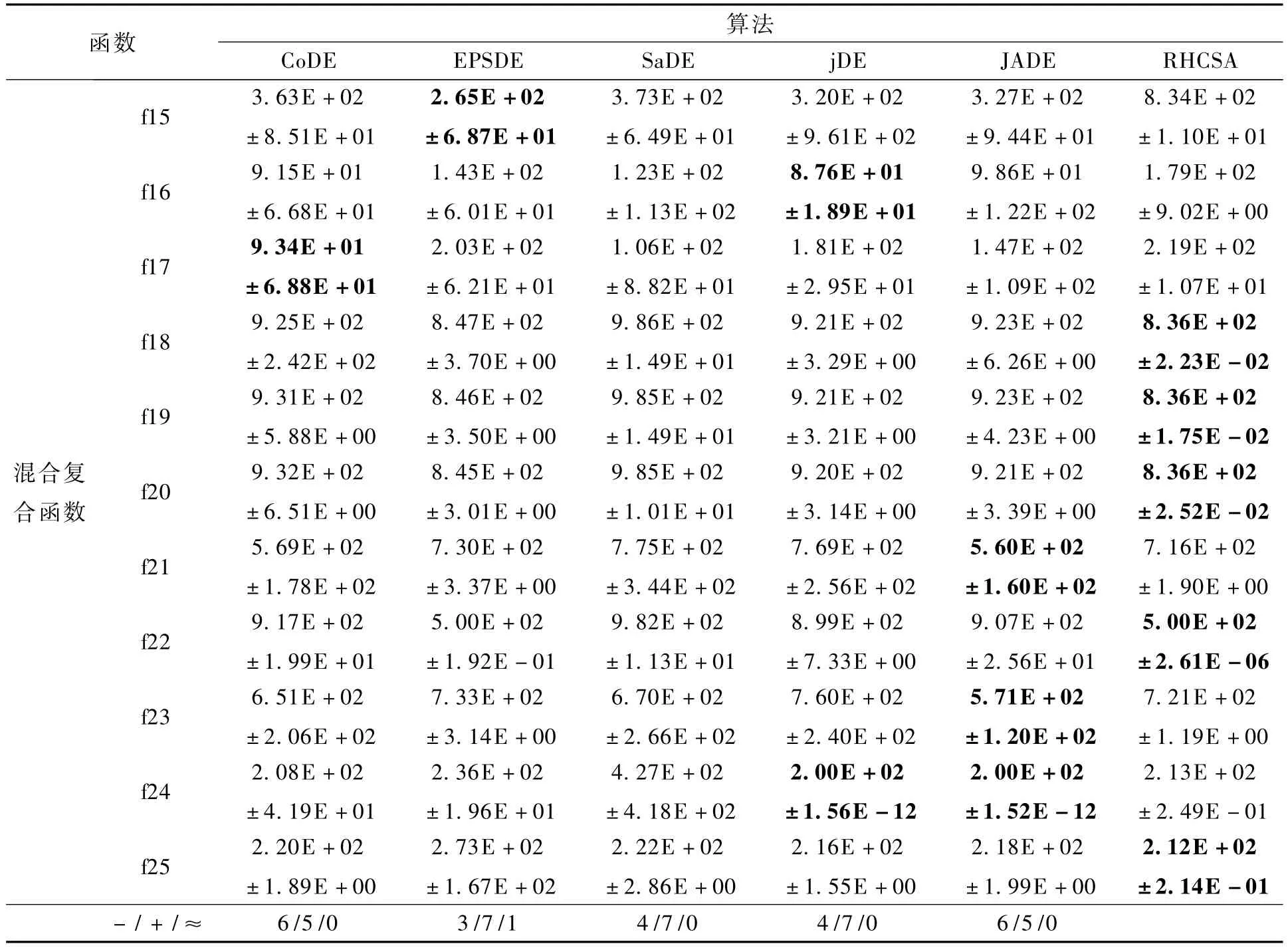
续表2
4 结论
针对传统克隆选择算法易早熟收敛和陷入局部最优的缺点,提出了基于成功历史自适应的混合克隆选择算法.该算法引入改进的基因重组策略来加强算法的全局搜索能力,并将成功历史自适应变异算子与超变异算子相结合提出了成功历史自适应超变异算子来提升算法的性能.仿真试验选取了25个包含单峰、多峰、混合复合的函数测试算法的性能,通过仿真结果可以看到,所提算法比传统的克隆选择算法具有更好的全局寻优和局部定位能力,与其他算法比较也显示了其竞争力.算法相关代码将整理发布在 https:∥github.com/haoyouqiezi/HCSA上.后续将继续深入研究免疫系统的原理和功能,提取和改进免疫算子,提高算法在处理优化问题上的性能.
