Apriori关联算法的企业创业期金融数据采集方法研究
2019-03-16赖红清
赖红清
(佛山职业技术学院工商管理学院,广东 佛山 528200)
0 引言
依据伊查克·爱迪斯提出的企业发展生命周期理论,可将企业的发展轨迹划分为发展、成长、成熟、衰退4个阶段。而企业创业期即发展与成长阶段,该时期的发展关系到企业自身的可持续发展。企业金融数据属于低频金融数据的一种,在企业金融量化管理水平不断提升的过程中,需要对企业创业期金融数据进行挖掘和特征分析,建立企业创业期金融数据的采集模型,实现企业创业期金融管理[1]。研究企业创业期金融数据的挖掘模型,在提升企业创业期金融信息的准确管理和调度方面具有重要意义,相关的企业创业期金融数据处理研究受到人们的极大关注。文献[2]提出了基于物联网的金融数据动态安全存管系统,该系统感知层采集和融合金融数据,并对数据进行安全保护。存储层采用云安全存储服务体系从感知层获取大量金融数据,并通过约束性软件函数实现金融动态云数据的合理调度。该存管系统可进行稳定的大量金融数据同步上传及在线查看,实现了金融数据的安全管理,但该方法数据采集的融合性较差。文献[3]提出了基于Python的互联网金融数据采集方法。通过确定搜索策略,获取HTML页面信息,再解析HTML文档,自动提取商品信息存储等数据相关信息,分析采集结果,完成金融数据的采集。该方法灵活多样,可采用的开源库较多,但数据采集精确度较低。
针对上述方法存在的问题,提出基于Apriori关联算法的企业创业期金融数据采集方法。构建企业创业期金融数据的统计信息模型,结合非线性比特序列重组方法进行企业创业期金融数据的离散融合处理,对数据库中的企业创业期金融数据进行Apriori关联规则挖掘。最后进行仿真实验分析,得出有效性结论。
1 企业创业期金融数据高阶特征量重构
1.1 金融数据统计序列分析
为了实现企业创业期金融数据采集,首先构建企业创业期金融数据的统计分析模型,采用关联规则挖掘方法,进行企业创业期金融数据采集过程中的统计时间序列分析和特征提取[3],采用多元回归分析方法提取企业创业期金融数据的相关性统计特征量,进行企业创业期金融数据重建。假设(F,Q)为企业创业期金融数据的统计特征量,对企业创业期金融数据中的冗余特征进行去重处理,采用模糊信息聚类方法,进行企业创业期金融信息融合处理,构建企业创业期金融数据调度模型,输出为:
(1)
(2)
采用多元信息融合方法,进行企业创业期金融数据调度,构建企业创业期金融数据挖掘模型,以根据统计序列的状态特征进行模糊信息识别[4],设金融数据统计分析的时间窗口函数为Δw=wmax-wmin,则:
(3)
当d1=d2=…=dp时,企业创业期金融数据状态空间重组的窗口函数Etotal取最小值。当Etotal′=0时,Etotal有最小值,此时,采用自相关融合方法,进行企业创业期金融数据的状态空间融合,提取关联特征量,得到企业创业期金融数据的模糊隶属度函数为:
(4)
式中:P为关联维特征;x(t)为原企业创业期金融数据特征分布长度;τ为空间采样时间尺度。在高维特征空间中,采用区域信息融合方法,得到企业创业期金融数据的频谱Z服从参数为βd的高斯分布,其中:
βd=(MPDist-d+1)/MPDist,d∈[2,MPDist],
(5)
式中adj(a,c)表示重构的企业创业期金融数据信息流的特征向量,对企业创业期金融数据进行本体结构重组,在虚拟数据库中进行企业创业期金融数据的二元结构重组[5],采用稀疏点表达方法进行企业创业期金融数据的相似度特征分析,得到虚拟数据库企业创业期金融数据的映射关系表示为A→B,B→C,推出回归分析模型为
MSDa→b=1-
(6)
提取企业创业期金融数据的谱特征量,采用向量量化编码方法进行企业创业期金融数据结构重组,得到数据的平均互信息特征量,在企业创业期金融数据分布的数据空间内,得到企业创业期金融数据的属性分布的互信息为
I(Q,S)=H(Q)-H(Q|S),
(7)
其中
(8)
结合特征提取技术进行企业创业期金融数据的深度融合处理,实现企业创业期金融数据统计序列分析[6]。
1.2 数据的高阶特征量重构
对统计得到的企业创业期金融数据进行高阶特征量重构,建立企业创业期金融数据的模糊关联规则挖掘模型[7],企业创业期金融数据的特征评价概念集表达式为:
(9)
挖掘企业创业期金融数据的属性关联规则特征量:
(10)
(11)
采用优先级调度方法进行企业创业期金融数据的特征融合,构建企业创业期金融数据分布的标量时间序列为x(t),t=0,1,…,n-1,给定企业创业期金融数据信息流的二维统计特征分布模型为x1,x2,…,xn∈Cm(m维复数空间),企业创业期金融数据的散乱点集为Pi=(pi1,pi2,…,piD),其中:
j∈Ni(k),Ni(k)={‖xj(k)-xi(k)‖ (12) 在企业创业期金融数据分布的最小共享资源分配区域内,调整虚拟数据库企业创业期金融数据的关联规则项,构建分布式企业创业期金融数据的模糊信息融合模型: (13) 企业创业期金融数据的边值收敛条件满足如式(14)~(15)边界函数为: (14) (15) 采用分段融合调度方法进行企业创业期金融数据采样后的信息融合处理,实现数据的高阶特征量重构[8]。 在上述对企业创业期金融数据进行高阶特征量重构的基础上,进行企业创业期金融数据采集。本文提出基于Apriori关联算法的企业创业期金融数据采集方法。企业创业期金融数据源整合模型为 X=[s1,s2,…,sK]= (16) 式中:K=N-(m-1)τ为企业创业期金融数据源整合的嵌入维数;τ为时延;m为特征采样的维数;si=(xi,xi+τ,…,xi+(m-1)τ)T是空间分布特征量,采用量化回归分析方法,进行企业创业期金融数据的定量递归分析,企业创业期金融数据的量化学习函数为 (17) 结合随机性的特征重构方法,进行企业创业期金融数据信息挖掘[9],得到输出负载量为 Computition(nj)=(Eelec+EDF)lδ+ETx(l,dj)=(Eelec+EDF)lδ+lEelec+lεfsdj2=[(Eelec+EDF)δ+Eelec+εfsdj2]l。 (18) 采用Apriori算法进行企业创业期金融数据融合,金融数据的综合调度输出为 (19) (20) 提取企业创业期金融数据融合特征值,在邻域空间(t,f)内,得到企业创业期金融数据融合的统计指数集为 (21) (22) 根据上述分析,结合自适应的反馈调节方法进行企业创业期金融数据空间的融合统计特征重建,求解企业创业期金融数据的融合特征W的最优解,即: (23) 对企业创业期金融数据采用相空间重构技术进行Apriori关联规则挖掘,根据Apriori关联规则挖掘结果,进行数据融合,为数据采集做铺垫。 基于上述金融数据挖掘过程,结合非线性比特序列重组方法进行企业创业期金融数据的融合处理,对数据库中的企业创业期金融数据进行Apriori关联规则采集,Apriori关联规则为 (24) 在重构的企业创业期金融数据空间中,采用主成分特征采样方法[10],进行企业创业期金融数据的关联规则集调度,得到采样模型为 Dopt=λXV-1WT(WV-1WT)-1。 (25) (26) (27) (28) 在企业创业期金融数据的表面分布结构模型中,采用稀疏点表达方法进行企业创业期金融数据的相似度特征分析,对企业创业期金融数据融合结果进行自适应均衡控制,得到数据的融合特征分布为 CT′(f)X(f)ej2πfτ0。 (29) (30) (31) (32) 计算企业创业期金融数据的测度特征量为: (33) 根据企业创业期金融数据的主成分特征,获取企业创业期金融数据的特征值,得到数据采集迭代方程为 (34) 式中μMCMA代表初始特征采样率。 基于Apriori关联规则对企业创业期金融数据进行挖掘与融合,再根据数据融合的统计序列分布完成数据采集。 为了测试本文方法在实现企业创业期金融数据采集的应用性能,进行仿真实验。实验采用Matlab进行仿真设计,企业创业期金融数据统计的软件平台为Visual Studio 2010和SPSS17.0。企业创业期金融数据原始数据的采样率为16 kps/s,数据采样的离散点为2 000,企业创业期金融分布的训练点数为120,特征提取的训练次数为15,Apriori关联系数设定为12.6,特征空间的重构延迟为8,嵌入维数为4,根据上述仿真环境和参数设定,进行企业创业期金融数据采集,得到数据的统计序列分布时域波形如图1所示。 图1 企业创业期金融数据统计序列分布 数据融合是指将多信息源的数据进行相关组合,进而可以得到更为精确的数据估计,从而可以对重要数据进行完整的评价处理。数据融合是数据采集的前提,数据融合的程度直接影响数据采集的效果。为了验证研究方法数据融合的效果,基于上述实验环境,对企业创业期金融数据进行融合分析。融合度越高,说明数据融合效果越好。得到数据融合结果如图2所示。 图2 数据融合结果 分析图2可知,在数据融合时间内,对0.95~1.05 TB的数据量进行融合,随着数据量的增加,运用本研究方法进行企业创业期金融数据采集的融合度越趋近于100%,其融合效果越好。 为了进一步验证本研究方法数据采集精度,基于上述实验环境,将本研究方法作为实验组,将文献[5]、文献[6]方法作为对照组,测试在迭代次数100内数据采集准确率。得到对比结果如图3所示。 图3 数据采集精度对比 分析图3得知,3种方法在100迭代次数时采集准确率达到或接近100%;但在0~90迭代次数时,文献[5]方法的采集准确率为56%~93%,文献[6]方法的采集准确率为65%~97%,均低于本研究方法的采集准确率83%~100%,说明采用本研究方法进行企业创业期金融数据采集的精度高,准确性较好,为企业创业期金融数据采集提供了有利的科学依据。 为实现企业创业期金融管理,针对传统金融数据采集方法缺少对数据的定量规划分析,导致存在融合性差、精度低等问题,提出一种新的基于Apriori关联算法的企业创业期金融数据采集方法。采用量化回归分析方法,进行企业创业期金融数据的定量递归分析,结合非线性比特序列重组方法进行企业创业期金融数据的离散融合处理,对数据库中的企业创业期金融数据进行Apriori关联规则挖掘。实验结果证明,利用此次研究方法进行企业创业期金融数据采集的融合性好、精度高,适用于实际企业创业期金融的数据采集,有助于帮助企业在创业期找到较优的方法来保持企业的发展能力。2 企业创业期金融数据采集方法
2.1 Apriori关联规则挖掘与融合
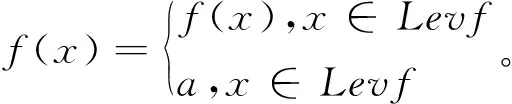
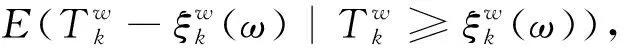
2.2 企业创业期金融数据采集
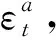
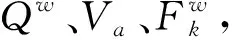
3 仿真实验与结果分析


4 结语
