一种通用的恶意域名检测集成学习方法
2019-03-17刘浩杰皇甫道一李岩王涛
刘浩杰 皇甫道一 李岩 王涛

摘 要:僵尸网络是指采用一种或多种传播手段,将大量主机感染僵尸病毒,从而在主控者和被感染主机之间,通过命令控制服务器,形成一个一对多控制的网络。攻击者操纵僵尸网络通常会使用多个域名来连接至C2服务器,达到操控受害者主机的目的。这些域名一般被硬编码在恶意程序中,使得攻击者能便捷地更改这些域名。为了躲避封禁,这些域名通常由域生成算法(Domain Generation Algorithms,DGA)生成。针对普遍的机器学习检测DGA域名方式存在样本不充分及通用型不强的问题,文章在研究了大量DGA域名生成算法的基础上进一步完善黑白样本,利用文本分析的手段结合GaussianHMM、LSTM、BernoulliNB模型提取具备普遍区分能力的特征,构建一个具备低风险结构的通用DGA检测集成学习方法。
关键词:僵尸网络;恶意域名;域名生成算法;集成学习
中图分类号:TP309 文献标识码:A
Abstract: Botnet refers to the use of one or more means of transmission, which will infect varieties of servers with zombie virus, therefore could result in a potential one to many control network between the controller and the infected servers. In order to gain the control of the infected servers, establishment of connections from multiple domains to C2 server would normally be used upon virus network. These domains could be programmed into codes, which could be easily changed by the hackers. To avoid being banned, these domains are normally generated by using Domain Generation Algorithms(DGA). Actually, some studies showed machine learning methods to cope with the issue mentioned. However, these methods does have issues such as insufficient samples and non-universal. This paper focus on the improvements of WriteBlack Sampling based on the fundamental of DGA by using text analysis in combination with GaussianHMM, LSTM, BernoulliNB. These models could effectively subtract the key features, therefore construct a low risk structured universally used DGA ensemble machine learning model.
Key words: botnet; malicious domain; domain generation algorithms; ensemble learning
1 引言
域名系統(Domain Name System)作为互联网的核心基础建设设施,主要是进行域名解析,域名解析为可访问的互联网IP地址,看似简单却异常重要。随着黑产的云化和人工智能化,互联网的规模不断扩大,网络出现漏洞和遭受黑产攻击的可能性也越来越大。作为守方安全从业人员也面临着愈加严峻的考验,黑产攻击手段推陈出新的同时互联网安全防护技术也是亦步亦趋,形成了一场没有硝烟、没有终点的持久战。在众多的黑产攻击技术当中,僵尸网络就是最常被采用的攻击手段,例如连续导致美国和德国断网的Mirai恶意软件,便内置了DGA域名生成算法,不仅感染控制了大量的摄像头等互联网终端设备组成僵尸网络,其自身还不断出现新的变种。僵尸网络采用不同的DGA算法生成大量的随机域名,对传统的防护手段带来了极大的考验。
1.1 DGA生成原理
域名在构造上可分为主机名和域名(顶级域名或二、三级域等),各Lable以点号分割,各Lable最长63个字符,而且总长度不能超过255。DGA域名在构造上一般用随机算法来生成主机名,因此只对DGA算法生成的主机名的字符串进行分析。本次实验搜集了大量DGA生成算法的源码,对每一种典型的生成方式进行了观察和研究。简单来说,DGA域名生成的原理是基于硬编码的常量以及字典,通过加入一些随机种子,利用一定的加密算法,生成一系列伪随机字符串来作为域名,如图1所示。
1.2 DGA相关研究
近年来,随着互联网安全越来越被重视,网络安全成了一个热门的话题。大量的学者、企业安全从业人员对恶意域名进行了深入研究。目前,针对恶意域名的检测方法可以分为主动分析和被动分析两种。主动分析方法一般包括DNS探测、网页内容分析及人工专家模式分析。被动分析包括黑白名单规则匹配、机器学习、图论。理论上,DGA域名的数量是可以无限生成的,传统的黑名单方式每增加一条域名黑名单,就意味着服务器会增加一份负担,因此使用机器学习的手段检测来DGA域名成了对抗黑产的有效手段。传统机器学习手段需要大量的特征提取,然后投入到传统的机器学习模型对这些特征进行分类。常用的机器学习算法有随机森林、XGBoost、lightGBM、支持向量机、HMM等。深度学习方法将每个字符或N-Gram后的字符组合当作一个特征,简化了特征转换方式,利用复杂的神经网络,主动去学习各个字符上下文之间的关系。目前,主流的深度学习方法有LSTM、CNN、GAN。
Jonathan Woodbridge等人将N-Gram后的域名字符组合序列投入LSTM模型,分别用softmax和sigmoid作为网络输出层的激活函数,形成多元分类模型和二元分类模型,并使用ROC曲线和F1得分等对模型进行评估,取得了良好的效果[1]。Enrico Bocchi等人利用知识图谱与网络攻击行为相结合,形成网络连通图,并利用无监督学习对某个典型的恶意网络行为进行聚类,形成标签数据集。最后利用树模型对知识图谱和网络行为挖掘的特征进行分类,实现恶意域名检测的目的[2]。张洋,柳厅文等人分析了主动分析和被动分析两种模式,采用了机器学习的手段,从词法特征和网络属性特征两个方面,提出了一种基于多元属性的20个特征恶意域名检测方式,词法方面有域名的长度、数字的个数、大写字母个数、数字域名占比。网络属性方面有TTL平均值、A记录个数、AS个数、NS个数、NS分散度等,并采用准确率、召回率、F1值对随机森林分类器对1662个域名的分类效果进行评估[3]。牛晋平等人通过对僵尸网络的综述性研究,通过聚类方法对其查询、攻击的行为特征进行分析,这种方法的好处是突破了基于域名文本特征检测的瓶颈[4]。
2 完善样本
目前,基于机器学习的被动分析检测模式成为了DGA检测的主流。大多数研究者使用的特征提取方式和机器学习方法在各自数据集上能够取得较高的评分,但是训练样本往往是不充分的。具體表现在训练样本的DGA家族覆盖率较低,总量也较少,这样使得训练样本比较“单纯”,模型也很容易取得较高的评分。事实上,每个DGA生成算法的代码编写习惯不同,生成的字符组成一般也是在给定的一些固定的随机种子字符上下波动。当训练样本中DGA家族数量较少或样本分布高度集中的时候,机器学习方法很容易学习到某种潜在的规律,并取得非常低的经验风险。然而,把这个模型应用到陌生的DGA域名上时,其召回率就会明显缩水,这也说明其结构风险较高。
2.1 补充白样本
Alexa每天在网上搜集的信息超过1000GB,给出多达几十亿的网址链接,而且为其中的每一个网站进行排名,是当前拥有URL数量最庞大、排名信息发布最详尽的网站。本文使用Alexa全球排名前100万的网站域名作为训练白样本的数据质量是很合适的,但是在一些特殊的应用领域,常用域名可能并没有体现在这份数据当中。因此对于如何补充训练白样本,考虑用三种方式来实现。
(1)添加行业公司及行业域名:将公司自身各子系统域名,以及与公司业务相关的外部域名加入训练集白样本。
(2)从站长之家爬取国内TOP5.7万的域名作为白样本。
(3)加入牛津词典中的英文词汇作为训练白样本。
2.2 补充黑样本
在实验中发现,循环神经网络具备十分强大的记忆和模拟能力。然而,即使模型对训练集和测试集都达到了99.7%的准确度,但是当把这个模型应用到一个新的DGA算法生成的域名中测试,模型的召回率却只有70%左右。这或许不是绝对的坏事,因为过高的召回率可能也意味着模型同样具有较高的误判率。理论上来说,由于每个人代码的编写习惯不同,通过使用不同的硬编码、随机种子和加密算法将会生成完全不同“风格”的DGA域名。DGA域名的样本空间几乎是无限大的,但也不必过于沮丧,它们之间也必然存在着隐晦的潜在联系,只要训练样本愈加充分,机器学习模型也就会具有更加强壮。为了实现上述目的,研究者搜罗了Github上公开的40个僵尸网络家族的DGA域名生成算法。其中360netlab重叠且数量较少的DGA家族,利用DGA生成算法将该家族训练样本补充至20000,同时针对360netlab中不存在的DGA域名家族,生成20000新样本用于模型的训练。
2.3 样本调整
不同的DGA算法会有一定概率生成相同DGA域名,一个域名在黑样本中可能会出现多次。在实际使用当中可以根据从正负样本均衡的情况和样本的重要性综合考虑是否去重。
对于黑白样本中都有的域名,按照其重要性来决定其标签。如某个域名在某个DGA家族出现过一次,同时在公司及相关行业域名白名单中也存在,将该域名定义为白样本;若是与英文词汇中某个词汇重叠,将其视为黑样本来看待。同时,将DGA域名家族添加到73个,丰富黑样本的同时也缓解了样本不均衡的问题,最终调整后的样本分布如表1所示。
3 特征工程
从文本分析的角度去区分正常域名和异常域名,有两个方向:一是,提取组成域名每个字母的统计指标,然后投入一个分类器去训练;二是,将一个字符或相邻的几个字符看作一个状态,把整个组成域名的字符组合当作一个序列去训练出一个状态转换模型,从而计算出一个是否为DGA域名的概率评分。研究者希望训练一个尽可能通用的DGA检测模型,因此在提取特征的时候也应该充分考虑特征的通用型,即对大多数DGA域名具备区分能力。
3.1 统计特征提取
人眼去区分正常域名和DGA域名时,看起来比较“顺眼”会觉的更“像”是正常域名 , 如 google.com, youtube.com。正常人在取域名的时候,通常会选取比较贴合业务的几个顺口的单词组合,具备好读、好记、有一定含义这些特点。而DGA域名由随机种子结合一定的算法生成,组成主机名的字符串大多不可读,顺序混乱且随机性较强,与正常域名存在一定差异。
3.1.1 域名长度
大多数正常域名都不会太长,太长的话也不符合好记这个条件。在随机种子长度不变的情况下,大多数DGA算法生成的域名长度是固定的,由于不同的DGA生成算法,不同的攻击者所设置的随机种子长度不同,生成的DGA域名长度也不同。这里将域名长度表示为|d|。
3.1.2 域名元辅音字母占比
出于“好读”的目的,正常的域名元音字母的比例会比较高,辅音字母的比例比较低;而随机生成的DGA域名则相反。
(1)元音字母占比:
其中|d|为域名字符长度,Count(d,Vowel),为元音字母个数。
(2)辅音字母占比
其中Count(d,Consonant)为辅音字母个数。
3.1.3 域名字符去重后数量占比
去重后的字母个数与域名长度的比例,从某种程度上反映了域名字符组成的统计特征[5]。
其中|Distinct(d)|为域名字符去重后的长度。
3.2 域名N-gram切割后的衍生特征
N-Gram方法常用语自然语言处理,常用于计算基于N-Gram模型定义的字符串距离,利用N-Gram模型评估语句是否合理等。N-Gram中N的取值为{1,2,3,4,5...},利用N-Gram对域名进行切割,然后统计切割后的字符组合分别在黑白域名集合中出现的概率。域名忽略字母的大小写,并将数字全部泛化为0后,由{.,_,-,0,a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z}共30个有效字符组成,这时可能的字符组合的维度为30n。当n取值过高时,特征空间的维度爆炸式增长,对LSTM、HMM这类需要计算状态转换矩阵的算法来说,则需要海量的样本去消化这些特征,也就是说n的取值越高模型过拟合的风险也就越高,越需要大量的訓练样本。由于正常域名的长度一般也不会很长,因此n取值为2或3时比较适宜。以google为例,2-Gram后的字符组合集合为Set(google)={go,oo,og,gl,le}。
抽象成数学语言,有如下表示:
(1)d:域名;
(2)D:域名集合;
(3)Set(d):域名 N-Gram 切割后的字符集合;
(4)Positive:正常域名集合;
(5)Negative:DGA域名集合;
(6)Total:全体域名集合;
(7)Count(d,D):N-Gram切割后的字符集合Set(d)元素在域名集合D中出现的次数和;
(8)Statistic(d,D):域名集合D中包含Set(d)元素的域名个数和。
根据上述表达,提取N-Gram衍生特征图表示:
(1)域名N-Gram DGA频率可表示为公式:
(2)域名N-Gram逆向文本频率(IDF):
(3)域名N-Gram DGA词性比例:
(4)域名N-Gram正常词性比例:
3.3 平均HMM系数
将组成域名的每个字符转换成对应的ASCII码作为该字符的状态表示,如google等,转换成形如[103,111,111,103,108,101],长度为6的向量表达。然后使用默认参数的GaussianHMM模型,用白找黑的思想训练正样本,并将训练后的GaussianHMM模型应用于待测域名,计算出一个HMM系数,然后利用准确率、召回率和F1得分分别对训练集及测试集进行评估。这里用到了10万个白样本,设置阈值后改模型表现如表2所示。
可见HMM作为区分DGA域名的一个变量,具备一定的区分能力,但进一步提升效果还需要增加变量。
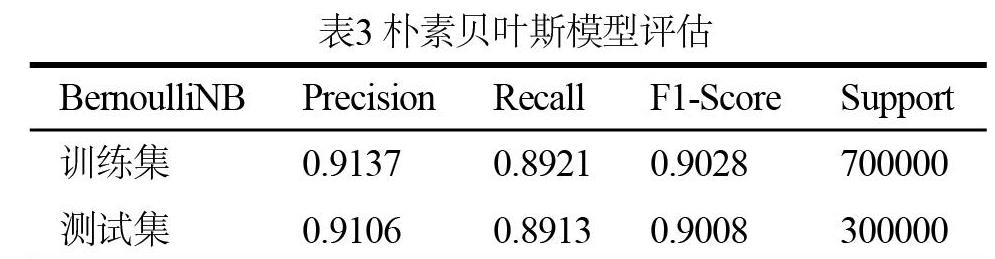
3.4 朴素贝叶斯系数
常用的朴素贝叶斯(Naive Bayesian)算法有三种,分别为GaussianNB、MultinomialNB和BernoulliNB。域名进行2-Gram切割后的特征向量维度为900,对这900个不同的字符组合建立词袋模型,利用词袋模型将每个域名转换成特征向量。由于面对的是稀疏的二元离散特征向量,所以采用BernoulliNB算法,它假设特征的先验概率为二元伯努利分布,如下式:
其中Ck为Y的类别,这里为0或1,分别代表正常域名和DGA域名。同样,xjl也取值为0和1。
本文使用Scikit-learn中的BernoulliNB算法,对随机抽取的100万正负样本进行训练,然后分别利用准确率、召回率和F1得分对训练集及测试集进行评估,如表3所示。
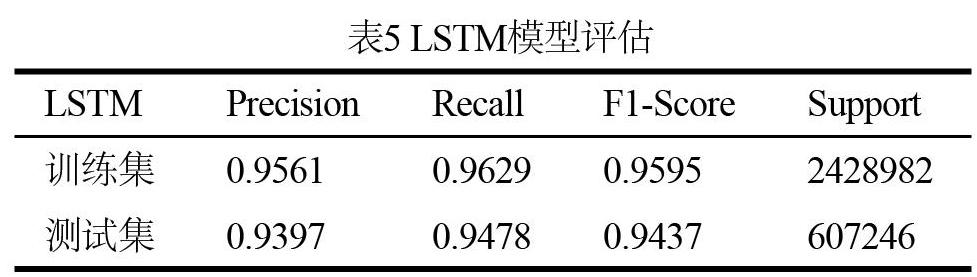
3.5 LSTM系数
长短期记忆网络(Long Short-Term Memory,LSTM)是一种时间循环神经网络,它解决了简单神经网络(RNN)存在的长序列训练过程中的梯度消失和梯度爆炸的问题。相比于简单的RNN,LSTM能够再更长的序列中有更好的表现。LSTM非常适合大规模数据的训练,具备异常强大的模拟能力,理论上能以任意精度拟合任意复杂度的函数,充分学习到域名序列中上下文之间的潜在关联。这里使用了Keras深度学习模型包对2-Gram后的构建循环神经网络,网络结构如表4所示。
随着样本的丰富和多元化,仅用一个全链接层的拟合效果并不是非常理想。因此,本文在在LSTM层和最后的全链接层中间添加了一个32节点的全链接层,同时加入两个Dropout层进一步降低网络结构风险。最后以Sigmoid函数作为输出层的激活函数,将全部3036228个样本投入LSTM模型,并利用准确率、召回率和F1得分分别对训练集及测试集进行评估,如表5所示。
4 集成学习方法
为了模型能有更好的鲁棒性,本文采用集成学习方法,基于训练样本、特征提取和模型结构三个方面的优化,提出了一种具有高鲁棒性的恶意域名检测方法,如图2所示。
4.1 关于模型风险评估
很多时候为了地追求模型评分的好看而误入歧途,忽略了模型的鲁棒性,事实上,尤其是当训练样本较少时,模型是非常容易过拟合的。关于模型的选择,监督学习有两种策略,分别是最小化经验风险和最小化结构风险。
(1)最小化经验风险
这里L(x)为经验风险函数,Θ为模型的参数;
当样本量较少时,经验风险最小化模型极易发生过拟合,尤其是树家族模型和模拟能力非常强大的神经网络模型。
(2)最小化结构风险
其中λ表示惩罚系数,J(f)表示模型结构风险函数。于是,选择最佳模型就成了如何平衡经验风险和结构风险的问题。
4.2 实验结果
结合上节的特征工程提取的八个统计特征和三个模型系数特征分别训练随机森林、SVM、逻辑回归二元分类器,形成集成方法。实验结果表明,集成后的方法相比单个HMM、BernoulliNB和LSTM模型具有更高的准确率和召回率,同时泛化能力和通用型也得到了提升,如表6所示。
5 结束语
DGA域名样本没有绝对的黑和白,多数人看起来毫无逻辑的域名也有可能被注册为正常的域名使用。同样的,实践证明DGA生成算法也有一定概率生成Aleax网站TOP排名完全相同的域名。因此一味追求模型的经验风险最小并非最佳的解决方案。与国内外学者针对DGA域名检测动辄0.999的准确率相比,本文覆盖更多的DGA域名家族和域名白样本,融合多个模型预测系数再加上多元统计特征和N-Gram衍生特征,利用惩罚系数令每个特征对最终的结果都作出一部分贡献,从而达到降低模型结构风险的目的。因此,针对国内企业生产场景更具备普遍适用性。
参考文献
[1] Woodbridge J , Anderson H S , Ahuja A , et al. Predicting Domain Generation Algorithms with Long Short-Term Memory Networks[J]. 2016.
[2] Bocchi E , Grimaudo L , Mellia M , et al. MAGMA network behavior classifier for malware traffic[J]. Computer Networks, 2016:S1389128616300949.
[3] 张洋,柳厅文,沙泓州,等.基于多元属性特征的恶意域名检测[J].计算机应用,2016, 36(4):941-944.
[4] 牛晋平,袁林.僵尸网络及检测技术探索[J].软件工程, 2016,19(4):16-18.
[5] 刘焱.Web安全之机器学习入门[M].北京:机械工业出版社, 2017.126
[6] 张永斌,陆寅,张艳宁.基于组行为特征的恶意域名检测[J].计算机科学,2012,40(8).
[7] 黄凯,傅建明,黄坚伟,李鹏伟.一种基于字符及解析特征的恶意域名检测方法[J].计算机仿真,2018,35(03):287-292.
[8] 蔡冰,马旸,王林汝.一种恶意域名检测技术的研究与实现[J].江蘇通信,2015, 31(4):59-62.
[9] 臧小东,龚俭,胡晓艳.基于AGD的恶意域名检测[J].通信学报, 2018,v.39;No.373(7):19-29.
[10] Mowbray M, Hagen J. Finding Domain-Generation Algorithms by Looking at Length Distribution[C]// IEEE International Symposium on Software Reliability Engineering Workshops. 2014.
[11] Abbink J . Popularity-based Detection of Domain Generation Algorithms: Or: How to detect botnets?[C]// International Conference on Availability. ACM, 2017.
[12] 杨佳宁,陈柯宇,曹凯,郭娴.工业互联网安全态势感知核心技术分析[J].网络空间安全,2019,10(04):61-66.
作者简介:
刘浩杰(1992-),男,汉族,安徽阜阳人,南京大学,学士,苏宁科技集团,算法研究员;主要研究方向和关注领域:网络安全、渗透测试、人工智能与机器学习。
皇甫道一(1990-),男,汉族,江苏淮安人,南京邮电大学,学士,苏宁科技集团高级工程师;主要研究方向和关注领域:应用安全、安全AI、企业安全建设。
李岩(1994-),男,汉族,河南南阳人,江苏科技大学,硕士,苏宁科技集团,工程师;主要研究方向和关注领域:机器学习、数据挖掘、Web应用安全。
王涛(1990-),男,汉族,河南驻马店人,合肥工业大学,学士,苏宁科技集团,高级技术经理;主要研究方向和关注领域:Web安全、安全管理。
