基于WDNN的温室多特征数据融合方法研究
2019-03-06孙耀杰薛绪掌郑文刚乔晓军
孙耀杰 蔡 昱, 张 馨 薛绪掌 郑文刚 乔晓军
(1.河北工业大学电子信息工程学院, 天津 300401; 2.北京农业智能装备技术研究中心, 北京 100097;3.北京农业信息技术研究中心, 北京 100097)
0 引言
随着设施园艺面积的逐年增加,为生产环境调控提供智能决策成为当前人工智能在温室生产中研究应用的核心问题之一。若对数据未进行融合而选择直接判断提供决策信息,仅在少量输入特征时可行,随着输入特征的增加,直接判断法的逻辑复杂度随着特征的增加呈指数增长且无学习能力,降低了决策系统的可发展性和可扩展性,造成日后维护和升级成本大大增加,因此高效的数据融合算法显得格外重要。目前国内温室数据融合算法较为单一,鲜有将深度学习模型与温室数据融合相结合。深度学习以强大的数据分类及拟合优势,能够为温室复杂多变环境数据实时精确融合提供新的算法,掌握温室环境变化规律,对温室作物的生长和温室环境的调控具有重要意义。
当前温室数据融合研究主要分为数据级、特征级和决策级3个层次。其中数据级数据融合[1]在温室环境监测系统广泛应用,对获取的原始数据进行加权平均比传统平均算法数据精度提高7%[2]。进一步优化算法可将指数平滑和新型幂均方融合算法结合,使实际运行时间缩短83.6%的同时,数据方差比算术平均降低0.027[3]。在面对数据异常情况时,将分布图算法与卡尔曼滤波相结合,增加系统对缺失数据处理的能力且处理精度进一步提高[4]。数据级融合适合硬件设备进行传输和处理,但融合后数据量庞大,从而产生了特征级数据融合[5-6]。因温室环境复杂导致监测数据常出现异常点、冗余或传输干扰等现象,多数特征级融合与数据级融合算法相结合,如卡尔曼滤波器与贝叶斯估计相结合[7],可改善数据融合前的不一致性以及利用贝叶斯算法融合后的不确定性。或将自适应加权平均和D-S算法相匹配[8],改进后的D-S算法时间复杂度由传统的O(an)下降到O(a2n)[9],在减少数据冗余的同时,提高了系统的运行效率,但存在模型参数难以确定等问题。决策级温室数据融合集中在专家系统和BP神经网络[10-11]的构建,专家系统利用推理机对已有条件做出精确判断及相关决策[12-13]。神经网络可利用ANN模型对温室温度及湿度进行融合,融合结果与真值对比,均方误差(MSE)分别达到0.04℃和0.075[14]。决策级数据融合层次位于顶层,具有高容错性和强鲁棒性的特点,但目前主流的决策级数据融合算法存在处理数据维度有限,收敛速度慢且泛化能力差等问题。
针对用于温室融合算法老旧、智能化程度低、融合数据种类单一及模型融合精度不足等问题,本文提出基于WDNN网络的两级温室数据融合体系,利用深度学习模型的强大非线性拟合及泛化能力,通过温室传感器网络采集数据并训练模型,以探索对多点多维混合特征的决策级融合,给出温室各区域及整体环境的决策信息。
1 温室数据获取与深度融合结构设计
试验于2017年11月20日18时在北京市农林科学院玻璃连栋温室内架设仪器采集数据,试验场地示意图如图1所示。
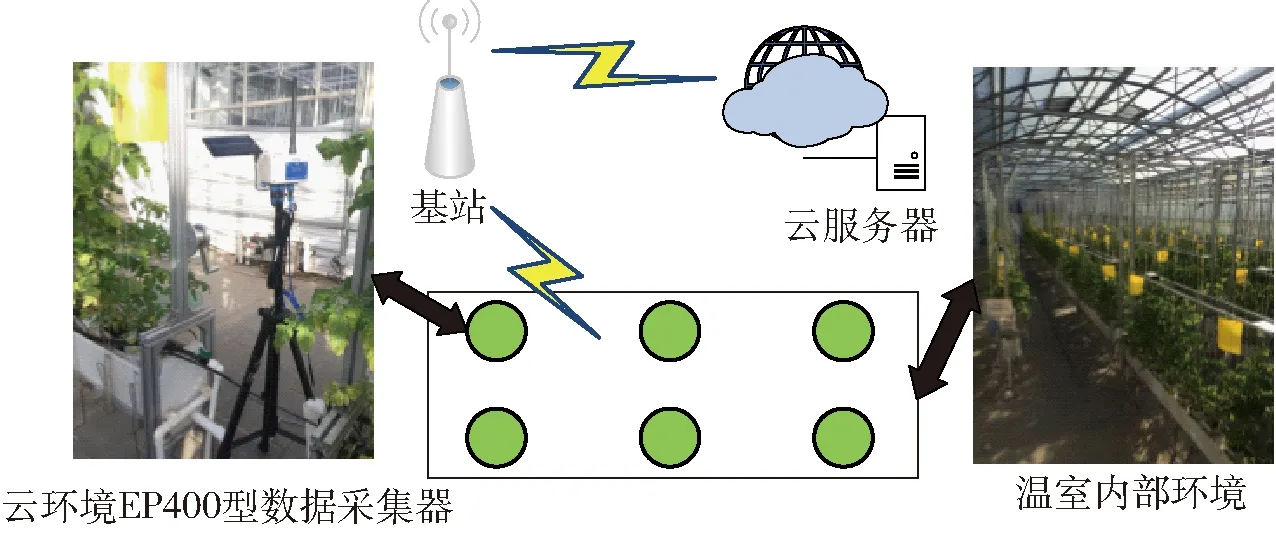
图1 温室环境监测网络布局与架构图Fig.1 Greenhouse environment monitoring network layout and architecture diagram
该温室单跨南北长度28.5 m,东西宽度10.5 m,总高6 m,肩高4 m左右,温室内种植作物为番茄[15-16],为符合番茄种植要求,温室采用相应调控措施,其中最大湿度阈值设定为80%,当湿度超过阈值会开启风扇进行排湿,但环境调控效果存在滞后现象,故湿度不会立刻降到80%以下,需要一段时间缓冲,因此本试验所获取湿度最大值会略高于80%,但不会使其达到100%,可有效避免番茄产生病害。温室环境监测设备采用国家农业智能装备技术中心研发的温室云环境EP400型数据采集器,每个数据采集器可测量空气温度(量程:-40~80℃,精度±0.5℃)、空气相对湿度(量程:0~100%,精度:±3%)、土壤温度(量程:-40~80℃,精度:±0.5℃)、土壤湿度(量程:0~饱和,精度:±3%)、CO2浓度(量程:0~2×10-3,精度:±5×10-5)及光照强度(量程:0~100 klx,精度:±10 klx),以30 min时间间隔通过GPRS网络发送到远端云服务器,数据采集器安装在三脚架上,距离地面高度为1.3 m,各数据采集器纵向间距为5 m,横向间距为4.8 m,对称均匀地放置在温室中,如图1中绿点所示。设置数据采集间隔为30 min一次,既保证了温室作物环境的有效监测、减少硬件传输损耗,又可保证模型训练的较大数据需求量,且无需在底层进行数据级的数据融合,降低系统复杂度,使数据的信息量没有损失,也保留了温室作物生长环境的原始信息。
采用WDNN深度学习模型对连栋温室内多点多特征数据进行决策级的数据融合。构建了两级温室数据融合系统,如图2所示。
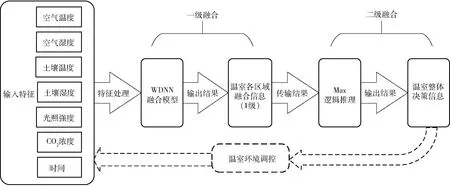
图2 两级温室数据融合模型Fig.2 Two-level greenhouse data fusion model
图2中,输入特征为温室内部环境监测数据,本文未考虑外部气象数据等间接特征(即调控设施或外部天气变化时会引起温室内部环境状态改变),在可直接获取温室内部各环境变量的前提下,已经包含了其他因素对温室内部环境的影响,若添加间接特征会增加数据冗余度,降低所训练模型的泛化能力。一级融合为该系统的核心处理层次即第1次数据融合,利用深度学习模型对6个数据采集传感器传输的多源异构数据进行处理,并分别给出各个区域作物的生长环境状态。二级融合处理将一级处理结果进一步融合,该融合体系将二级融合称为Max逻辑推理,按照少数服从多数原则进行二次融合,当区域融合结果相同数量占据总量1/2及以上时,该区域融合结果代表温室整体融合结果(若胁迫结果与正常结果相等时,取胁迫结果,此设定可减少作物受到伤害)。第2次数据融合后,给出温室整体的环境状态并提供温室环境调控建议,以达到对作物生长环境进行调控的要求。图2虚线模块为温室硬件调控模块,主要负责接收根据综合决策信息而提供的调控建议,并实施相应调控策略,以虚线画出表示本文研究不涉及硬件层面,但却与硬件调控紧密结合。二级融合架构可对无线传感网络数据进行分层融合,且多级融合符合模块化设计理念,可对架构作出相应调整以更好地适用于更复杂的融合环境,提高了融合系统的泛化能力。
2 传感器网络数据预处理
目前温室数据融合的预处理主要集中在底层,会采用较小的数据采集间隔(多为1 min间隔)以提高数据量,但考虑到温室无线传感网络的功耗和传输效率,大多预处理会剔除或滤掉异常数据[17-21],减少了数据本身的信息量,信息量的减少会造成对所监测对象的决策和分析产生较大误差。在利用WDNN网络模型进行顶层数据融合时,为了保留原始数据的全部信息,本试验并未对数据进行平滑处理(平滑或其他预处理会损失特征的信息量),而是对获取的全部原始数据进行标记,且在此基础上增加了时间特征,丰富的数据信息可增加融合后的决策准确度。
训练模型首先需构建训练集和测试集,因两种数据集构建方式一样故以训练集为代表进行描述。首先获取原始数据,为传感器实时传送并记录到数据库的环境监测数据,因融合过程是对输入数据进行分类,故训练集中每条数据都需进行类别标记。数据与标签的合理匹配需明确各输入特征间的权重关系,进行多特征分析,找出主导特征。各参数走势曲线如图3所示。
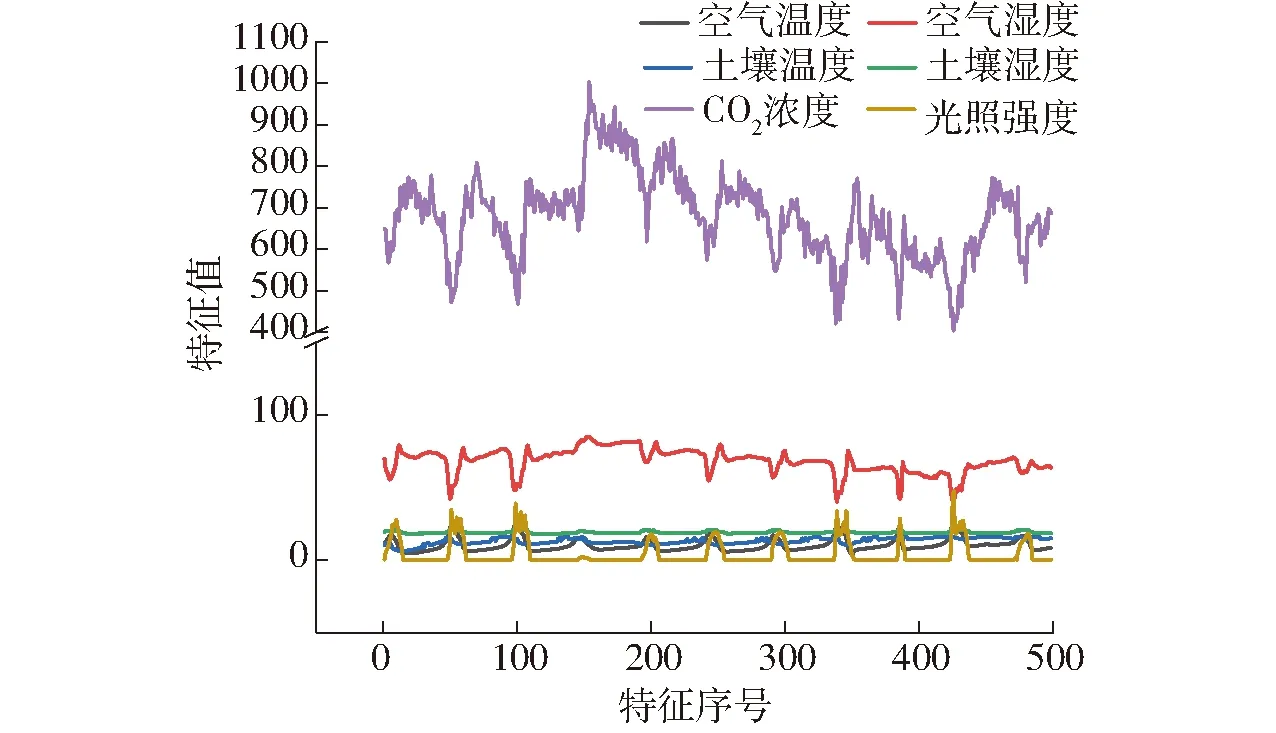
图3 温室环境特征Fig.3 Features of greenhouse environment
由图3可以看出,温室各环境特征间具有很强的规律性和周期性,特征之间具有明显的正相关或负相关关系,如温度、湿度两个参数具有强负相关特性,温度的增长会导致湿度的下降,温度、湿度、CO2浓度和光照强度均为植物生长的重要环境参数,每个特征都应在融合系统中分配相应的权重,由图3可知,温度与其他监测特征具有强耦合关系且可控性高,所以以温度特征为基准去分析,可以更准确地反映其他参数的分布及变化趋势。
其次需增加训练集的数据量,将异常数据加到训练集中,可使模型对异常值进行判别,为全面准确地描述温室内各区域及整体的环境参数分布,需将6个数据采集点数据全部合到一起,可使训练集包
含整个温室内部的数据,处理后训练集部分数据如表1所示。表1中第1列时间变量是稀疏特征(特征值为1、2、3、4和5)。其中1、2、3分别代表上午、中午和下午,对应:06:00—10:00、10:00—14:00、14:00—18:00,只用来描述日间温室环境正常及胁迫数据;4代表日间,对应:06:00—18:00,只用来描述日间传感器异常数据;5代表夜间,对应18:00—06:00,用来描述夜间温室环境正常、胁迫及异常数据,用于细化不同时间段作物对环境的需求;第2~7列变量为数值数据,为各气象参数;第8列为分类类别,根据番茄适宜生长环境需求及具体监测数据情况划分为:日间温度过低、湿度过高、CO2浓度较高、光照强度过低; 日间温度较低、湿度较高、CO2浓度正常、光照强度较低;日间各环境参数正常;日间温度较高、湿度较低、CO2浓度较低、光照强度较高;夜间温度较低、湿度较高、CO2浓度较高、无光照;夜间各环境参数正常;传感器网络数据异常共7个类别,以上类别涵盖了24 h各情况下的温室监测数据,适合WDNN网络对数据进行深度融合;此外,表1中1~4行为白天4个类别的典型数据示例;5、6行为夜间2个类别的典型数据示例;7~9行为传感器异常数据的典型示例(日间异常数据不进行细分,用4统一进行描述)。本文所用训练集、测试集及预测集均为实时数值。
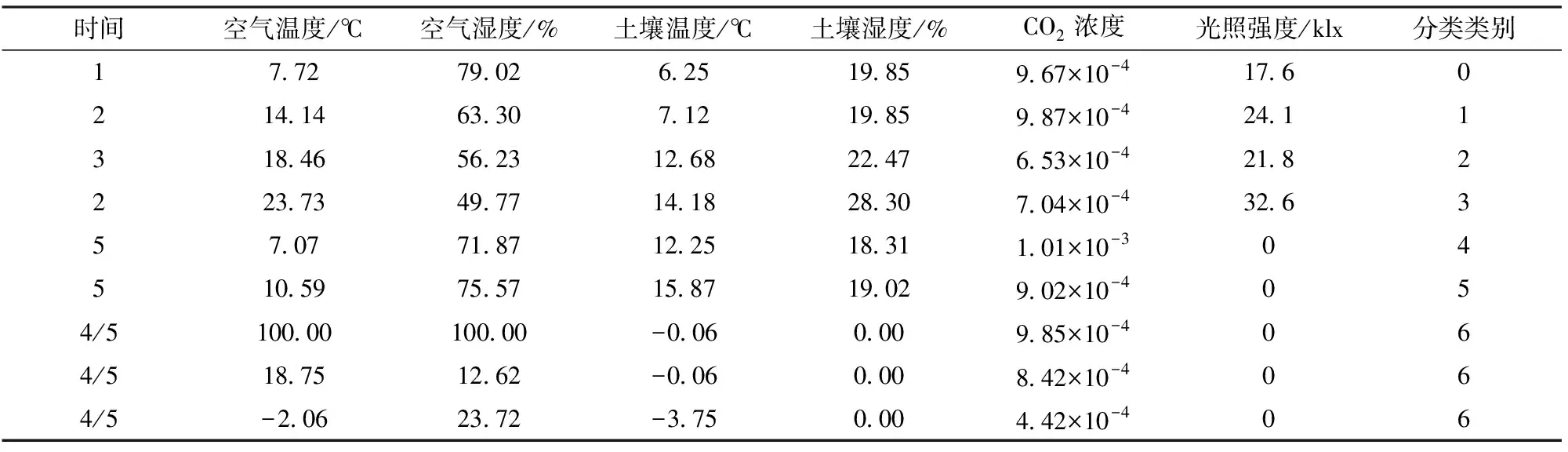
表1 训练集数据示例Tab.1 Data example of training set
处理后的训练集和测试集均为7个特征和7个分类类别的混合数据集,测试集需要严格按照训练集的规格进行整理,才能精确地判断所训练模型的性能,最后需将整理好的Excel格式训练集和测试集转换成csv格式,方便程序对数据的读取及处理。
3 深度学习融合模型构建
3.1 普通DNN分类模型
传统深度学习网络[22](Deep neural networks, DNN)即含多个隐含层(大于等于2层)的人工神经网络,理论上单个隐含层的多层感知机(Multilayer perceptron, MLP)只要具有足够多的隐含层节点就可以拟合任何非线性函数,但是过多隐含节点极易导致优化算法无法确定模型最优参数或训练过拟合,无法进行泛化及应用。2006年HINTON等[23]提出的深度学习算法很好地解决了上述问题,模型结构示意如图4所示。
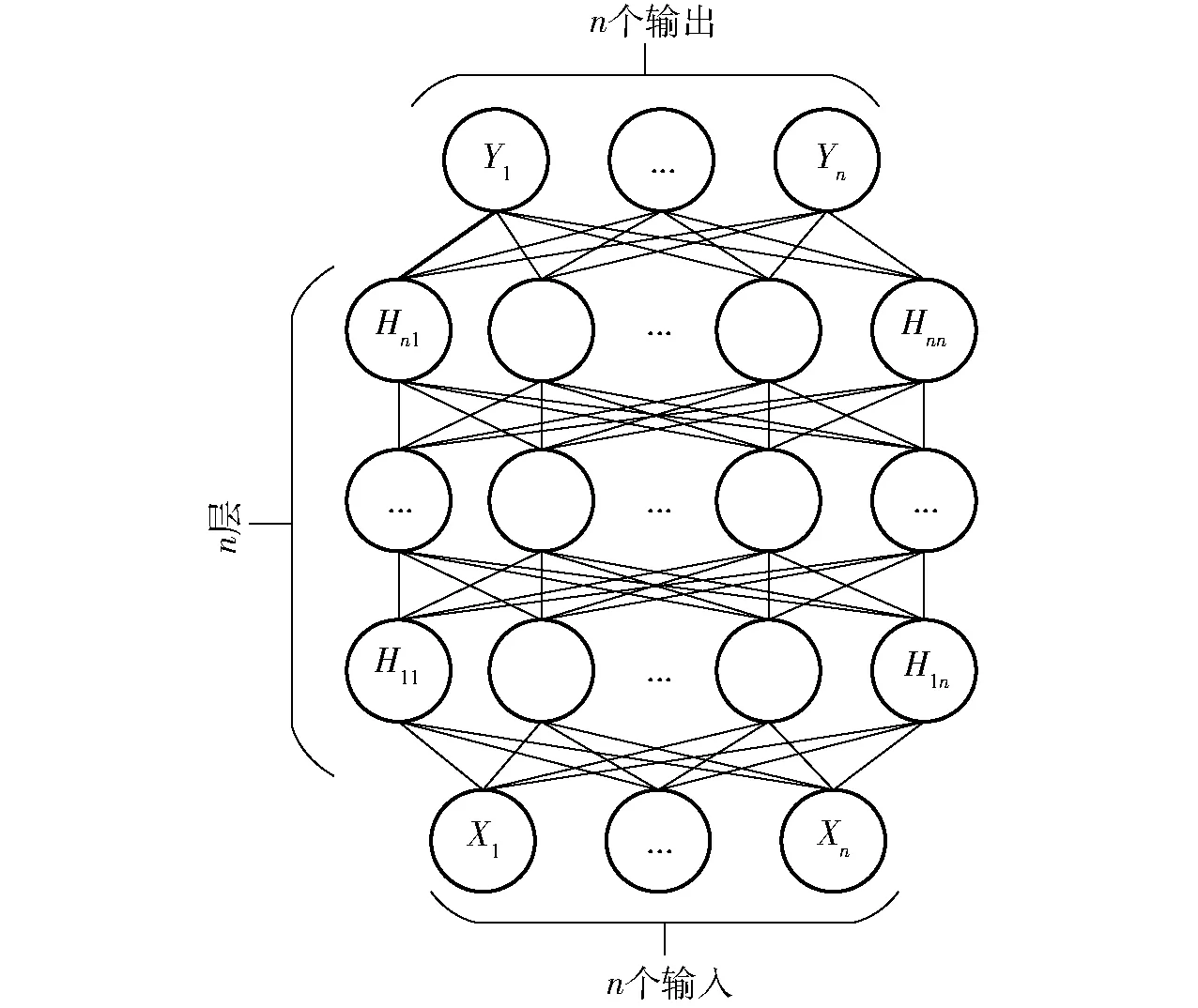
图4 DNN网络模型Fig.4 DNN network model
图4中的模型具有多隐含层结构,相比于传统的MLP模型而言具有更强的数据拟合能力,GOODFELLOW等[24]试验表明,增加隐含层节点数量对模型的性能提升作用有限,模型深度的增加(增加隐含层层数)不仅可以减少每个隐含层节点的数量,还能增加对数据的处理和拟合能力。所以本文选择利用深度学习模型进行温室监测数据的融合和决策,可以很好地解决MLP隐含层节点过多导致收敛速度过慢及局部极小化的问题。
3.2 改进后的WDNN模型
DNN深度学习模型可以较好地对多特征的数据进行分类,但是由于其模型结构限制和网络特性,使其不易处理稀疏特征,无法对特征之间的强耦合性进行关联记忆,当输入数据出现稀疏特征和关联特征时,不能快速并准确地对该关联特征进行参数优化。
Google于2016年提出了宽-深神经网络(Wide-deep neural network, WDNN)[25]用于Google商店的APP推荐服务,该模型改进之处在于从原来DNN深度模型的基础之上联合训练了一个wide模型(线性模型)用于共同对数据进行分类决策。wide网络数学模型表示为
y=WTX+b
(1)
其中X=(x1,x2,…,xn)W=(w1,w2,…,wn)
式中X——特征向量W——模型参数
b——模型偏置
y——wide网络输出
wide网络最重要的转换为交叉乘积变换,定义为
(2)
式中cki——布尔变量,只有当第i个特征是φk第k次转换的一部分时为1,其余条件下为0
wide模型善于处理稀疏特征,通过对特征进行交叉乘积来记忆特征之间的相关性且需要较少的模型参数,记忆性可以理解为能够自主学习频繁共同出现在一起的特征并当该关系再次出现时可以发现并利用,善于处理特征之间的固定组合。
deep网络具有更好的泛化能力,可以关联或发现之前几乎没有出现的特征组合,善于将隐藏的特征属性进行融合,减少了特征工程的复杂度。
deep网络数学结构:
(1)输入层为输入数据的各个特征。
(2)每个隐含层节点均由激活函数构成,为了克服梯度消失等问题, DNN模型构建时默认函数为整流线性单元ReLu,函数定义为
g(z)=max(0,z)
(3)
式中z——激活函数输入值
(3)多分类模型输出层多为SoftMax函数,形式为
(4)
(4)DNN模型的整体函数表达式为
f(x;W,c,w,b)=wTmax(0,WTx+c)+b
(5)
(5)优化函数默认使用Adagrad算法
(6)
式中ε——一个极小值,防止分母为0
η——学习速率θ——模型系数
deep网络的算法构建主要由以上函数组成,函数1为隐含层节点的激活函数,负责对特征进行非线性变化以达到进行非线性拟合的目的,其中层内节点无连接,层间节点全连接;函数2为深度学习模型常用的多分类函数,用于搭建模型输出层;函数3为特征经过一层隐含层后的数学表示,即前一层输出经过ReLu函数进行非线性变化后传递给下一层,模型深度的增加就是该表达式的多层嵌套;函数4为常用的梯度下降算法,具有动态调整学习速率的特点,能够快速优化模型参数。因此将以上两个模型进行合并可以达到在不改变深度网络对数据融合能力的同时加强WDNN模型对关联特征的识别和记忆,改进后的模型示意图如图5所示。
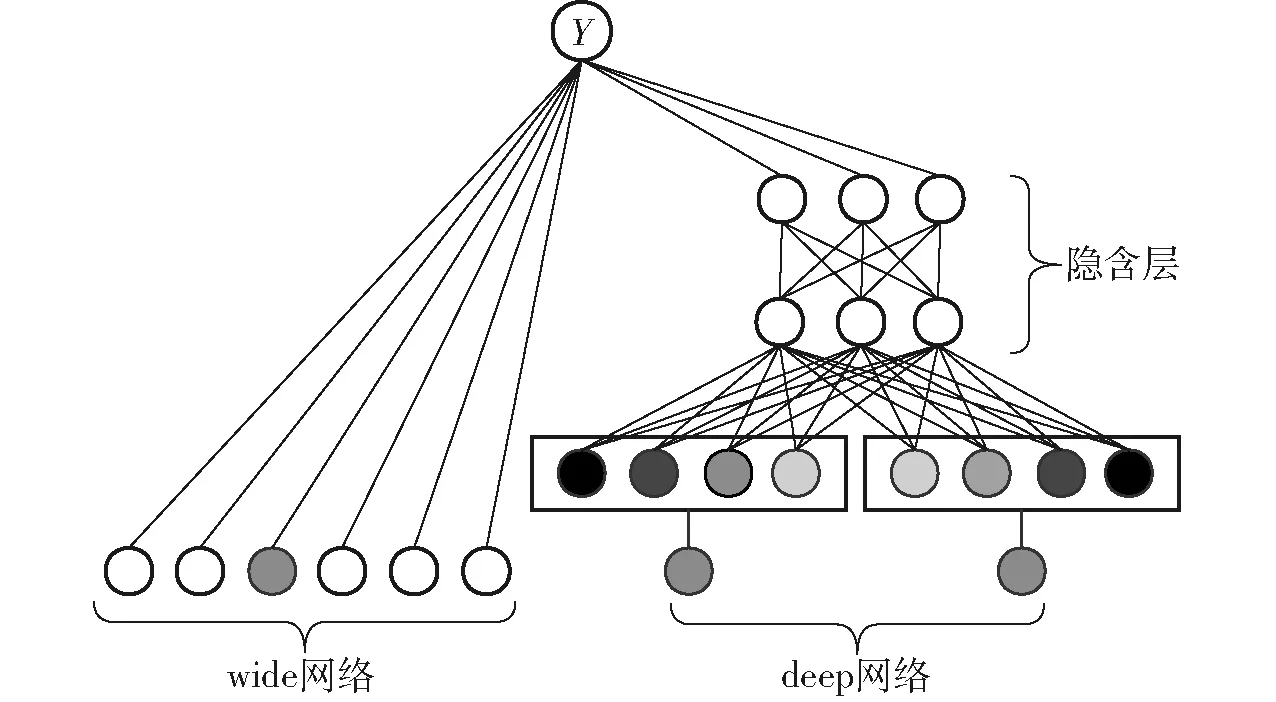
图5 WDNN网络结构示意图Fig.5 WDNN network structure diagram
WDNN模型的训练采用联合训练,即训练阶段将wide和deep网络的参数一起优化,再共同对未知数据进行融合,改进后数据融合的数学表达式为
(7)
式中Y——分类类别标签
SoftMax(·)——多类别分类函数
φ(x)——原始特征x的交叉乘积转换
Wwide——wide模型的权重向量
Wdeep——deep网络的权重向量
本文将WDNN模型和温室作物环境数据相结合进行训练可以得到数据融合模型,其结构示意图如图6所示。
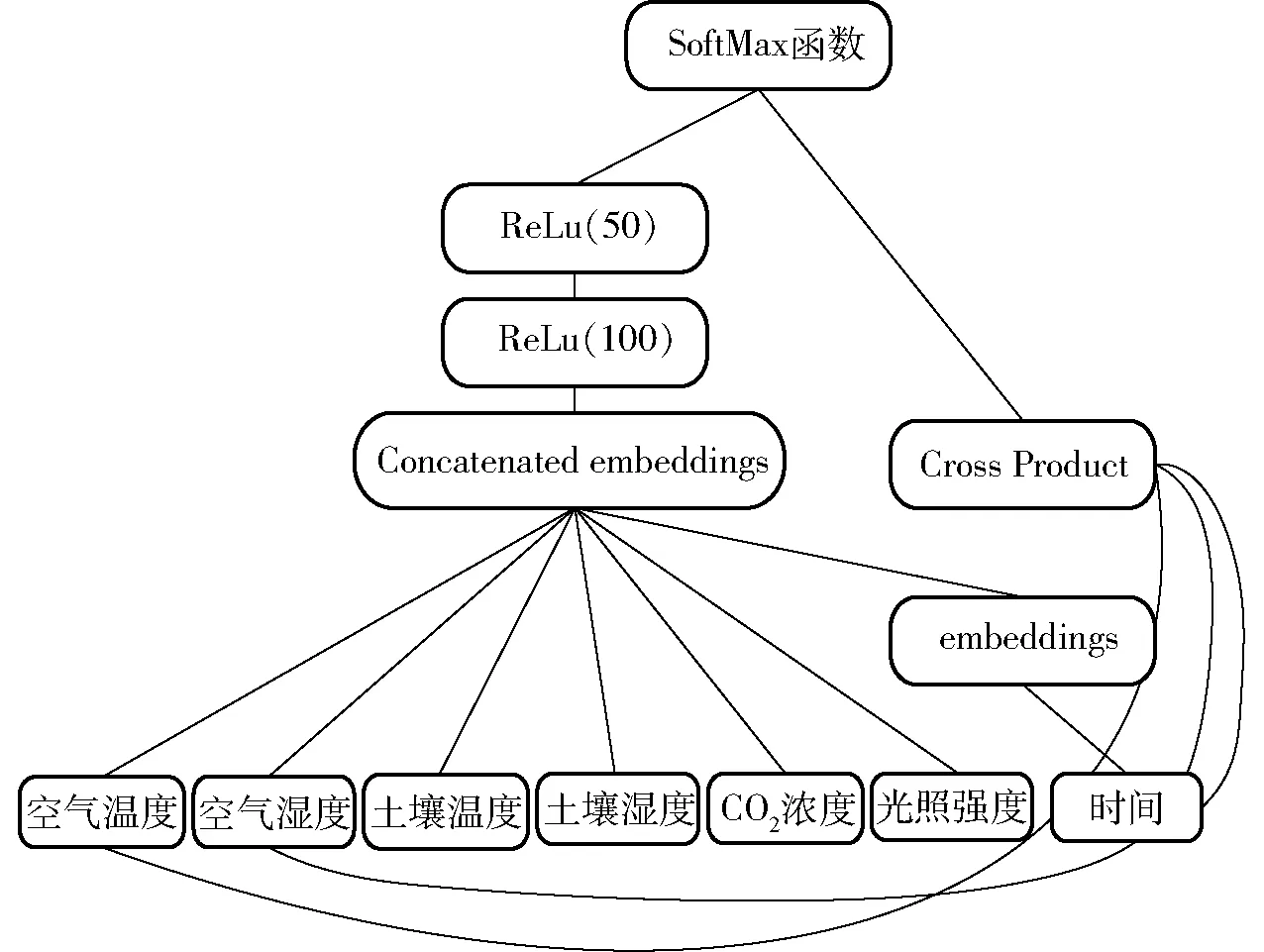
图6 WDNN网络融合温室数据示意图Fig.6 Schematic of WDNN network fusion of greenhouse data
4 试验与分析
4.1 数据采集及准备
试验选取了6个数据采集点,从2017年12月23日至2018年1月2日的4 858条数据用于模型训练和测试,其中训练集4 009条数据,测试集849条
数据,每条数据均为30 min间隔、24 h连续采集。将下载数据进行标记并将训练集和测试集用于模型的搭建。融合系统搭建环境为MacOS High Sierra操作系统(版本为10.13.3),模型实现基于Google开源的Tensorflow工具包(版本为Develop r1.1),编程语言为Python(版本为3.6),集成开发环境(IDE)为集成在Anaconda中的jupyter notebook。
搭建模型前需对数据进行特征处理,按照番茄种植规范[26]将温度划分为6个区间段,分别为日间:0~10℃、10~15℃、15~20℃、20~30℃,夜间:0~8℃、8~12℃;湿度划分为3个区间段(不区分日间和夜间):30%~60%、60%~70%、70%~80%;依据划分标准对训练集和测试集添加标签,然后与时间特征进行交叉乘积输入到wide模型;其余气象特征不进行区段划分;将实际值特征直接输入到deep模型中并与wide模型进行联合训练,特征对应分类类别为7类(数字0~6),每一类别对应一个融合结果(各区域作物当前环境状态融合后的决策信息)及温室调控建议, 成功构建用于温室数据融合的深度学习网络,用户可以根据融合信息实时掌握各区域作物的各项参数指标及温室整体的调控信息,实现温室作物环境数据融合的信息化和智能化。
4.2 模型构建及对比分析
为对比测试,分别训练了DNN和WDNN两种深度学习模型及BP神经网络(BP neural network, BPNN)和随机森林(Random forest,RF)两种常用分类模型,选取DNN可实现在网络深度相同及对应算法一致的条件下进行对比测试,利用BPNN和RF可对比相同数据集条件下不同分支模型的融合精度情况,模型参数对比如表2所示。
由表2可以看出,由于WDNN网络为混合模型,所以增加了一个wide网络的优化算法FTRL,因具有良好的稀疏性及收敛特性,故适用于线性模型的优化训练,两个deep网络部分的模型参数配置均相同;BPNN模型为3层结构,只含一个隐含层,层中部署100个隐含节点,为避免ReLu与SoftMax直接相连时训练过程出现权重为零值现象,激活函数选择Tanh即可;RF模型的决策树深度选择自由生长,对应算法选取Cart,弱分类器个数为50个,设定为有放回随机挑选特征。

表2 4种模型参数对比Tab.2 Comparison of four models parameters
注:Cart(Classification and regression tree):分类回归树;Ensemble learning:集成学习;Gradient descent:梯度下降;MLP(Multilayer perceptron):多层感知机。
模型参数预设完成后进行训练,模型训练步骤均为2 000步,训练损失函数相同,对比如图7所示。损失函数定义为
(8)
式中a——预测变量
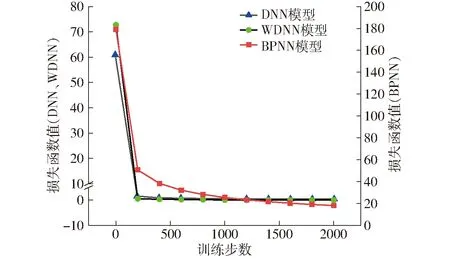
图7 DNN、WDNN和BPNN模型损失对比Fig.7 Loss comparison of DNN, WDNN and BPNN models
由图7可以看出,虽然WDNN网络在训练初段损失值高于DNN网络,但是曲线下降速率更快,模型参数优化效果更优,训练后的模型准确率更高;BPNN模型训练损失值远高于其他2个模型,参数优化较慢。4个模型性能对比评估如表3所示。
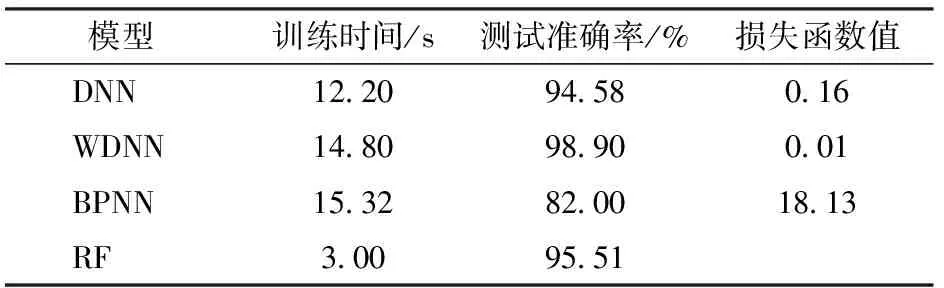
表3 4个模型性能评估Tab.3 Performance evaluation of four models
通过数据对比可知,WDNN模型的训练时间相比于DNN网络增加了21.31%,这是由于WDNN网络需联合训练wide和deep网络,模型复杂度较高导致,但模型的测试准确率高了4.32个百分点,且参数优化更快、损失函数值更低;BPNN模型训练时间最长,融合精度最低,且训练所需步数较多;RF模型虽训练时间最短,但模型预测准确率比WDNN降低了3.39个百分点,融合精度不足;结果表明WDNN网络对于强耦合性的温室监测数据具有更好的拟合能力,使融合后数据的决策分析更加准确。
4.3 融合结果
将搭建完成的WDNN深度学习模型用于融合实时的温室监测数据,选取了2018年1月500个全新数据构建预测集,预测集包含传感器异常和区域环境差异等各种条件下温室环境数据,用于测试温室数据融合的准确率,融合结果如图8所示。

图8 融合结果Fig.8 Charts of fusion result
由图8a可以看出,该模型既可发现异常数据并进行警告,也可在精确融合各区域情景信息的同时,按照少数服从多数的原则对区域融合结果进行二级融合,得到温室整体环境综合决策(若胁迫结果与正常结果相等时,取胁迫结果,此设定可减少作物受到伤害);图8b为降维后的模型分类结果,可看出各簇数据分类效果明显,个别交叉数据点为降维后视觉误差所致;测试表明融合准确率高达98.00%,达到预测期望结果。
4.4 模型通用性验证
为验证WDNN融合模型的通用性,随机选取了2018年2—6月共计200个数据(随机选取数据为春季和夏季监测数据,可同时验证模型对季节的泛化能力)进行融合系统通用性验证。融合结果如表4所示,其中正确融合数据量为190个,对应融合准确率为95.00%,融合精度相对于训练时有所下降,主要原因为春夏气象特征分布与冬季差别较大,会对模型融合精度产生一定影响,但仍然高于DNN和BPNN模型且与RF模型几乎持平, 能够满足温室作物环境数据融合的需求。
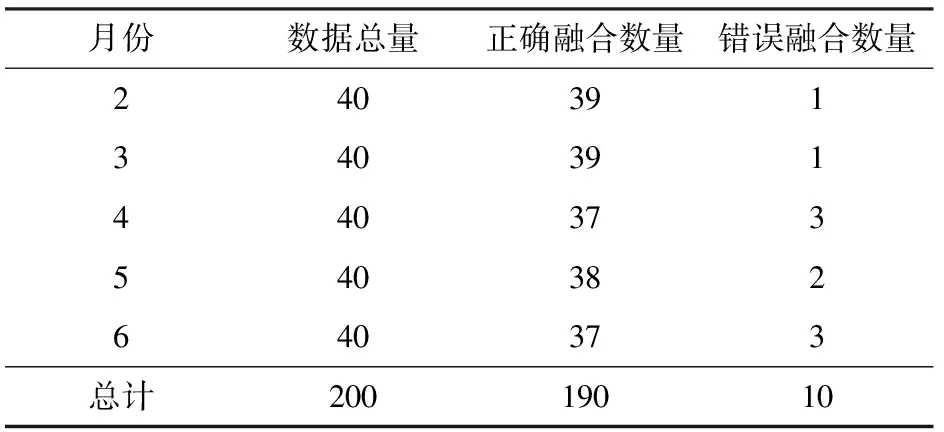
表4 模型通用性验证Tab.4 Verification of model generalization 个
5 结论
(1)温室数据融合可以有效地监测并给出温室作物生长环境的决策信息。分析各深度学习模型的优缺点,选取WDNN网络模型,利用其对数据的强大非线性拟合及泛化能力,根据无线传感网络获取的多点监测数据建立了一个两级温室环境数据融合体系,给出温室整体的作物环境决策信息。
(2)在深度网络参数配置相同时,改进后的WDNN网络比DNN和BPNN网络参数优化更快,损失函数值更低;改进后的模型输入特征不局限于连续实值数据,对含有稀疏特征的混合信息依然可以进行精确融合,且融合精度较DNN模型高4.32个百分点、高BPNN模型16.90个百分点、高RF模型3.39个百分点;WDNN模型除了具有高精度的融合能力外,还兼具良好的通用性,可应对复杂多变的温室作物环境。
