基于BP神经网络的分段函数连续优化处理
2019-03-18冯长敏张炳江
冯长敏,张炳江
(北京信息科技大学 理学院,北京 100192)
0 引言
数值优化与计算中,有很多学者研究了光滑优化问题。如,张培爱[1]提出了求解非线性规划的一个连续化方法,其KKT条件通过NCP函数转化为一个非光滑的方程组,然后用熵光滑化函数光滑化,得到一个带参数的方程组,为此提出了一个求解该参数方程组的非内点连续化方法,但是计算效率不高。
人工神经网络(ANN)是在人脑结构的启发下所构建的计算模型。不同于一般的算法,被训练后的神经网络可以完成一些特殊的功能,为系统提供一系列具有代表性的描述问题的样本,即成组的输入、输出样本。神经网络可以推断出输入和输出数据间的映射关系。当训练完成之后,与训练阶段的样本相类似的数据可由神经网络来辨识[2]。
最小二乘法(又称最小平方法)是一种数学优化技术。它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。最小二乘法还可用于曲线拟合[3]。
本文以一分段函数为实例,先分析其在间断点处的特点,然后在间断点的领域内随机取出一组正态分布的数据作为输入样本值,计算后的函数值作为输出样本值,然后利用神经网络进行仿真,最后再利用最小二乘法进行函数拟合得出光滑函数,并对其进行误差分析[4]。
1 分段函数的分类
分段函数一般划分为连结型分段函数、分离型分段函数和它们的组合形式3种类型。其中分离型分段函数和组合形式是不具有连续性的。这里研究的是分离型分段函数和它们的组合形式。连结型分段函数如图1所示,分离型分段函数如图2所示,组合形式如图3所示。
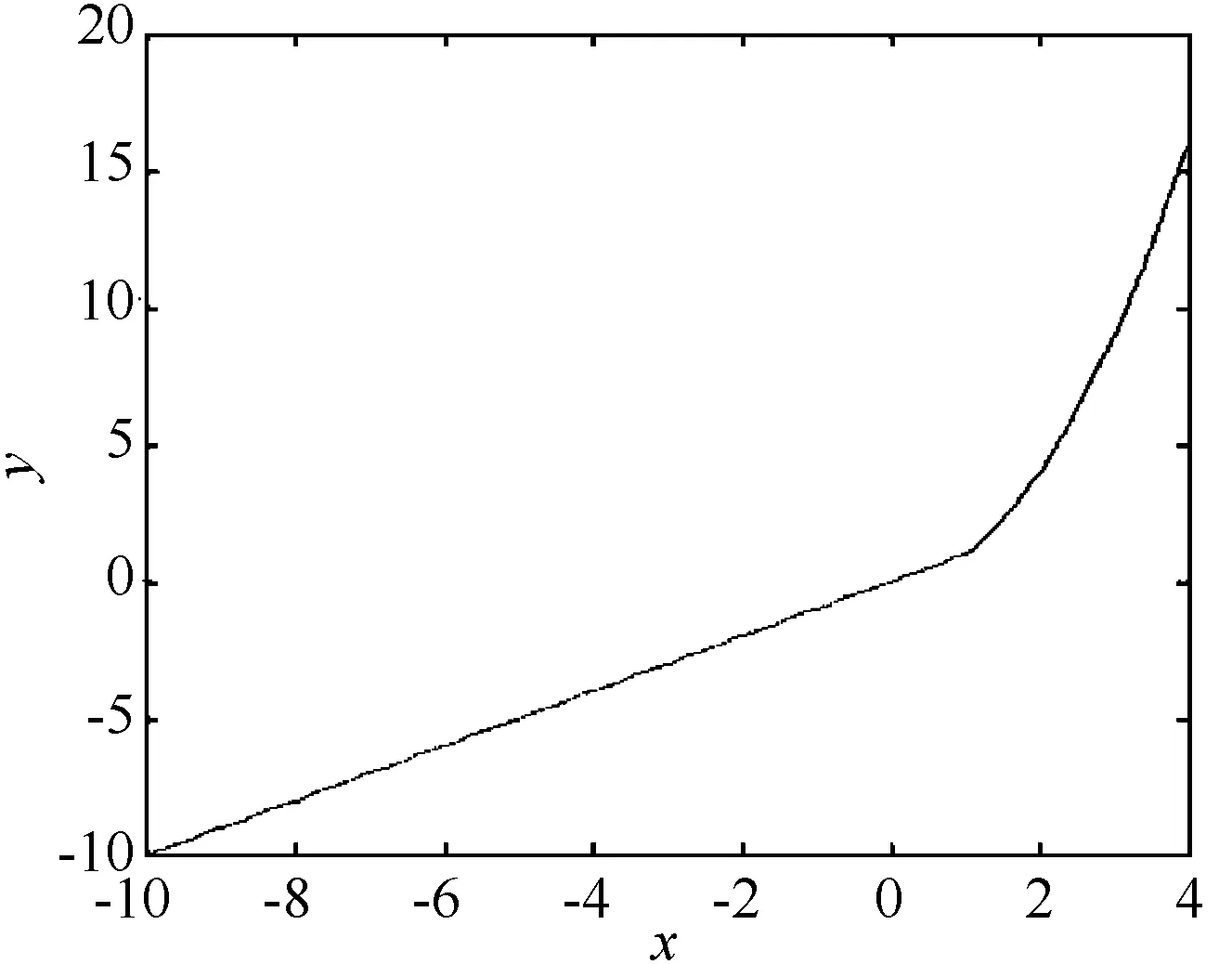
图1 连结型分段函数
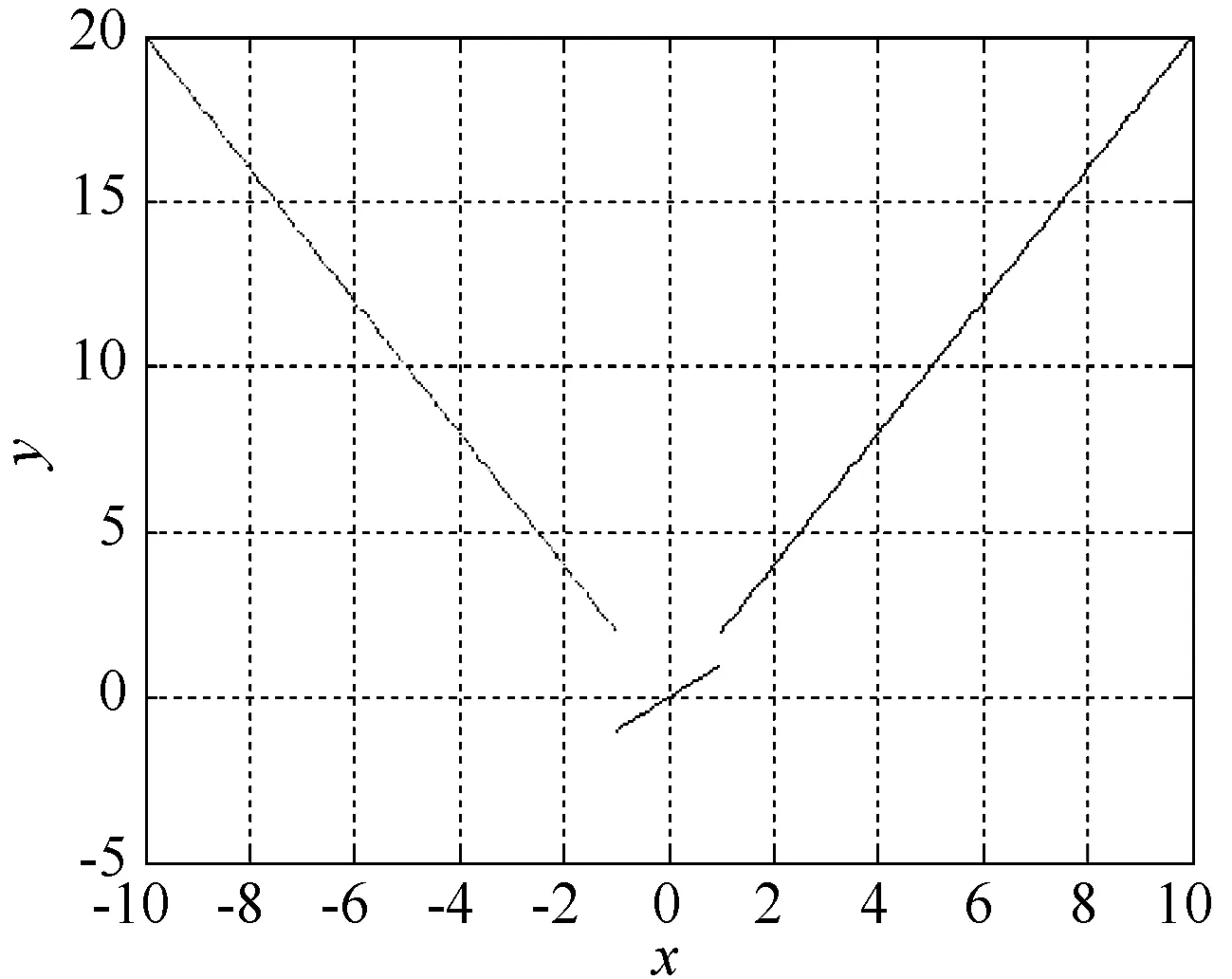
图2 分离型分段函数
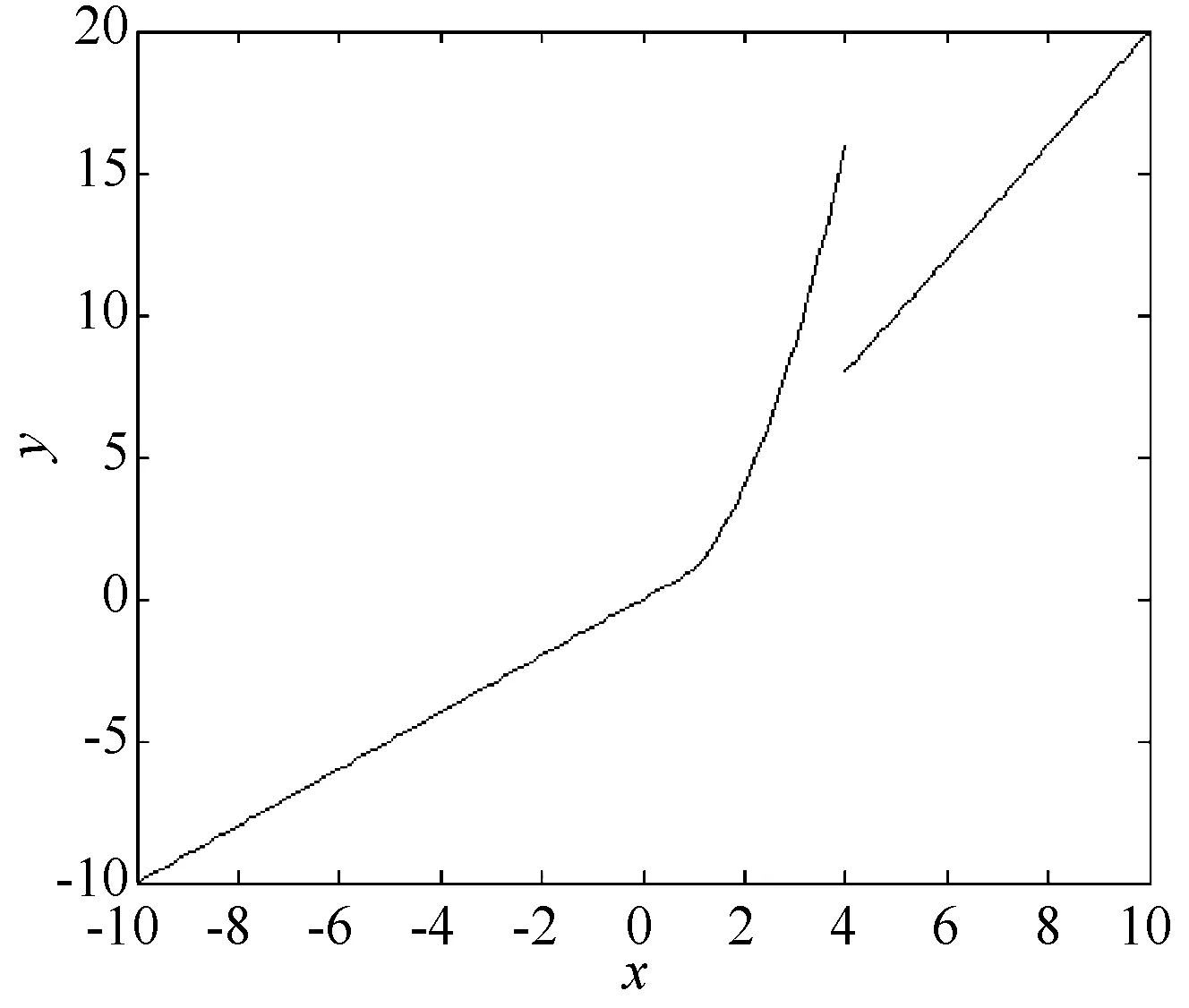
图3 组合形式
2 BP神经网络学习过程
BP(Back Propagation)神经网络,是目前应用较为广泛的前向网络。它由2个传播过程所组成,一是信息的正向传播,二是误差的反向传播[5]。BP 神经网络具有3层或更多层,各种神经元在上下层之间实行的是全连接,而各层之间的神经元则无任何连接。图4是一个3层 BP 网络的结构示意图。

图4 三层BP网络结构
BP神经网络学习基本原理为:对n个输入样本p1,p2,…,pn以及与其对应的输出样本t1,t2,…,tn进行学习训练,学习训练的目的是通过用网络的实际输出a1,a2,…,an与目标向量t1,t2,…,tn之间的误差来修改其权值,使ai(i=1,2,…,n)与期望的ti尽可能地接近,即让网络输出层的误差平方和达到最小。这个过程中,通过连续不断地在相对于误差函数斜率下降的方向上计算网络权值和偏差的变化而逐渐快速地逼近目标,每一次权值和偏差的变化都与网络误差的影响成正比,并以反向传播的方式传递到每一层。
BP神经网络具体训练步骤为:
第一步设置网络相邻层之间节点的初始连接权值、隐含层和输出层之间节点的初始阈值。初始权值和阈值一般选取(-1,1)之间的随机小量;
第二步选取并输入训练样本;
第三步确定输入信息在正向传播过程中的激活函数。在本文分段函数连续优化处理中使用S型激活函数:
f(x)=1/(1+e-x)
(1)
在经过S型激活函数的作用后,在输出层节点k(k=1,2,…,H)处得到输出值:
(2)
式中
(3)

第四步计算训练输出yk与目标输出Tk之间的误差:
δk=(yk-Tk)yk(1-yk)
(4)
第五步令误差δk沿原来的通道返回,进入反向传播,计算引起的隐含层误差:
(5)
第六步沿降低误差的方向调整权值μjk和阈值ψk:
(6)
ψk=ψk+dδk
(7)
第七步沿降低误差的方向调整权值wij和阈值θj:
wij=wij+cγjxi
(8)
θj=ψj+dγj
(9)
第八步针对训练样本集中的每个样本,反复学习上述过程,直至整个样本集的均方误差
(10)
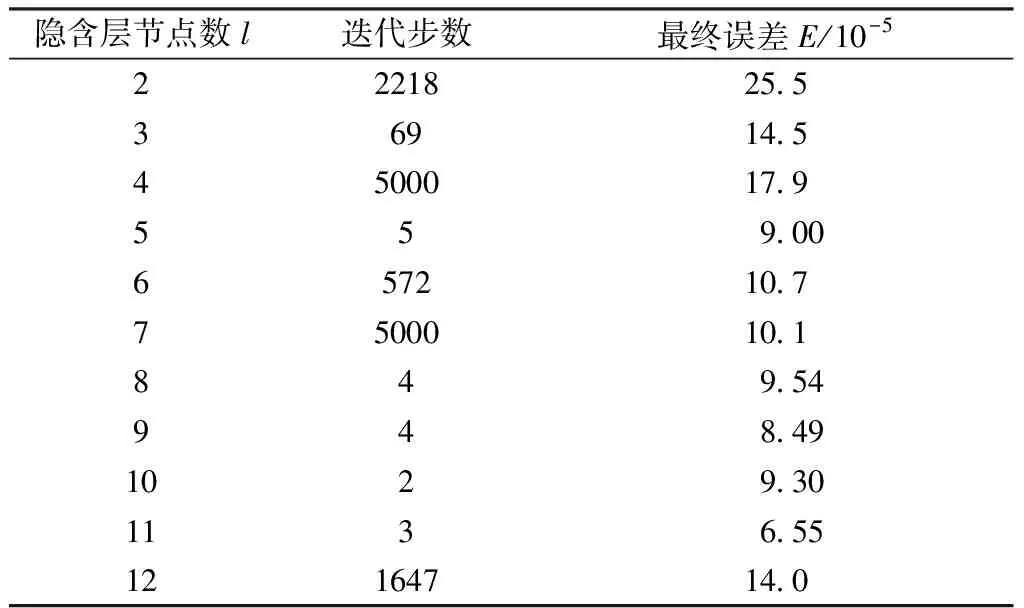
在达到某种精度要求a,即E (11) 式(11)为一分段函数,其间断点为x=-1,纵轴分段距离为0.5,函数图像见图5。要对其进行连续化处理,采用神经网络函数逼近方法得到一个精度比较高的连续函数去逼近。 图5 分段函数图像 由于该分段函数分段点为x=-1,为了使得神经网络函数逼近得到的函数精度更高,逼近效果更好,所以取样本点要求在间断点x=-1近的领域样本点密集,远的领域样本点稀疏,呈现正态分布。采用matlab中的normrnd函数随机取出一组正态分布的数据,其中μ取-1,σ取0.5,共取出300个数据。再利用normpdf函数画出其正态分布图象如图6所示。把所取样本点代入函数计算函数值,画出样本点,其实际值图像如图7所示。 图6 数据分布 图7 样本点—实际值图像 由于输入变量只有1个,为函数自变量x,因此输入层的节点数n为1;输出变量只有y,即输出层节点数m为1。隐含层节点数的多少直接决定了建立的BP神经网络的训练性能。如果节点数太少,网络可能无法训练,或者建立的网络容错性差,鲁棒性差,抗噪音能力差;如果节点数太多,网络的复杂性和训练时间急剧增加,甚至可能使网络难以收敛或无法收敛[7]。 终止条件:训练最大迭代数为5000(net.trainParam.epochs=5000),目标误差10-4(net.trainParam.goal=1.0e-4)。学习率η不同BP神经网络参数和训练时间也会不同,学习率过大时可能会导致系统的不稳定,学习速率较小会导致较长的训练时间,可能导致收敛很慢。η需要由实验来确定具体的值。隐藏层和输出层的传递函数分别为正切s型函数tansig和线性函数purelin,设置BP神经网络的训练函数为trainlm函数,trainlm即采用Levenberg-Marquardt学习算法,该算法的优点在于其训练过程收敛速度快,且网络的训练误差也比较小[8]。 为了使建立的神经网络具有更好的性能,须对输入样本先进行归一化处理。本文是将输入变量的值折算到[0,1]区间内[9]。 要确定隐含层节点数,需要先取定学习率η的值。通常情况下学习率取为0.3,所以此处先取定η=0.3。采用上述确定的神经网络结构和样本数据进行训练,如表1所示,隐含层节点数为5和9时最终误差较低,通过综合考虑建立网络结构的复杂性和训练速度等因素,本文选择隐含层节点数为5,其神经网络训练图如图8所示。 表1 不同隐含层节点数下训练参数 图8 隐含层节点数为5的训练图 确定隐含层节点数为5之后,通过试验确定学习率,训练结果如表2(初始0.0001)所示。综合考虑各因素,再对照表2,最终选择学习率η=0.3。 表2 不同学习率下训练参数 使用newff函数创建BP网络,然后使用train函数训练网络,再使用sim函数进行仿真。其实际值和仿真值的对比如图9所示。 图9 实际值—仿真值对比 使用matlab中的函数拟合工具箱cftool进行函数拟合。得到函数表达式为一9次多项式: f(x)=p1·x9+p2·x8+p3·x7+p4·x6+ p5·x5+p6·x4+p7·x3+p8·x2+ p9·x+p10 (12) 式(12)中系数以及95%置信区间为: p1=-0.168 (-0.221 1, -0.114 4) p2=-1.453 (-2.023, -0.883) p3=-4.336 (-6.809, -1.864) p4=-3.986 (-9.546, 1.574) p5=3.813 (-2.989, 10.62) p6=7.948 (3.725, 12.17) p7=1.754 (0.694, 2.813) p8=-1.541 (-2.067, -1.016) p9=1.689 (1.514, 1.864) p10=0.536(0.515, 0.557 1) 该函数拟合的误差分析结果为: SSE(误差平方和): 0.422 3 R-square(确定系数): 0.998 9 Adjusted R-square: 0.998 8 RMSE(标准差): 0.038 09 由上述误差分析结果可知该拟合函数能较精确地代替前面的分段函数式(11)。 本文使用了BP神经网络对分段函数进行连续化处理,样本输入点集为自变量区间的离散点组成的集合,并且考虑了分段函数间断点对函数值间距的影响,所取出的样本点集满足正态分布特性,从而对间断点附件的函数值预测效果更佳。最后结合最小二乘法曲线拟合的方法得出了具体的函数表达式,有助于该类优化问题的进一步优化求解。本文通过实例验证了该方法的有效性。3 最小二乘法曲线拟合
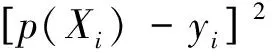
4 实例验证
4.1 问题描述
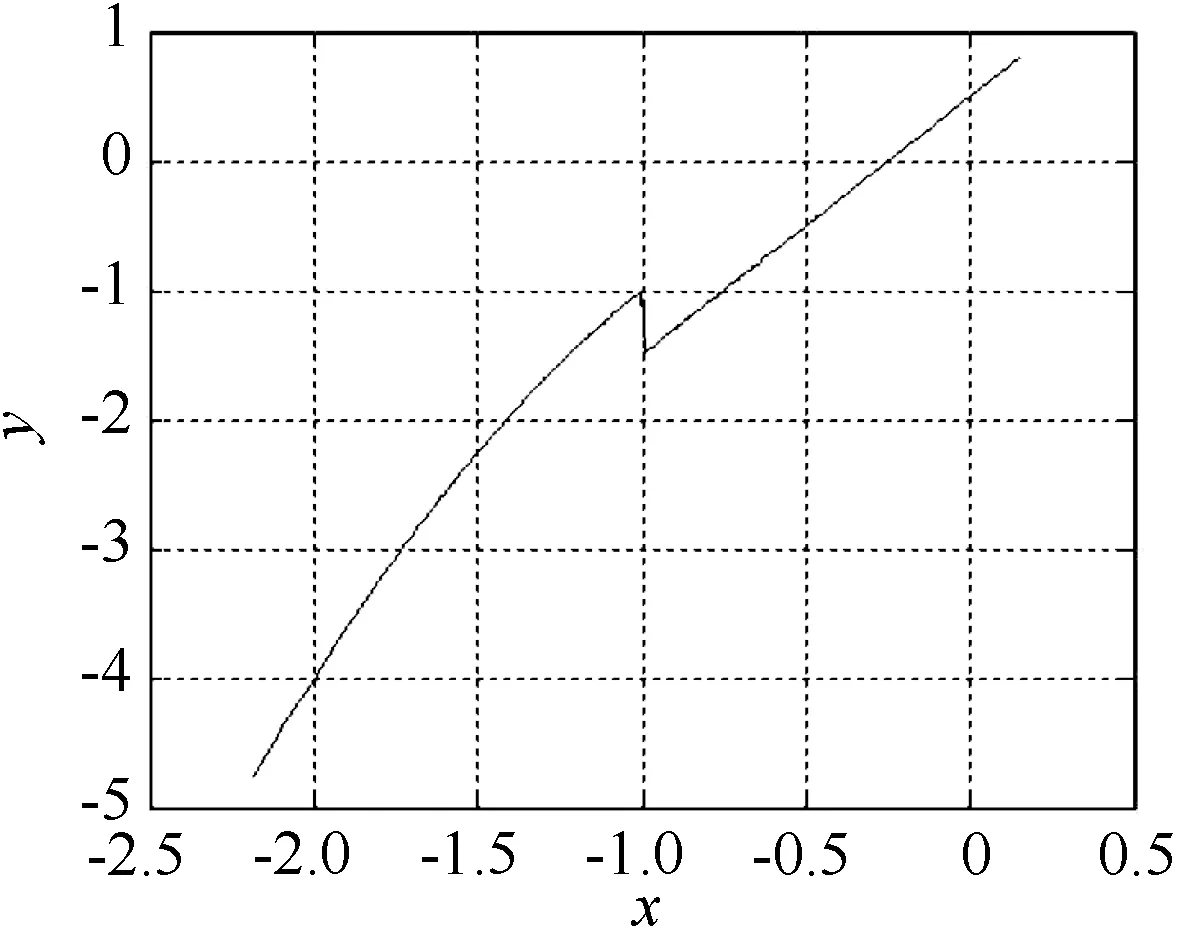
4.2 样本确定
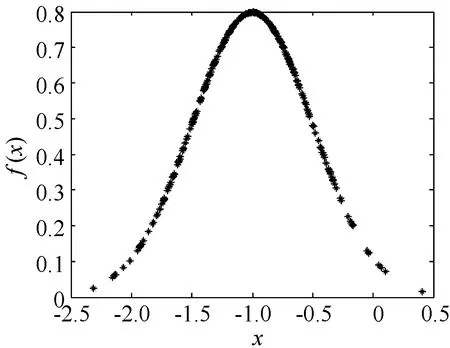
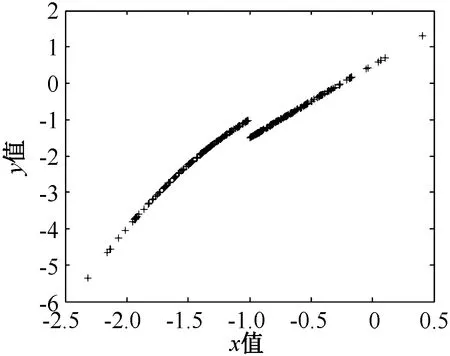
4.3 构造神经网络
4.4 隐含层节点数和学习率


4.5 仿真结果

5 结束语
