基于帧间路径搜索和E-CNN的红枣定位与缺陷检测
2019-03-06曾窕俊吴俊杭马本学汪传建罗秀芝王文霞
曾窕俊 吴俊杭 马本学 汪传建 罗秀芝 王文霞
(1.石河子大学信息科学与技术学院, 石河子 832003; 2.石河子大学机械电气工程学院, 石河子 832003;3.石河子大学图像处理与光谱分析实验室, 石河子 832003)
0 引言
新疆红枣具有极高的营养及药用价值,被称为“黄金寿枣”,受到消费者青睐,社会需求量不断加大,促进了枣树的产业化经营[1]。但同时,霉烂、虫害、裂纹等缺陷严重影响了红枣的品质和价值,红枣分拣势在必行。
计算机视觉技术具有效率高、精度高、检测信息丰富、非接触等优点,在农产品缺陷检测和品质分级领域获得了广泛应用。目前,国内外对于一些流通性好、普及性高的水果,计算机视觉分级或分拣技术已有很多研究,如苹果[2-3]、橙子[4-5]、桃子[6-7]等分级。而对红枣等一些有地域特色的水果涉及相对较少。赵杰文等[8]以河北省沧州市金丝小枣为研究对象,提取HSI模型的H分量均值和均方差,利用支持向量机识别缺陷枣。张萌等[9]基于红枣近红外图像,提出一种亮度快速校正算法,实现红枣表面缺陷分割。李功燕等[10]针对红枣表面饱满度不同的情况,利用不同的梯度算子作为对比,采用归一化梯度直方图作为红枣表面纹理特征实现对干瘪红枣的识别,进一步实现了对红枣品质的评价。然而,通过提取红枣图像特定特征结合传统分类方法对缺陷红枣进行识别,虽然取得了较好的识别效果,但是由于这些特征规则都是人为指定,仍不足以表征图像深层特征。同时,干制红枣表面复杂的纹理特征和图像采集时的不均匀光照,将对基于颜色、纹理等特征的提取产生不利影响。
卷积神经网络[11]是一种目标分类方法,可以自主学习事物间的差异,通过网络训练将原始图像数据变为更高层次和更加抽象的表达,强化表征能力强的特征,弱化不相关因素,在目标检测[12-13]、识别[14-15]上得到了广泛研究和应用。本文设计一套基于计算机视觉,融合CNN学习算法的缺陷红枣智能检测系统。提出基于帧间最短路径搜索的目标定位算法,实现检测场景中每个红枣目标定位,并使得每个目标的位置信息随视频时间序列进行传递,避免复杂的传感器电路设计,并运用该算法结合视频数据,快速、有效地构建样本数据集。基于随机森林的“Bagging”集成学习方式,构建集成卷积神经网络模型(E-CNN),以提高模型泛化性,避免复杂的深层网络模型训练收敛时间长、模型参数庞大的问题。
1 试验材料与预处理
1.1 数据采集
根据GB/T 5835—2009[16]规定,干制红枣缺陷是指红枣在生长发育和采摘过程中受病虫危害、机械损伤和化学药品作用造成损伤的果实。本文以常见的裂纹、虫蛀和霉变缺陷为研究对象讨论缺陷识别方法。试验采用如图1所示计算机视觉视频、图像采集系统,该装置包括在线传输单元和图像采集单元。其中,图像采集单元主要由CV-M7+CL型彩色CCD摄像机、亮度可控的5×2阵列 LED光源、光电传感器、Matrox Solios图像采集卡和计算机组成。在线传输单元由传送带和基于PLC控制系统的可调速传送装置组成。开启光源并调节传送带传送速率,约3 min后,光源和传送速率趋于稳定,利用Matrox MIL9.0软件实现在线视频数据采集。
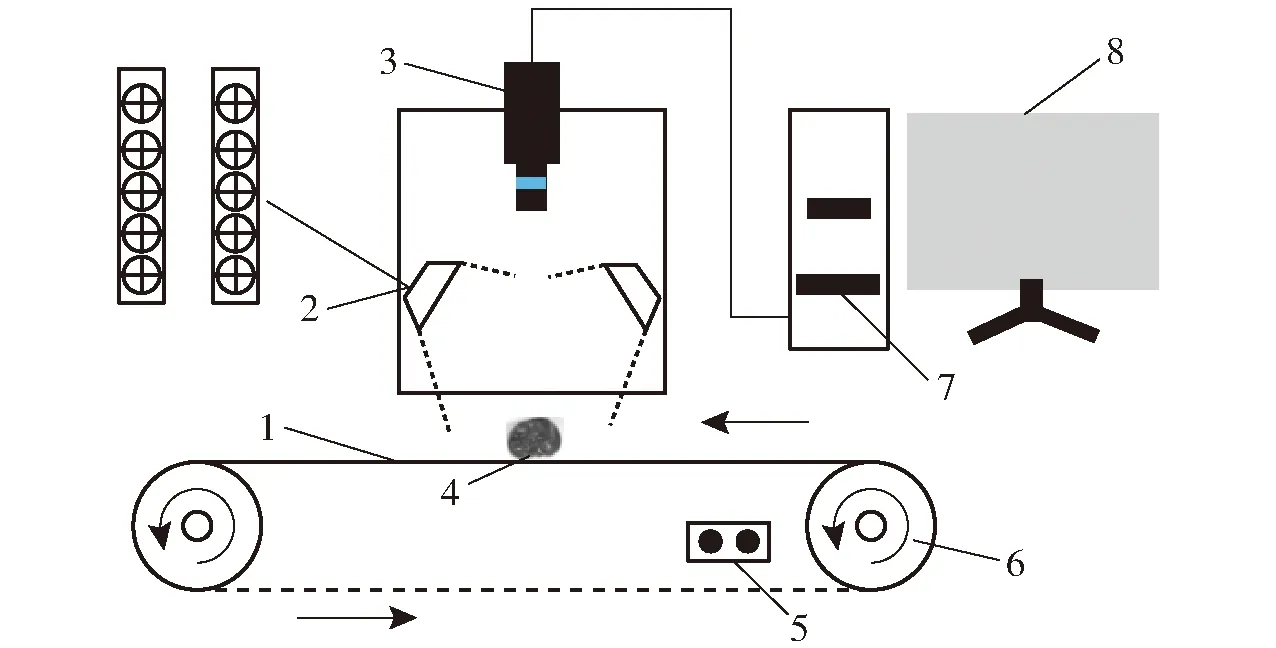
图1 视频、图像采集系统示意图Fig.1 Schematic for video acquisition system1.传送带 2.并排状光源 3.摄像机 4.样本 5.调节阀 6.传动轮 7.图像采集卡 8.计算机
1.2 图像预处理
二值化是一种简单的图像分割方法,对图像进行二值化操作可以有效地将图像中的红枣目标和背景进行分割。在基于视频流实现每个目标定位的过程中,首先需要对帧图像中的红枣目标进行分割。如图2a为视频序列中随机抽取的一帧图像,通过对比其R、G、B等各分量灰度分布直方图,发现B分量的灰度直方图(图2c)中,背景和红枣目标分别形成2个明显波峰,同时波谷呈现的形态代表背景和目标在B分量灰度上存在着较大差异。因此,根据波谷的位置,选取100作为图像分割阈值得到二值图像。再对得到的二值图像进行腐蚀、膨胀等操作滤除噪点,结合设定的连通域内最小面积阈值,搜索得到满足要求的连通域集合,进而获得集合中每个连通域对应红枣目标的正外接矩形(图2b)。

图2 图像预处理Fig.2 Image preprocessing
2 基于自适应帧间最短路径搜索的红枣定位
2.1 构建图像坐标系与红枣正外接矩形特征向量

图4 基于帧间最短路径搜索的目标定位示意图Fig.4 Schematic of target location based on the shortest path search between frames
检测场景中红枣目标定位是实现对其缺陷检测的重要前提。视频图像中目标的定位一直是图像处理领域的研究热点。相比于YOLO系列[17]、R-CNN[18]和Fast R-CNN[19-20]等复杂的神经网络模型,基于图像背景与目标的显著差异性,利用分割阈值以及形态学等操作的图像处理方法,是实现图像中目标定位的常用手段。而对于视频流数据,每一帧图像之间相互独立。因此,要实现视频中红枣目标的定位,需要在单帧图像处理基础上,使得图像中每个目标的位置信息能够随视频时间序列进行传递。
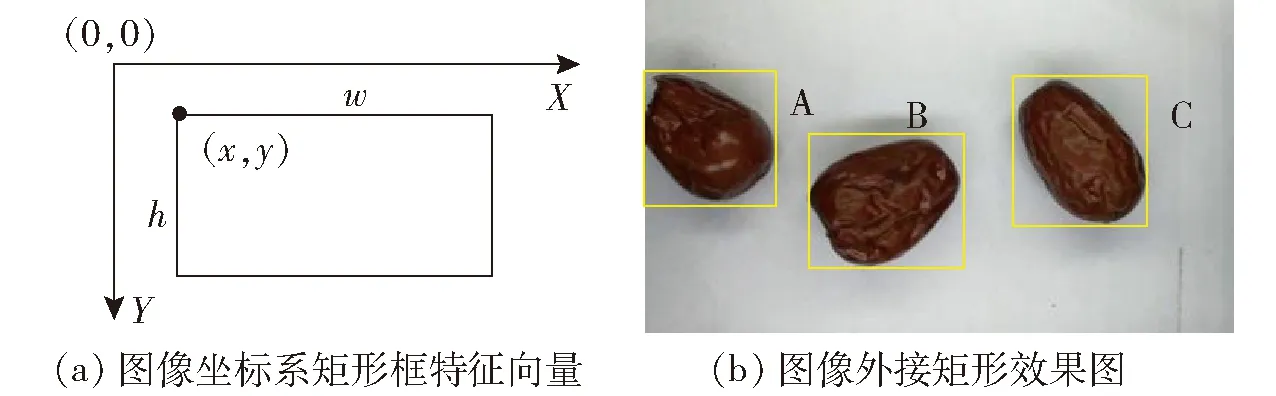
图3 图像坐标系与外接矩形Fig.3 Image coordinates system and circumscribed rectangle
图像都是由像素组成,图像中目标的位置信息由像素坐标确定。要确定像素坐标,首先需要确定图像的坐标系,常见的坐标系有图像坐标系、相机坐标系和世界坐标系等。由于试验只需要确定检测目标在二维平面的位置即可,因此选择图像坐标系。如图3a所示,该坐标系以图像左上角为原点建立以像素为单位的直角坐标系X-Y,横、纵坐标分别是其在图像数组中所在的列号和行号。试验以红枣最小正外接矩形左顶点(x,y)作为该目标的位置坐标,同时结合水平方向长度w和竖直方向长度h,构成单个目标外接矩形的4维特征向量
f=(x,y,w,h)
(1)
针对一幅图像中出现的多个目标,从而建立第n帧图像的目标最小正外接矩形特征向量集合
Fn={f1,f2,…,fk,…,fm|fk=(xk,yk,wk,hk)}
(2)
如图3b所示,图像中存在目标A、B和C,在对图像中的红枣进行基于最小正外接矩形框提取ROI时,发现目标A没有完全进入场景。因此,为了保证场景中红枣目标的完整性,利用外接矩形和图像边界关系,得出特征向量约束条件
(3)
式中lcols、lrows——输入图像数组中的列号和行号
2.2 基于帧间最短路径搜索的红枣定位
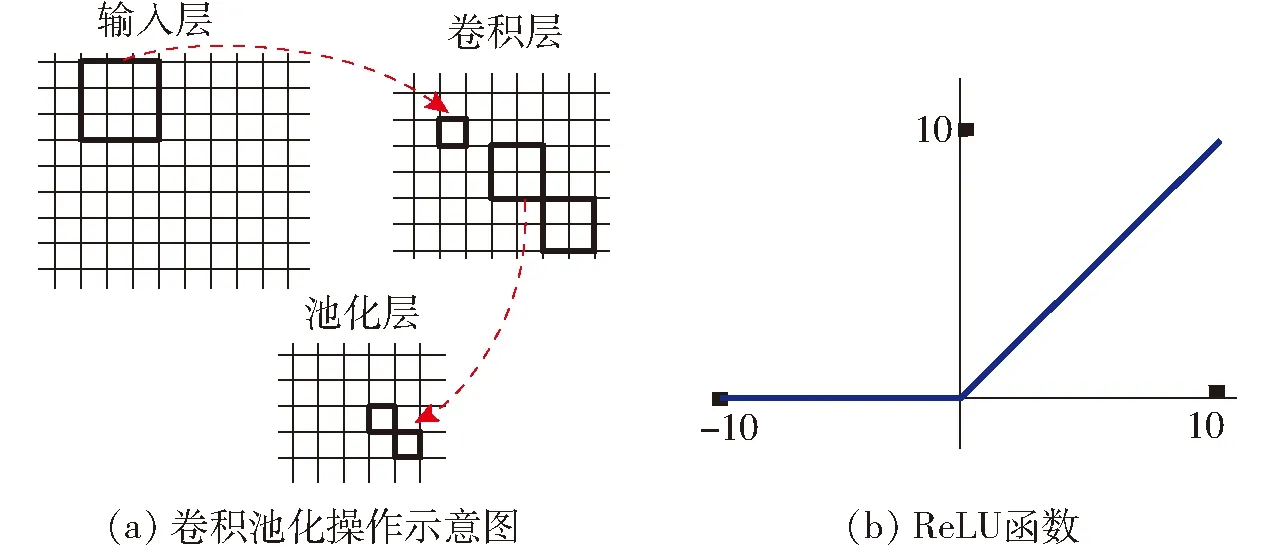
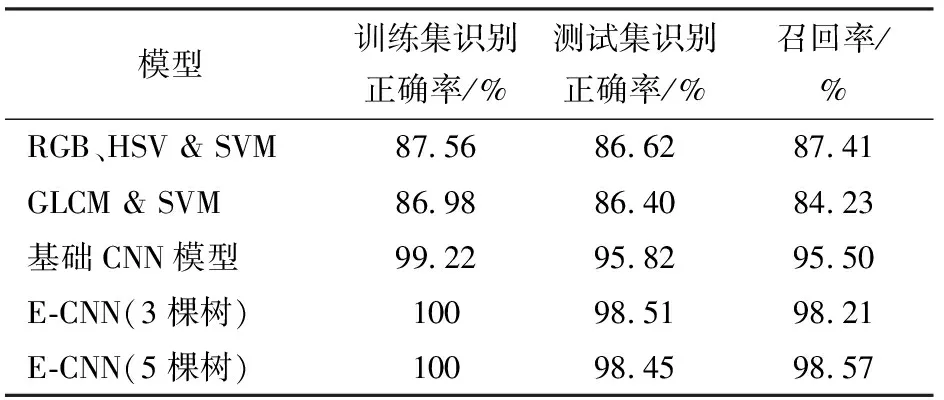
图4为基于帧间最短路径搜索方法实现目标定位的流程示意图。如图4所示,第n-1帧中目标A的位置坐标被映射到空间坐标内,记作目标A0。进入第n帧后,图像中出现2个目标,同理,将其位置坐标映射到坐标系内,分别记作A1、B0,通过距离公式计算得到距离lA0A1和lA0B0,根据lA0A1 此算法的核心是提取第n帧中所有红枣目标的正外接矩形参数,得到当前帧特征向量集合Fn,根据得到图像中每个红枣目标的位置信息(x,y),将其坐标映射到空间坐标系中。再基于一定的间隔选择合适的图像帧,计算当前帧中目标i与某一历史帧中所有目标的距离得到距离集合 Di={D(i,j)|j∈1,2,…,m} (4) 式中m——历史帧中所有目标数目 为减少计算,距离D(i,j)定义为“D4”距离(城市距离) D(i,j)=|xi-xj|+|yi-yj| (5) 在距离集合Di中选择最小距离的目标 (6) 根据得到的最小距离D(i,k),表明历史帧中的目标“k”和当前帧中目标“i”为同一目标,从而实现目标定位和位置坐标信息随视频序列传递。 其中,对于刚进入检测场景的完整红枣目标,在进行帧间最短路径搜索匹配的过程中,必然会有一个最短距离。显然,检测场景中新出现的目标不能与历史帧中任何一个目标建立匹配关系进行位置坐标传递,因此在距离集合Di中选择代表最小距离的位置坐标时,需要添加约束条件 (7) 图5 基于集成学习方式的卷积神经网络模型Fig.5 Convolution neural network model based on ensemble learning 式中TH为判断条件成立的最大距离阈值,该值的选取需要同时考虑传送带转速和传送带上红枣目标放置的疏密程度。因此只有同时满足最小距离要求和约束条件γ时,才能进行对应位置坐标的更新与传递,否则将被作为新目标传递到下一轮判定中。 卷积神经网络的基本结构包括卷积层C、激活层ReLU和池化层P。在卷积层中,每个神经元的输入与前一层的局部感知区域相连,提取局部特征;在激活层中,根据得到的每个神经元输入,结合偏置项,通过激活函数实现对结果的非线性映射,使得网络不再是输入的线性组合,从而能够逼近任意函数;在池化层中,网络中每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值共享。卷积神经网络具有局部感知和权值共享的特点,从而使之更类似于生物神经网络,能有效减少需要学习的参数数量,降低网络模型的复杂度,从而提高神经网络的训练性能。 根据卷积神经网络的基本结构,结合待测样本的特征,建立了如图5所示的基于集成学习方式的卷积神经网络模型。考虑到所需分类任务相对简单,且规定的输入图像分辨率较低,同时为了减少需要学习参数的数量,降低模型训练的复杂度和时间,所以摒弃了类似Alexnet、Googlenet、Resnet等复杂的特征提取、分类模型或其对应的迁移学习模型。同时,基于随机森林“Bagging”集成学习方式利用各个学习器之间没有依赖关系,可以并行拟合的特点,将若干个较“浅”的卷积网络模型分别作为树模型。在同一样本空间下,每个卷积神经网络模型在“有放回”的训练模式下,随机从样本空间中选取80%的样本进行特征学习、分类。最后利用得到的若干个神经网络树模型结果进行“投票”,选出票数最多的类别作为最终分类结果。同时,规定每一棵树模型具有相同的网络结构,其结构如表1所示,具体描述如下: (1)输入层 基于帧间最短路径搜索实现检测场景中的红枣目标定位,再根据获得的目标最小正外接矩形参数,对红枣目标进行提取ROI操作,得到每个目标对应的完整图像。最后进行尺寸归一化操作,得到分辨率为64像素×64像素的输入图像。 (2)卷积层和激活层 C1、C2为卷积层,分别由25、30个3×3的卷积核与输入图像进行卷积运算,实现对高维向量的低维特征提取,从而使原信号特征增强并降低噪声影响,其操作运算如图6a所示。其中对于C1层,设定“Padding”为1,存在公式 表1 卷积神经网络树模型结构Tab.1 Details of tree models of proposed CNN architecture (8) 式中i——输入图像的尺寸 p——填充系数 k——卷积核尺寸S——步长 o——C1层特征图像边长 经过计算,得到o=(64+2×1-3)/1+1=64,特征图和输入图像尺寸一样,但个数由3变为25。试验发现,在网络深度一致的情况下,使用尺寸更小、数量更多的卷积核能更有效地进行特征表达,实现准确分类。同理,由于C2没有设置填充,经过相应卷积核运算后,输出尺寸相应减小。然而,经过卷积运算后得到的输出,本质上仍然是上层输入的线性函数,因此需要通过激活函数向模型中加入非线性因素,从而实现向任意函数逼近。其中,ReLU激活函数(图6b)相对于传统的Sigmoid激活函数计算量更少,收敛速度更快。同时,ReLU函数会使一部分神经元的输出为0,使得网络具有稀疏性特点,从而能更好地挖掘相关特征并减小参数的相互依存关系,缓解过拟合问题发生。最终,卷积层特征图计算过程表示为 图6 卷积神经网络的操作运算和函数Fig.6 Major operations and function in CNN (9) (3)池化层 作为特征映射,池化层通常同卷积层、激活层级联出现。通过对得到的卷积图进行下采样得到池化特征图,能在有效降低特征维度的同时,尽可能地保留原始信息。同时,池化运算也能实现平移不变性、旋转不变性及尺度不变性,并扩大感知野。池化层特征图计算过程表示为 (10) 式中s——下采样模板尺寸 根据模板权值不同,池化方式包括最大池化、平均池化和随机池化等,本文选用最大池化方式。 (4)dropout dropout是指深度学习网络在训练过程中,对于网络神经元,按照一定的概率将其暂时从网络中丢弃。因此,对于随机梯度下降来说,由于是随机丢弃,所以每个mini-batch其实都在训练不同的网络。同时,其强迫一个神经单元和随机挑选出来的其他神经单元共同工作,减弱了神经元节点间的联合适应性,增强了泛化能力,是一种简单而有效的正则化方式。 卷积神经网络相对传统机器学习,需要更多的训练数据。而传统的基于静态图像的数据采集方式存在效率低、耗时长等缺点,而对得到的图像,通常采用旋转、映射变换的方式来扩大数据集。然而,由于卷积神经网络具有平移不变性、旋转不变性及尺度不变性等特点,因此可能对模型的泛化能力存在一定影响。本文在基于帧间最短路径搜索实现图像中红枣定位的基础上,结合红枣的最小正外接矩形参数,选取合适的帧间隔,对图像中的目标分别提取ROI,实现目标从进入场景到离开检测场景的图像采集,从而提高采集效率。图7为某一红枣目标从“进入”到“离开”之间,采集到的不同时间序列的图像。 图7 基于帧间最短路径搜索的目标时间序列图像采集Fig.7 Image acquisition of targets based on the shortest path search of inter frames 模型引入“sgdm”的梯度下降方式,不同于传统随机梯度下降方式使得参数更新方向完全依赖当前的batch,导致更新不稳定。“Momentum”,即权值动量因子,通过模拟物体运动时的惯性,即在更新时在一定程度上保留之前的更新方向,同时利用当前batch的梯度进行微调,可以在一定程度上增加稳定性,加快学习速率,并具有一定摆脱局部最优的能力。模型设定保留原始更新方向比例参数为0.8。同时设定学习率为0.000 1,迭代次数为50次,梯度更新的最小随机样本数为128,正则化惩罚系数为0.000 1。同时,为了随机生成更多的网络结构,设定隐含节点dropout率为0.5。 经过预处理操作后,根据2.1节和2.2节的原理概述,进而建立图像坐标系、提取目标正外接矩形 参数、设置边界判断条件、位置坐标映射、最短路径搜索判断、坐标更新传递,使得红枣目标能够随视频时间序列实现定位。同时,为了能够更好地显示算法对场景中每个红枣目标的定位效果,根据目标在场景中出现的顺序,用相应的序列数字作为每个红枣目标独有的标签。试验选取10段实时检测视频,且每段视频都包含10颗红枣,累计100颗红枣目标。运行算法,100颗红枣目标被识别和标记,试验表明,对红枣目标的定位、标记正确率为100%。如图8所示,10颗红枣被正确定位,且根据进入场景的顺序,被赋予正确的标签。 图8 基于帧间最短路径搜索的目标定位效果Fig.8 Location of targets based on the shortest path search of inter frames 分别采集有虫蚀、霉变、裂痕和黑头的140颗缺陷红枣和156颗正常红枣的图像,基于3.2节所述的样本集制作方法,结合视频图像数据,对红枣目标进行定位及提取ROI,将提取ROI得到的图像作为网络模型输入,并最终制得871个试验样本。试验按照4∶1比例随机分配训练集和测试集,进行10次模型训练和检测识别,取平均识别率。同时,为了直观反映模型试验效果,规定缺陷红枣为正样本P,正常红枣为负样本N,TP表示结果正确预测为正样本数,FP表示结果错误预测为正样本数,TN表示正确预测为负样本数,FN表示错误预测为负样本数,进而得出 (11) (12) 式中FAccuracy——识别正确率,体现算法的整体识别效果 FRecall——召回率或查全率,表示模型对缺陷红枣的识别精度 在进行集成卷积神经网络模型训练时,每次同样随机选择训练集中的80%作为训练样本来构建基础树模型。试验发现,经过50次迭代训练后,可以实现对训练集的识别正确率达到99%以上,网络得到了较好的收敛,达到了预期的训练效果。按照图5所示的模型架构,使用训练好的模型对训练集进行检测,识别结果如表2所示。 表2 模型缺陷识别结果Tab.2 Identification results of training and test set with different models 如表2所示,试验使用了5种不同的识别模型,基于传统的颜色、纹理识别模型,试验提取图像R、G、B和H、S、V分量的均值、方差作为颜色特征,采用常用的灰度共生矩阵(GLCM)进行纹理特征提取,再分别使用支持向量机(SVM)分类器得到识别结果。通过对比发现,卷积神经网络的识别正确率和召回率都在95%以上。因此,相比传统的颜色、纹理分类模型,卷积神经网络在特征表达和分类识别上具有明显的优势。同时,相比基础卷积神经网络模型,基于集成学习方式的卷积神经网络模型(E-CNN)集合随机森林算法特点,通过构建基础树模型,根据每棵树的输出结果通过“投票”得到模型最终结果,能有效提高模型的泛化能力和识别正确率。文中试验了E-CNN(3棵树)和E-CNN(5棵树) 2种E-CNN模型,相比基础CNN模型,识别正确率和召回率都提高2个百分点以上,证明了E-CNN模型的有效性。同时对于本次试验,3棵基础树和5棵基础树构建的分类模型输出结果近似,因此在实际使用中需要不断试验得到最佳树模型数。 (1)基于帧间最短路径搜索实现目标定位的方法,使得待测目标的位置信息能够随视频序列进行传递,避免了传统的复杂传感器电路设计。试验表明,检测场景中目标定位正确率达到100%。 (2)基于帧间路径搜索的目标定位方法,结合视频数据,能快速、有效地制作数据集。同时,由于传统的数据集扩充方法受卷积神经网络平移不变性、旋转不变性及尺度不变性特点影响,本文提出的数据集制作方法能从数据上提高模型的泛化能力。 (3)基于“Bagging”学习方式,集成卷积神经网络模型(E-CNN)。通过构建较“浅”的基础树模型,结合“投票”机制提高了模型的泛化能力和学习能力。试验表明,模型的识别正确率和缺陷红枣的召回率都达到98%以上,该模型在相机像素普遍较低、计算能力有限的生产背景中,有着较大的研究价值和应用潜力。

3 基于卷积神经网络的缺陷红枣识别
3.1 网络模型构建





3.2 训练集制作

3.3 网络训练参数设置
4 试验与结果分析
4.1 基于帧间最短路径搜索实现目标定位效果

4.2 基于集成卷积神经网络模型的缺陷红枣识别
5 结论
