可拓逻辑和可拓思维对决策树算法的分析与优化
2019-03-21朱弘扬柴华金
朱弘扬,丁 怡,柴华金,李 升
(1. 广东海洋大学 数学与计算机学院;2. 广东海洋大学 机械与动力工程学院,广东 湛江 524088)
伴随着人工智能技术的飞速发展和广泛应用,模式识别和机器学习等基于数据处理的研究领域变得比以往任何时期都更具有重要意义,而分类是处理数据挖掘问题无法避免的基础操作[1]. 决策树是解决分类问题的一种经典算法,相比于神经网络、支持向量机和逻辑回归算法,决策树算法更容易理解和操作,尤其是在处理多分类问题和离散型数值分类问题中具有较高的自主学习能力和较低的先验知识要求,因而在很多领域都有着广泛的应用. 决策树算法是一种逼近离散值目标函数的方法,这种方法通过对训练集的学习,找到特定样本环境下样本类别属性和单个特征属性的集合关系,并提取出该特定环境和集合关系作为分类规则,把所有的分类规则构建为一棵决策树,从而达到预测模型的目的. 决策树方法以其速度快、精度高、生成的模式简单等优点,在数据挖掘中受到许多研究者和软件公司的关注[2].
单标签分类问题是一类典型的矛盾问题,因为样本不可能同时属于两种类别,因而造成了分类结果“是”与“不是”的单一描述,和“对”或“不对”的评价标准[3]. 可拓学是以矛盾问题为研究对象、以矛盾问题的智能化处理为主要内容、以可拓方法论为主要研究方法的一门学科,对矛盾问题的解决有着横跨哲学、数学和工程学领域的逻辑思维模式. 所以不同于其他学者从正确率、泛化能力和分类效率等方面对决策树进行分析和改进,从数学推导和计算的方式来评价该算法,文章尝试从可拓逻辑和可拓思维模式的角度对决策树分类算法的各个步骤进行逻辑和理论分析,从全新视角下验证决策树算法的可行性和优劣性,并根据可拓集理论以关联函数为参考,建立一套关于决策树分类结果的评价体系.
1 决策树算法简介
决策树学习算法是一种归纳算法,它采用自上而下、阈值区分的方法将样本集划分为若干个互不相交的子集,并将每个子集按层层递进的规则提取出来作为一个分枝,并建立决策树,用来形成分类器和预测模型,可以对未知数据进行分类、预测和数据预处理等. 每一层选择哪个属性作为子节点,以及怎样对子节点进行分枝将决定决策树的规模和分类精度[2]. 设训练集为S,其类别集包含 k个类别值{c1,c2,···,ck},每个样本有个属性 (A1,A2,···,AM).构建决策树的一般流程如下[4-6].
Step1 把全体样本集作为根节点,计算所有属性的信息增益值,并找到信息增益值最大的属性作为分枝的子节点.
(1) 根据类别集划分样本集S所得信息熵为
其中,Pi(i=1,2,···.k)为样本属于类别ci的概率,Pi=|ci|/|S|,|ci|为样本集S中属于第i个类别ci的样本个数,|S|是样本集S所含样本的个数.
(2) 假{设所有样本}的第 m个 属性 Am共有 q 个不同的取值,a1,a2,···,aq,把取值为aj的样{本划分到同}一个子集Sj,则样本可以划分为q 个 子集S1,S2,···,Sq,根据属性 Am划分样本集S的信息熵为
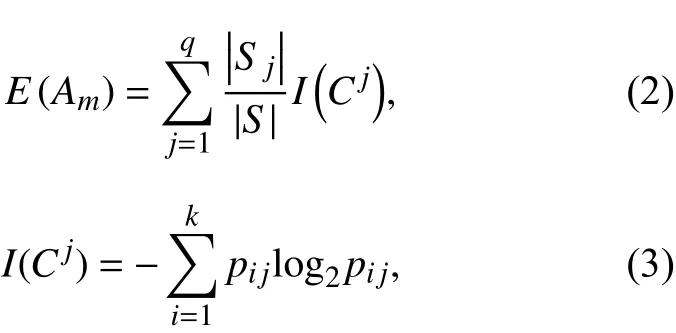

(3) 属性 Am的信息熵为

根据式(4)~(5)可得信息增益率

Step2 选择信息增益率最大的属性作为子节点对根节点进行分类,把样本集分为若干子集,然后采用与step1相同的方法递归地对子集进行分类,建立树的分枝,一直循环到所有分枝节点中的样本都属于同一类别,则该子节点就成为叶子节点,该分枝停止生长.
Step3 对构建好的决策树进行剪枝,消除噪声和孤立点等随机因素的影响,以得到简化的决策树,其中剪枝方法可分为预剪枝和后剪枝两种类型.
Step4 根据修剪好的决策树,提取分类规则,对新的样本进行逐层分类,一直到叶子结点,从而预测样本的类别.
2 可拓学视角下的决策树算法分析
可拓学理论认为解决矛盾问题的工具是变换和推理,若不考虑事物的内涵和外延,就不能表达物、事、关系和特征变换以及变换所引起的其他物、事、关系和特征变换的传导变换. 所以可拓学处理矛盾问题的过程就是把物、事、关系看成是可以拓展的,并根据物、事、关系的可拓性,变换问题的目标或条件,使得目标得以实现[7].
决策树算法是解决分类问题这一典型矛盾问题的有效方法,其解决问题的过程符合可拓学处理矛盾问题的理论,样本的属性和类别就是事物的内涵,样本的属性和类别之间的关系就是事物的外延,而样本某一或某些属性值的变化导致类别发生变化,就是事物的传导变换. 文章从可拓思维模式中的菱形思维模式的角度分析决策树算法每个节点的选择,以可拓逻辑中基元变换理论来评价决策树算法的规则提取,以可拓逻辑中的基元发散规则来解释决策树算法的预测步骤,验证了决策树算法和可拓学理论的契合程度.
2.1 菱形思维模式
菱形思维模式是一种先发散后收敛的思维方式,它包括了发散思维和收敛思维两个阶段. 利用菱形思维模式解决问题,首先对问题进行拓展分析,提出解决问题的尽可能多的信息和丰富资料,这个过程就是发散;然后从可行性、优劣性、相容性等角度
出发对信息进行整合,向最佳的解决方案聚焦,这个过程就是收敛[8-10]. 在构建决策树的过程中,找到每个节点,即每个子集的最优的分类属性,我们要拓展出所有会影响分类效果的信息,不仅要考虑每个属性分类的精度和分类的集中度,为了构建更简单有效的决策树,还要考虑子集的类别复杂度和属性复杂度;在找到所有影响因素之后,还需要对这些因素进行综合考虑,使得决策树在精度和复杂度两个方面达到平衡. 利用可拓思维模式中的菱形思维模式来解决这一问题的模型如图1所示[11-12].

图1 决策树的菱形思维模式Fig.1 The rhombus thought model of Decision Tree
在图1子集 T(Am,C,v)中,T , Am表示当前考虑的属性,表示子集 T 的类别集,而v 表示对分类效果有影响的因素. 根据属性 Am对子集T 分类的菱形思维模式过程如下:
(1) 在菱形思维模式的第一阶段进行发散思维,发现对分类效果有影响的因素有:根据类别集C 划分样本集 T 所得信息熵 T(Am,C,I(C)),根据属性 Am对子集 T 分类的所得信息熵T (Am,C,E(Am)),和属性 Am的信息熵T (Am,C,Split(Am));
(2) 在菱形思维模式的第二阶段进行收敛思维,根据式(4)把 T(Am,C,I(C))和 T(Am,C,E(Am))综合考虑为一个新的因素T (Am,C,Gain(Am));
(3) 在菱形思维模式的第三阶段继续对第二阶段的两个因素进行收敛思维,根据式(6)把T(Am,C,Gain(Am))和T(Am,C,Split(Am))组合为一个新的因素 T(Am,C,Gain_Ratio(Am)),就得到可以同时考虑到 I(C),E (Am)和 Split(Am)3个因素的选择节点的评价指标.
2.2 基元变换
可拓逻辑不同于经典数理逻辑和模糊逻辑,是通过变换和推理将矛盾问题转换为不矛盾问题的逻辑思维方法. 在数理逻辑和模糊逻辑中,事物是否属于某种类别,命题为“真”或“假”是对立的,但在可拓逻辑中,由于引入了变换,事物属于某类别的程度或者说命题的“真假”程度是会随着事物某些属性的改变而改变的,比如性别“男”和“女”是对立的,但在生活中我们经常会有“很男人”或者某人比另外一人“更男人”的说法. 所以,数理逻辑是从静态的角度研究事物的特征和命题的真假,而可拓逻辑从变换的角度研究事物的动态和变化的特征[13].
决策树分类规则的提取是基于属性的分类方法,在每一个节点都根据该节点的属性,把具有相同属性值的样本分到同一个子集,然后在对所有子集使用同样的方法递归处理,直到子集里的样本全都属于同一类,则该分枝就是一个分类规则. 把样本看作基元,样本的属性和类别就是基元的要素,样本某一属性的取值不同可能会使得样本的类别不同,就相当于基元内部的某一属性要素的变化导致了类别要素的传导变换.
图2为一棵简单的决策树,首先根据属性 A1的3个取值 a11,a12,a13把样本集分为3个子集,其中第二个子集中的样本都属于同一类别 c1,因此成为叶子结点,然后再对另外两个子集根据不同的属性继续划分为不同的子集,直到子集中的样本都属于同一类别为止.
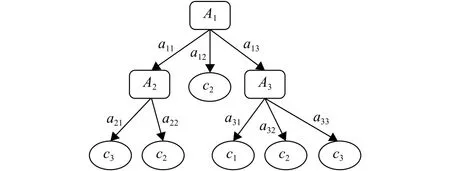
图2 简单决策树Fig.2 A simple decision tree
根据可拓学基元变换的理论,图2决策树的分类规则可以理解为对于具有多个属性的基元,即使仅仅改变其中一个重要属性,也有可能会对基元的性质产生影响,而相反的,改变多个无关属性,也有可能对基元的性质没有影响. 文本将可拓化的样本记作基元O,传导规则T决定了基元O的所属类别C,比如 A1→c1该分枝决策规则的基元变换的传导规则为

即若基元O的A1特征取值为a12,那么该基元属于c1类. 样本属于类别c3的A1→A2→c3决策规则的基元变换的传导规则为
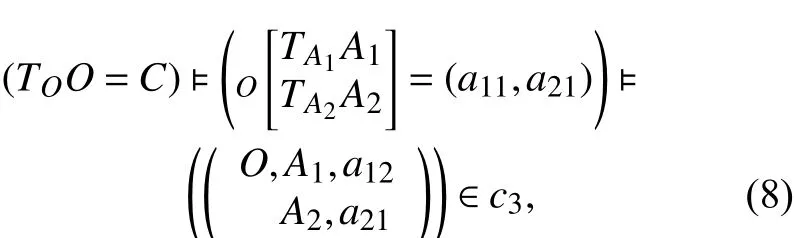
即若基元O的A1特征取值为a12,A2特征取值为a21,那么该基元属于c3类.
A1→A3→c2决策规则的基元变换的传导规则为

对基元O 做变换TOO ,改变其关键特征 A1、A2、A3的量值就会改变基元的类别性质C ,而其他的变换没有影响.
2.3 预测中的基元发散规则
决策树构建完成以后,就可以用来预测新样本的类别. 根据样本在决策树中根节点属性的取值,把样本划分到不同的子集,然后再根据子节点的属性取值继续划分,直到把样本划分到叶子结点,就得到样本类别的预测结果. 这种预测方法和可拓学中基元的发散过程推理是一致的. 基元发散是基元拓展推理中的一种,可以利用基元的发散推理,结合决策树的分类规则,对已知类别的样本进行发散,把某些属性和该已知样本的取值相同的未知样本分类到该类别中[14-15]. 如图2所示的决策树,根据训练得到的A1→c1规则为 A1属性取值为 a12的样本为c1类,那么对未知样本进行预测时,如果某样本 S1的 A1属性取值为 a12,那么无论其他属性的取值怎样都可以根据发散规则预测该样本为 c1类. 同理,根据A1→A3→c1规则,若某样本S2的 A1属性取值为 a13,并且 A3属性取值为 a31,无论其他属性怎样,该样本都可以预测为c1类,其基元发散推理过程为
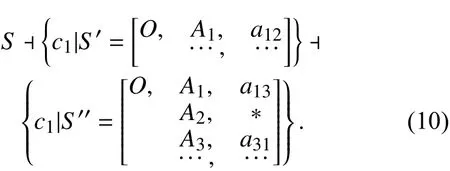
根据 A1→A2→c2规则和 A1→A3→c2规则,可以得到c2类样本的基元发散推理过程为

3 可拓评价体系
在构建决策树的过程中,不同的分类规则也有可能得到同样的分类结果,如图2所示的决策树中,A1→c1和A1→A3→c1都可以得到结果为c1的分类结果. 对于传统的决策树预测,不同规则预测得到的相同结果,并没有进行更具体的区分. 但很明显,在日常生活的很多分类问题中,不同事物属于同一类别的程度是不一样的. 比如,香蕉和苹果都属于水果,而且没有隶属程度的区别,但是换一个问题,身高178 cm和身高185 cm的人都可能被分类为“高个”,但很明显后者隶属于这一类别的程度要更多一些.为了评价决策树预测结果的程度多少,笔者参考可拓学中关联函数的内容,建立以可拓距反映隶属程度的评价体系[16].
当样本根据决策树的某一分枝的预测规则被预测为某一类别时,找到训练集中所有符合该规则的样本,求得其每个属性的平均取值,最大取值和最小取值,把每个属性都取平均值的样本视为该分枝的标准枝,把每个属性的最大值的和最小值的作为样本取值区间的上下限. 然后计算预测样本与标准枝的可拓距,以此来反映样本属于该类别的程度.
假设数据集中样本共有5个属性,其决策树规则如图2所示,某样本S=(a11,a22,a3,a4,a5)在分枝A1→A2→c2规则下,被分为c2类. 因为样本属于同一分枝,若节点属性是离散的,那么节点属性的取值是一样的,只需要统计该分枝非节点属性的最大值和最小值,计算平均值. 训练集中属于该分枝下的样本 A1属性和 A2属性的取值都应该为a11,a22,若训练样本中 A3、A4和 A5属性的平均取值为(∂¯,β¯,λ¯),最大取值为(∂1,β1(,λ1),最小取值)为( ∂2,β2,λ2),那么该分枝的标准枝为 a11,a22该样本在 A3属性上与c2类的可拓距为
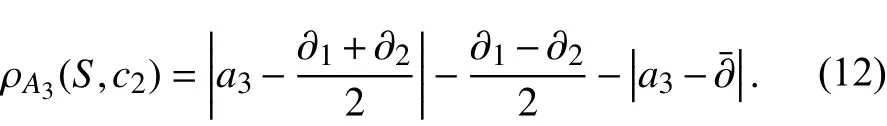
同理,该样本在属性 A4和 A5上与c2类的可拓距为
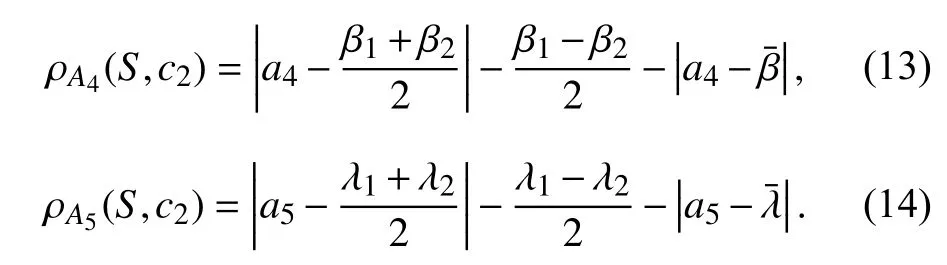
根据式(12-14),把样本S与该分枝的标准枝的可拓距定义为

可拓距越小,则表示该样本属于 c2类的程度或者可能性越大.
若样本的特征量化值是连续的,需要对某分枝上所有样本找到每个属性的最大值和最小值,并求得平均值,作为该分枝的标准枝. 以fisher iris数据为例,我们建立一套基于可拓距的决策树分类评价体系,因为该数据的特征量化值是连续的,因此得到如图3所示的二叉树.

图3 fisher iris的决策树Fig.3 Tree of fisher iris

4 结论
可拓学以形式化的模型,探讨事物拓展的可能性以及开拓创新的规律与方法,并用于解决矛盾问题,其理论价值或应用价值在各个领域都能得到体现. 本文以可拓学的视角去解析决策树分类算法的逻辑推理过程,不仅证明了决策树算法和可拓学理论的契合性,还对决策树算法的预测结果建立基于可拓距的评价标准.
