基于SVM的网络定位算法的仿真设计
2019-03-16冯娜
冯 娜
(潍坊工程职业学院,山东 潍坊 262500)
随着信息技术的飞速发展,使得低成本、低功耗、大规模网络应用和更微小的传感器节点变得简单而高效[1]。无线传感网络作为如今最新型的信息采集终端,其检测[2]、跟踪[3]、反馈[4]等功能直接关系到传感器网络的精准度和实效性。尤其是无线传感器网络的定位技术最为关键[5]。目前,采用的定位方法主要包括三角测量法、极大估计法、最小二乘方法以及支持向量机法(SVM)[6]。其中SVM具有体积小、低能耗、费用低与具有自主独立功能等特点,一直成为无线传感领域的研究热点[7]。然而,现在基于SVM的定位技术存在着种种缺陷,例如无法实现多种类别的准确划分,无法实现全局的最优化[8],特别是在使用SVM定位的过程中,一般是采用测距定位与非测距定位的算法进行定位节点的确定,在内核函数的计算上无法降低算法的复杂度[9]。本文采用内核方法针对传感器网络的粗粒度的定位问题,解决了统计学习理论的内核方法模式的识别问题,并用“点对点”定位算法评估模拟传感器网络。为基于SVM网络学习方法的定位与跟踪技术研究提供具有实际应用意义的参考。
1 SVM的相关理论
1.1 SVM的概念

图1 SVM示意图
1.2 最优分类面
SVM的分类主要通过线性可分的具体情况进行划分,尤其是最优分类面之间关系到各个维度中空间节点所涵盖的意义。如图2所示,对于一维空间中的点,二维空间中的直线,三维空间中的平面,以及高维空间中的超平面,图中两类样本由实心点和空心点代表,它们之间分类超平面为H,H1、H2分别是过各类中离分类面最近的样本且平行于分类面的超平面,它们之间的距离叫做分类间隔(margin)。

图2 最优分类面示意图
然而,最优的分类面需要满足两个必备的特征:其一是能够将两种不同的类别精准分开;其二是判定分类的特征值需要足够的大,即向量的分类间隔应该达到最大值。这样才能实现不同类别之间准确分开,满足训练错误率达到0%。
2 基于SVM定位算法的设计
2.1 使用核方法分类
利用支持向量机把传感器的定位问题变成分类问题。设X1,…,Xm表示一组m个传感器,并让xi表示传感器在R2中的位置。假设第一个n传感器的位置是已知的,即X1=x1,…,Xn=xn,其中n (1) 对于一个优化的选择系数ai,有大量的内核函数满足的SVM算法所需的半正定的值。实例包括高斯核函数: K(x,x′)=exp-(‖x-x′‖2/σ), (2) 以及多项式核函数: K(x,x′)=(γ+‖x-x′‖-σ)。 (3) 参数σ和γ。这两个内核函数衰减相对距离为‖x-x′‖,即有最理想化的信号强度模型共享的属性,尤其是无线电信号模型具有类似于一个多项式核的形式。由此可知,使用具有高斯核形式的模型,能够反映核方法和传感器网络之间的基本连接。 假定有大量传感器被均匀地部署在一个地理区域。输入一组m传感器,记X1,…,Xm。对于每一个i,xi表示节点在R2的位置。假设第一个n的位置是已知的,X1=x1,…,Xn=xn,其中n 针对于Xn+1,…,Xm,目标是获得一个粗略的位置估计。在给定的一个任意构造的区域C⊆R2里,询问Xi是否在C区域里,i=n+1,…,m,这可以容易地归结成分类问题。事实上,由于已知传感器X1,…,Xn的位置,所以可以知道其他传感器是否在C区域。对于任何传感器s(xi,xj),基于判别函数f(xj)知道他是否在区域内。 (4) 其中f(xj)的值是已知的,因为内核的值K(xi,xj)是已知的,尽管不知道xi本身的位置。接下来,转向核矩阵K=(k(xi,xj))1≤i,j≤m的定义,设想基于信号矩阵内核的层次结构。这种层次结构的例子如下: 1)简单地定义K(xi,xj)=s(xi,xj),称之为一线的内核。如果信号矩阵S=(s(xi,xj))1≤i,j≤m是一个对称的半正定矩阵,那么这种做法是正确的,虽然它不可能产生;如果S不是对称半正定的,则可能是近似值为(S+ST)/2+δI。该矩阵是对称的,并且是半正定为足够大,δ>0(特别是δ绝对大,比(S+ST)/2的负的特征值大得多)。 2)定义K=STS称为二线线性核。K永远是对称半正定。该内核可以被解释为是由形式的矢量跨越一个特征空间H中的内积: φ(x)=((x,x1),(x,x2),…,(x,xm)), (5) 可以定义: (6) 直观地说,所用的传感器读数的类似载体是附近的空间中的。 3)高斯核函数。这将产生一个对称半正定矩阵,称为第三层内核。具体来说,第三层高斯核有如式(7)形式,对于一个参数σ: (7) 在Matlab软件上设定网格为10×10平方单位。基传感器均匀地分布在网格状结构中,共有n个这样的传感器。我们想知道的是传感器位置xi在区域C中有没有,i=1,…,n。定义一个信号模型:每个传感器的位置x被假定为被位于x′的信号值的下一个衰落信道模型中的传感器接收: 其中N(0,τ)表示标准差τ独立产生的正态随机变量。该信号模型是高斯核的随机版本。同时,设定一个信号强度模型是多项式核的随机版本: s(x,x′)=(‖x-x′‖)-σ+N(0,τ)。 其结果为多项式内核,类似于高斯核,上述两个模型都是用来产生信号矩阵S的。其次,定义一个区域C。C包含所有位置x并满足以下方程: (x-v)TH1(x-v)≤R, 其中v=[5 5]T,H1=[1 0:0 1],以及R=2。半径R是用来描述C的大小的为每个模拟设置了支持向量机的不同相约束参数。一旦判别函数f已知,可以得出区域C的边界。 框约束参数=5 000 如图3所示,比较框约束的参数5 000、5和0.005发现:C是惩罚系数,C越大,边界越不光滑,但是对传感器的参与度要求不高,一些无效的传感器对边界的确定没有太大的影响;C越小,边界越光滑,对传感器的参与度要求越高,每一个传感器对边界的确定影响都很大。 本文针对定位算法容易受节点测距误差影响,在不同的环境下适应性不足,在点对点无线传感器网络定位的问题中,利用核方法在分布式检测与估计,提出了非参数学习算法粗粒度定位的点对点无线传感器网络。利用统计分类方法,测得自然坐标系中部署的信号强度。对于定位问题,避免了测距计算、运算要求以及很难准确地校准信号模型的问题。本章对算法的正则化参数、核函数参数、定位区域的网格划分宽度,经过Matlab的仿真实验取得了较好的定位效果,验证了算法的正确性和高效性。
2.2 点对点无线传感器网络中的定位方法
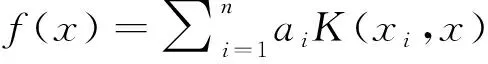
3 SVM定位算法的仿真评价

4 结语
