深度PCA子空间极限学习机图像检索算法
2019-03-13李昆仑李尚然巩春景
李昆仑,王 琳,李尚然,巩春景
(河北大学 电子信息工程学院,河北 保定 071000)
1 引 言
基于内容的图像检索[1](content-based image retrieval,CBIR)指在给定查询图像的前提下,无需人工注释图像,通过提取图像的底层特征(例如纹理、颜色、形状等),在图像数据库中检索出与查询图像相近的图像[2].随着深度学习(Deep Learning)[3]的日趋成熟,很多学者将深度学习应用于人脸识别、目标检测、图像分类等领域[4-6].深度学习,即深度神经网络(Deep Neural Network,DNN)由Hinton等提出,深度神经网络通过多层神经网络来排列底层的原始数据特征,并抽象出原始数据的高级特征.常见的深度学习模型有深度自编码器(Deep Autoencoder,DAE)、深度置信网络(Deep Benefit Neural Networks,DBN)以及深度卷积神经网络(Convolutional Neural Networks,CNN)[7-9]等.自动编码器(Auto Encoder,AE)是一种无监督的用于数据降维和特征提取的神经网络模型,旨在尽可能地重构原始输入数据,以便从大数据中有效提取隐藏特征[10].为了改善其性能,Bengio等在自动编码机的基础上提出堆栈自动编码器(Stacked Autoencoder,SAE),堆栈自动编码器是通过多层稀疏自编码器获得比自动编码器更强的特征表达能力.Krizhevsky和Hinton提出用深度自编码器哈希进行图像检索,文章将图像直接作为输入,训练深度自编码器哈希,然后对图像进行二进制编码[11].
极限学习机(Extreme Learning Machine,ELM)是Huang G.B.等于2004年提出的作为一种训练单隐藏层前馈神经网络(Single-hidden Layer Feed forward Network,SLFN)学习方法,其分类性能好、训练速度快且具有良好的泛化性能[12].Kasun等提出了多层极限学习机(Multilayer Extreme Learning Machine,MLELM)网络模型[13].Lekamalage等提出了一种基于极限学习机自编码器的聚类算法(Extreme Learning Machine Auto Encoder Clustering,ELM-AEC),该方法利用极限学习机自编码器(ELM based Auto Encoder,ELM-AE)[14]进行特征映射,并使用矩阵分解和K均值算法对聚类中心进行初始化[15].
尽管深度学习模型具有强大的特征抽象能力,但它需要大量数据集和较高的硬件水平,网络参数多,收敛速度慢,因此研究人员将目光锁定在寻找基于CNN的简化深度学习框架中.在此背景下人们开始关注“子空间深度化”.2015年,Chan等提出PCANet模型,借助2DPCA[16]映射单元,在DPCA基础上进行扩充,辅以二值化哈希编码和直方图分块,将子空间学习[17]引入到深度学习中,为卷积神经网络中卷积核的研究提供新的思路[18].与卷积神经网络相比,可以无监督地获取分层特征,避免由于迭代和最优解导致的高计算复杂度.在人脸识别、物体识别和手写数字识别中,识别率超过95%,但单层或双层的PCA滤波器无法获得像CNN模型中抽象的高层特征,容易受训练图像影响,而深度极限学习机可以弥补这一缺陷.
图像检索最主要的问题之一就是如何给出有效的图像描述,特征的提取和表达一直受到人们广泛关注.综上所述,为实现更加准确高效的图像检索,本文提出了一种深度PCA子空间极限学习机图像检索算法.将深度PCA子空间作为基本学习单元并有效的提取其底层特征,然后输入到深度极限学习机中以得到高层次的特征.实现了对底层特征的逐层转换,在特征降维的同时得到更具代表性的特征表示.最后利用哈希编码将高层特征映射到低维汉明空间中,比较查询目标图像编码和图像数据库中哈希编码的汉明距离,判断两幅图像是否相似,从而可实现基于深度学习的图像检索.这些措施,能够建立从底层信号到高层语义的映射关系,提取图像特征的深层表示和数据内部的隐含信息,获得较好的图像特征表达,避免了大量的迭代过程,提高了算法的分类精度和泛化性能,与CNN等神经网络相比,训练时间明显缩短.
2 深度子空间模型
深度子空间模型是基于深度学习理论,将经典子空间映射结果作为图像特征,通过深度网络提取图像的深层抽象特征.PCANet使用最基本的主成分分析来模拟卷积神经网络,卷积滤波器层采用PCA滤波器;非线性处理层使用二进制哈希算法;重采样层采用二进制哈希编码的分块直方图.一个完整的PCANet包括3个部分,结构如图1所示.

图1 PCANet原理框图Fig.1 Principle of PCANet
1)输入层

(1)
(2)
此时输入的图片库可以表示为向量集形式:
(3)
2)映射层
通过输入图像矩阵X学习PCA滤波器.V是标准正交约束矩阵,L1是第一层映射层滤波器个数,对应PCA滤波器为:
(4)
s.t.VTV=IL1
(5)
(6)
其中ql(XXT)代表XXT的第l主特征向量.对图像进行边缘延拓操作来保证卷积后能重构原图像,得到第一层映射层的图像描述:
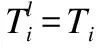
(7)
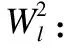
(8)
将第二层输出进行卷积映射,得到深度子空间主成分特征:
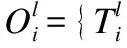
(9)
3)输出层
对提取到的特征进行非线性表示,通过二值化处理和哈希编码来加大各特征差异:
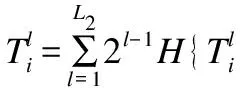
(10)
其中H(·)是一个单位阶跃函数,目的是将特征值调整为正数.然后对获得的特征图进行直方图块处理,以获得最终的特征输出:
(11)
3 深度PCA子空间极限学习机算法
3.1 极限学习机自编码器
极限学习机结构简单,学习效率高,无需迭代微调,不易陷入局部最优,可以随机赋值输入权重和偏移量以得到相应的输出权重,具有极强的非线性逼近能力.自动编码器是深度学习中常用的人工神经网络模型,根据编码生成的输出数据近似表达输入数据来最小化重构误差.极限学习机自编码器(ELM based Auto Encoder,ELM-AE)是一种输入等于输出的特殊 ELM,它可以加快AE(auto encoder)的训练过程,隐藏层的编码矢量是输入数据的一种特征表示.
ELM-AE由三层组成:输入层、隐藏层和输出层.如图2所示.设置输入层和输出层的节点数为D,隐藏层的节点数为L,ELM-AE可以根据代表输入信号的隐藏层输出分为三种表示方法:压缩表示,等维表示和稀疏表示.对于N个训练样本xi,i=1,…Nxi∈RL,ELM-AE的隐藏层输出可以表示为式(12),隐藏层输出和输出神经元输出数值关系可以表示为式(13).
h=g(ax+b)
(12)
(13)
其中:a=[a1,a2,…aL]为输入层和隐藏层节点之间的正交随机权值,b=[b1,b2,…bL]为正交随机阈值,隐藏层上的激活函数为g(x).ELM-AE 的输出权值β负责从特征空间到输入数据的学习转换,如果D小于或大于L,ELM-AE实现压缩或稀疏的特征表达,依据正则化原则,输出权值β由公式(14)计算:
(14)
若是D等于L,ELM-AE实现的是等维度的特征表达,通
过公式(15)计算输出权值β:
β=H-1X
(15)
ELM-AE 的β可以把特征映射恢复为输入数据;相反,β的转置可把输入数据映射到特征.
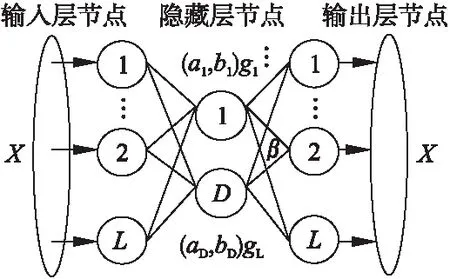
图2 ELM-AE网络Fig.2 Network structure of ELM-AE
3.2 深度PCA子空间极限学习机图像检索算法
深度PCA子空间虽然对图像进行了分块处理,利用卷积进行特征提取保留了一些图像二维的空间信息,减少了网络模型参数数量并降低了模型复杂度,由于并未使用梯度下降法来调整各层权值,其结构制约了该方法在高维度数据中捕获有效特征的能力.多隐层的神经网络具有出色的特征学习能力,特征的多层映射能够更好地描述图像.为了解决这个问题,利用ELM训练速度快的特点,将深度PCA子空间和深度极限学习机良好的表达能力结合,提取隐藏在像素点下更深层的结构信息,从而提高图像检索精度.
本文在深度子空间模型基础上给出了深度PCA子空间极限学习机图像检索算法并给出如图3的模型结构,分成三个部分:
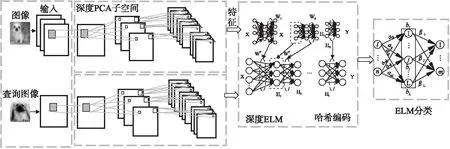
图3 深度PCA子空间极限学习机模型Fig.3 Model of deep PCA subspace extreme learning machine
1)深度PCA子空间将图像直接作为网络的输入,通过级联PCA做卷积来完成非监督低层次特征学习,生成该阶段的卷积特征映射;
2)深度极限学习机通过多层神经网络进行高层次特征学习,将深度极限学习机的输入和输出设置为前一阶段生成的卷积特征映射,最后将隐藏层的输出输入到极限学习机进行监督特征分类;
3)通过二进制哈希实现高维图像数据向低维的二进制空间的映射和重新表示,对隐藏层的特征值进行二值化编码,得到编码后的图像.然后通过汉明距离进行相似性比对并进行图像检索.
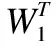
Hi=g((βi)THi-1)
(16)
连接输入数据和隐藏层每一个隐节点的权重向量是彼此正交的,这样可以将输入数据映射到一个随机的子空间.以便捕捉输入数据的各种边缘特征,使得模型可以自动地学习数据中的非线性结构.
为了增强模型的泛化能力,通过L1范式正则化这一常用的变量选择方法,对深度ELM进行约束.使用绝对值函数作为惩罚项来确保算法结果的稀疏性,λ越大,惩罚力度越大,得到的结果越稀疏.下式为所求目标函数:
(17)
Oβ=p(β)+q(β)
(18)
其中,p(β)=‖X-Hβ‖2,q(β)=‖β‖l1,l1表示将求解β既数据稀疏化的过程看做L1范数最优化问题,β表示稀疏代价函数的系数.求解公式(17)中的目标函数得到β,从而得到自动编码的稀疏性限制.
为了求解此最小化目标函数,可采用一种快速的迭代阈值收缩算法来求最优解.设置步长为t=1/L(f),其中,x为所求W,其收敛速度为O(1/k2),具体算法:
1)计算光滑凸函数梯度▽p的Lipschitz常数γ
2)令y1=β0∈Rn为初始点,t1=1开始迭代,对j(j≥1)有:
①βj=sy(yj),其中sy由下式计算得出:
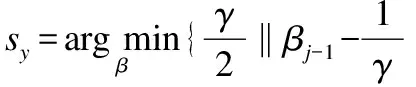
(19)
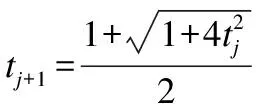
(20)
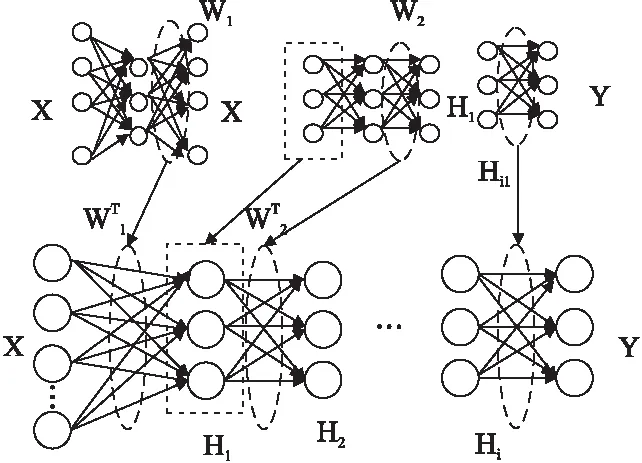
图4 深度极限学习机模型Fig.4 Model of deep ELM
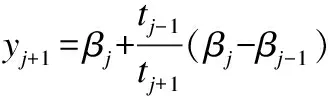
(21)
连接隐藏层和输出层的输出矩阵通过下式进行计算.
(22)
其中H是最后一层隐藏层的输出矩阵.按照上面的步骤迭代后,能够得到深度极限学习机输出的权重,然后将输入数据与经过编码器学习后的特征进行内积运算便可得到输入数据的紧凑型式.
深度极限学习机用作学习单元以执行多层的无监督学习,在此基础上加入稀疏性限制将PCANet得到的特征传递形成较为完整的特征表示,获得稀疏高层特征.随机生成深度极限学习机的输入权值以便能够近似训练中任何输入数据.因此,一旦深度极限学习机被初始化,不需要再对整个网络进行更新和调整.避免了繁琐的BP算法,节省了昂贵的计算资源并降低了模型的复杂度.
此模型的深度架构有助于学习特征的层次结构,减少调整参数的需要,并将原始数据样本逐层重新组合,由低层次的特征逐步形成数据的高层表示,所获特征具有更好地鲁棒性,能够学习到有效的深层特征.利用ELM和堆叠自动编码机的训练速度提高了深度极限学习机的训练速度,同时兼具深度网络优秀的特征抽取能力,避免反向传播算法容易陷入局部极小的缺陷,有效的提升了图像特征的学习效果.
本文所提出的基于深度PCA子空间极限学习机的图像检索算法基本过程如图5所示,主要分为以下3个步骤:

图5 深度PCA子空间极限学习机图像检索算法流程图Fig.5 Flow chart of image retrieval algorithm based on deep PCA subspace extreme learning machine
1.图像预处理
通过预处理,对图像进行简单缩放、数据归一化、逐样本均值消减,以此来删除图像中的兀余信息,便于训练和计算.
2.训练深度PCA子空间极限学习机网络
将图像库送入PCANet,PCANet的滤波器核通过直接提取图像可接受域进行映射,经过级联PCA处理后,送入深度极限学习机得到图像的高层特征表达,同时将待查询的图像样本输入到训练好的深度网络中.
3.哈希检索
为了在保证良好特征的基础上提高算法的性能,通过简洁的特征减少存储和计算的开销,将特征值转化为二值特征.本文将深度PCA子空间极限学习机获得的高层图像特征逐一映射为一维向量,然后通过非线性的sigmoid激活函数将特征向量的值规范到(0,1),通过哈希函数将图像一维向量转换成二进制的编码向量,从而得到图像的特征编码.编码函数表达式如下:
H(x)=f(s(Wx+b))
(23)
在获得图像的哈希编码后,需要将查询图像的哈希编码和图像库中图像的哈希编码进行汉明距离度量,汉明距离通过式(25)计算,汉明距离小则说明两图像相似程度高.反之则说明两图像相似度低.表示为:
(24)
当t>0时,S(x)>0.5;当t<0,S(x)<0.5,将阈值设为0.5,则当t>0时,H(x)=1;当t<0时,H(x)=0.
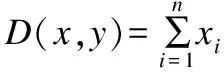
(25)
其中⊕为异或运算,xi∈{0,1},yi{0,1}两个集合分别表示通过哈希函数映射后检索图像和图像库中图像的特征哈希编码.
4 实验结果与分析
为了验证提出算法的有效性和可行性,在MNIST、CIFAR-10、CALTECH256数据库上进行实验,同时与CNN等深度学习算法和当前主流图像检索算法进行对比.所有的实验在CPU为Intel Core i5,2.30GHz,内存为8G的计算机上运行,实验软件为MATLAB-2016a.
4.1 图像库
MNIST数据集默认包含70000个手写0到9阿拉伯数字灰度图像,是NIST集合的子集,每个图像规格为28*28像素,每个采样数据对应0~9中的一个数字标签.
CIFAR-10图像数据库包含10个类别(每类6000张)共60000张彩色图像,大小为32×32,包括猫、鸟、飞机、汽车、鹿、狗、青蛙、马、船和卡车.
CALTECH256图像库是常用的应用于目标分类任务数据集,包括 256 个类别总共 30608 张图像.
4.2 深度PCA子空间极限学习机算法参数分析
4.2.1 深度PCA子空间参数的确定
由PCANet实验可知,卷积核的大小对识别率有较大影响,卷积核太小,无法提取图像的有效特征,卷积核过大,卷积核的表达能力无法体现出特征的复杂度.因此,卷积核大小与神经网络的性能密切相关.在 MNIST手写字符集上进行测试,如表1所示,发现采用3×3大小的卷积核准确率最高,因此本实验采用3×3大小的卷积核.
表1 不同卷积核在MNIST上的训练时间和准确率
Table 1 Time and accuracy of different convolution kernels on MNIST training set

卷积核大小训练时间(S)准确率(%)3×311794.925×511592.547×712193.56
4.2.2 深度极限学习机参数的确定
与现有的深度神经网络相比,深度极限学习机无需人为设置大量的网络参数,只需要设置网络的隐层节点个数和用于计算正则化最小方差的参数C,即可产生唯一的最优解.随着网络层数增加,能够学习到输入图像更深层次的特征,但网络层数过多,很容易形成过拟合的现象,训练时间也会增加.因此,本实验中使用含有两层隐藏层网络结构.
本实验在 MNIST 手写字符集上进行试验,比较分析隐藏层节点数在 1024、512、256、128、64、32 情况下的分类准确率.
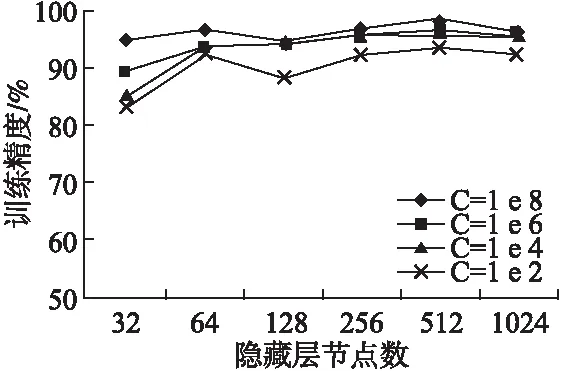
图6 不同隐藏层节点在MNIST中训练精度Fig.6 Training accuracy of nodes with different hidden layers in MNIST training set
由图6可以看到,分类准确率随隐藏层节点数增加而增加,在达到某一数值后保持相对稳定状态,隐藏层节点较少时,深度极限学习机无法充分训练数据,达不到必要的学习和信息处理能力要求.当隐藏层节点数目较多时,深度极限学习机会出现“过学习”现象使训练样本误差率达到最小,且在图像存储方面会消耗更多的存储空间,导致分类的准确率降低.因此,我们选取准确率达到稳定范围内较大的隐藏层节点数.
4.3 深度化算法-神经网络分类性能对比实验
本文算法和深度学习网络节点的激活函数为Sigmoid 函数.深度PCA子空间算法使用双层网络,第一层40个卷积核,第二层8个卷积核,卷积核大小为3×3.使用MNIST和CIFAR-10 采样得到的子数据集,分别在CNN,PCANet,和LLENet等神经网络上进行训练,其中CNN参数参考文献[19],LLENet参数参考文献[20].因分类识别率在衡量算法性能中具有核心作用,所以实验结果使用识别率作为评判标准.
由表2可知,相同训练集和测试集的情况下,本文模型的特征提取能力与卷积神经网络的特征抽象能力相当,CNN使用反向传播算法迭代修正卷积核,需要大量时间训练,而本文算法和PCANet使用了简单的PCA基向量作为卷积核,训练时间相对较少,收敛速度是卷积神经网络的三分之一.相较于LLENet和PCANet识别率提升大约1%.在运行时间方面,与LLENet和PCANet基本相当;可以看出,本文提出的深度PCA子空间极限学习机算法在识别率与卷积神经网络相差无几,可以快速收敛到全局最优值,而且具有简洁的模型结构和少量参数,在识别速度方面有显著提升.
表2 不同神经网络在MNIST和CIFAR-10训练集上的时间消耗和识别率
Table 2 Time consumption and recognition rate of different neural networks on MNIST training set and CIFAR-10 training set

数据库 MNISTCIFAR-10识别率时间消耗识别率时间消耗CNN 99.15% 63min 81.93% 306minPCANet 98.30% 20min 78.81% 90minLLENet 98.35% 21min 79.90% 102min本文算法 99.10% 37min 80.00% 143min
4.4 深度化算法检索-常见图像检索算法对比实验
为了验证本文提出的图像检索算法的有效性和可行性,和经典算法以及一些当今前沿算法进行对比实验和分析,将类标签作为正确的标准,通过对比查询图像和返回图像是否有相同类标签来计算所有指标.比较算法包括:传统的哈希算法LSH、深度哈希DSH、主成分分析哈希算法(PCAH)等.
图像检索性能指标采用查全率(recall),查准率(precision)和平均精度均值(Mean Average Precision,MAP).


在 CIFAR-10 和CALTECH256数据库上测试本文算法的图像检索性能.本实验在哈希编码长度分别为 8、16、32、64、128 情况下测试算法的平均精度均值.
实验结果如图7-图10所示,随着编码长度增加,各算法MAP值都逐渐上升,当编码长度达到一定值后,MAP值逐渐变得平稳.编码长度相同时,使用深度PCA子空间极限学习机后的检索性能有很大提升,表明本文提出的网络算法对提升图像检索性能是有效的.这主要是因为本算法可以学习到更多丰富的细节特征,提高图像的识别能力,直接影响了图像的最终检索性能.
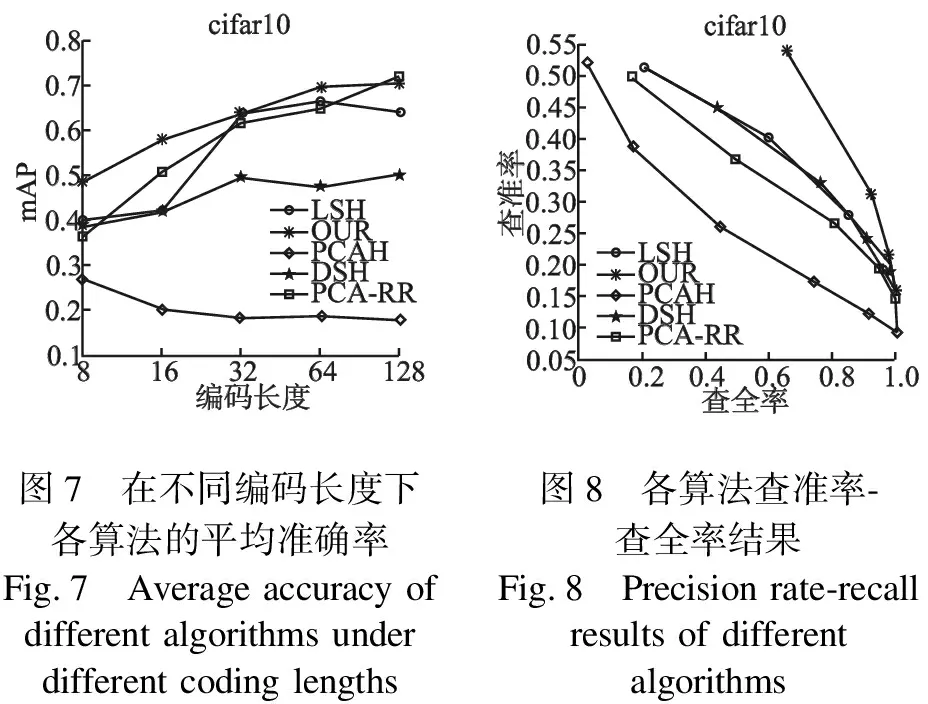
0.80.70.60.50.40.30.20.1mAP8163264128编码长度LSHOURPCAHDSHPCA-RRcifar100.550.500.450.400.350.300.250.200.150.100.0500.20.40.60.81.0查全率查准率cifar10LSHOURPCAHDSHPCA-RR图7 在不同编码长度下图8 各算法查准率-各算法的平均准确率查全率结果Fig.7 Average accuracy ofFig.8 Precision rate-recall different algorithms under results of differentdifferent coding lengths algorithms
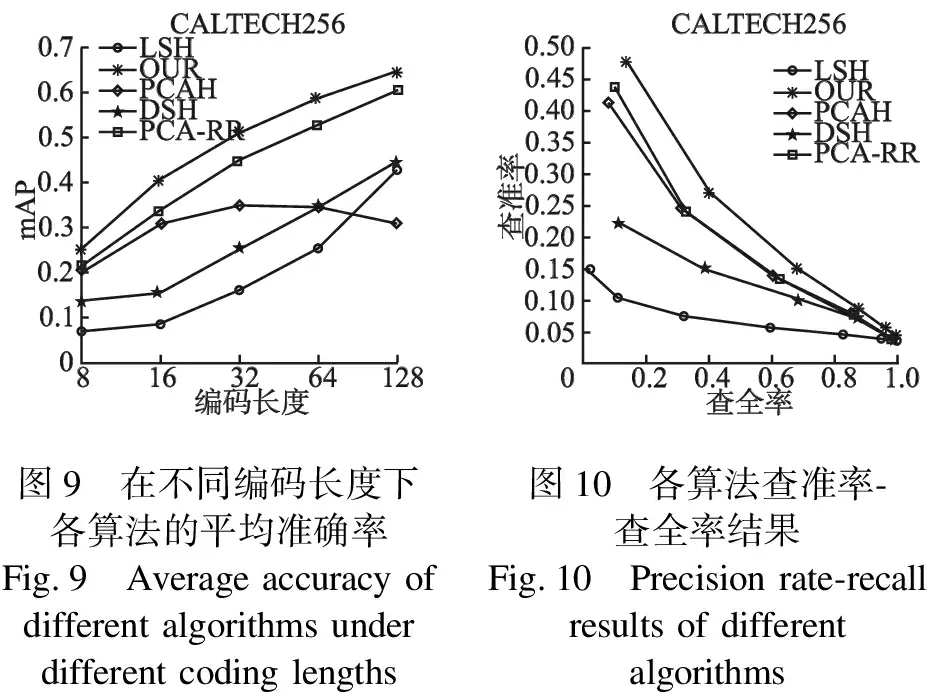
0.70.60.50.40.30.20.108163264128编码长度mAPCALTECH256LSHOURPCAHDSHPCA-RR0.500.450.400.350.300.250.200.150.100.0500.20.40.60.81.0查全率查准率CALTECH256LSHOURPCAHDSHPCA-RR图9 在不同编码长度下图10 各算法查准率-各算法的平均准确率查全率结果Fig.9 Average accuracy of Fig.10 Precision rate-recall different algorithms under results of differentdifferent coding lengths algorithms
5 结 语
受深度学习理论启发,深度结构模型本质上就是将信号在多层次模型中进行逐层映射,极大地有助于分类和检索.本文将深度PCA子空间算法和深度极限学习机应用于图像检索中,在MNIST、CIFAR-10、CALTECH256等图像库上的实验结果表明本文提出算法在图像检索各项指标中表现了较好的性能,这得益于以下3点:
1)采用深度PCA子空间的特征作为深度极限学习机的输入,保留图像的全局特征并保持图像不变性.PCANet 使用二层卷积网络,可以将训练数据中学习到的滤波器组与图像卷积,弥补了认为设置特征的缺点,大大提高了图像分类的性能.
2)多隐层神经网络具有更优异的特征学习,深度极限学习机不但继承了原始极限学习机快速学习特性,而且通过多层堆叠无监督提取层次特征,充分的压缩完成从高维数据到低维数据的映射,得到原始输入数据的多层稀疏表示,具有更好的泛化能力,并保留了图像特征的相似性,提高了图像检索模型效率.
3)将哈希方法与神经网络相结合,通过二进制哈希编码实现高维图像数据向低维二进制空间的映射和重新表示,提高了检索性能.
