多线程并发网络爬虫的设计与实现
2019-03-04邵晓文
邵晓文
(长春理工大学计算机科学与技术学院,长春130022)
0 引言
进入21 世纪以来,互联网技术进入了飞速发展阶段,互联网上的信息量成爆炸式增长,谷歌、百度、雅虎等搜索引擎,每天都会抓住数以亿计的网页,不同领域、不同背景的用户,对于信息的需求不同,尽管这些搜索引擎帮助我们抓取了互联网上的大部分信息,但是返回的结果包含大量用户不关心的网页。网络爬虫[1]是搜索引擎的基础,目的是为了对互联网中的海量数据进行抓取,当需要对具体网站(如知乎)数据进行抓取,通用搜索引擎无法完成这部分工作,需要设计专门的主题爬虫[3-4]程序,自动抓取特定网页中的信息。
知乎作为国内知名的问答社区,连接着各行各业的用户。用户分享着彼此的知识、经验和见解,为中文互联网源源不断的提供多种多样的信息。目前知乎的用户已经突破1 亿,但是知乎官方并没有提供相应的数据接口,以供使用。Python 语言常被用于爬虫程序编写[2],但相比于Java 而言Python 的执行效率低,并且Java 语言对多线程的支持更加完善。因此本文设计了一款基于Java 语言的多线程并发网络爬虫,爬取知乎用户的相关信息。实验结果表明:多线程爬虫,具有较快的爬取效率,可以更快地爬取数据。
1 爬虫简介
整个互联网可以看成一个无限大的有向图,网络爬虫的抓取流程是以一个URL 为初始点,根据URL 发送请求,获取对应的HTML 页面,提取出需要采集的信息保存,同时解析出更多的URL 加入URL 队列,从而实现从一个点扩展到整个网络的过程。直到符合爬虫的停止条件。爬虫的抓取流程如图1 所示。
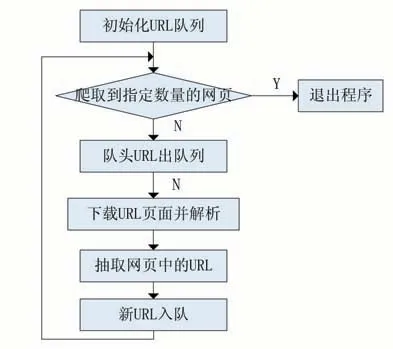
图1 普通爬虫的抓取流程
2 爬虫结构设计
2.1 抓取的策略
知乎的用户之间的关系可以看做一个有向图,如图2 所示。

图2 知乎用户关系示意图
对图的搜索主要有两种方式,深度优先搜索和宽度优先搜索。深度优先遍历测试是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路的链接之后,再转入下一个起始页,继续跟踪链接。宽度优先策略是按照树的层次进行搜索,如果此层没有搜索完成,不会进入下一层搜索。即首先完成一个层次的搜索,其次再进行下一层次,也称之为分层处理。
本文采用的是宽度优先搜索。因为离种子URL比较近的,往往是重要的网页,随着浏览的不断深入,所看到的网页重要性会越来越低。宽度优先搜索也有利于多爬虫的合作抓取。
知乎中的每个用户都有唯一的Urltoken 与之对应,首先选取一名知乎活跃用户作为起点,使用httpclient 工具发送请求,返回JSON 格式的数据,提取用户的相关信息存入MySQL 数据库,同时获取该用户关注的用户列表,用户列表中的数据以Urltoken 的方式给出,通过Urltoken 组成新的URL 加入队列。
2.2 队列的设计
爬虫队列的设计是网络爬虫的关键部分,小型爬虫可以直接使用链表实现,但是需要爬取的数据量很大时,仅仅靠Java 自身提供的数据结构是远远不够的,并且当爬取时间很长时,爬虫程序不一定能够在一次的启动过程中就完成所有爬取工作,可能需要重复启动多次,这就需要将队列中的数据固化到硬盘中,否则再次启动爬虫,将重新从开始节点爬取。因此这里选用Redis 数据库来实现爬虫队列。
Redis 是一款高性能的key-value 数据库,主要具有以下特点:
●Redis 支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用,这一点对网络爬虫来说非常重要。
●Redis 不仅仅支持简单的key-value 类型的数据,同时还提供list、set、hash 等数据结构的存储。
●Redis 性能极高,读取速度高达110000 次/s,写入速度高达81000 次/s。
因此Redis 非常适合用来做网络爬虫的队列,本文使用Redis 的List 结构,作为爬虫程序的URL 队列。
2.3 布隆过滤器
在采用深度优先的爬取策略时,需要对已经爬取过的URL 进行过滤,避免重复爬取,可以使用Java 提供的哈希表对已经爬取过的URL 进行记录,从而达到避免重复的效果。对于小型爬虫而言,通过Java 提供的哈希表来实现过滤器,能满足需求。但是知乎的用户数量已经超过一亿,当爬取的数据量很大时,需要非常大的内存空间,一般服务器很难满足这样的存储需求。因此本文采用了布隆过滤器[5-6]来过滤已爬取的URL。
布隆过滤器是由巴顿·布隆于1970 年提出,它是一种数学工具,只需要哈希表的1/8~1/4 的大小就能解决同样的问题。它主要是由一个二进制的向量和一系列的hash 函数组成。本文通过下面的示例说明其工作原理。
利用内存中的一个长度是m 的位数组B,对其中所有位都置为0,如图3 所示。

图3 位数组的初始状态
对于每一个URL 地址,选取8 个不同的随机质数,根据这8 个质数,计算出八个不同的hash 值,并将位数组中对应hash 值的位置设为1,如图4 所示。
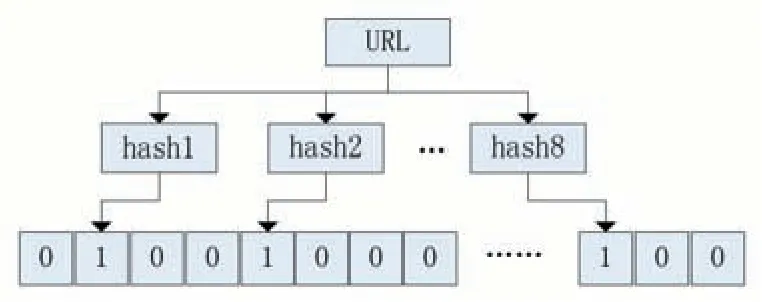
图4 布隆过滤器的实现
对于5000 万级别的URL,布隆过滤器值占用200M 左右的空间,大大节省了存储空间。
正如上文所述,当爬取数据量很大,爬取时间很长的时候,当遇到爬虫程序意外终止的情况,再次启动爬虫程序,就得重新开始爬取,对于过滤器也一样,如果使用HashMap 或者Set,再次启动爬虫时,过滤器中的数据丢失,因此,鉴于前面对Redis 的介绍,这里采用Redis 的List 结构来实现。
2.4 多线程爬虫
爬虫主要消耗三种资源:网络带宽、中央处理器和磁盘。三者中的任何一个都可能成为会爬虫程序的瓶颈。在这三者都无法控制的前提下,单线程爬虫的效率低下,爬取速度很慢。为了增加爬虫的效率,最直接方便的办法就是使用多线程技术[7]并行抓取,Java 语言对多线程提供了很好的支持。在爬虫系统中,要处理的URL 队列是唯一的,多个线程依次从队列中取出URL,各自对用户信息进行抓取,再将用户关注者的URL 加入队列,因此,线程既是生产者也是消费者,这里使用线程池来管理线程。
使用多线程并发爬取数据时可以大大提升爬取的效率,但同时也带来数据竞争的问题。即存在同一块内存上,存在两个并发的操作,其中至少有一个为写操作。数据竞争会导致读取的数据和预期的不一致。本文通过Redis 实现了URL 队列和布隆过滤器,Redis 的基本操作,在并发环境下是具有原子性的,因此不用考虑数据竞争。
2.5 计数器
本文的爬虫程序结束逻辑是使用了一个共享变量count 作为计数器,记录已爬取的URL 数量,当达到指定数量,就不再向URL 队列中加入新的URL,直至将URL 队列中的数据爬取完毕,URL 队列为空,爬虫程序终止,因此爬取页面的时间远远长于向队列中加入URL 的时间,因此不会出现URL 队列为空,而count 没有达到指定数量的情况。由于多线程的执行顺序使无法确定的,且线程之间的操作是相互透明的,因此对count 的操作是存在线程安全问题的,会产生数据竞争的问题。对此,通常的解决方案是将操作count 的临界区通过Java 提供的同步锁进行保护,保证每一次只有一个线程修改count 变量,但是当线程数量很多是,锁机制会大大降低爬虫的效率。因此采用乐观锁来解决count 的数据竞争问题,乐观锁的主要元素是通过CAS(Compare And Swap)操作实现,使用Java 提供的原子操作类:AtomicInteger 原子更新整型类,该类保证更新的原子性,性能高效,线程安全。本文的爬虫程序结构如图5 所示。
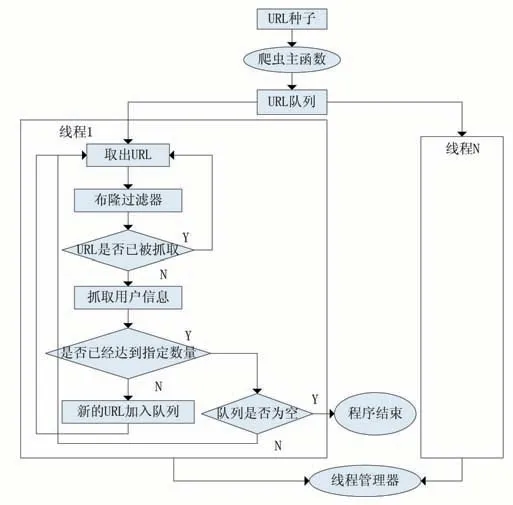
图5 本文的爬虫架构
3 实验结果
3.1 实验环境

表1
3.2 使用的Jar包工具

表2
3.3 抓取过程
首先从种子URL 开始,使用HttpClient,根据URL,向服务器发送请求,知乎服务器响应一段HTML代码,其中包含用户相关信息的JSON 格式数据,使用Jsoup 解析HTML 网页,获取用户的信息,通过JsonObject,解析出用户的相关数据并存入MySQL 数据库,根据用户的token,发起新的请求,获取用户关注列表,得到JSON 格式数据,解析出关注列表的Urltoken,组成新的URL,存入队列,最终完成队列的初始化工作。
完成初始化工作后,开启线程开始爬取工作,从队列中取出URL,判断URL 是否已经被爬取,如果没有,就执行爬取工作,否则重新从队列中取出新的URL,当URL 计数器达到指定数量时,停止向队列中加入新的URL,继续爬取队列中剩下的URL,最终URL 队列为空,结束爬虫程序。
3.4 实验结果分析
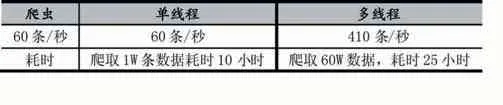
表3
实验结果表明:相比单线程爬虫的抓取速度远远小于多线程爬虫,因此本文设计的爬虫,能够有效提高了爬虫的效率。
4 结语
本文的爬虫采用Java 语言针对知乎的用户数据进行抓取,设计了多线程爬虫架构,实现了多数据的并发抓起,加快了爬取的速度,并使用了Redis 实现了URL队列,提升了存取的效率。本文实现了布隆过滤器,过滤已爬取的URL,大大减少了内存的消耗,放弃使用同步锁,使用Java 提供的原子操作类AtomicInteger,保证了线程的安全,提升了爬虫的效率,最终达到预期的爬取效果。
