视频监控系统异常目标检测与定位综述
2019-03-21胡正平李淑芳孙德纲
胡正平,张 乐,李淑芳,孙德纲
(1. 燕山大学 信息科学与工程学院,河北 秦皇岛 066004;2. 燕山大学 河北省信息传输与信号处理重点实验室,河北 秦皇岛 066004;3. 山东华宇工学院 电子信息工程学院,山东 德州 253000)
0 引言
随着室内外监控摄像机数量的增加,在采用传统人为视频监督方法进行异常检测时,常因为人们的疏忽和疲劳以及信息本身的复杂性,造成监视任务的低效和繁琐。因此,采用智能视频监控系统自动检测异常行为对于确保公共安全和社会秩序管理具有至关重要的作用,同时视频异常行为检测作为人类行为识别的一个特殊问题引起国内外学者广泛关注。
基于对智能监控系统的需求,2005年Valera和Velastin 归纳了基于自动异常检测的监控系统的基本组成框架[1]。1997年美国国防高级研究项目署设立以卡内基梅隆大学为首麻省理工学院等高校参与的视觉监控重大项目VSAM(Visual Surveillance And Monitoring)用于战场及普通民用场景监控的运动物体的检测、定位和分类[2]。此外,欧盟也大力资助基于系统结构的公共交通行人监控项目来提高视频监控异常检测的效率,如CROMATICA (Crowd Management with Telematics Imaging and Communication Assistance)[3]和 PRISMATICA (Proactive Integrated Systems for security Management by Technological Institutional and Communication Assistance)[4]。在国内中科院自动化所学者发起的实时智能视频监控预警系统已成功应用于北京地铁13号线,大大提高效率的同时使场所犯罪率降低至新的标准[5]。
视频异常检测首先需要确定异常的含义,一般来说在不同的视频中对于“异常”的定义各不相同,即异常的定义取决于视频本身的内容,通常情况下将视频场景中小概率事件视为异常行为。异常可以分为全局异常和局部异常,全局异常指整个场景的群体行为是异常的,这类异常是从视频序列的某一帧开始就整个帧场景而言出现的异常,如UMN数据集中的人群恐慌四处逃散场景和Hockey Fight中的暴力行为场景[6]。而局部异常是指视频中只有某一区域中的个体行为异于邻近人群或整个场景中的绝大部分行为,如UCSD数据集中步行街中骑自行车的行为等。
视频异常检测就是从大量视频中高效地检测出异常事件,进而保障公共安全防止危险的情况发生。一般来说实现这一目标需要三个步骤,首先对视频序列进行前景分割和提取,检测出运动目标,然后进行特征的提取和筛选来表示基本事件,最后实现异常事件的识别和定位。智能视频异常检测系统流程如图1所示,本文也将按照该流程分别进行阐述。

图1 智能视频异常检测系统
Fig.1 Intelligent video anomaly detection system
1 前景提取与运动目标检测
通常情况下监控视频中的异常情况常为运动的物体或目标,然而视频中大面积的背景或是静止的物体使得异常检测运算过程变得庞大复杂,同时大量的噪声及冗余信息使得特征提取、行为表示变得困难,从而大大降低了异常检测的效率和质量。因此,运动目标检测是智能异常检测系统中不可或缺的步骤。传统运动目标检测方法有帧间差分法(帧差法)、背景减除法和光流法。帧差法是通过相邻帧之间的差分判定对应像素的灰度值的变化从而检测出运动目标。背景减除法需要先对背景进行建模得到背景模型,再将每帧图像和背景模型图像进行对比。光流法是运动目标检测中最常用的一种方法,在视频分析中通常定义为一个视频帧序列中的图像亮度模式的表观运动,即空间物体表面上的点的运动速度在视觉传感器的成像平面上的表达,常用的光流方法有HS算法和金字塔HK算法。监控视频异常检测领域常用的前景提取与运动目标检测方法框图如图2所示。在进行视频异常检测时常使用光流法配合元胞分割方法剔除背景信息并得到含有运动目标的二维图像或三维时空兴趣块,例如Roberto Leyva等人通过对视频帧进行运动目标检测,得到含有运动目标的二维图像,然后对这些二维图像进行特征提取和行为表示[7]。Zhou Shifu等人采用光流法提取到含有运动信息的时空兴趣块,作为三维卷积网络的输入,该方法有效地减弱了背景信息的影响,提高了异常检测速度和准确率[8]。
图2 前景提取与运动目标检测方法框图
Fig.2 Block diagram of foreground extraction and moving object detection method
2 特征提取和行为表示
在视频异常检测的研究中,合适特征的高效提取对正常及异常行为的快速准确鉴别具有重要的作用,为此研究学者也提出各种方法进行特征提取和行为表示。特征提取从思路上可以分为两大类:一类是采用手动设计方式提取人工设计特征,一类是直接对原始视频帧进行学习得到深度特征,两种特征提取方式都是基于生物神经理论实现的,不同之处在于手动设计方式提取的特征是模仿人类视觉框架得到的,而深度学习的特征提取方法重点在于对数据本身的分布规律进行学习。异常检测中常用的特征提取方法如图3所示。
图3 异常检测特征提取方法框图
Fig.3 Block diagram of feature extraction method for anomaly detection
2.1 人工设计特征行为表示
人工设计特征是根据人类视觉对特征的敏感度从图像中提取有区分能力的特征,因此提取出来的特征具有明确的物理含义。目前,常用于视频异常检测的人工设计特征有纹理特征、颜色、MoSIFT(Motion Scale Invariant Feature Transform)、光流特征、轨迹特征等。例如Li Weixin等人使用动态纹理混合(Mixtures of Dynamic Textures,MDT)对正常人群的行为建模,利用显著性区分判别空间中的异常与正常事件将模型中的异常值视为异常事件[9-10]。在二维纹理的基础上,Wang J基于时空视频概念,提出具有丰富的人群模式特征的时空纹理模型,将提取到的监视记录的人群纹理在基于冗余小波变换的特征空间进行行为模板匹配实现异常的检测[11]。Aravinda S.Rao等人从统计的角度通过灰度共生矩阵(Gray Level Co-occurrence Matrix,GLCM)对异常事件或物体的对比度、相关性、均匀性等空间特征进行描述构建异常框架,并采用时空编码检测出人群中的异常游荡行为[12]。从显著性角度,中国科学院学者提出基于显著性的异常事件检测方法,一方面通过对比两个连续的视频帧之间特征点的运动构造时空异常显著图,另一方面基于颜色对比构造空间异常显著图,实验结果显示该方法在没有训练阶段的情况下,对异常事件的检测效果具有较高的准确率和鲁棒性[13]。MoSIFT作为一种有效的特征描述符,不仅可以检测到空间上具有一定运动的、区分性强的兴趣点,并且能够通过兴趣点周围的光流强度衡量兴趣点的运动强度, 因此采用基于MoSIFT的行为表示方法进行异常检测可以得到较好的效果,例如文献[14]采用MoSIFT算法提取视频的低级别的描述,并采用核密度估计(Kernel Density Estimation,KDE)对MoSIFT描述符进行特征选择,消除特征干扰。基于Harris角点及兴趣点算子文献[15]在空间时间有显著的局部变化的部分建立时空局部结构,并计算它们的尺度不变的时空描述符,如此将空间兴趣概念扩展到时空域(Space-time Interest Points,STIPs)以获得更好的异常检测效果。此外针对彩色图像的运动行为描述问题,Insaf Bellamine等人通过对图像的色彩几何结构成分和纹理成分分解得到色彩时空兴趣点(Color Space-Time Interest Points,CSTIP),实现运动目标描述[16]。
异常事件常伴随着目标的运动速度变化,光流作为一种有效的目标运动描述子被广泛应用在异常检测的研究中。文献[17]基于光流采用运动粒子区分正常与异常行为从而实现拥挤场景下的异常行为检测。光流加速度和光流梯度直方图特征在文献[18]中被用来检测场景中存在的异常物体和速度违规现象。文献[19]中所采用光流多尺度直方图(Multistage Histogram of Optical Flow,MHOF)进行特征表示,MHOF不仅有传统的HOF (Histogram of Optical Flow)表示运动信息的功能,也可用于空间相关信息的表示。为利用方向信息,文献[20]采用具有更低维度的光流方向直方图(Histogram of Optical Flow Orientation,HOFO)描述子来区分正常与异常事件,并在全局异常检测中取得了较好的效果。为提取视频帧中存在运动的局部区域特征,文献[21]在对视频序列进行时空网格分割后,采用概率主成分分析(Mixture of Probabilistic Principle Component Analyzers,MPPCA)得到每个时空网格内的光流信息,并用于时空MRF模型的建立从而检测出视频中的异常。基于光流方法,研究人员采用两个新颖的局部运动视频描述子SL-HOF(Spatially Localized Histogram of Optical Flow)和ULGP-OF(Uniform Local Gradient Pattern based Optical Flow)对视频特征进行提取,SL-HOF描述符可以捕捉到时空兴趣块中三维局部区域变化的空间分布信息,ULGP-OF描述符融合了经典的2D纹理描述符LGP(Local Gradient Pattern)和光流算法,在定位视频前景信息时较普通光流算法更为准确,然后采用OCELM(One-class Extreme Learning Machine) 对两种描述符进行学习从而得到用于异常事件检测的正常事件模型[22],这类基于特征块的通用型框图如图4所示。
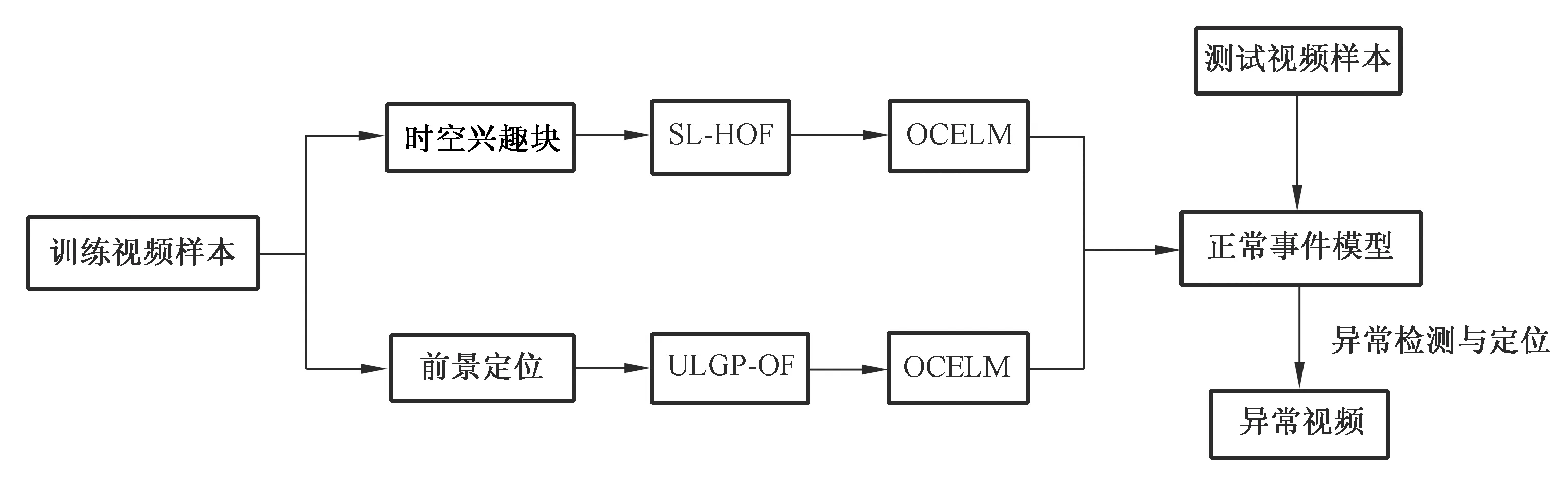
图4 基于时空兴趣块进行特征提取框图示例
Fig.4 Block diagram example for feature extraction for spatial-temporal interest blocks
为实现实时的视频异常检测,Roberto Leyva等人采用了二进制特征行为表示的异常检测方法。首先对输入视频帧进行前景、时间梯度(temporal gradients)计算,利用时间梯度、目标快速分割 (Fast Accelerated Segmentation Test,FAST)检测到时空兴趣点(Spatial Temporal Interest Points,STIPs)并采用二进制小波差异(Binary Wavelets Differences,BWD)对时空兴趣点进行编码,采用GMM(Gaussian Mixture Model)分别对前景占用率、汉明距离和直方图投票机制进行建模从而完成对异常的检测与定位,该方法基本框图如图5所示[23]。
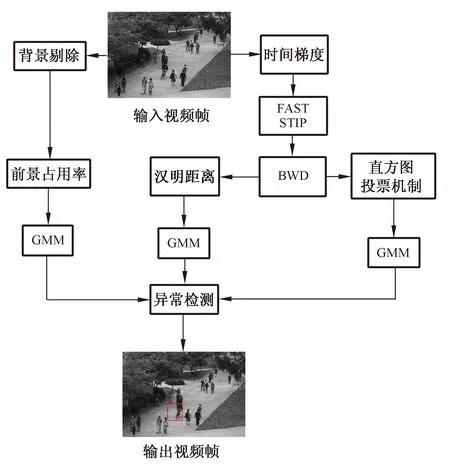
图5 基于单帧特征框图示例
Fig.5 Examples of feature method block diagram for single frame extraction
物体在运动时会产生运动的轨迹,而运动轨迹中包含运动物体的长度、像素、位置和运动程度等信息[23]。文献[24]中将提取的不同长度、时间变化带有噪声的轨迹进行分层聚类,对每类进行建模从而表示正常异常事件。近年来基于目标时空轨迹的新颖异常检测方法层出不穷,例如文献[25]提出基于轨迹稀疏重构的异常检测方法,在视频场景中提取最小二乘三次样条曲线近似值(the Least-squares Cubic Spline Curves Approximation,LCSCA)特征构成字典完成异常检测任务。Coar S等人认为无论是基于轨迹的方法还是基于像素的方法都具有局限性,不可能检测到所有的异常行为,轨迹特征可以检测出速度和方向的异常,但是类似于跳跃或打斗这类与人的部分肢体运动相关的异常动作很难从时空轨迹的分析中发现,同样,基于像素的方法可能无法探测到游荡的恐怖分子或小偷这类与人的整体运动有关的异常,因此作者融合两种方法采用断开轨迹高效地高层次地表示轨迹,既可以检测到物体的速度和方向也可以表示每个物体更为复杂的局部运动,在准确检测异常事件的同时减少了计算负荷[26]。文献[27]提出基于轨迹优化的异常活动检测系统,系统结构分为两层:在第一级低级别过程中,采用基于轨迹的方法产生轨迹信息进行实时异常处理,并对可疑事件进行实时检测分析并实时报警;在第二级中,采用密集视频分析算法检测可疑事件是否由实际人触发。
2.2 深度特征行为表示
通过手动设计提取的人工设计特征的方法尽管有众多的理论依据但是人为因素太强,不能客观地表示行为,其次通过这种方式提取的特征往往依赖于数据库,也就是说手动特征可能只对某些数据库表现较好而对其它的数据库并不一定可以获得同样的效果。当采用直接对数据进行学习的方式进行深度特征提取时,只需设计特征提取的规则,例如神经网络中通过人为设计网络模型的结构及学习的规则获得深度模型参数并提取深度特征,因此得到的特征往往无法解释具体每一维的物理含义。近年来,深度学习和卷积神经网络的快速发展为计算机视觉领域的各项研究提供了新思路,然而尽管普通的卷积神经网络对二维图像的特征学习有很好的效果,但是对于三维的视频特征学习有一定的局限性。为打破这一局限,Simonyan Karen等人提出了采用并行的双流网络分别对RGB图片的空间信息以及视频序列的光流图进行特征学习及行为判别,最后融合两个网络的判别结果得到最终的动作分类,实验证明双流网络对于特征提取及行为表示具有一定的效果[28]。研究者基于双流网络也做了一系列的改良并得到了多种双流网络衍生算法,如convolutional two-stream network[29],temporal segment networks[30]以及基于加权融合的STN[31]等。基于双流网络是通过对单帧进行二维特征学习并采用光流表达帧间关系并作为时域信息的弥补,Tran Du等提出了深度3维卷积神经网络(3 Dimension Convolution Network,C3D)将视频的连续帧即视频块作为输入简单高效地获得时域空域特征,将深度卷积网络的方法引入解决视频中的分类问题[32]。基于这一方法Zhou Shifu等人使用三维卷积神经网络解决了视频中的异常行为检测和定位,将整个视频中可能存在的时空兴趣块不经任何处理直接作为C3D的输入进行特征学习[8]。同时,Sabokrou Mohammad等人采用级联三维神经网络的方法,由三维自动编码器检测出时空兴趣块送入C3D中进行训练完成对异常进行快速的检测和定位[33]。此外,目标检测领域的深度学习经典方法如SSD[34]、Faster-RCNN[35]、YOLO[36]等实现了目标检测定位与分类的同步完成,为异常目标检测提供了新的思路。Xu Huijuan等人将Fater-RCNN的思路应用到时域的动作定位,并结合C3D网络得到R-C3D网络,该网络通过共享Progposal generation和Classification网络的C3D参数能够以更快的速度针对任意长度视频、任意长度行为进行端到端的检测[37]。类似对C3D网络进行改进的还有CDC网络,该网络首次将卷积、反卷积操作应用到行为检测领域,在实现端到端学习的同时,做到了对每一帧的预测(per-frame action labeling),取得了较好的效果[38]。
3 异常行为识别分类方法
针对视频监控中异常行为(全局异常,局部异常)的检测问题作为计算机视觉中的具有挑战性的任务近年来已有重要的进展,根据学习过程中需要用到的样本类型,可将分类的方法归纳为监督、半监督和无监督三种方式,常用的异常行为识别分类方法如图6所示。

图6 异常行为分类方法框图
Fig.6 Block diagram of abnormal behavior classification
3.1 有监督异常行为分类方法
监督的分类方法需要在建模之前对所有的正常数据和异常数据都进行标签标记,属于传统的分类问题,对于视频异常检测来说是二分类的问题,经典监督分类方法包括支持向量机(Support Vector Machine,SVM),例如文献[39]提出的基于遗传算法特征选择与支持向量机(SVM)训练混合优化模型。该方法为在短的时间内快速获得最优特征子集和SVM参数,提高监控视频异常检测的准确性,采用自适应模拟退火遗传算法(Adaptive Genetic Simulated Annealing Algorithm,ASAGA)进行特征选择。ASAGA通过模拟退火算法(Simulated Annealing Algorithm,SA)的局部搜索能力大大改善了遗传算法(Genetic Algorithm,GA)的慢收敛和复杂度高的问题。除此之外,Kim H等人基于测地线图 (geodesic graph)和支持向量机(SVM)分类器对人体行为异常识别进行研究,该算法根据对人体关节的估测完成异常检测,然而异常检测效果对被检测到的人体区域较为敏感[40]。近年,深度学习和云计算技术的飞速发展为计算机视觉领域取得突破性的发展,卷积神经网络作为最新监督学习方法被广泛应用于拥挤场景中的异常行为检测研究,如文献[8,33]都是采用监督的方法先对所提取的含有运动信息的时空兴趣块进行标签标记,并作为三维卷积神经网络的连续帧输入进行训练,最后由训练得到的模型对测试集中的时空兴趣块进行异常判别,这种基于卷积神经网络的视频异常检测方法很大程度上提升了异常检测的速度和效率。
管棚灌浆孔封孔应采用“机械压浆封孔法”或“压力灌浆封孔法”,用浓浆(0.5:1)全孔一次性封孔。封孔压力为该孔最大灌浆压力。如该段灌浆结束为最浓一级水灰比(0.6:1)时,可不进行置换浓浆,直接封孔。
3.2 半监督异常行为分类方法
采用半监督方法进行训练时只需要对正常的视频数据进行标签标记,根据分类原理半监督方法可分为基于规则和基于模型的方法。基于规则的半监督方法通过对只含有正常样本训练集进行规则学习,将测试阶段任一不符合此规则的样本判为异常,最常用的基于规则的半监督分类方法是稀疏表示,例如文献[41]提出一种基于规则的稀疏编码方法来检测异常行为,虽然这种方法可在较短的执行时间(每秒150帧)内取得完成异常检测,但其效果对阈值选择过于敏感。Zhu Xiaobin 等人将稀疏重构代价引入正常字典衡量测试样本中的异常,该方法在稀疏重构的每个主要成分引入先验权重,与其他的方法相比有更好的鲁棒性[42]。为了克服训练样本的缺乏,实现更精确的检测,文献[43]提出动态更新的双稀疏字典表示方法,该方法从只包含正常样本的训练样本集得到正常字典,然后通过稀疏表示方法和正常字典对测试样本进行分类,如果分类结果是正常,则将这一特征加入到正常字典进行字典的动态更新,如果分类结果为异常,则将这一特征动态更新到异常字典中。目前大部分用于解决异常分类问题的稀疏表示方法在构造字典时并没有将结构信息考虑在内此外,因此,Yuan Yuan等人通过正常数据训练得到结构字典,并在测试阶段根据所提出的参考事件的概念即当将正常事件作为参考事件进行训练时,相较于异常事件,正常事件与参考事件具有更强的相似性,将无法用结构字典表示的行为判为异常行为[44]。基于模糊规则,Albusac等人通过自动动态地设置正态分量的权重提高异常检测的效率[45]。Chen Zhengying等在视频异常事件检测研究中采用基于模糊聚类方法和多个自动编码器的框架,该框架利用模糊聚类对运动目标的运动轨迹进行提取和分组并使用训练阶段聚类后的编码实现了视频中的异常行为检测与定位[46]。
在基于模型的方法中,通常采用正常样本进行模型构造,由于异常样本总是偏离于由正常样本构成的模型,因此在测试阶段时通常将偏离于模型的样本判为异常。常用的模型有:高斯混合模型(Gaussian Mixture Model,GMM)、马尔可夫随机场(Markov Random Field,MRF)、隐马尔可夫模型(Hidden Markov Model,HMM)。如文献[17]利用人群分布信息和人群速度信息估计由正常行为构建的高斯混合模型的参数,并对异常人群行为进行检测。隐马尔可夫模型作为标准马尔可夫模型的扩展是在标准马尔可夫模型基础上添加了可观测状态集合以及这些状态与隐含状态之间的概率关系。Weiya R等人通过隐马尔可夫模型,将提取的轨迹信息作为衡量标准来判别测试样本中的时空信息块是否存在异常[47]。文献[21]中采用时空MRF模型完成对视频的半监督异常检测,该方法首先将视频序列在时空内进行网格分割,并采用概率主成分分析(Mixture of Probabilistic Principal Component Analyzers,MPPCA)获取网格的局部光流信息并对应到MRF图的节点,通过MPPCA模型计算MRF模型参数对异常事件进行检测,同时完成对MPPCA和MRF的参数更新。Hajananth N等人在训练阶段采用高斯混合模型进行聚类,在测试阶段采用基于马尔可夫的随机场的高斯混合模型(GMM-MRF)对测试样本进行判别,取得了较好的异常检测效果[18]。此外,文献[48]提出基于社会力模型的视频异常行为检测和定位方法为异常检测研究提供了新思路。
3.3 无监督异常行为分类方法
无监督的检测方法属于典型的聚类问题,无需事先获得任何的先验知识,单独依靠样本数据之间的连接完成正常事件的聚类和建模,然后把小概率的或相似度非常低的事件看作异常事件,如此完成异常判断。Alvar M等人采用主集(dominant set)的无监督学习框架实现了高效的异常行为检测,这种方法与其他聚类方法相比具有更好的鲁棒性[49]。此外,文献[41,50]采用非负矩阵分解(Non-negative Matrix Factorization,NMF)对特征空间学习,并使用支持向量数据(Support Vector Data Descryiption,SVDD)在特征空间通过聚类程度检测出异常。在深度学习方法中生成式对抗网络可以实现无监督的学习,Mahdyar Ravanbakhsh等人通过生成式对抗网络(Generative Adversarial Nets,GAN)中生成模型和判别模型之间的博弈实现监控视频中的异常行为检测与定位。该方法通过生成式对抗网络对正常场景的帧图像和对应的光流图的训练得到场景中正常行为的内部表示,并在测试阶段将测试数据的外观表示和运动表示与正常数据进行比较,由于存在异常的区域无论是外观表示或是运动表示都与正常数据有很大的不同,通过计算局部符合程度检测出异常所在区域[51]。
3.4 异常行为分类方法优缺点分析
基于监督的视频异常检测方法易于操作和理解,可以充分利用先验知识控制训练样本的选择,并通过反复检验训练样本提高异常检测的精度如SVM[39]C3D[8,33]。然而这类基于监督的方法主观因素较强,需要花费大量的人力和时间对训练样本进行选择和评估,同时这种方法无法自动调整异常的数据并自适应的更新异常或者自动生成新的异常模式,因此往往对应用场景具有局限性即对于不同的场景需要重新设计检测算法。基于规则的半监督检测方法如稀疏表示[41-44]易于操作,但计算复杂且需要强大的内存。基于模型的半监督分类方法运算速度快、模型简单容易建立,但是模型的分类效果对多个参数敏感,同时这种方法很容易将训练中没有出现过的正常数据错判为异常[17-18,21,47-48]。无监督的检测方式无需获得任何先验知识,运算快捷简便,但需通过大量的分析和处理才能得到可靠的分类结果,例如GAN网络尽管可以通过无监督的方式得到视频场景中正常行为的内部表示,但是最终测试数据中异常目标的检测与定位还需要靠与正常数据的符合程度分析来获得[51]。
4 视频异常检测数据集
近年来最常用的数据集有UCSD行人异常数据集、UMN全局恐慌数据集、Hockey Fight暴力行为数据集[6]和LV数据集[52],本节将介绍这几个标准实验数据集,各数据集中正常及异常示例如图7所示。
UCSD数据集分为两部分Ped1和Ped2,二者都是由一个安装在固定高度的摄像机俯瞰行人获得的视频,数据集中的人群密度随着时间的推移不断变化。Ped1中包含34个用于训练的正常视频序列及36个用于测试的含有异常的视频序列,其中每个视频序列的帧长都为200,每帧分辨率为158×238。Ped1主要描绘的是人群在视频画面中的垂直方向移动,人群走向主要为走向和远离摄像头,具有一定的透视畸变。Ped2描绘的是人群的水平移动,包含16个正常的训练序列和12个包含异常的测试视频序列,每个序列的帧长由120到170不等,每帧的分辨率为360×240。UCSD数据集中训练样本只含正常行为,测试集中的某一帧中可能不存在、存在一个或多个异常行为,其中异常类型主要有:自行车、滑冰、小型汽车,轮椅等。Ped1中的物体分辨率较低给识别造成一定的难度而Ped2中的遮挡问题比较严重,因此,UCSD是一个具有挑战性的拥挤场景下的局部异常数据集。
UMN数据集中的异常属于全局异常,主要表现为恐慌、四处逃散。UMN数据集总时长为4分17秒,帧速率大小为30帧/秒,每帧大小皆为320×240。UMN数据集含有室内室外三种场景下的11个视频片段,包括两个彩色草坪场景片段,六个黑白长廊视频片段及三个彩色广场场景片段,视频内容皆为正常的行走或游荡从某一帧忽然开始四处逃散直至消失在视频画面中。
Hockey Fight数据集[6]描述的是曲棍球比赛中的暴力斗殴异常行为,共分为两个部分:暴力斗殴及正常的曲棍球比赛,两部分分别含有500个独立的视频片段,每个视频序列的帧速率为25帧/秒,每帧大小为360×288。




图7 部分数据库正常、异常帧示例
Fig.7 Examples of normal and abnormal frames in some databases
5 性能评估准则
异常检测性能评估的目的是在衡量某一异常检测方法效果的基础上将这一方法与其他各类方法进行比较,如此验证新方法的先进性和可靠性。关于视频监控系统的评估项目有很多,例如,由美国国家标准与技术研究院(National Institute of Standards and Technology,NIST)发起的全球视频内容分析比赛TRECVID(TREC Video Retrieval Evaluation)采用SED(Surveillance Event Detection)评估监控系统实时检测的效果[53]。
在视频异常检测领域,两个常用的异常检测评估标准是等误差率(Equal Error Rate,EER)和ROC曲线下的面积AUC(Area Under Curve)。这两个标准来自于接收机操作特性曲线(Receiver Operating Characteristic Curve,ROC),该曲线非常适用于性能比较。等误差率EER是ROC曲线上假阳性率FPR(False Positive Rate:正常行为被认定为异常)与假阴性率FNR(False Negative Rate:异常行为被认定为正常)相等的点即ROC曲线与ROC空间中对角线([0,1]-[1,0]连线)的交点。如果一个识别算法ROC曲线中的EER越小AUC越大,则表明这个方法的性能越好。
基于ROC曲线的评估标准分为三个级别:帧级准则(frame level criterion),像素级准则(pixel level criterion)及双像素级准则(dual pixel level criterion)。异常检测领域部分优秀方法在帧级和像素级的评估准则下UCSD Ped1的实验效果比较如表1所示,对UCSD Ped2的实验效果比较如表2所示。UCSD Ped1、Ped2中双像素级EER(β=5%)比较如表3所示。
在帧级准则中,若检测出某一帧至少含有一个异常行为则将这一帧记为异常帧,该标准仅关注异常行为的时间定位精度,不考虑异常的空间定位准确度。因此,当采用这一准则进行性能评估时可能发生假阳性的巧合预测,即在某一存在异常行为的帧中并未检测出真实异常行为而是将某一正常行为错判为异常,如此巧合地将检测结果认定为检测正确。
表1 UCSD Ped1中帧级和像素级EER、AUC比较
Tab.1 EER and AUC for frame and pixel level comparisons on UCSD Ped1%
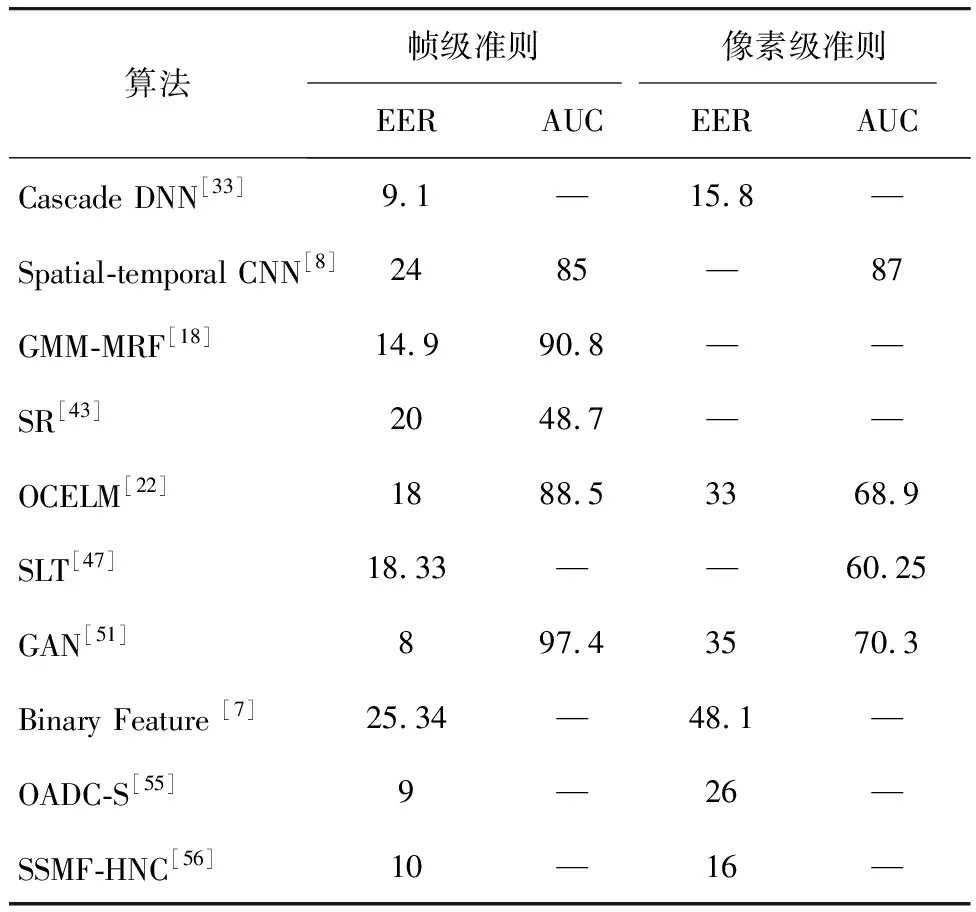
算法帧级准则像素级准则EERAUCEERAUCCascade DNN[33]9.1—15.8—Spatial-temporal CNN[8]2485—87GMM-MRF[18]14.990.8——SR[43]2048.7——OCELM[22]1888.53368.9SLT[47]18.33——60.25GAN[51]897.43570.3Binary Feature [7]25.34—48.1—OADC-S[55]9—26—SSMF-HNC[56]10—16—
表2 UCSD Ped2中帧级和像素级EER、AUC比较
Tab.2 EER and AUC for frame and pixel level comparisons on UCSD Ped2%
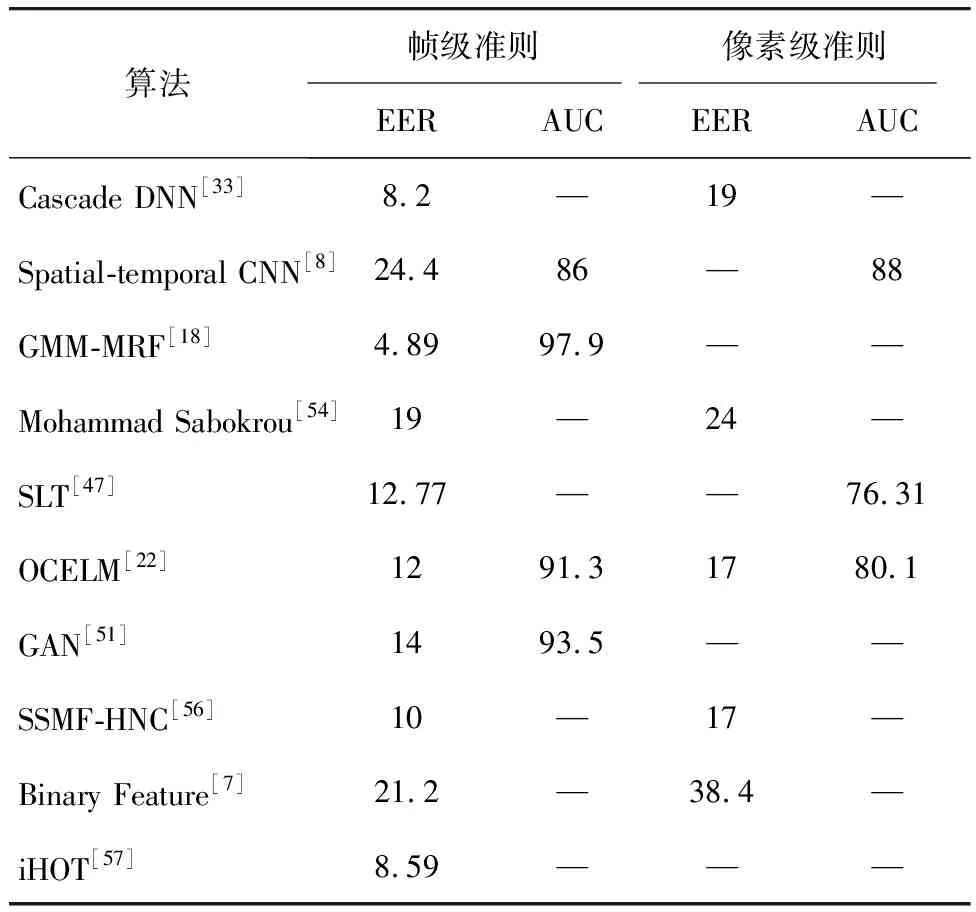
算法帧级准则像素级准则EERAUCEERAUCCascade DNN[33]8.2—19—Spatial-temporal CNN[8]24.486—88GMM-MRF[18]4.8997.9——Mohammad Sabokrou[54]19—24—SLT[47]12.77——76.31OCELM[22]1291.31780.1GAN[51]1493.5——SSMF-HNC[56]10—17—Binary Feature[7]21.2—38.4—iHOT[57]8.59———
表3 UCSD Ped1、Ped2中双像素级EER比较
Tab.3 EER for dual level comparisons on UCSD Ped1 and Ped2%

算法UCSD Ped1UCSD Ped2Mohammad Sabokrou[54]—27.5Cascade DNN[33]24.523.8
在像素级准则中,只有将某一帧中所有真实异常行为所在像素块的40%以上被正确检测到,这一帧才可被认定为有效异常检测的异常帧,否则视为判错。像素级标准需要对异常检测的时间和空间定位精度进行评估,因此更为严格和详细,评估结果也更为可靠。在采用这一准则进行性能评估时,有研究人员采用异常检测率(Rate of Detection,RD)代替EER对方法的异常检测效果进行评估,异常检测率越大方法的异常检测效果越好。在实际评估时,若某一帧中被检测到多处存在异常的区域,其中只有一处真实标签为异常其他区域皆为幸运猜测的错判,在采用帧级和像素级准则进行评估时依旧将这一判别视为检测正确,因此,研究者引入了双像素级评估准则[45,54]对异常检测效果进行更为准确、严格的评估。
在双像素级准则中若某一帧被视为异常帧需满足:1)这一帧满足像素级准则标准下的异常判定;2)被检测为异常的区域至少β%(如10%)真实标签为异常。这一准则不仅要求在时间和空间上对异常进行准确的检测和定位对于假阳性错判也十分敏感,相较于其他准则,该准则对异常事件检测的准确度的检测更为可靠。
6 结论
本文讨论了视频监控系统的不同层次,即运动目标检测与前景提取、特征提取和行为表示以及异常行为识别分类方法,首先对运动目标检测、特征提取与描述常用方法进行总结,然后针对行为建模的不同分类方法进行了归纳,最后讨论了视频异常检测研究常用的数据集以及异常检测性能的评估标准。
近年来,视频异常检测技术快速发展,取得不小的进展,但这项技术存在局限,主要的局限有以下四种:1) 在复杂场景下,选择合适的运动目标的特征尤其是异常目标特征是一项十分重要且困难的任务。2) 相对于正常事件可用于训练的异常事件数量较少。3)大多数异常行为识别算法只针对单个摄像机,与实际情况不符,因此研究人员将多个摄像机捕捉移动对象的不同视图将组合起来进行下一步的研究,尽管这种方法效果较好,但是过于复杂耗时并不适合实时应用。4)某行为是否异常取决于运动发生的场景、动作的时间和地点,因此若将某方法应用到另一场景时需要重新进行训练建模。随着深度学习和云计算技术的发展,若将包括所有可能场景的大量数据投入训练,得到具有强大学习能力以及场景适应力的模型,将会使异常检测技术得到历史性的突破。
